插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。
原文:TokenFlow: Responsive LLM Text Streaming Serving under Request Burst via Preemptive Scheduling
用过 ChatGPT 或者任何一个 AI 对话产品的人都有同样的体验:你发出一条消息,页面上的文字一个一个「流」出来,就像打字机一样。这种「流式输出」(text streaming)是现代 LLM 交互的标配,给人一种 AI 正在「思考」的感觉,体验比等待一整段文字突然出现好得多。
但如果你仔细观察,有时候这个「流」并不稳定——刚开始等了很久才出现第一个字(TTFT 高),或者文字时快时慢、突然卡顿(TBT 不稳)。这篇来自 EuroSys 2026 的论文 TokenFlow 就是要彻底解决这个问题。
LLM 流式服务的核心矛盾,可以用两个指标来描述:
问题在于,这两个目标天生矛盾。
当大量请求同时涌入(request burst),系统资源有限,服务器必须做取舍。SGLang 等主流框架采用 FCFS(先来先服务)策略:正在处理的请求继续跑,新来的请求乖乖排队。结果是——
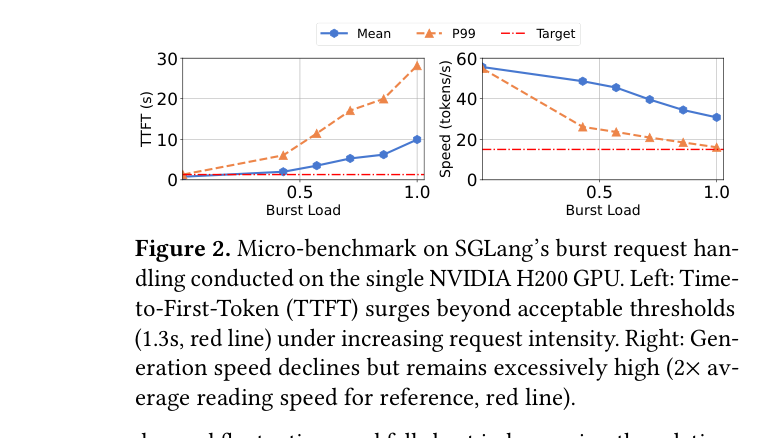
如下图所示,SGLang 在 burst 负载下,P99 TTFT 轻松突破 30 秒,而生成速度却远超用户阅读需求——两头都没做好。
这里有一个关键观察,也是 TokenFlow 的核心洞察:
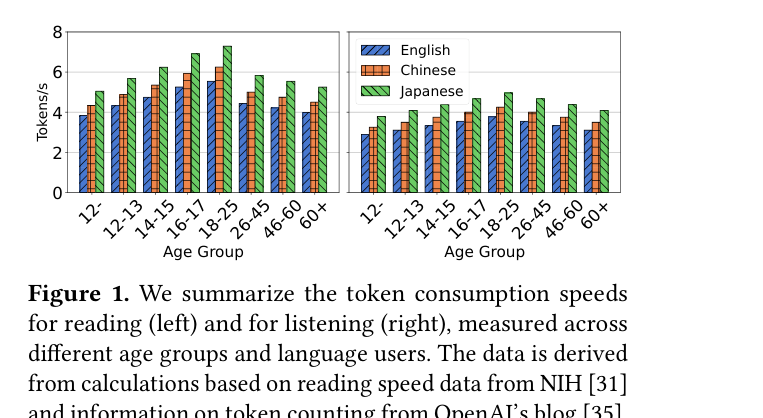
LLM 的生成速度远远快于用户的阅读速度。
实测数据(Figure 1)显示,用户平均阅读速度约 3-5 tokens/秒,而模型生成速度可以达到 30-100 tokens/秒,相差一个数量级。
这意味着,服务端可以提前生成一批 token 存在 output buffer 里,用户慢慢消费,系统不用死等用户。只要 buffer 不空,用户体验就是流畅的。
这个 buffer 的存在,给了系统一个「喘息空间」——可以暂停一个正在跑的请求,先处理一个新来的请求的 prefill(生成第一个 token),只要 buffer 里还有剩余 token,暂停的那个用户不会察觉任何异常。
这就是 preemptive scheduling(抢占式调度)的机会所在。
TokenFlow 的整体架构如下图所示,核心由两部分组成:Buffer-Aware 调度器 + Proactive KV Cache 管理器。
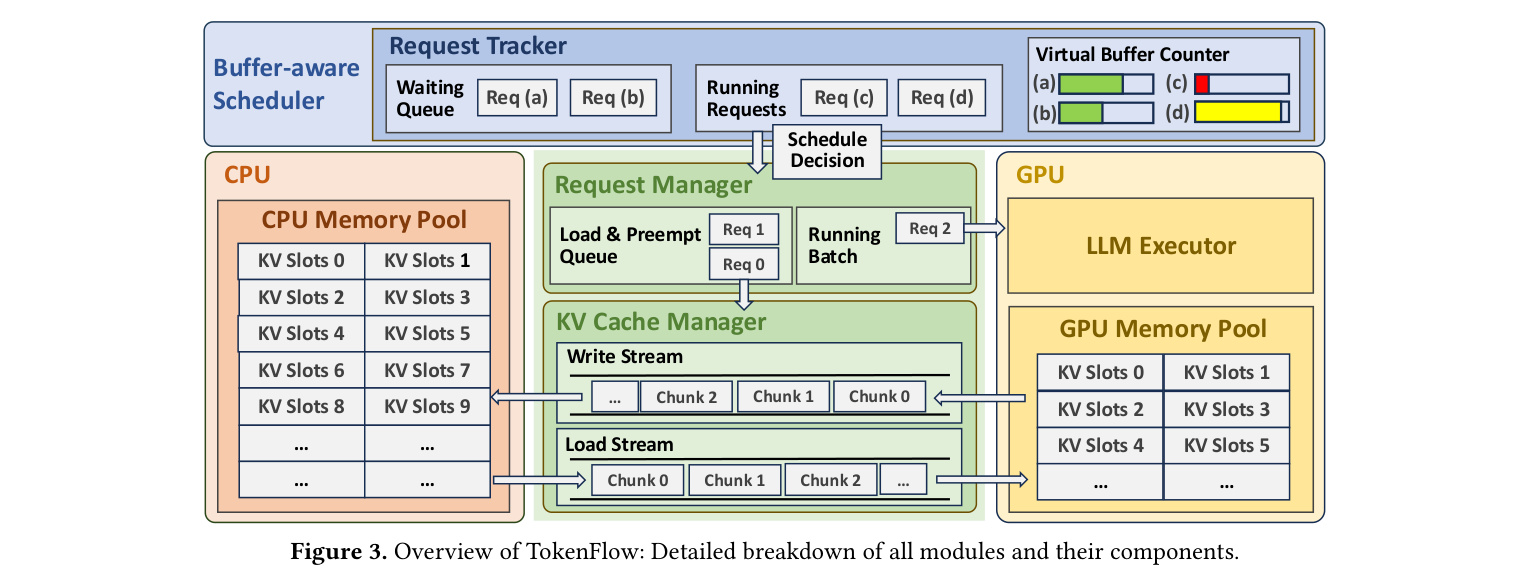
传统抢占式调度(如 Andes)的思路是:新请求来了就强制暂停旧请求。问题是这会导致频繁的 context switch,干扰正在运行的请求。
TokenFlow 更聪明——它引入了 Virtual Buffer Counter,实时追踪每个请求的:
基于这两个信息,调度器动态决定:什么时候该暂停哪个请求。
具体来说,调度策略分两步(如 Figure 7 所示):
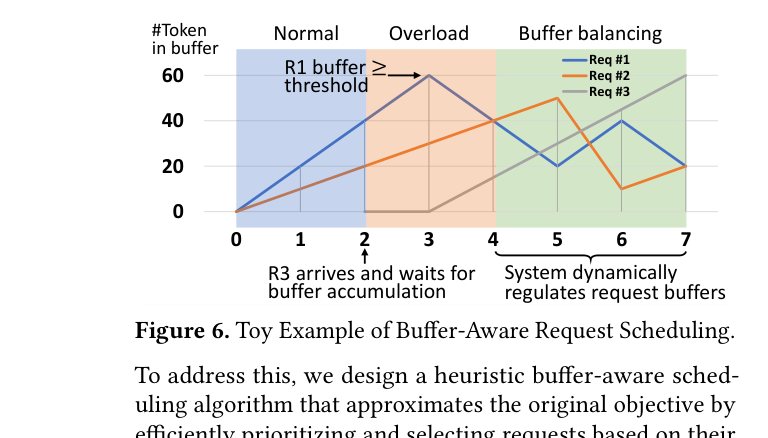
这样的设计,让系统在”稳住老用户”和”快速响应新用户”之间找到最优平衡点。
这是 TokenFlow 另一个关键创新。
传统系统(包括 Andes)的 KV cache 管理是被动的(reactive):只有当 GPU 内存快满时,才开始把 KV cache 卸载(evict)到 CPU;需要恢复请求时,再从 CPU 加载(load)回 GPU。这个过程 I/O 开销极大,会导致系统从 compute-bound 变成 I/O-bound。
TokenFlow 的做法是主动的(proactive):
Write-Through 策略:每次生成新 token,就立刻把对应的 KV cache 同步写到 CPU 内存(类似 CPU cache 的 write-through 策略)。这样,当真正需要抢占请求时,KV cache 已经在 CPU 里了,evict 操作几乎是零开销。
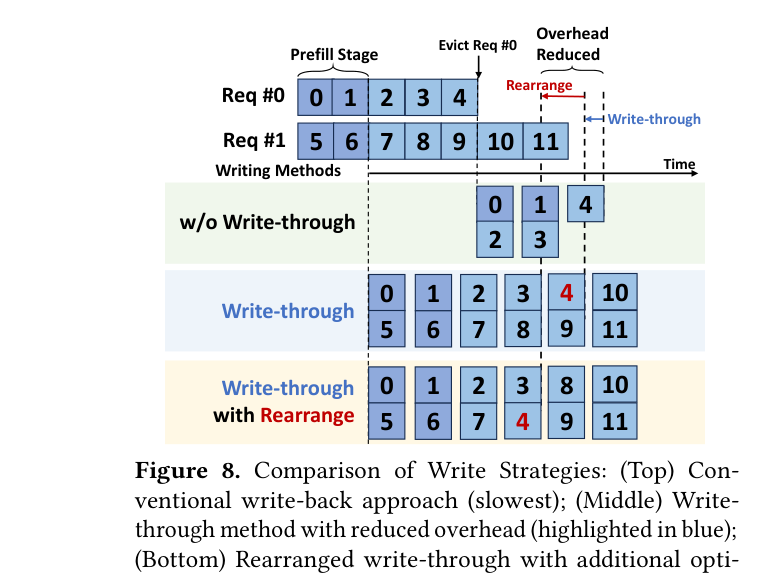
Chunked + Overlap 策略:KV cache 的 load/evict 操作被拆成小块(chunks),与 GPU 计算并行执行,利用 PCIe 带宽不影响 CUDA 核心的特点,做到 I/O 和计算的充分重叠。
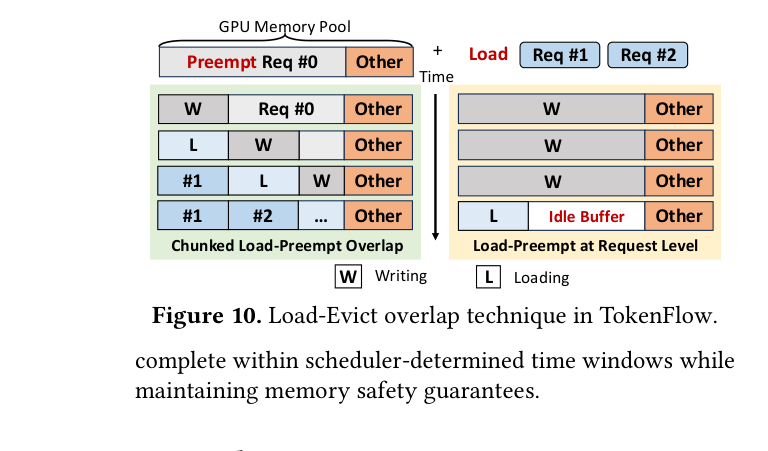
具体实现上,TokenFlow 基于 SGLang 构建,用 CUDA streams + Python 多线程实现了完全重叠的计算与内存操作,代码约 4000 行 Python。
这篇论文还提出了一个重要观点:传统的 tokens/second 吞吐量指标不足以评估流式服务。
原因是:如果服务器狂生 token 但用户 buffer 已经满了,那些多余的 token 对用户没有任何价值,反而浪费了 GPU 算力。
TokenFlow 定义了 Effective Throughput:只统计用户实际消费到的 token,而不是系统生成的所有 token。这个指标综合了 TTFT、TBT 稳定性和 buffer 利用率,更贴近真实的用户体验。
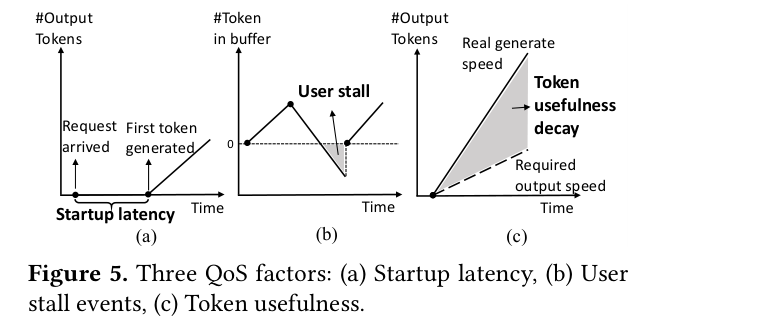
同时,论文定义了 QoS(Quality of Service) 指标,综合考虑:
实验在多种硬件(RTX 4090、A6000、H200)和模型(Llama3-8B、Qwen2.5-8B/32B)上进行,基线包括 SGLang 和 Andes。
使用真实 workload(BurstGPT trace + 内部运营商 trace)的结果:
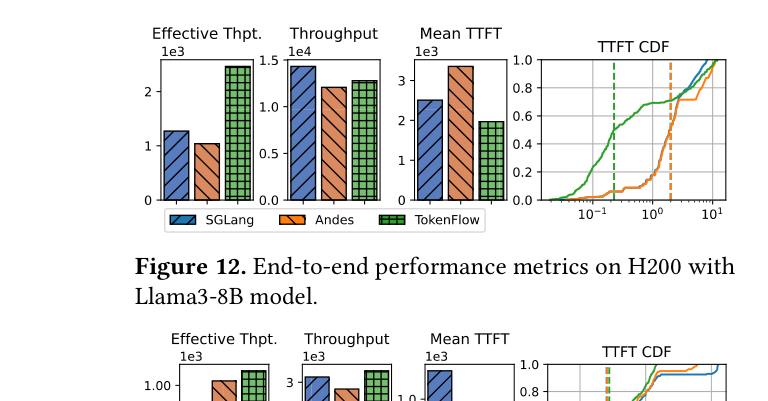
Burst 场景下(合成 workload):
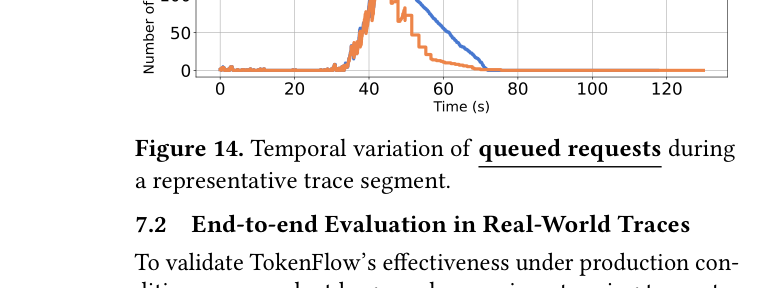
TokenFlow 在 burst 到来时明显减少了排队请求数量,同时保持更高的并发运行请求数——说明系统在压力下能更高效地利用 GPU。
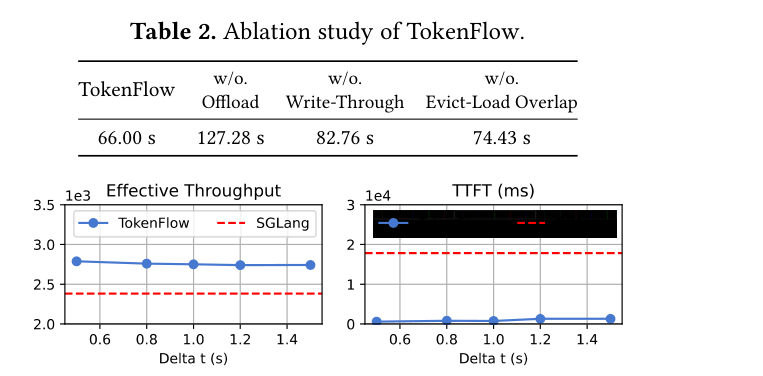
消融实验(Table 2)验证了两个核心模块的贡献:单独使用 buffer-aware 调度器或 proactive KV cache 管理都有提升,但两者协同才能达到最优效果——co-design 的价值不言而喻。
TokenFlow 这篇论文最打动我的地方,是它对”token buffer”这个平时被忽视的结构的洞察。大家都知道 LLM 生成比用户读快,但把这个速度差转化成调度的优化空间,需要一个跨越层次的系统思维。
Buffer-aware 调度 + Proactive KV cache 管理,这两个设计形成了一个自洽的闭环:调度器知道什么时候可以安全抢占(因为 buffer 里还有余量),KV cache 管理器提前把数据备好让抢占近乎无代价,两者协作,最终让”流式输出”真正流起来。
这个思路对做 LLM serving 的朋友很有参考价值——不只是优化单个请求的延迟,而是从整个 request burst 的角度来看资源分配和调度策略。下一步自然的延伸问题是:如果用户的阅读速率是动态变化的(比如暂停了 App),或者有不同 SLA 的混合请求,buffer-aware 策略该如何自适应调整?这应该是后续工作有意思的方向。