EuroSys'26 | PARD 提前丢掉注定超时的请求,goodput 最高提升 176%
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

EuroSys’26 | PARD 提前丢掉注定超时的请求,goodput 最高提升 176%
原文:PARD: Enhancing Goodput for Inference Pipeline via Proactive Request Dropping
1. 前言
你有没有遇到过这种系统设计问题:请求太多时,到底该不该 drop request?
直觉上,drop request 肯定是坏事。请求都丢了,goodput 怎么可能更高?但在 latency-sensitive inference pipeline 里,这个直觉经常会错。因为有些请求即使不丢,也已经注定超时;它们继续占用 GPU,只会拖累后面的请求,最后大家一起 miss SLO。
PARD 这篇 EuroSys 2026 的工作讲的就是这个问题。它的核心观点很直接:
请求不是越晚丢越好。有些请求应该提前丢,而且要丢对集合。
这篇 paper 不是专门针对 LLM,但对今天的 multi-model / agentic / RAG pipeline 很有参考意义。因为现在很多应用已经不是单次 model inference,而是多个模型或者多个模块串起来:rewrite、retrieve、rerank、generate,任何一步排队都会传导到 end-to-end latency。
2. 背景:什么是 goodput?
普通 throughput 是单位时间完成多少请求;goodput 更苛刻,只算在 latency objective 内完成的请求。对于实时视频分析、游戏直播分析、低延迟交互系统来说,超过 deadline 的结果基本没价值。
所以 serving 系统遇到 overload 时,通常要 drop 一些请求,避免它们排队太久。但现有系统大多是 reactive dropping:
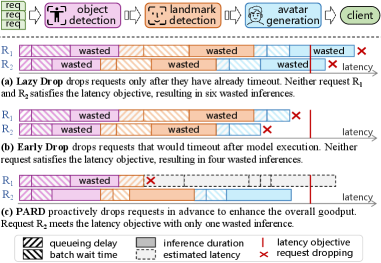
- Lazy Drop:请求已经 timeout 了才丢。
- Early Drop:当前 module 执行前发现它跑完也会 timeout,于是丢。
如下图,Lazy Drop 和 Early Drop 都太晚了,已经消耗了不少无效计算。PARD 则在更早阶段判断这个请求是否值得继续跑。
3. 挑战:pipeline 里 drop request 比单模型复杂得多
单模型场景下,你只要估计当前请求还能不能在 deadline 前跑完。但 pipeline 场景麻烦很多。
第一,模型是 cascaded 的。一个请求经过多个 module,系统只有 end-to-end SLO,不一定有每个 module 的固定 SLO。
第二,latency 不确定。动态 batching 会引入 batch wait time;queueing 会随着 workload burst 变化;这些不确定性在多个 module 串起来后会放大。
第三,workload 会变。steady workload 和 burst workload 下,应该优先保哪些请求并不一样。
论文指出 reactive policy 有两个典型问题:
- drop too late:只看前面和当前 module,不看后续 module 的 latency budget,导致请求到了后面才发现必超时。
- drop wrong set:按 arrival order 丢请求,不考虑 remaining latency budget 和 workload intensity。
如下图,reactive dropping 在真实 workload 里甚至可能比 naive baseline 更差,drop rate 很高但 goodput 不一定好。
4. PARD 的核心方法
PARD 主要回答两个问题:
- 什么时候 drop?
- drop 哪些请求?
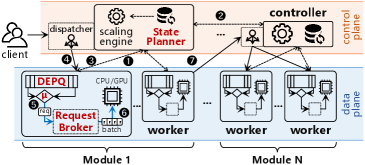
系统架构如下图。PARD 有 control plane 和 data plane。State Planner 负责估计 pipeline 后续 latency,Request Broker 负责管理队列和优先级,worker 负责实际模型推理。
4.1 用 end-to-end latency 判断什么时候 drop
对 pipeline 中第 k 个 module 的请求,PARD 把 end-to-end latency 拆成三块:
L = L_pre + L_cur + L_sub
其中 L_pre 是前面 module 已经消耗的 latency,L_cur 是当前 module 的 latency,L_sub 是后续 module 还会消耗的 latency。
reactive policy 最大的问题是忽略 L_sub。PARD 则尝试估计 L_sub,再把请求的完整 end-to-end latency 和 SLO 比较。
但 L_sub 不是一个简单常数。每个后续 module 的 latency 又包括:
Lat(k) = Q_k + W_k + D_k
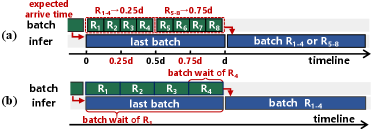
Q 是 queueing delay,W 是 batch wait time,D 是 execution duration。尤其 W 很讨厌,因为请求加入 batch 的时间不同,等待时间可以从 0 到 batch execution duration。
如下图,PARD 在请求进入 batch 前收集前后向 runtime information,再做 dropping decision。

4.2 batch wait time 的 sweet spot
如果把后续 batch wait time 估得太低,系统会保留一些实际会超时的请求,造成 invalid computation。估得太高,又会误杀本来能完成的请求。
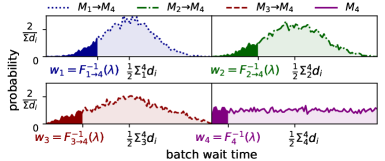
PARD 的做法是为每个 module 估一个 sweet spot w_k。它会基于最近请求采样 batch wait time distribution,然后选一个 quantile。论文默认 λ = 0.1,并在 sensitivity 实验里验证 0.075 到 0.15 附近都比较稳。
如下图,越靠前的 module,后续 batch wait time 是多个 module 的叠加,会更接近集中分布;越靠后的 module,不确定性更大。
4.3 用 adaptive priority 决定 drop 哪些请求
只知道什么时候 drop 还不够。系统 overload 时,队列里很多请求都可能风险很高,到底该丢谁?
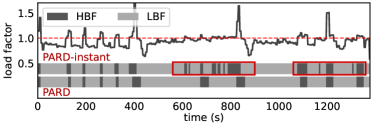
PARD 不按 arrival order,而是根据 remaining latency budget 和 workload intensity 动态切换优先级:
- workload 较轻时,更偏向保留 low remaining budget 的请求,避免临近 deadline 的请求超时。
- workload 较重时,更偏向保留 high remaining budget 的请求,避免系统被快超时请求拖死。
这个策略的本质是:steady 阶段尽量救急,burst 阶段避免连环堵塞。
如下图是 PARD 在 steady workload 下的 dropping 示例。

5. 实验设置
PARD 的实验平台是 16 台机器,每台 4 张 NVIDIA 2080Ti GPU 和 48 CPU cores。作者把集群虚拟成 64 个 worker containers,每个 container 一张 GPU。NTP 用来保证跨 container 时间戳同步到毫秒级。
workload 包括四类 pipeline:
-
tm:traffic monitoring,3 个模型,包括 object detection、face recognition、text recognition。 -
lv:live video analysis,5 个模型,包括 person detection、face recognition、expression recognition、eye tracking、pose recognition。 -
ga:game analysis,5 个模型。 -
da:DAG-style live video analysis,基于lv改成分支 DAG。
SLO 分别设置为 400ms、500ms、600ms、420ms。请求 trace 来自 Wikipedia access trace、Twitter access trace 和 Azure Function trace。
baseline 包括 Nexus、Clipper++ 和 naive。Nexus/Clipper++ 都是 reactive dropping 的代表。指标有三个:
- goodput:单位时间内满足 latency objective 的请求数;
- drop rate:被丢弃或虽完成但超 SLO 的请求比例;
- invalid rate:被丢弃请求消耗的 GPU time 占比。
6. 主结果:提前丢,反而少丢
PARD 的主结果很漂亮:在 12 个 workload 上,PARD 平均只 drop 0.12% 到 3.6% 的请求,相比 Nexus 和 Clipper++,drop rate 降低 1.6× 到 16.7×,wasted computation 降低 1.5× 到 61.9×。
换句话说,PARD 不是“更激进地丢请求”,而是更早、更准地丢掉注定没价值的请求,所以最后总 drop rate 反而更低。
如下图,PARD 在不同 workload 下 drop rate 和 invalid rate 都明显更低。
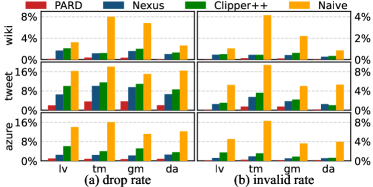
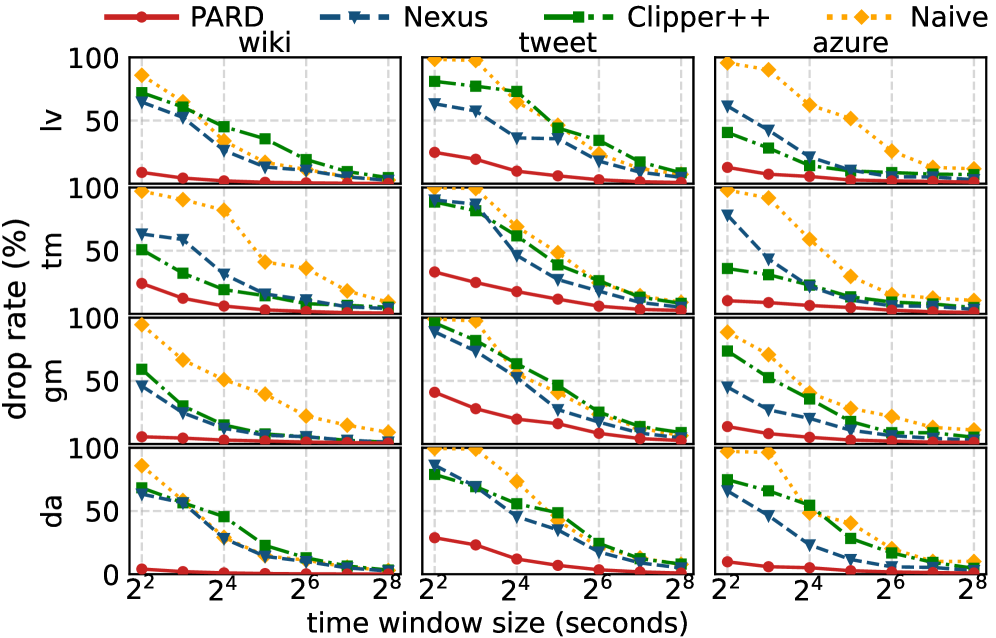
goodput 方面,PARD 相比 state-of-the-art 提高 16% 到 176%。而且在短时间窗口里,Nexus 和 Clipper++ 的 transient drop rate 可以冲到 90%/96%,PARD 则能把 transient drop rate 降低 41% 到 98%。
DAG pipeline 下也类似。PARD 对 DAG-style live video analysis 会估计所有分支中的最大 end-to-end latency,然后决定是否 drop。虽然 DAG 会让 invalid computation 更复杂,但 PARD 仍然比 baseline 低 3.2× 到 15.9×。
7. 消融实验:为什么必须 pipeline-wide?
论文的 ablation 很重要,因为它解释了为什么简单修修 reactive policy 不够。
第一,去掉 proactive latency estimation 后,drop rate 上升 1.1× 到 3.6×,invalid rate 上升 2.1× 到 24×。PARD-back 忽略后续 module,95% 的 drop 都集中在最后一个 module,典型的“太晚丢”。
第二,把 end-to-end SLO 静态切成 per-module SLO 也不行。PARD-split 的 drop rate 和 invalid rate 分别比 PARD 高 2.6× 和 6.7×。原因是每个 module 的 queueing/batch wait 会快速变化,固定预算太死。
第三,只用 FCFS、只用 HBF 或只用 LBF 都不稳。PARD-FCFS 在 burst 时 queueing delay 增加 34%,goodput 降低 24%;PARD-LBF goodput 降低 29%。adaptive priority 的价值就在于根据 load factor 切换策略。
如下图是 ablation 结果,可以看到每个组件都不是装饰。
8. 额外实验:RAG workflow 也能用吗?
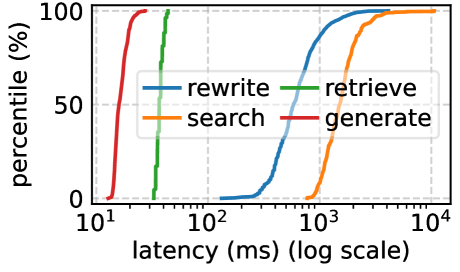
论文最后还做了一个 RAG workflow demo,包括 rewrite、retrieve、search、generate。测试环境是 2 张 A100-80GB,vLLM v0.9.0 和 LangChain,输入是 HotpotQA 的 10k queries,generate/rewrite 用 Llama-3-8B。
结果显示,proactive dropping 比 reactive dropping 少 drop 22% 请求。oracle 级别的 output length prediction 可以把 drop rate 从 17% 进一步降到 11%。
这部分我觉得挺有现实意义。今天很多所谓 agent 或 RAG 应用,其实就是 inference pipeline,只不过模块从 DNN 变成 LLM、retriever、search API。PARD 的思想能迁移,但 latency estimation 会更难,比如 search 有网络长尾,rewrite/generate 有 output length 不确定性。
9. 我的 take
PARD 的核心不是“丢请求”,而是把 request dropping 从被动止血变成主动调度。
这个思路听起来有点反直觉,但系统里经常会遇到类似问题:如果一个任务已经注定不能带来有效收益,继续执行它就是在污染后面的任务。尤其是在 pipeline 里,这种污染会被级联放大。
我比较喜欢这篇 paper 的一点是,它没有用一个复杂 ML predictor 去硬猜 latency,而是从 pipeline latency decomposition 出发,把 queueing、batch wait、execution duration 拆开,再用 runtime distribution 做估计。这个方法虽然看起来朴素,但工程上可解释,也比较容易落地。
当然,PARD 的边界也清楚:它依赖 latency profiling 的稳定性。对于 LLM agent workflow,output length、tool latency、网络 API 长尾都会让 estimation 更难。所以后面如果把 PARD 思想用到 LLM pipeline,我猜一个重要方向会是把 output length prediction、cache state、tool latency distribution 一起放进 runtime planner。
但结论本身很值得记住:在 latency-sensitive serving 里,goodput 最大化不是尽量不丢请求,而是尽量不把 GPU 浪费在注定无效的请求上。