KV Cache 也能「语义共享」?SemShareKV 用 LSH 做到了
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

KV Cache 也能「语义共享」?SemShareKV 用 LSH 做到了
原文:SemShareKV: Efficient KVCache Sharing for Semantically Similar Prompts via Token-Level LSH Matching
1. 前言
你有没有想过,当两个用户几乎同时向 LLM 提问,一个问的是”请总结这篇关于气候变化的报道”,另一个问的是”帮我概括一下这篇气候危机的新闻”,服务器里会发生什么?
大概率:两份几乎一样的 KV cache 被从头算了两遍。
这件事搁在单用户场景里不算大问题,但现实中的 LLM 推理服务是高并发的——多文档摘要、对话系统、RAG 检索……同质化 prompt 批量打进来。KV cache 的内存占用和重复计算已经成了推理吞吐量的核心瓶颈之一。
现有的优化思路集中在两类:一是压缩单个 prompt 的 KV cache(比如 StreamingLLM、H2O 这些做 token 剪枝的),二是复用多个 prompt 之间共享的前缀(prefix caching)或频繁出现的文本片段。但这两类方案都有一个硬伤:只认”一模一样”的 token,认不出”意思相近”的 prompt。
IJCNLP-AACL 2025 Findings 的这篇工作 SemShareKV 做了一件有意思的事:把 KV cache 的复用从”精确匹配”扩展到了”语义匹配”——用 LSH(Locality-Sensitive Hashing)在 token embedding 级别做模糊匹配,让语义相似但措辞不同的 prompt 也能共享彼此的 KV cache。
今天想和大家聊聊这篇工作解决了什么真问题,以及它背后有哪些值得细品的设计。
2. 现有方案的局限
先说说 prefix caching 为什么不够用。
prefix caching 的逻辑很直接:如果两个 prompt 的开头部分 token 完全一致(比如 system prompt 一模一样),那这段的 KV cache 可以复用,不用重新计算。vLLM 的 automatic prefix caching 就是这个思路,工程上做得很成熟。
但现实场景里,语义相似的 prompt 往往在措辞上差异很大:
- “请总结这篇新闻” vs. “帮我概括一下这篇报道”
- 用户把同一篇文章换了个说法重新问一遍
- RAG 检索召回的文档块,内容重叠但 token 序列不同
这时候 prefix caching 完全失效,只能从头算。问题的本质是:现有的 cache 复用依赖于 token 级别的精确匹配,而”语义相似”和”字面相同”之间有一道鸿沟。
SemShareKV 要做的,就是跨过这道鸿沟。
3. 三个关键洞察
SemShareKV 能行得通,背后有三个实验观察作为支撑,我觉得这部分是全文最有意思的地方。
3.1 高偏差 token 的排名在不同层之间高度一致
如下图,作者统计了不同模型(LLaMA3.1-8B、Mistral-7B、MPT-7B)相邻层之间”偏差 token”排名的 Spearman 相关系数:
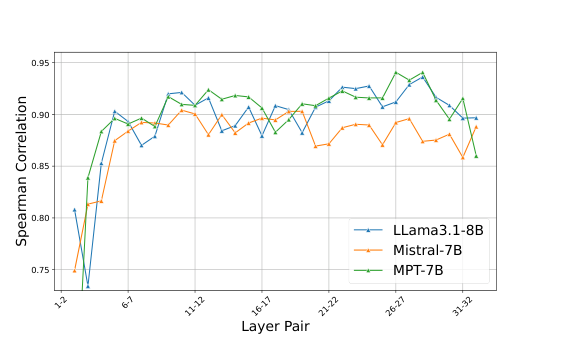
Spearman 相关系数普遍在 0.85 以上,中间层甚至接近 0.95。
这意味着什么?你只需要在浅层识别出”哪些 token 比较重要”,这个判断在深层依然成立。不用每一层都重新计算一遍重要性排序,省了大量 overhead。
3.2 越深的层关注的 token 越少
如下图,随着层深度增加,attention 实际上只集中在越来越少的 token 上:
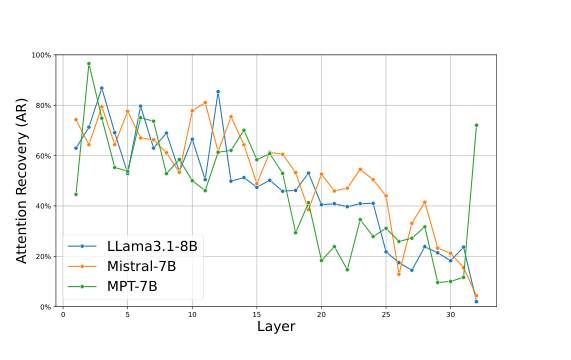
这个现象很多做 KV cache 压缩的工作都观察到过。深层的 attention 更”挑剔”,只盯着少数关键 token。这意味着深层的 KV cache 有更大的压缩空间。
3.3 越深的层包含越多冗余信息
如下图,作者测量了不同层 KV cache 的”冗余度”(相邻层之间的相似度):
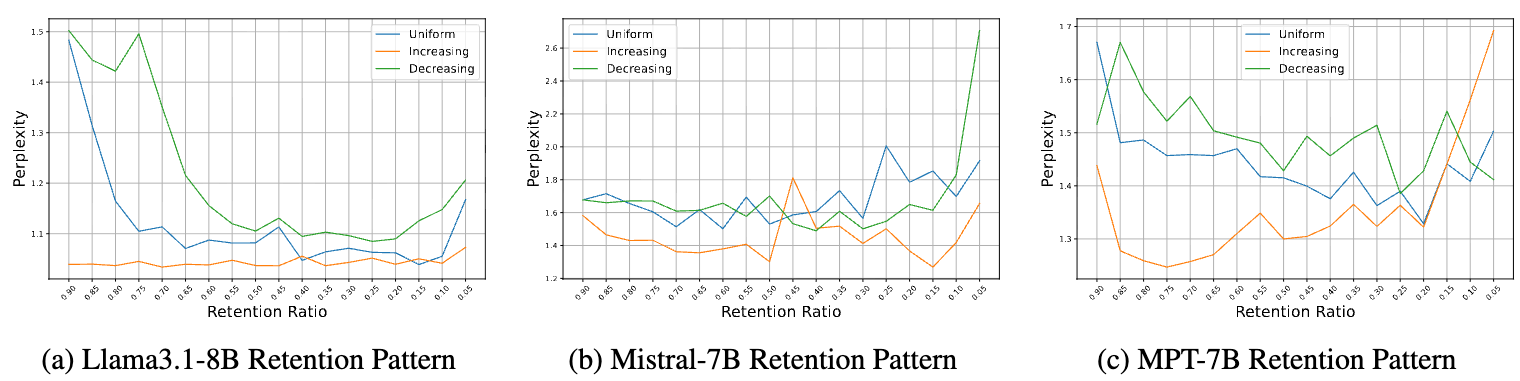
深层 KV cache 和上一层的差异越来越小,很多计算都是在做重复的事情。
把这三个洞察合在一起:重要 token 的集合是稳定的,深层关注更少的 token,深层信息更冗余。这给了 SemShareKV 一个操作空间:可以只复用”重要 token”对应的 KV cache,略去冗余部分,损失可控。
4. SemShareKV 怎么做
系统的整体流程如下图:
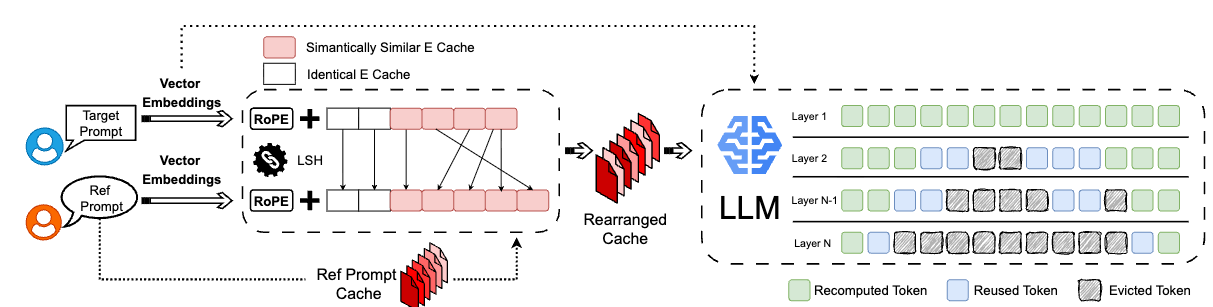
核心步骤分三块:LSH 模糊匹配、RoPE 的重新处理、KV cache 重排与复用。
4.1 LSH 做语义级别的 token 匹配
传统 prefix caching 用的是精确的 token ID 匹配。SemShareKV 换了个思路:在 token embedding 空间里做近似最近邻搜索,用 LSH 找到语义相近的 token 对。
具体做法:对每个 token,用 LSH 把它的 embedding 映射成一个 hash,语义相近的 token 有很高概率被映射到同一个 hash bucket 里。新 prompt 进来之后,先对所有 token 做 LSH 编码,和 cache 里已有的 reference prompt 的 token hash 做匹配,找出配对。
这样,即便新 prompt 和已缓存的 prompt 一个字都不一样,只要语义足够接近,对应的 token 就能被匹配上,KV cache 就能复用。
4.2 RoPE 的巧妙处理
这里有个工程上的坑——KV cache 复用时,位置信息怎么处理?
标准的 LLM 在生成 K 时会把 RoPE(Rotary Position Embedding)加进去,position encoding 是和 token 位置绑定的。如果直接把 reference prompt 的 K cache 搬过来用,位置信息就乱了——因为匹配上的 token 在两个 prompt 里位置不同。
SemShareKV 的解决方案如下图:
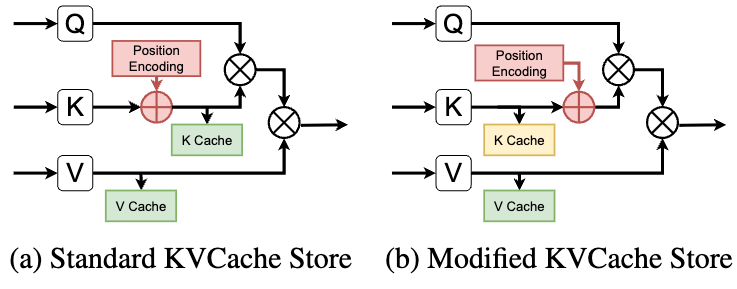
左边是标准流程:RoPE 在存入 cache 之前就已经加到 K 上了。右边是修改后的流程:K cache 里存的是加 RoPE 之前的原始 K 值,position encoding 单独存。
这样,复用 cache 时可以按照新 prompt 里的 token 位置重新应用 RoPE,而不是硬搬 reference prompt 的位置信息过来。位置准了,后续的 attention 计算才对。
4.3 KV cache 重排与复用
匹配完 token 之后,要做一次重排(Rearranged Cache):把 reference prompt 的 KV cache 按照匹配关系重新排列,让它对应到新 prompt 的 token 位置上。
匹配上的 token,直接复用重排后的 KV cache;没匹配上的 token,走正常的 attention 计算,重新算 KV。
核心收益就在这里:减少了需要重新计算的 token 数量,越相似的两个 prompt,复用率越高,省的算力越多。
5. 实验结果
5.1 质量:在多个摘要数据集上几乎无损
如下表,在 MultiNews、Wikihow、SAMSum、PubMed、BookSum、BigPatent、LCC 等 8 个摘要数据集上,分别用 Mistral-7B 和 LLaMA3.1-8B 做测试:
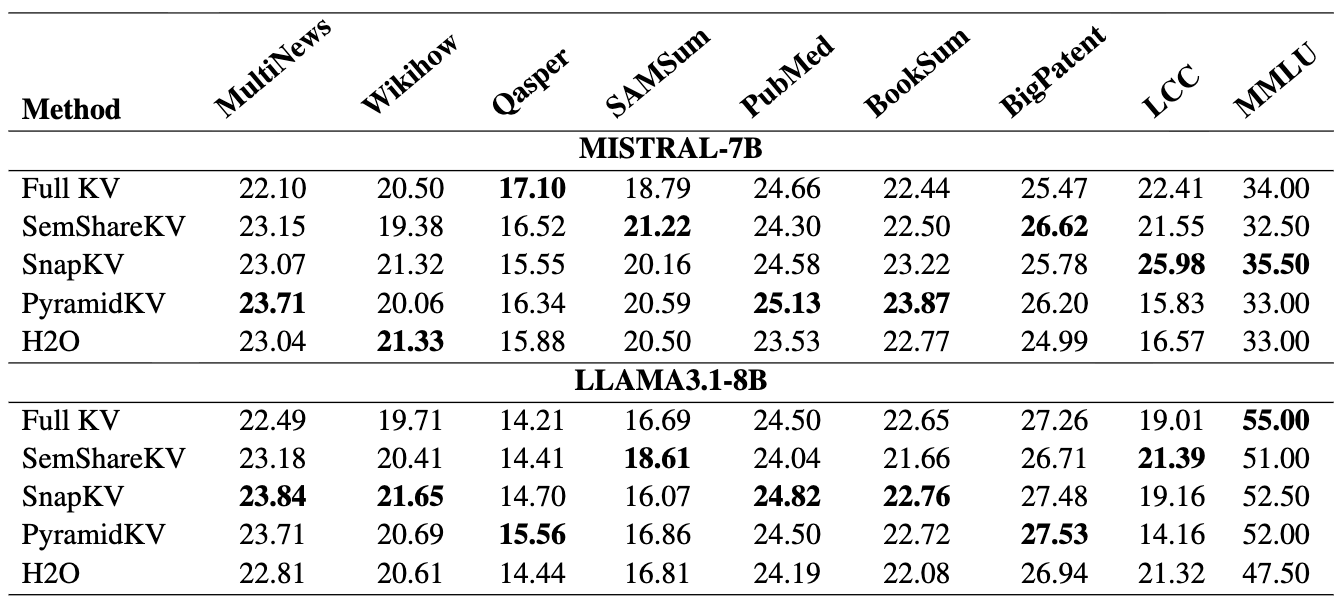
SemShareKV 在大多数数据集上的 ROUGE-L 和 baseline 相差不大,部分数据集甚至略有提升(匹配到的 KV cache 相当于引入了额外的”上下文信息”)。质量损失在可接受范围内。
5.2 效率:最高 6.25× 加速,42% 显存节省
这是最直接的收益。在 5k tokens 长输入场景下:
- 推理速度最高提升 6.25×
- GPU 显存使用减少 42%
数字不算夸张,但对于长文档摘要、高并发推理服务这类场景来说,这个量级的提升已经相当可观了。
5.3 Prompt 相似度的影响
如下图,不出意料,两个 prompt 越相似,匹配率越高,加速效果越好:
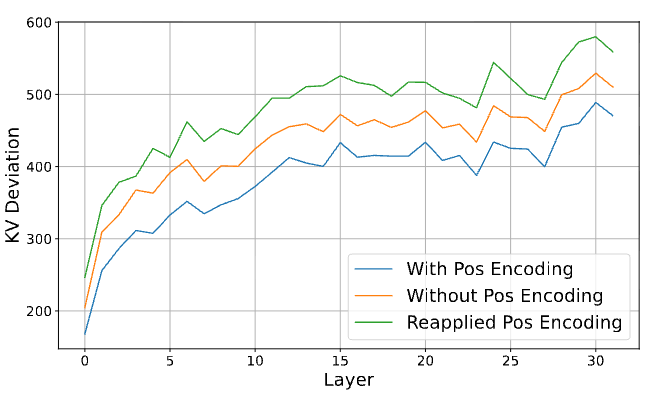
实线(Replacement,用 reference 的 KV 替换)和虚线(Elimination,直接删掉未匹配 token)相比,Replacement 策略在高替换比例下降得更慢——说明直接复用 KV 比暴力删 token 更温和。
5.4 消融实验
如下表,消融实验验证了三个设计选择的必要性:LSH 匹配、RoPE 处理方式、层级选择策略:
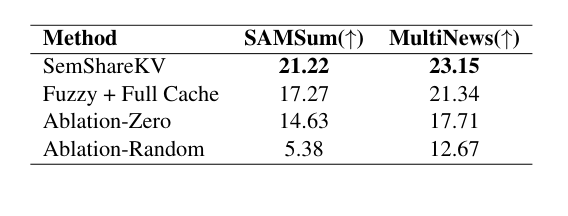
去掉任何一个组件,ROUGE-L 都有可见的下降。
6. 几点个人想法
这篇工作解决的场景非常实际——语义相似但 token 不同的 prompt 之间的 KV cache 复用,是 prefix caching 一直以来的盲区。用 LSH 做 token 级别的模糊匹配,这个方向本身很有意思,工程上也可以落地。
但也有几个地方值得继续打磨:
-
LSH 匹配本身有开销。对每个 token 做 hash 并查找 reference prompt,在高并发场景下也是一笔算力支出,文章里对这块的分析不够细。
-
Reference prompt 怎么选?当 cache 里积累了大量历史 prompt 后,如何快速找到最合适的 reference,是个工程上的检索问题,文章里没有深入讨论。
-
动态 prompt 场景的泛化能力。论文主要在摘要任务上测,摘要的 prompt 相似度天然偏高,泛化到其他场景(比如代码生成、多轮对话)效果如何,需要更多验证。
总体来说,这是一篇方向清晰、动机充分的工程论文,把”语义级别的 KV cache 共享”这个想法走通了。KV cache 优化这个方向还有很大空间,期待后续有更多工作在”跨请求复用”上继续挖。
欢迎评论区交流,有问题也可以指出来哈哈。