把 Dense LLM 变成 MoE 还能推理提速?NeurIPS 2024 Read-ME 做到了
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

把 Dense LLM 变成 MoE 还能推理提速?NeurIPS 2024 Read-ME 做到了
原文:Read-ME: Refactorizing LLMs as Router-Decoupled Mixture of Experts with System Co-Design
1. 前言
做 MoE 推理优化的牛马应该对这个场景不陌生:
你好不容易把 Mixtral-8x7B 或者 DeepSeek-MoE 部署起来,满心期待地等着”稀疏激活带来的效率红利”落地,结果一跑推理,GPU 显存占用跟 dense 模型差不了多少,延迟也没降多少。
为什么?
因为MoE 的优势是推理时只激活少数 expert,但落地被”全量加载 + 低效调度”的系统设计给卡死了。
这也是整个 MoE 推理领域的核心矛盾之一:模型架构设计和系统推理策略之间的脱节。
今天想聊的这篇 Read-ME(NeurIPS 2024)正面刚了这个问题,而且是从算法和系统两侧同时动刀——它不只是在模型结构上做文章,而是提出了一套 algorithm-system co-design 的框架,实现了在更小规模下更好的精度,同时端到端延迟也降下来了。
2. 问题出在哪
先交代下背景,MoE 落地有两个经典难题:
第一个:从头训练 MoE 太贵了。
Mixtral、DeepSeek 这些模型,要么是专门设计的 MoE 架构从头预训练,要么是对已有 dense 模型做 “upcycling”(把 dense FFN 直接复制成多个 expert,再继续训练)。无论哪条路,都要消耗海量 token。
第二个:传统 layer-wise router 设计在系统层面效率很差。
这是 Read-ME 真正重点解决的问题。
现在主流 MoE(Mixtral、OpenMoE 等)的 router 是 layer-wise 的:每一层都有独立的 router,每层的 expert 选择要等上一层的 hidden state 出来之后才能决定。这带来两个直接的系统问题:
-
没法提前 prefetch expert:expert 权重可能分散在不同 GPU/机器上,等到运行时才决定要哪个 expert,来不及预加载,要么 OOM 全加载,要么边算边取等 I/O。
-
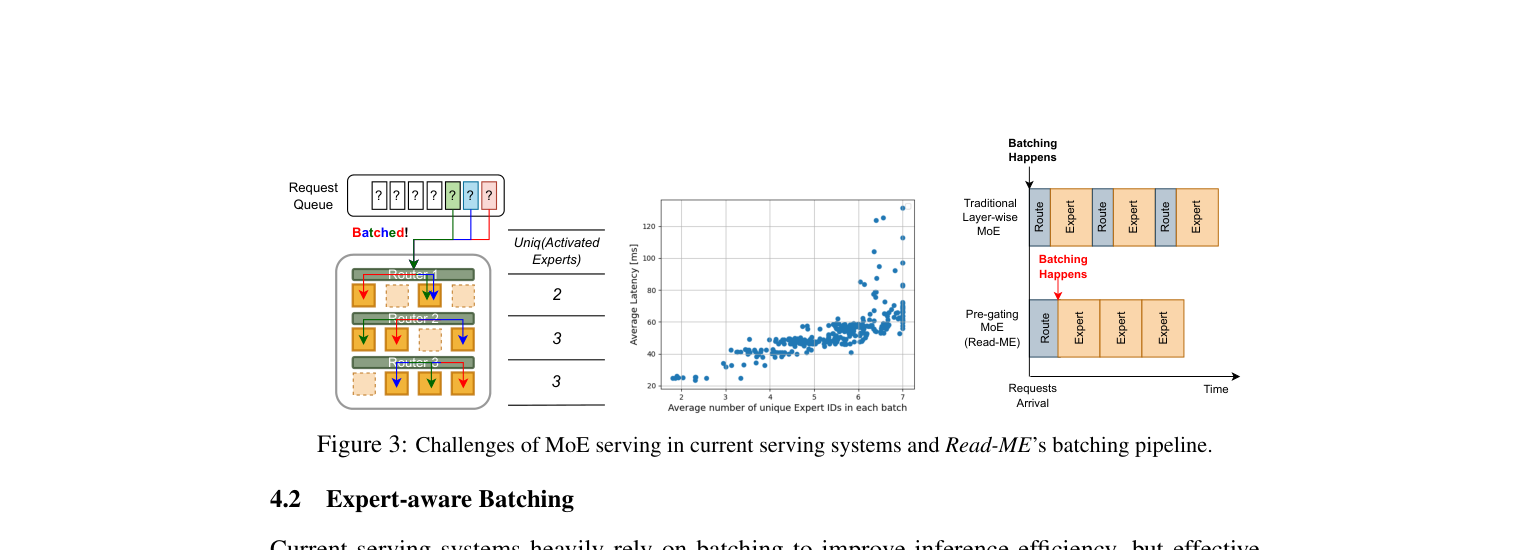
batching 效率极差:一个 batch 里不同 token 需要不同 expert,GPU 利用率拉稀。这里有个很离谱的数据:Mixtral-8x7B 在 batch size 为 56.8 时,平均每层激活的 unique expert 数量是 7.63 个(总共才 8 个)——等于说稀疏激活的优势几乎全丢了。
如下图右边的散点图,unique expert 数量和平均延迟几乎线性相关——expert 越分散,latency 越高。左边展示了 batching 困境:同一个 batch 里每个 token 走的 expert 路径都不同,系统调度根本没法做优化:
3. Read-ME 的核心 idea
Read-ME 的框架如下图所示:左半部分是算法侧,把预训练好的 dense 模型(黄色)”重构”成两个稀疏 expert(红/绿),并训练一个轻量 pre-gating router;右半部分是系统侧,利用 pre-gating 在请求到达时就预先分配 expert,实现 expert-aware batching:
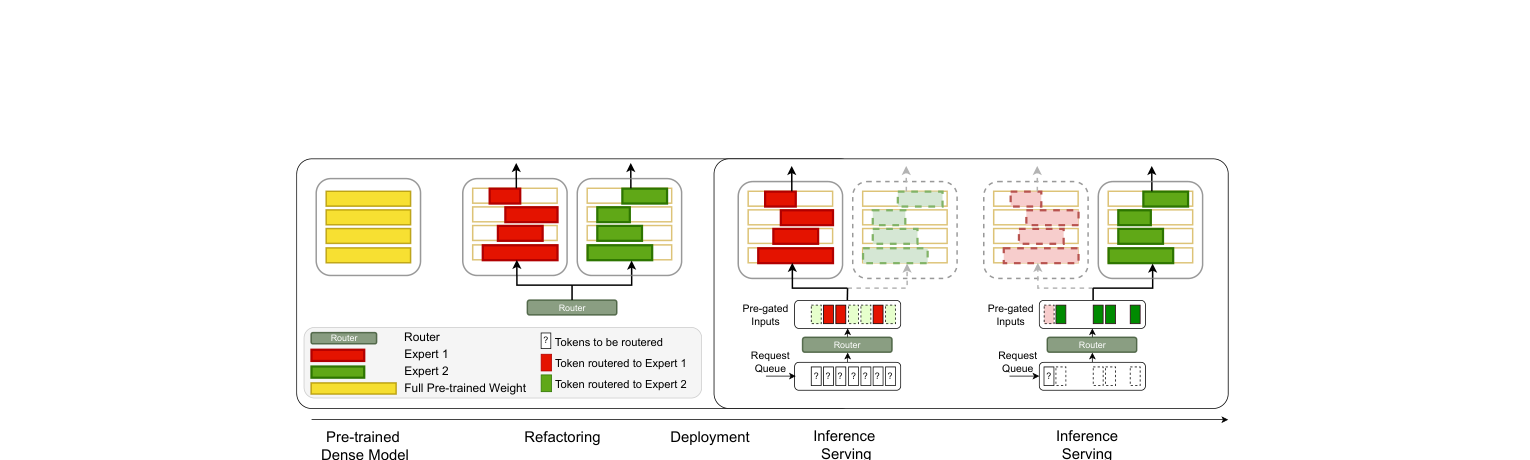
3.1 算法侧:从 Dense 提 Expert,再解耦 Router
Read-ME 首先在 Llama-2-7B-chat 这类预训练 dense 模型上做 MoE 化,不从头训练,只用 1B tokens 做 continual tuning,代价极小。
具体是怎么提取 expert 的?基于激活稀疏性(activation sparsity)。Dense LLM 里的 FFN,不同数据域对应的激活 channel 是不同的(科学文章、小说、代码、QA 各自激活不同的神经元),把这些”domain-specific”的 channel 组合成独立的 expert,就得到了领域对齐的 MoE 结构——本质是在 activation magnitude 上做 top-k channel 选择,再用 mask 矩阵把 FFN 参数切分成 N 个 expert。
这个思路其实和 NAS 领域的 once-for-all 网络有点像:都是在一个共享的参数空间里,通过动态 mask 选出不同的”子网络”来执行不同任务。这种方式在训练 / fine-tune 数据集上效果可以做得不错,但 mask 的划分是基于这批数据的激活统计,能否在 distribution 差异较大的其他数据集上保持同等性能,是个值得警惕的问题。相比之下,直接在预训练好的原生 MoE(如 Mixtral、DeepSeek-MoE)上做推理优化,模型能力的上限和泛化性是原厂保证的,更有工程落地的确定性——我们自己的工作 ExpertFlow [1] 就走的这条路。
关键创新在 router 设计。
作者发现了一个很有意思的现象:相邻层之间的 expert 选择高度相关。如下图(a)所示,Mixtral-8x7B 第 30、31 层之间的转移矩阵几乎是行稀疏的——每行只有少数几个非零项,说明”知道第 30 层选了哪个 expert,第 31 层几乎就确定了”。图(b)的 mutual information 曲线也印证了这一点:相邻层之间的 MI 明显高于条件独立的基线。图(c)是对应的 router 蒸馏训练方案:
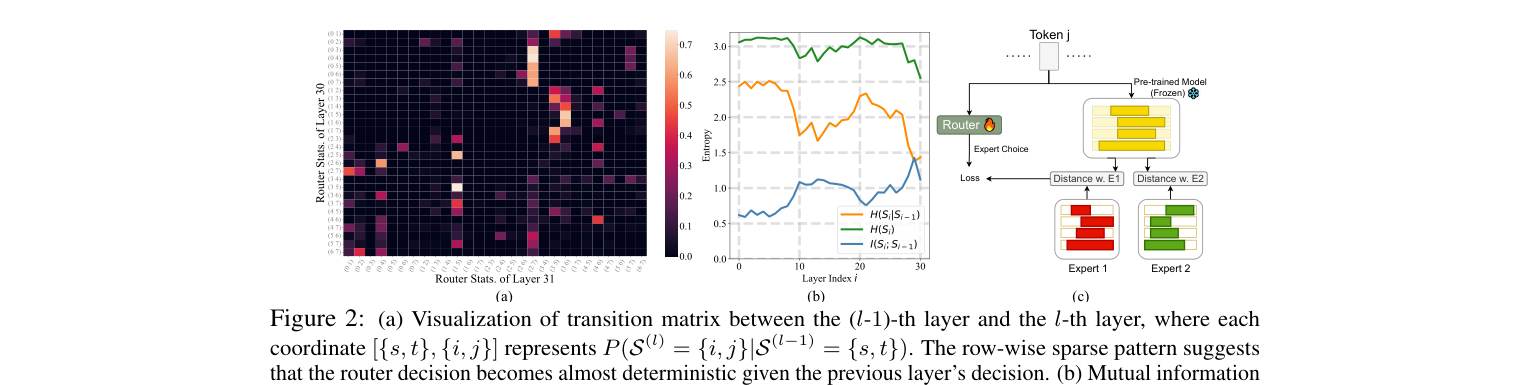
这意味着什么?Layer-wise router 大量在做重复工作,完全可以用一个统一的 router 在推理最开始就预测所有层的 expert 选择。
Read-ME 把这个 router 叫做 pre-gating router,它和 MoE backbone 完全解耦。结构很简单:一个 1-layer transformer block,只有 18M 参数(可以忽略不计的 overhead)。它在 token 进入 MoE 之前就跑完,一次性输出所有层的 expert 路由决策。训练时用 routing distillation loss(KL 散度)对齐原始模型的激活稀疏模式,监督信号非常自然。
3.2 系统侧:Pre-gating 带来的三个优化
有了 pre-gating router,推理系统可以做三件事:
① Fine-grained Expert Prefetching
知道了接下来要用哪些 expert,就能把加载 expert 权重和当前层的 forward pass 完全 overlap 起来——算第 i 层的同时,后台异步加载第 i+1 层需要的 expert,完全 hide I/O latency。
② Belady-inspired Expert Caching
这里先简单交代一下为什么需要 expert cache。
MoE 模型的参数量往往比 dense 模型大很多(比如 Mixtral-8x7B 总参数 47B,但每次推理只激活约 13B),在 GPU 显存有限的情况下,根本没法把所有 expert 都常驻显存。常见的做法是 offload 到 CPU 内存或 NVMe,推理时按需加载(on-demand loading)。这就引出了一个问题:哪些 expert 应该留在 GPU 显存里(”热缓存”),哪些 expert 应该被换出去?
这就是 expert cache 的问题。最朴素的策略是 LRU(最近最少使用),但 LRU 是基于历史的,并不知道”接下来要用哪个 expert”。
Read-ME 的做法是利用 pre-gating router 的预测能力,直接实现 Belady 算法。Belady 的逻辑很简单:当 cache 满了需要淘汰某个 expert 时,驱逐”未来最晚被再次访问到”的那个——这在理论上是最优的 cache 替换策略。它的问题是在普通场景里你不知道”未来”,是个离线算法。
而有了 pre-gating,你恰好知道当前 batch 里每个 token 接下来要走哪些 expert。“未来访问序列”从未知变成了已知,Belady 算法就可以直接在线跑了。论文也在理论上证明了在 pre-gating 框架下这个 caching 策略是 provably optimal 的——这个理论保证在工程实践里相当加分。
③ Expert-aware Batching
Pre-gating 让系统在 batch 组建时就知道每个 token 要用哪些 expert,可以把激活相同 expert 的 token 放同一个 batch,从根本上减少每个 batch 里 unique expert 的数量。
如下图对比了两种 pipeline:传统 layer-wise MoE(上)每个 token 各走自己的 route,batching 完全没有 locality 可利用;Read-ME(下)在请求到达时就做 expert-aware 分批,Expert 计算可以高效合并:
具体怎么合并?对于进入系统的多个请求,pre-gating 先跑一遍,拿到每个 token 在每一层对应的 expert ID,然后在 scheduler 层面按 expert 亲和性重新分组——把要用同一批 expert 的 token 打包成一个 mini-batch,这样一个 expert forward 可以同时服务多个 token,计算利用率大幅提升。
顺带一提,我们自己的工作 ExpertFlow [1] 也有类似的思路,区别在于我们是在一个 batch 内部用 k-means token scheduler 对 token 做重组:按照 token 的 expert 激活向量做聚类,把同 cluster 的 token 组成 mini-batch,目标同样是降低每个 mini-batch 内 unique expert 的数量、提高单个 expert 计算时服务的 token 数。两者目的一致,但 Read-ME 是在请求调度层做,ExpertFlow 是在 batch 内重排做,两个维度可以互补。
4. 效果怎么样
4.1 模型质量
用 Llama-2-7B-chat 做 base,Read-ME 模型 activated parameters 为 4.7B(总参数 17B),训练代价只用了 1B tokens。如下表,和各类 baseline 的综合对比:
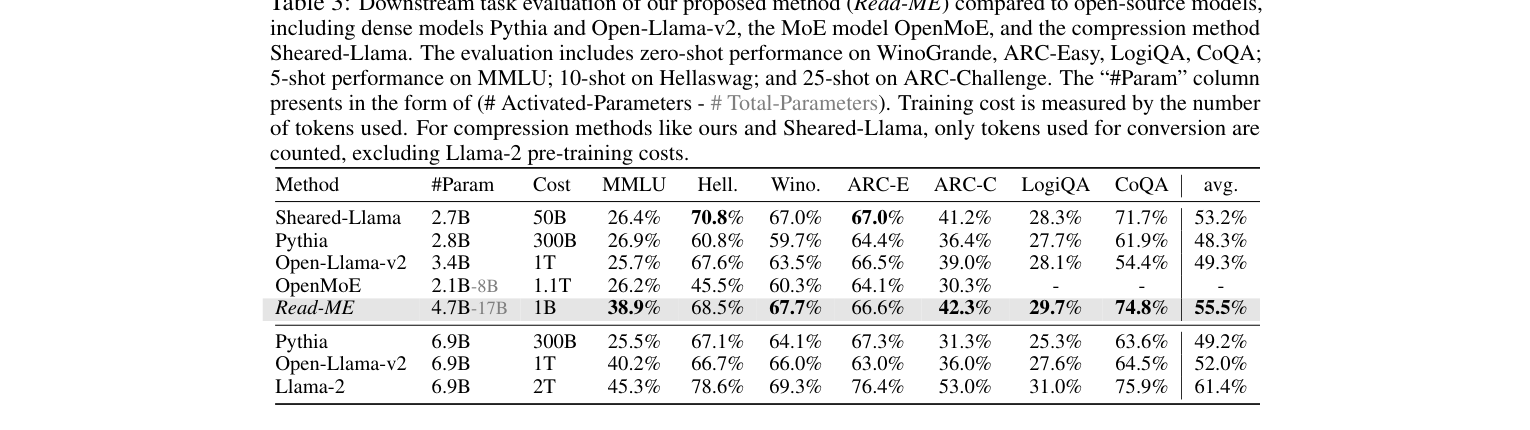
Read-ME 在 MMLU 上达到 38.9%,综合 avg 达到 55.5%,显著领先同规模的所有 baseline——而对面的 Pythia 用了 300B tokens,Open-Llama-v2 用了 1T tokens,Read-ME 只用 1B tokens 就超过了它们。
本质上还是 Llama-2-7B-chat 预训练带来的底子,continual tuning 只是把 dense 知识迁移到 MoE 结构。
如下散点图更直观地展示了 Read-ME 在”MMLU performance vs activated parameters”维度上的位置——相比同等参数量的对手,它处于 Pareto frontier 之上(只有 Llama-2-7B 这种大模型才能超过它,而 Llama-2-7B 激活参数量是它的 1.5 倍):
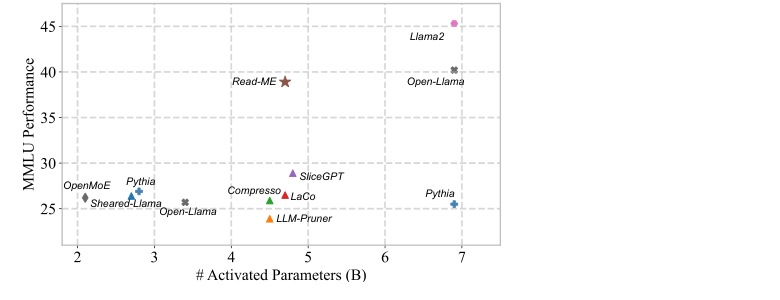
(细思极恐:Open-Llama-v2 用 1T tokens 才训到 25.7% MMLU,Read-ME 1B tokens 就做到 38.9%……这就是 pretrain-then-convert 的威力。)
4.2 推理速度
如下图展示了三组实验:左图是单次 124 token 生成任务的 latency 分解(OpenMoE / Llama2-7b / Read-ME),Read-ME 的 Expert/MLP 耗时明显更短;中图是 batched inference 场景下的 p95 latency 分布,Read-ME 的分布更集中且整体更低;右图展示了 temporal locality 分析——Read-ME 的 router 让同序列内 token 倾向于选相同 expert(2921 个 token 跟随上一个 token 的选择 vs Mixtral 的 850 个),这进一步降低 unique expert 的切换开销:
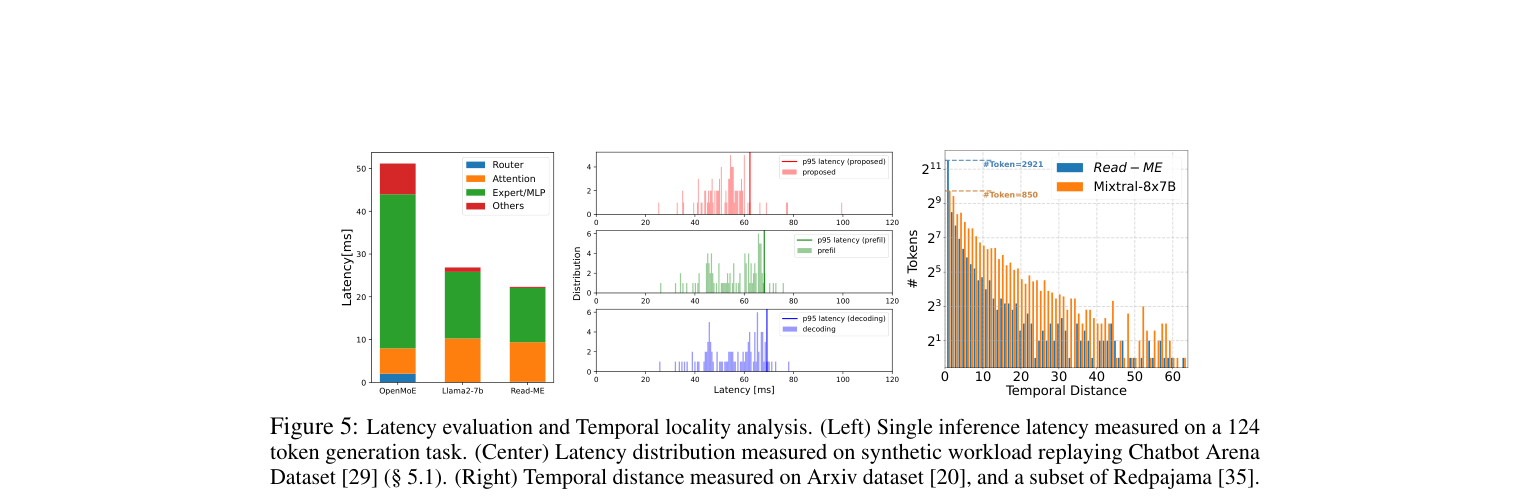
综合下来:平均 end-to-end latency 降低 6.1%,tail latency(p95)改善 9.5-10.0%。
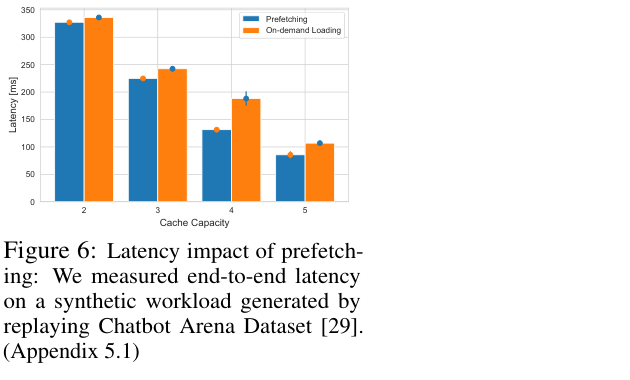
在内存受限场景(只缓存 k 个 expert)下,expert prefetching 的效果如下图——在所有 cache capacity 设置下,蓝色(Prefetching)都比橙色(On-demand Loading)有稳定优势,cache capacity 越小时差距越大,最多 30% 的 latency 节省:
5. 我的一些看法
这篇工作让我觉得最有意思的地方,不是最终数字,而是那个关于层间 router 冗余性的观察。
大家做 MoE 时候默认每层都需要独立的 router,没人细想过这个设计是不是多余的。Read-ME 用转移矩阵和 mutual information 两个角度说话,发现相邻层 router 的决策几乎是确定性的,layer-wise 设计是过设计(overdesign)。
这个 insight 的迁移价值很高:如果我们在一开始就设计 MoE 架构(而不是从 dense 转换),是不是也可以考虑 shared router?参数量少了,推理也更友好。这是个值得跟进的方向。
另外值得注意的是,这套框架的前提是”从预训练 dense 模型转换 MoE”,且需要原始模型本身有足够强的激活稀疏性,才能做出质量够好的 expert 划分。如果原始模型的 FFN 激活很稠密,这条路可能就走不通。而且把 dense FFN 按 domain 切分成 expert,类似 once-for-all NAS 的思路,mask 划分基于训练数据的激活统计,能否在 distribution 差异较大的下游任务上保持性能,是个需要认真对待的风险。这也是我们在 ExpertFlow [1] 里选择直接在原生 MoE 上做推理优化(而非模型重构)的原因之一——原生 MoE 的能力边界和泛化性是原厂保证的,推理优化不损失模型本身的能力。
不管怎样,algorithm-system co-design 这个思路是对的——光在模型架构上优化,忽视系统层面适配,落地效果必然打折。Read-ME 这篇给出了一个完整的闭环方案,理论上证明了 caching 最优性,工程上也量化了每个优化模块的贡献,是那种”可以直接参考来设计自己系统”的工作。
欢迎评论区交流,有 MoE 推理踩坑经历的也欢迎来聊。
References
[1] ExpertFlow: Optimized Expert Activation and Token Allocation for Efficient Mixture-of-Experts Inference (DAC 2026)