打个广告:最近我们实验室的一篇文章“NAS-LID: Efficient Neural Architecture Search with Local Intrinsic Dimension”被AAAI2023主会录取,该文提出了一种基于局部本征维度(local intrinsic dimension, LID)的神经架构搜索算法,提高对候选模型的性能排序相关性,从而帮助找到优秀的模型结构。
One-shot NAS通过训练一个超网来估计每个可能的子网的性能,从而显着提高搜索效率。然而,子网之间特征的不一致对优化产生了严重的干扰,导致子网的性能排名相关性差。随后的一些工作尝试通过特定准则(例如梯度匹配)分解超网权重以减少干扰;然而,这些方法的问题在于计算成本高和空间可分性低。在这项工作中,我们提出了一种轻量级且有效的基于局部本征维度(LID)的方法 ,叫做NAS-LID。NAS-LID 通过对子网逐层计算低成本 的LID 特征来评估架构的几何特性。我们发现基于LID的表征方式与基于梯度的相比具有更好的可分离性,从而有效地降低了子网之间的干扰。在 NASBench-201 上进行的大量实验表明,NAS-LID 以更高的效率实现了卓越的性能。具体来说,与梯度驱动方法相比,NAS-LID 在 NASBench-201 上搜索时可以节省高达 86% 的 GPU 内存开销。我们在 ProxylessNAS 和 OFA 空间上也验证了NAS-LID的有效性,实验结果显示NAS-LID搜索到的模型在ImageNet数据集上取得了与之前工作相似甚至更好的结果。
神经架构搜索(Neural Architecture Search, NAS)旨在自动搜索模型结构,该方法已经被应用到多种任务,并且实验表明其搜索到的模型已经可以与人工设计的模型相媲美,甚至表现更好。早期的普通NAS算法(也叫Vanilla NAS)是每次从搜索空间中采样一个模型并将其训练至收敛,然后在验证集上得到验证性能(如validation accuracy),之后不断重复采样新的模型,最后挑选出验证性能最高的作为最终模型结构。所以NAS也可以理解成是对模型性能进行排序,排序的准确性决定了能否找到最优模型结构。
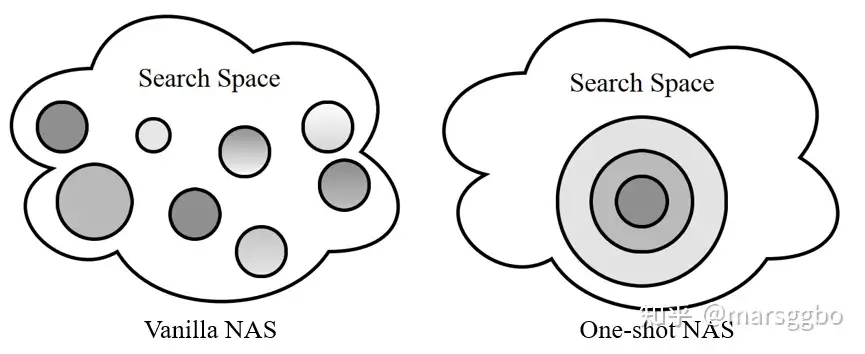
不过很显然,Vanilla NAS方法会耗费大量计算资源和时间,因此后续有工作提出权重共享策略来提高效率,这类方法叫One-shot NAS。下图给出了Vanilla NAS和One-shot NAS的区别,每一个圆圈代表一个模型结构。
可以看到One-shot NAS的候选模型之间会有部分重叠区域,这就表示权重共享。换句话说,整个搜索空间可以看成是一个巨大的模型结构(叫超网,Supernet),而每个候选模型则是这个超网的子网(subnet)。One-shot NAS中模型之间共享权重,所以共享部分的权重可以直接继承过来,而不用每次重复训练了。 虽然权重共享让One-shot NAS有效提高了搜索效率,但是它也是问题所在。为方便理解,我们以上图(右)中的最小同心圆为例进行说明。可以看到它是很多模型共享权重的部分,假设它的权重更新了,有可能它会让一部分模型性能得到提升,但也有可能会使得另一部分模型性能降低。换句话说,权重共享方式下每一次更新对于不同模型会带来不同的影响,而这最终会导致我们对模型性能产生误判,导致没法找到真正好的模型。而Vanilla NAS因为是独立地训练每个模型所以不存在这个问题。
已经有不少工作尝试去解决One-shot NAS评估模型性能不准确的问题,其中一种思路就是把互相产生负面干扰的模型划分开来。最早的工作是Few-shot NAS [2],该论文作者将一个Supernet以穷尽地方式随机划分成指定个数的sub-Supernet,这样一来其实是减少了每个sub-Supernet中包含的模型数量,从而间接地减少模型之间的干扰。简单理解Few-shot NAS就是介于Vanilla NAS和One-shot NAS的方法,前者每一个模型都视为一个sub-Supernet,而后者就只有一个Supernet。Few-shot NAS有一个比较明显的缺点就是划分方式存在随机性,效率不高。所以后面一个发表在ICLR2022的工作,GM-NAS [3]提出根据模型梯度相似性来划分Supernet,其实验结果表明这种划分方式的确能进一步提高NAS对模型性能的排序相关性,一般用Kendall tau或Spearman系数作为评价指标,这两个指标范围都介于-1到1。-1表示相关性完全相反,即实际上最好的模型被预测成最差的;1则表示相关性最强,即能准确预测每一个模型的相对好坏。
我们对GM-NAS做进一步分析发现它仍然有一些地方可以改进。首先,GM-NAS因为需要额外计算梯度,所以整个过程对GPU内存开销有较高要求。另外,GM-NAS是根据梯度cosine相似度对模型进行划分的,而我们知道深度神经网络的梯度是处于非常高维的空间。而高维空间有维数灾难问题,计算cosine距离并不能真实反映相似度。我们的实验也证实模型之间梯度的cosine相似度都很接近,因此很难基于梯度对模型进行划分。
为了解决GM-NAS的两个缺点,我们使用了一个新的指标,即局部本征维度(LID)。LID衡量的是能够用于表征数据的最小维度,比如很多工作用它来衡量数据集的难易程度等。这里,我们尝试用LID来对模型结构进行表征。我们首先对NAS-Bench201搜索空间随机采样并独立训练了多个模型,之后我们根据如下公式计算了每个模型逐层特征的LID值。
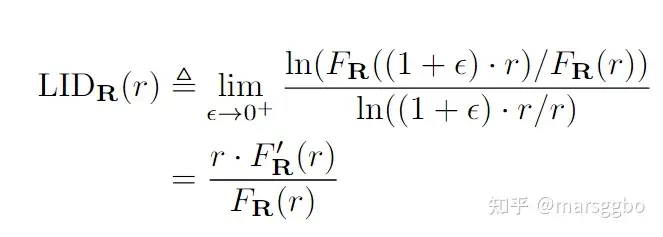
最后我们将采样的模型的逐层LID可视化如下图,图中每个曲线代表一个模型,横坐标表示模型的相对深度,纵坐标表示对应层数的LID值。
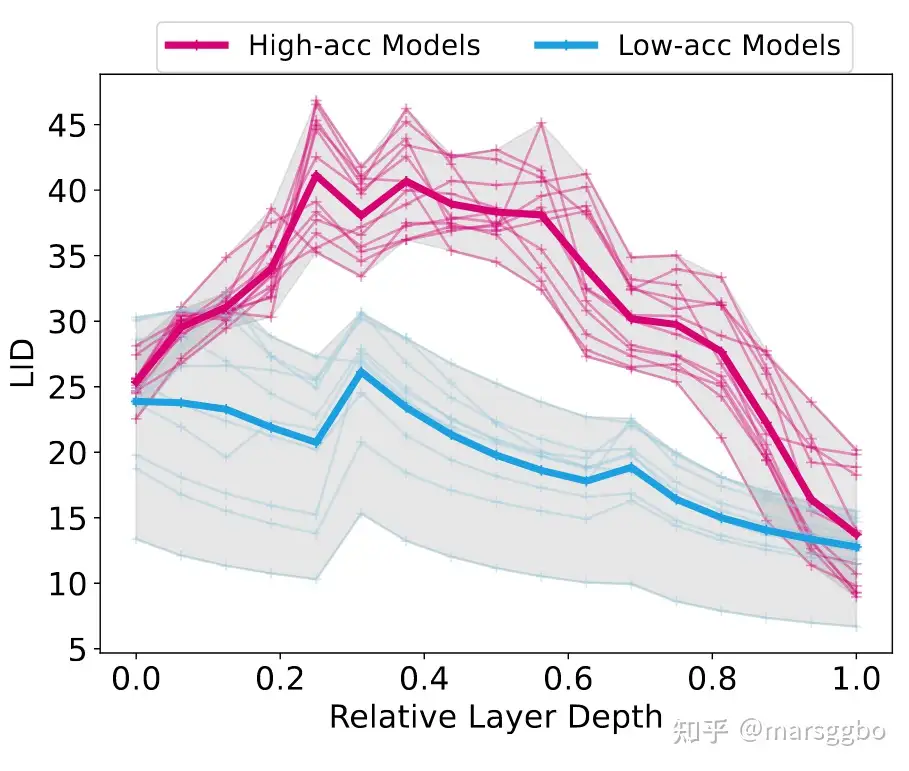
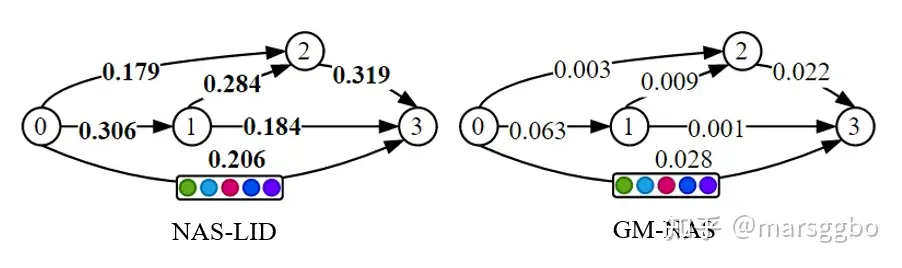
图中红色曲线为准确度高的模型,可以看到它们的LID都呈现拱形。我们认为红色曲线的LID先增趋势表示模型首先浅层将输入数据逐渐映射到更高维的流形空间,这一过程模型在学习数据的特征,而后面LID值不断下降表示模型此时在剪枝那些冗余的信息;而蓝色曲线代表准确率偏低的模型,它们的LID呈现递减趋势,这可能表示模型在浅层并未能有效学习到数据的特征。基于上面的分析,我们认为模型逐层的LID值分布能够表征模型结构的几何特性,而该特性在一定程度上决定了模型的training dynamics。换句话说,逐层LID值分布相似的模型在训练过程中可能有相似的偏好。作为一个概念验证性的工作,我们提出了NAS-LID方法,即基于逐层LID值分布相似性来对模型进行划分。具体来说,NAS-LID将每个模型表征成一组LID值,其长度即为模型的深度。很显然,相比于基于梯度的方法,我们将每个模型的表征维度大大降低了,这有效缓解了维数灾难问题。 下图显示了基于LID和梯度对NAS-Bench201空间可分性得分对比。每条边上有5个候选操作,选择不同额操作会得到不同的模型结构。每条边上的分数表示空间可分性得分,分数越低表示不同模型之间相似度方差越小,即很难将它们区分开来。可以看到NAS-LID能更有效地区分不同模型,而GM-NAS反之。
下图是基于LID相似度对Supernet划分的示意图,Supernet每层有若干个候选操作。通过连接不同节点而得到的路径可以看成是一个子模型。下面是Supernet划分步骤,为方便理解我们考虑第一层: 把第一层中的4个候选操作划分开来,这样可以将原来的Supernet划分得到4个sub-Supernet。 对生成的4个sub-Supernet分别计算它们逐层的LID值分布 计算sub-Supernet彼此之间LID分布相似度 基于min-cut算法找到对sub-Supernet最合理的划分方式,即尽可能保证相似的sub-Supernet归为同一类。属于同一类的会进行合并得到最终的sub-Supernet,如下图(左)所示。 划分完sub-Supernet之后分别finetune若干个epoch,最后每个模型通过继承对应sub-Supernet的权重直接进行性能评估。我们采用了进化算法进行搜索。
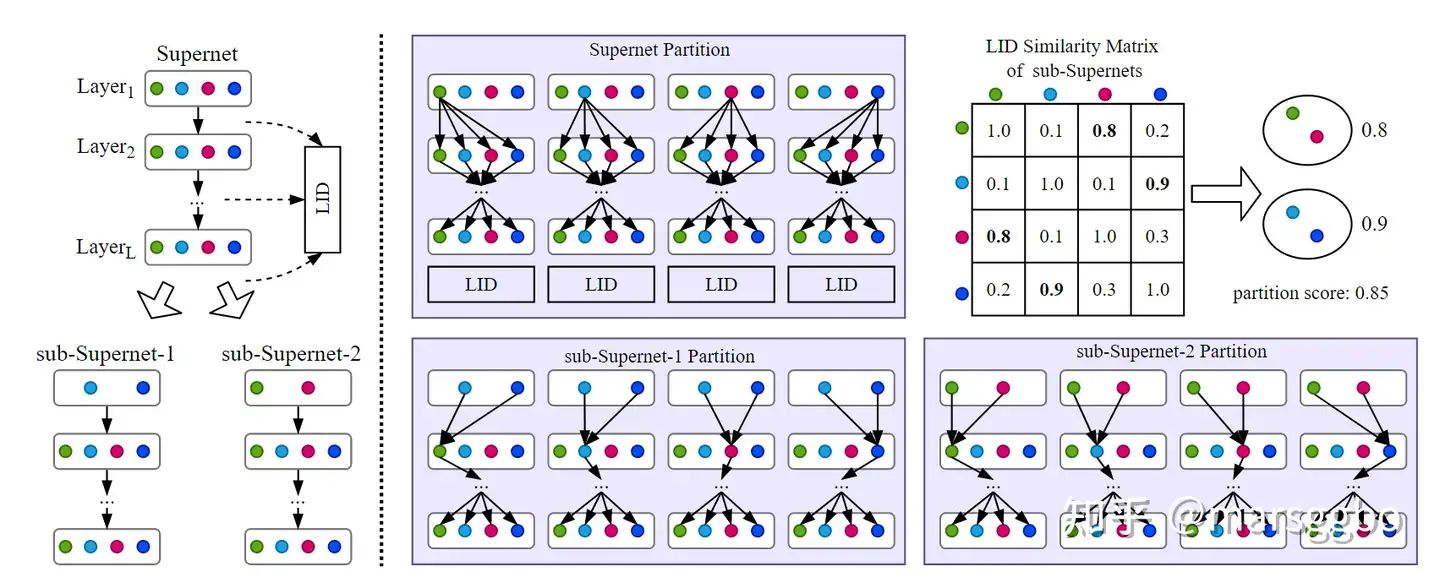
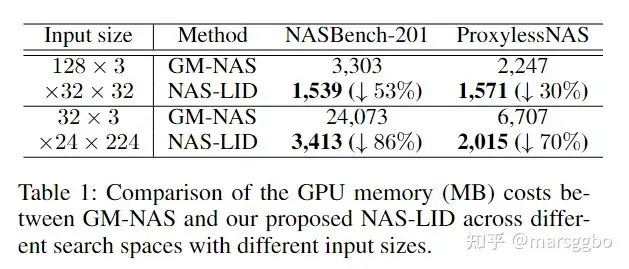
GPU内存开销对比 下表显示了GM-NAS和NAS-LID在不同搜索空间和输入数据大下GPU内存开销对比。可以看到,在四种情况下,NAS-LID的GPU内存开销都明显小于GM-NAS,尤其是当时输入数据大小为32×3×224×224和搜索空间为NASBench-201时,GPU内存开销能降低86%。
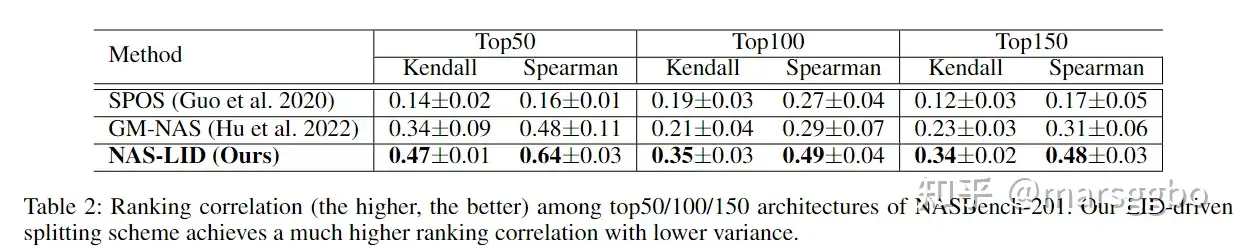
模型性能排序相关性实验 下表对比了SPOS、GM-NAS和我们的NAS-LID在NAS-Bench201数据集上对模型性能排序相关性。可以看到NAS-LID有效提升了排名靠前的模型之间的性能排序。
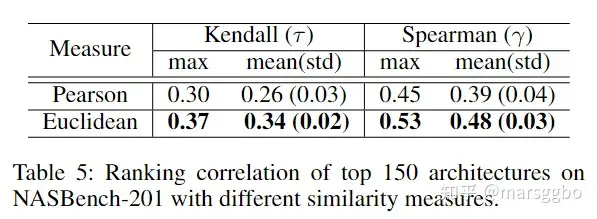
相似度衡量指标对性能排序影响 我们对比了基于欧氏距离和Pearson距离指标对最终性能排序相关性的影响。其中Pearson只衡量不同模型的LID的相对关系,例如假设两个模型的LID分布分别是[1,2,3]和[10,20,30],那么Pearson指标会认为二者完全相似,而欧氏距离则关注的是绝对关系。 下表结果显示基于欧氏距离计算LID相似度取得了更高的性能排序相关性,这意味着LID值的绝对大小对于表征高维空间中不同结构的几何特性至关重要。
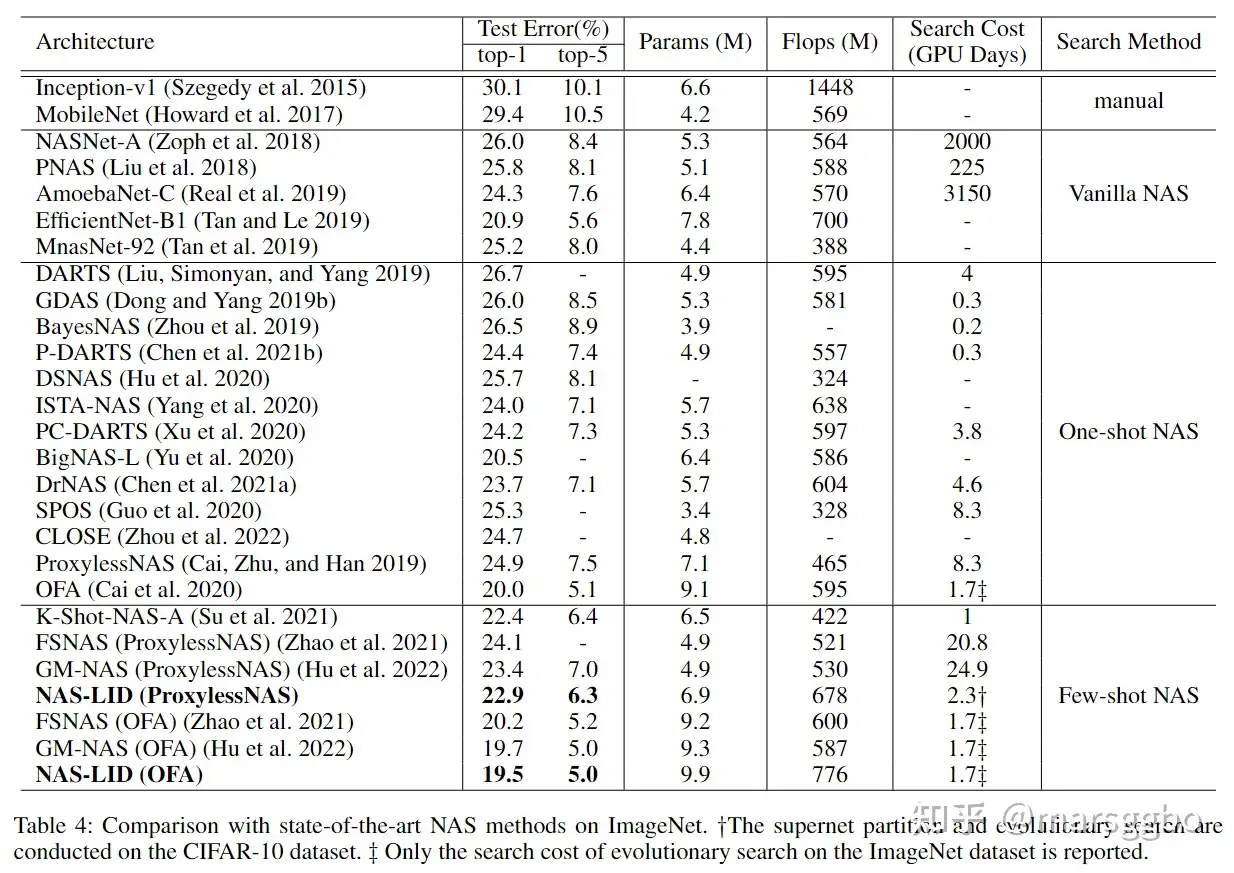
在OFA和ProxylessNAS搜索空间上的表现 我们进一步在 OFA和ProxylessNAS搜索空间验证了NAS-LID的有效性,下表显示了搜索到的模型在ImageNet上的表现,可以看到NAS-LID能够有效找到优秀的模型结构。
我们的实验表明,逐层LID是一个能有效表征模型架构的指标。作为一个概念验证,我们提出了NAS-LID 来证明LID在划分超网中的潜在应用。与梯度相比,LID有效地解决了维度的诅咒,用于计算相似度的计算开销可以忽略不计,并且NAS-LID实现了更好的空间可分离性和更高的子网排名相关性。我们发现,LID值的大小在基于LID的模型架构表征中起着至关重要的作用,我们认为逐层的LID描绘了高维数据在模型中是如何变化的。
不过在这项工作中,我们只探讨了图像分类模型。我们认为有必要对大型语言模型也做类似的LID分析,也许能够帮助我们对大模型有更深入的了解。
[1] He X, Zhao K, Chu X. AutoML: A survey of the state-of-the-art[J]. Knowledge-Based Systems, 2021, 212: 106622. [2] Zhao Y, Wang L, Tian Y, et al. Few-shot neural architecture search[C]//International Conference on Machine Learning. PMLR, 2021: 12707-12718. [3] Hu S, Wang R, Hong L, et al. Generalizing Few-Shot NAS with Gradient Matching[J]. arXiv preprint arXiv:2203.15207, 2022.