AAAI'23 | NAS-LID:用「局部内在维度」给超网做体检,省 86% 显存
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

AAAI’23 | NAS-LID:用「局部内在维度」给超网做体检,省 86% 显存
原文:NAS-LID: Efficient Neural Architecture Search with Local Intrinsic Dimension 代码:github.com/marsggbo/NAS-LID
1. 问题背景:One-shot NAS 的排名失灵问题
One-shot NAS(又叫 Weight-sharing NAS)是 AutoML 领域在 2019-2022 年最火的研究方向之一。核心思路很简单:
不是搜一个架构就从头训练,而是训练一个包含所有候选架构的超网(Supernet),所有子网(subnet)共享权重,搜索时直接评估 subnet 的性能。这样搜索效率从「450 GPU 天」降到了「4 GPU 时」(对比 NASNet 和 DARTS)。
但有一个老大难问题:超网训出来的权重,给子网的性能排名严重不准。
具体来说,同一个超网里,子网结构差异很大(有的选 conv3×3,有的选 skip-connect),但它们的权重被强制共享,训练时互相干扰,导致从超网继承权重估计出的性能排名,和子网单独训练的真实排名对不上。
当时的解决方案(GM-NAS 等)是:按梯度相似度把超网拆成多个子超网,每个子超网只包含结构相似的架构,减少干扰。方向是对的,但有两个痛点:
- 计算梯度需要 forward + backward,内存消耗大(对大 batch 不友好)
- 梯度是高维稀疏的,用它衡量架构相似度,可分性(separability)低
我们就是从这里切入,提出了 NAS-LID。
2. 核心 idea:用「局部内在维度」代替梯度
局部内在维度(Local Intrinsic Dimension,LID) 是一个来自拓扑学的概念,描述数据点周围邻域的有效维度(内在维度),反映了高维数据实际”躺”在的低维流形的维数。
形式上,对于数据分布 $\mathbf{R}$,点 $x$ 的 LID 定义为:
\[\widehat{\text{LID}}(x) = -\left(\frac{1}{k}\sum_{i=1}^{k}\ln\frac{r_i(x)}{r_k(x)}\right)^{-1}\]其中 $r_i(x)$ 是 $x$ 到第 $i$ 个近邻的距离,$r_k(x)$ 是最大近邻距离(本文取 $k=20$)。
在 NAS 里,我们把这个工具用来描述架构的几何性质:
- 对超网的每一层,提取该层的输出表示,算出层级 LID 值 $\text{LID}(x_i)$
- 把所有层的 LID 拼成向量 $[\text{LID}_1, \ldots, \text{LID}_L]^T$,作为这个架构的”几何指纹”
- 用这个指纹来判断两个架构是否”相似”
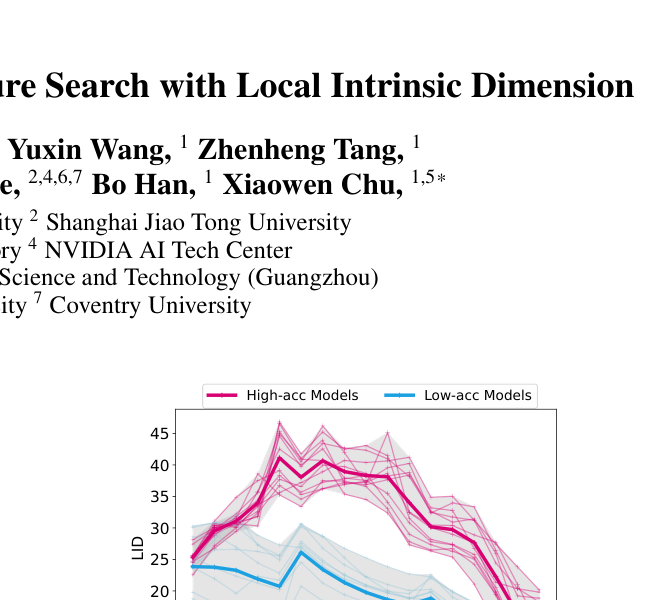
有意思的现象:性能好的架构往往呈”拱形”LID profile(先升后降),而性能差的呈单调递减。这说明 LID 不只是一个分组工具,它本身就包含了架构性能的信息。
为什么 LID 比梯度更好?
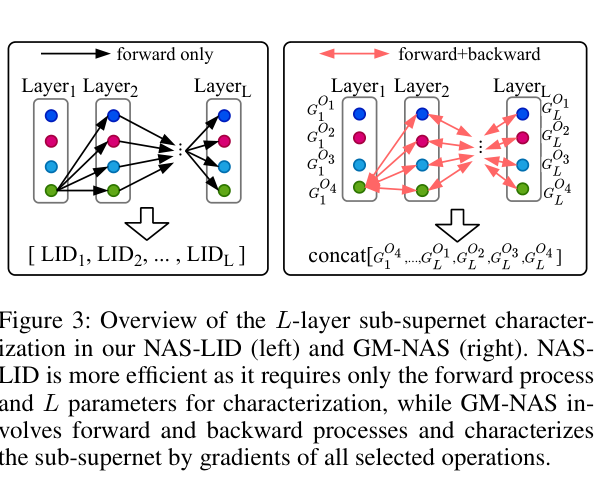
- 计算量小:只需 forward,不需要 backward(梯度)。对于一个 $L$ 层超网分成 $n$ 子超网,NAS-LID 只需 $n \times L$ 个参数,而 GM-NAS 需要 $n \times M$ 个($M$ 是超网参数量,$M \gg L$)
- 可分性高:梯度在高维稀疏空间里很难区分相似架构,而 LID 衡量的是低维流形的维数,在低维空间里更好区分
3. 方法:如何用 LID 拆超网
核心流程如下图:
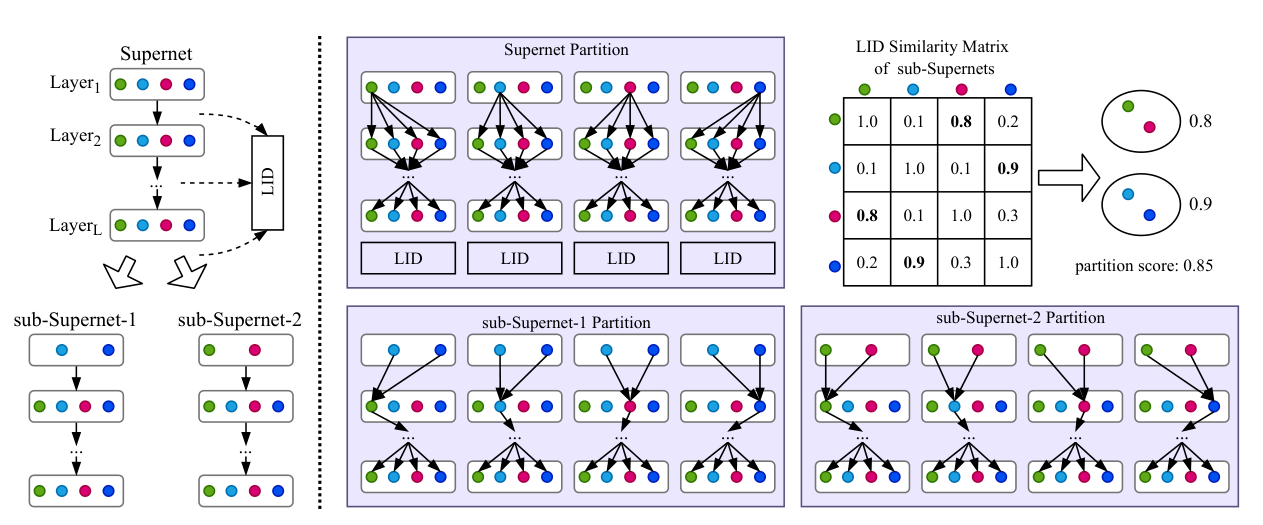
第一步:对超网每一层的每个候选操作(conv3×3, skip-connect 等),计算该操作对应子超网的层级 LID。
第二步:构造 LID 相似度矩阵。两个子超网的相似度定义为:
\[S(\mathcal{A}_{O_i}, \mathcal{A}_{O_j}) = \frac{1}{\|\mathcal{L}_{\mathcal{A}_{O_i}} - \mathcal{L}_{\mathcal{A}_{O_j}}\|_2 + \epsilon}\]第三步:用图最小割(Graph Min-Cut)把操作分成两组,最大化同组内相似度之和(partition score)。
第四步:迭代拆分,直到子超网数量满足需求。
对比 GM-NAS 的双向传播方式,NAS-LID 只需要 forward,内存节省显著:
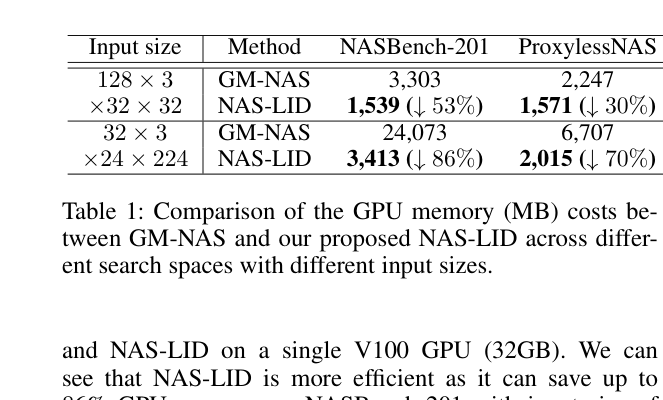
在 NASBench-201 上 batch size 32×3×224×224 时,NAS-LID 只用 3,413 MB,GM-NAS 用 24,073 MB,省了 86% 的 GPU 显存。
4. 实验结果
可分性(Separability)
核心指标之一:LID 的可分性比梯度高出两个数量级。

所有 edge 上,NAS-LID 的可分性分数都远高于 GM-NAS,说明用 LID 做超网分组更”确定”,不同组之间的边界更清晰。
排名相关性 & 最终架构性能
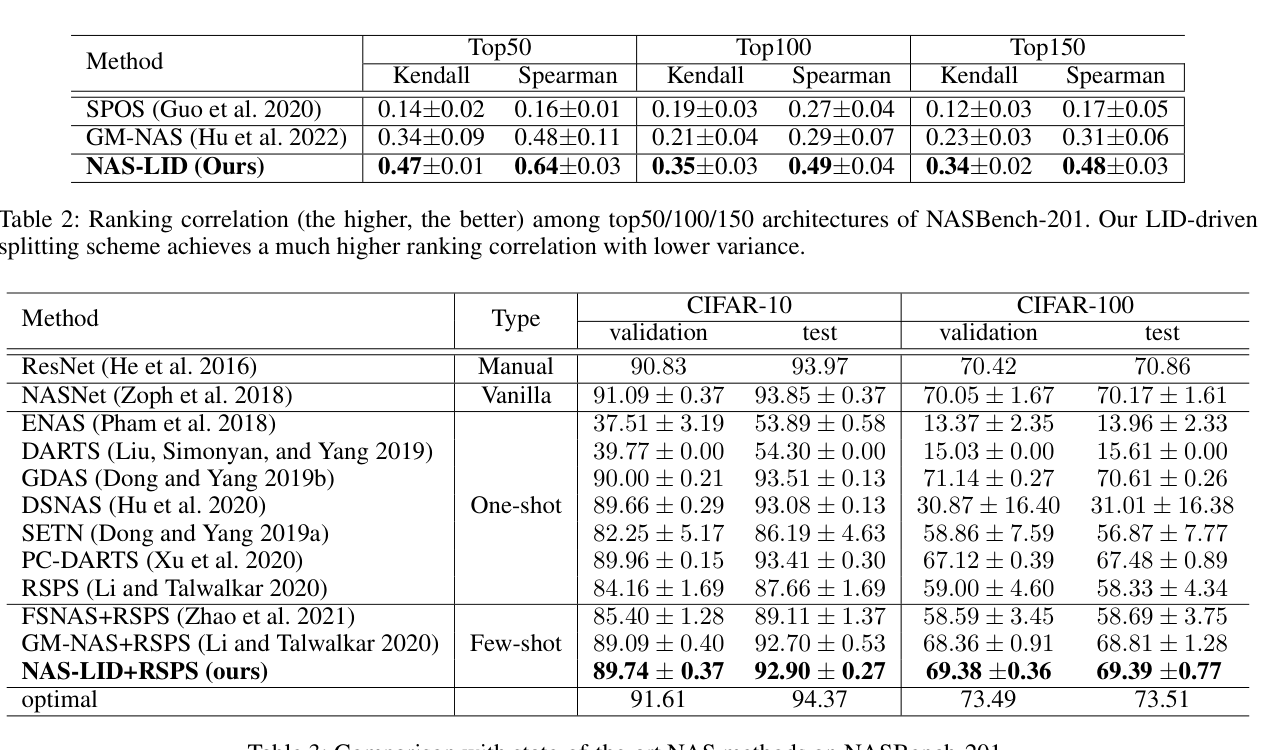
- 排名相关性(Table 2):NAS-LID 在 Top50/100/150 上的 Kendall 和 Spearman 系数均显著优于 SPOS 和 GM-NAS。更低的标准差说明 LID 驱动的分组更稳定。
- 最终架构性能(Table 3):NAS-LID+RSPS 在 CIFAR-10 test 上达到 92.90%(接近 optimal 94.37%),CIFAR-100 test 上达到 69.39%,均超过 GM-NAS+RSPS。
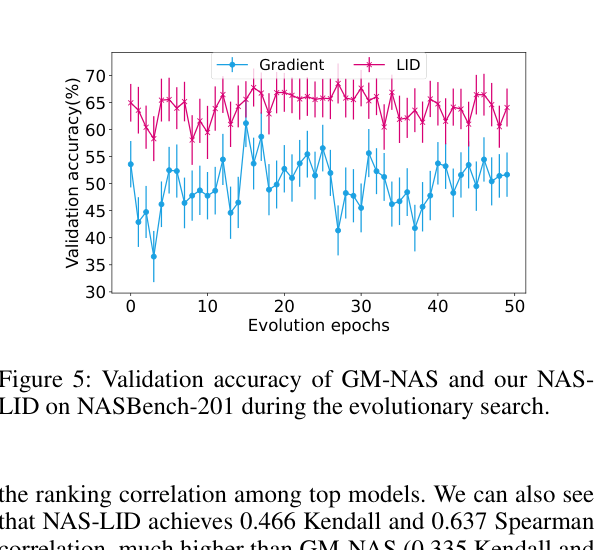
进化搜索过程中,NAS-LID 的验证精度波动明显小于 GM-NAS(蓝线 vs 红线),说明子超网干扰减少了,搜索更稳定。
5. 踩坑记录
坑 1:LID 估计的近邻数 k 怎么选?
我们在代码里硬编码了 $k=20$。实际上 $k$ 太小会导致估计不稳定,$k$ 太大又引入了远邻噪声。20 是个经验值,在 NASBench-201 的 batch size 32 下表现稳定。如果换更大的 batch size 或不同数据集,可能需要重新调。
坑 2:子超网数量的平衡
拆太多子超网会增加 fine-tune 的开销(每个子超网都要单独 fine-tune),但拆太少减少干扰的效果有限。我们最终选择 $T=2$ 轮拆分($2^2=4$ 个子超网)作为默认配置,兼顾效率和效果。
坑 3:迁移到 OFA/ProxylessNAS 空间
NASBench-201 是个比较小的 tabular 搜索空间,迁移到更大的 OFA 和 ProxylessNAS 空间时,LID 计算的 batch size 需要相应调大,否则近邻不准。这也是文章最后指出的一个局限。
6. 总结
NAS-LID 的贡献可以用一句话概括:用更轻量(只需 forward)、更有可分性(LID vs 梯度)的几何指标来拆超网,解决 one-shot NAS 里的权重共享干扰问题。
从 86% 的显存节省和更高的排名相关性来看,这个方向是对的。
从现在(2026 年)回看:one-shot NAS 这个方向在大模型时代确实沉寂了不少,但超网权重干扰这个根本问题依然存在——换个场景,比如 MoE 的路由器训练干扰、多任务学习的梯度冲突,本质上是同类问题。NAS-LID 里的 LID-based 分组思路,或许在这些新场景里还有用武之地。