进阶篇 | 不靠人工设计,让遗传算法自己进化出 SOTA 的 LLM 剪枝指标
进阶篇 | 不靠人工设计,让遗传算法自己进化出 SOTA 的 LLM 剪枝指标
插播:以下内容节选自我们团队最近出版的书籍《动手学 AutoML:从 NAS 到大模型优化实战》,感兴趣的朋友可以前往 jd 搜索购买,感谢支持 https://item.jd.com/15384990.html

在上一篇《说人话:一文搞懂现在火热的 LLM agent 自进化原理》里,我们用 LLM agent「自进化」当引子,把进化算法的基本原理捋了一遍——「选择—变异—保留」这套循环,搜的对象可以是网络结构、也可以是 agent 的 prompt 和工具链。
但那篇基本还停留在「原理」层面。这篇我想上点强度,给你看一个真正进阶的应用——让进化算法自己「进化」出一个数学公式,而且这个公式比人类专家手工设计的还要好。
具体场景是 LLM 剪枝。结论先放这:用遗传编程自动搜出来的剪枝指标(这个工作叫 Pruner-Zero),在 LLaMA / LLaMA-2 全系列上、多种稀疏度配置下,困惑度全面低于 Magnitude、SparseGPT、Wanda 这些主流方法,而且全程不需要更新权重。
这就是我想让你看到的——AutoML 不只是「调调超参」,它真的能把「人类专家做设计」这件事自动化掉。
不背公式,从问题出发。
1. 先说问题:LLM 剪枝,卡在哪
剪枝(pruning)这事不新鲜:把神经网络里那些「可有可无」的权重干掉,模型变小、推理变快。GPT-3 有 1750 亿参数,光存下来就够呛,剪枝的价值不言而喻。
但 LLM 把这事的难度抬高了一截。传统 CNN 剪完可以重训一遍把精度找回来;LLM 你重训一次试试?光算力就劝退。所以 LLM 这边主流走的是后训练剪枝(Post-Training Pruning, PTP)——剪完不重训,直接就能用。
PTP 的核心,是一个剪枝指标(pruning metric):给每个权重打个分,分低的就是「不重要」,剪掉。问题在于,这个打分公式到现在都是人手工设计的。下面这张表是几个主流方法用的指标:
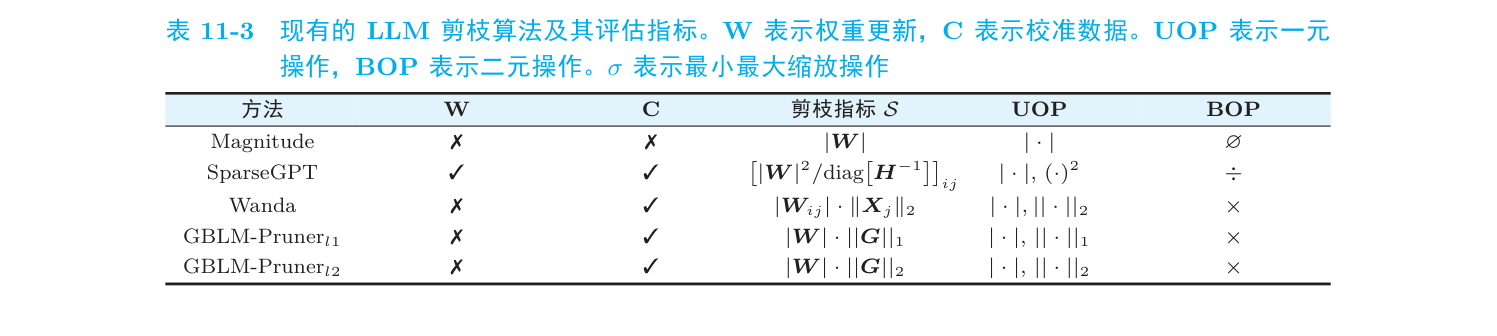 (节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 11 章 表 11-3)
(节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 11 章 表 11-3)
你看:
-
Magnitude:最朴素,就看权重绝对值 $ W $,小的剪掉。 -
Wanda:聪明一点,权重幅值 × 输入激活的范数,$ W_{ij} \cdot |X_j|_2$。 - SparseGPT:再复杂点,还要算海森矩阵的逆。
这些公式都是人琢磨出来的,背后是大量的经验和试错。这就引出一个很自然的问题:
凭什么这些公式就是最优的?能不能让算法自己去找一个更好的?
2. 关键转念:把「找公式」变成一个进化问题
这一步是整个工作里我最喜欢的地方。
仔细看上面那些指标,它们其实都是同一类东西:拿几个基本输入(权重 W、梯度 G、激活 X),做一堆数学运算组合出来的表达式。比如 Wanda 就是「W 取绝对值,X 取范数,俩乘起来」。
那「找最优剪枝指标」这件事,就可以重新表述成:在所有合法的数学表达式里,搜一个打分最准的出来。这在学术上叫符号回归(Symbolic Regression)。
| 而任何一个数学表达式,都能画成一棵表达式树——叶节点是输入变量(W / G / X),内部节点是运算符(加减乘除、取绝对值、平方、归一化……)。比如 $ | W | \cdot |G|_1$ 就是一棵很小的树。 |
到这一步,事情就和上一篇接上了:搜索对象从「网络结构」换成了「一棵表达式树」,但「选择—变异—保留」那套机器原封不动。专门搜表达式树的进化算法有个名字,叫遗传编程(Genetic Programming),它就是上一篇进化算法的近亲。整个流程长这样:
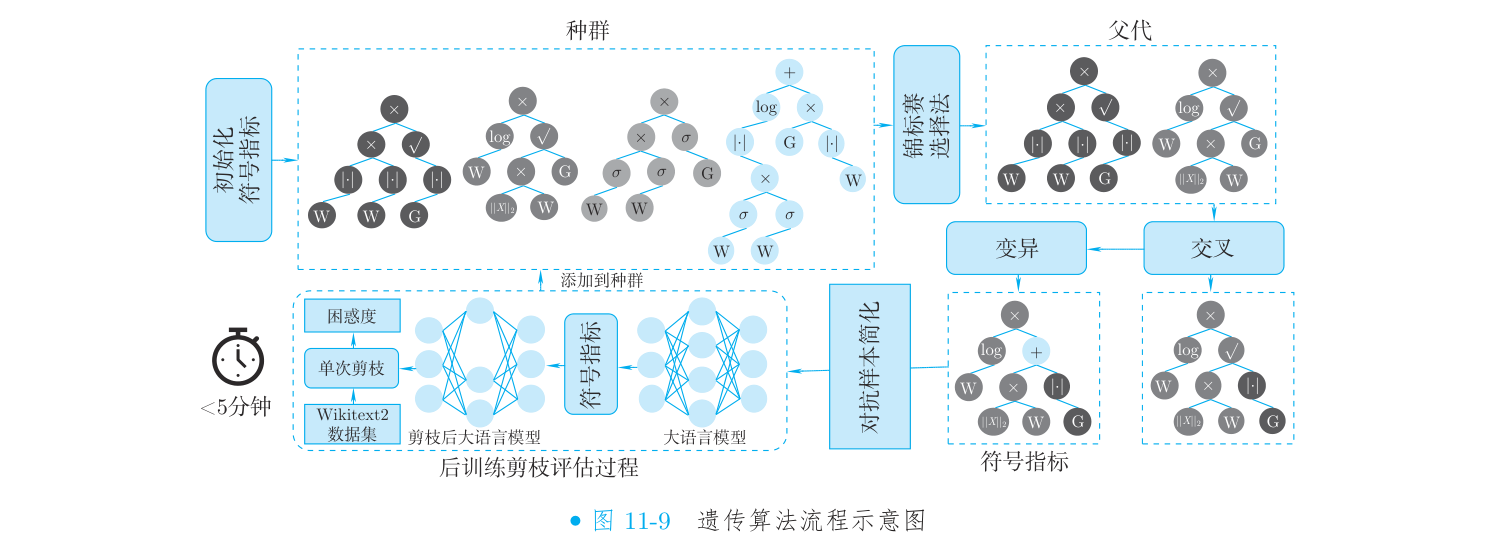 (节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 11 章 图 11-9)
(节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 11 章 图 11-9)
- 个体 = 一棵表达式树(一个候选剪枝指标)
- 变异 = 随机改一个节点、或换掉一棵子树
- 交叉 = 两棵树互换子树
- 适应度 = 用这个指标去剪枝,剪完模型的困惑度(越低越好)
- 选择 = 留下困惑度低的那批
下面就把这几块拆开看代码。
3. 怎么把一个「公式」编码成能进化的个体
先定义搜索空间——也就是「允许用哪些积木」。终端集是三种基本输入,函数集是一堆数学运算:
# 单目函数:平方、取负、绝对值、对数、指数、平方根、tanh、幂、跳过、最小最大归一化、Z-score 标准化
UNARY_FUNCTIONS = [sqr, neg, abs, log, exp, sqrt, tanh, pow, skp, mms, zsn]
# 双目函数:加减乘除
BINARY_FUNCTIONS = [add, sub, mul, div]
FUNCTIONS = UNARY_FUNCTIONS + BINARY_FUNCTIONS
# 终端节点:权重 W、梯度 G、激活 X
TERMINALS = ['W', 'G', 'X']
然后用一棵二叉树来表示表达式,每个节点要么是运算、要么是输入:
class GPTree:
def __init__(self, data=None, left=None, right=None):
self.data = data # 运算符 或 终端符号(W/G/X)
self.left = left # 左子树
self.right = right # 右子树
这棵树怎么「算出一个分数」?递归求值就行——碰到运算符就往下递归算子树,碰到 W/G/X 就返回对应的张量:
def compute_tree(self, W, G, X):
if self.data in FUNCTIONS:
if self.data in UNARY_FUNCTIONS: # 单目:只算左子树
return self.data(self.left.compute_tree(W, G, X))
else: # 双目:左右子树都算
return self.data(self.left.compute_tree(W, G, X),
self.right.compute_tree(W, G, X))
elif self.data == 'W': return W
elif self.data == 'G': return G
elif self.data == 'X': return X
变异和交叉就是直接在树上动刀,和上一篇 NAS 里的树结构编码是一模一样的套路:
def mutation(self):
if random() < PROB_MUTATION:
self.random_tree(grow=True, max_depth=2) # 随机长一棵新子树替换掉当前节点
elif self.left:
self.left.mutation() # 否则递归往下变异
def crossover(self, other):
if random() < XO_RATE:
second = other.scan_tree([randint(1, other.size())], None) # 在对方树里随机选一棵子树
self.scan_tree([randint(1, self.size())], second) # 换到自己树上
是不是很眼熟。换汤不换药——只是这次进化的「基因」是一段数学表达式。
4. 适应度:怎么判断一个公式「好不好」
进化算法里最贵、也最关键的一步永远是适应度评估。这里的逻辑很直接:拿这棵树算出来的分数去真剪一遍模型,再看剪完的困惑度(perplexity):
def evaluate_fitness(self, model, calibration_data):
self.fitness_scores = []
for individual in self.population:
# 1. 用这棵表达式树算出每个权重的重要性分数
pruning_scores = individual.compute_tree(
model.weight_matrix, model.gradient_info, calibration_data)
# 2. 按目标稀疏度剪枝
pruned_model = apply_pruning(model, pruning_scores, sparsity=0.5)
# 3. 评估剪完的性能(困惑度,越低越好)
performance = evaluate_model(pruned_model)
self.fitness_scores.append(performance)
选择用的是锦标赛选择——随机抓几个出来 PK,谁困惑度低谁赢,简单又不容易被「超级个体」垄断:
def tournament_selection(self):
tournament = random.sample(
list(zip(self.population, self.fitness_scores)), self.tournament_size)
winner = min(tournament, key=lambda x: x[1]) # 最小化困惑度
return winner[0].copy()
主循环就是标准的进化流程,加了个精英保留(每代留住最好的 10% 不让它丢):
def evolve(self, generations=50):
self.initialize()
for gen in range(generations):
self.evaluate_fitness()
# 精英保留:top 10% 直接进下一代
elite_size = int(0.1 * self.pop_size)
elites = sorted(zip(self.population, self.fitness_scores),
key=lambda x: x[1])[:elite_size]
new_population = [e[0] for e in elites]
# 其余通过 选择→交叉→变异 生成
while len(new_population) < self.pop_size:
p1, p2 = self.tournament_selection(), self.tournament_selection()
child1, child2 = p1.copy(), p2.copy()
if random.random() < CROSSOVER_RATE:
child1.crossover(child2)
child1.mutation(); child2.mutation()
new_population.extend([child1, child2])
self.population = new_population[:self.pop_size]
种群 100、跑 50 代、交叉率 0.8、变异率 0.1——这套参数下来,算法就开始自己「卷」剪枝公式了。
5. 进化出来的东西,到底有多猛
跑完之后,先看硬指标。下面是不同方法在 WikiText-2 上的困惑度对比(数字越低越好):
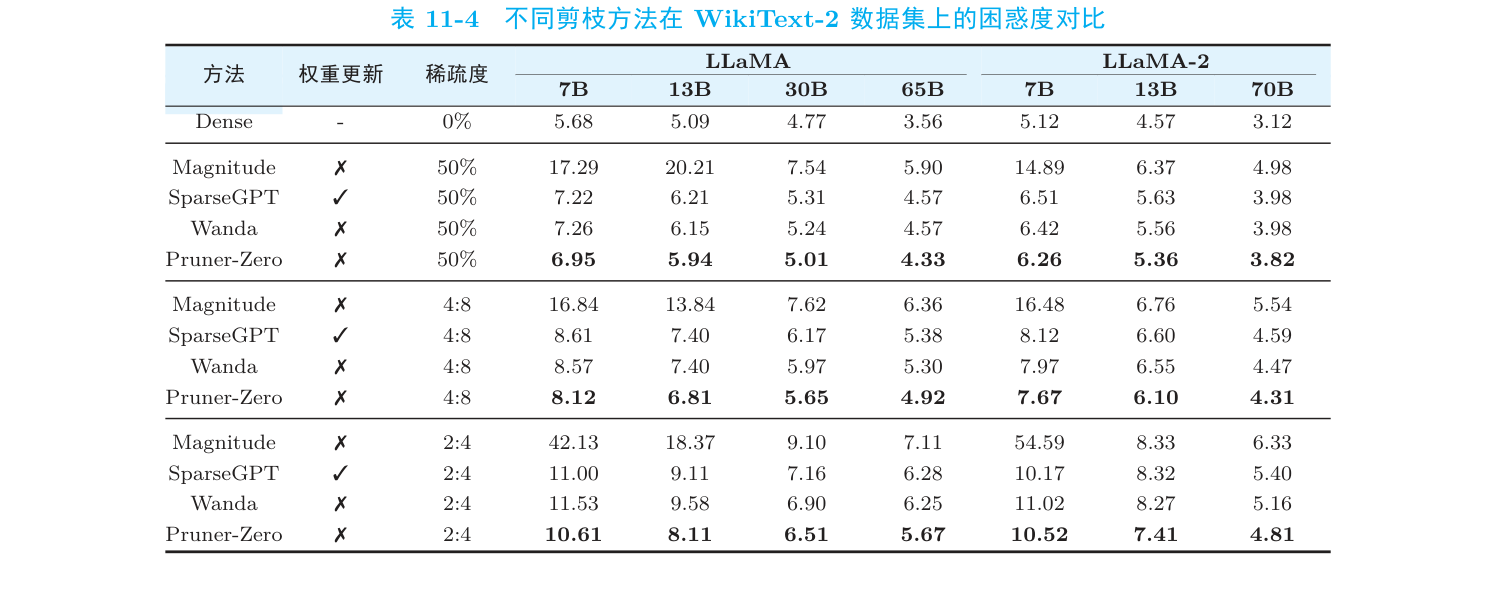 (节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 11 章 表 11-4)
(节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 11 章 表 11-4)
挑几个数说话(LLaMA-7B,50% 稀疏度):
- Dense(不剪):5.68
- Magnitude:17.29(崩了)
- SparseGPT:7.22
- Wanda:7.26
- Pruner-Zero:6.95 ✅
在最难的 2:4 稀疏模式下,Pruner-Zero(10.61)对 Wanda(11.53)、SparseGPT(11.00)的优势还更明显。而且它和 Wanda 一样不需要更新权重——SparseGPT 那套算海森矩阵的重活全省了。从 7B 到 70B 都稳定领先。
那它到底进化出了个什么公式?这是搜索过程中冒出来的一批表达式和对应困惑度:
 (节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 11 章 表 11-5)
(节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 11 章 表 11-5)
最后的最优解长这样:
\[((((W \cdot W)\ \text{abs})\ \text{mul}\ (G\ \text{mms}))\ \text{sqr})\]说人话就是:权重平方 → 取绝对值 → 乘上「归一化后的梯度」→ 再平方,困惑度做到了 6.70798。这个组合,说实话没几个人会手工去这么设计。
更有意思的是,把所有高分表达式扒一遍,能看到一些共性规律:
- 几乎都同时用了权重 W 和梯度 G——单看权重不够,得融合多维信息;
- 偏爱用乘法(mul)做融合,而不是简单相加;
- 高频出现非线性变换(abs、sqr、pow),对异常值更鲁棒;
- 爱配归一化(mms),让不同尺度的量能合理地揉到一起。
这些「经验」不是人总结出来塞给算法的,是算法自己在几千次试错里进化出来的。回过头看,它甚至帮我们理解了「一个好的剪枝指标应该长什么样」。
6. 写在最后
把这两篇连起来看,我想说的其实是一条线:
进化算法那套「选择—变异—保留」,威力远不止「搜个网络结构」。 这一篇里,它进化的对象是一个数学公式——把「设计剪枝指标」这种过去只有资深研究员才玩得转的活,变成了一个算法自动跑出来的结果,效果还反超人工。
这也是我一直觉得 AutoML 被低估的地方:它真正想干的,是把人在「试错、调参、做设计」上耗掉的脑力,尽可能自动化掉。从搜网络结构、搜超参,到这里搜一个公式,再到现在大火的 LLM agent 自进化——底层都是同一台机器。你把这台机器吃透了,再看那些新名词,会发现它们只是换了个搜索空间而已。
下一篇大概会聊聊把这套思路用到「自动搜索损失函数」上——也是一棵树,也是进化,挺好玩的。
以上内容(剪枝指标分析、符号树 / 遗传编程实现、Pruner-Zero 的搜索与实验结果)节选自我写的《动手学 AutoML:从 NAS 到大语言模型优化实战》(机械工业出版社)。书里从 NAS 各大范式、超参优化,到 LLM 时代的量化剪枝都有覆盖,每个概念都尽量配了可运行的代码而不是 toy demo。有需要的同学可以前往京东搜索书名,或复制下方完整链接购买,感谢支持:
https://item.jd.com/15384990.html
照例,欢迎评论区聊——包括书里写得不清楚的地方,都可以直接来问。

- 作者:marsggbo,新加坡 A*STAR CFAR 研究员
- 小红书 / 知乎 / GitHub: marsggbo