EuroSys'26 | MFS 把整个 model family 融进一套嵌套模型,KVCache 跨 tier 直接共享
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

EuroSys’26 | MFS 把整个 model family 融进一套嵌套模型,KVCache 跨 tier 直接共享
1. 前言
你有没有想过,为什么 LLM provider 总喜欢给你一整个 model family?
比如同一个系列里有 7B、13B、70B;用户有的要便宜,有的要快,有的要效果。站在产品视角这很合理,但站在 serving 系统视角就很烦:每个模型都要单独加载参数、单独维护 KVCache、单独 batching。明明它们架构很像,GPU 却没法很好地共享。
MFS 这篇 EuroSys 2026 的工作就想解决这个问题。它的核心想法可以一句话概括:
不要同时 serve 一个 family 里的多个独立模型,而是把小模型“沉淀”到大模型的中间层里,形成一个 multi-tiered model。
论文把这个过程叫 Knowledge Precipitation。名字有点玄学,但说人话就是:用最大模型做底座,通过 full-parameter fine-tuning,让它的浅层/子结构也能像小模型一样独立输出。
这样带来的好处是:参数可以共享,batching 可以跨 tier 做,KVCache 也可以跨 tier 复用。
2. 背景:model family serving 的尴尬
现在的 LLM serving 优化很多,比如 continuous batching、PagedAttention、KV-cache management、speculative sampling。但它们大多默认你 serve 的是一个模型。
如果服务端同时放 Llama2-7B、13B、70B,会遇到三个问题。
第一,GPU memory 压力大。模型参数本身就占内存,KVCache 也占内存。论文举例,Llama2-70B 在 512-token input 下,KVCache 至少需要 1.25GB。如果多个模型同时 serve,KVCache 之间不能共享,参数也重复占用。
第二,batching 变难。不同模型的 layer number、head number、hidden size 不一样,计算图和开销都不同。GPU 喜欢规则的大 batch,但 model family serving 天生不规则。
第三,cost per query 难控。服务商想根据用户 QoS 选择不同模型,但不同模型资源占用差异很大,调度粒度很粗。
如下图,论文先回顾了 LLM inference 的基本过程:prefill 阶段一次性处理整个 prompt,decode 阶段则逐 token 生成,每步都要访问所有历史 token 的 KV 向量。
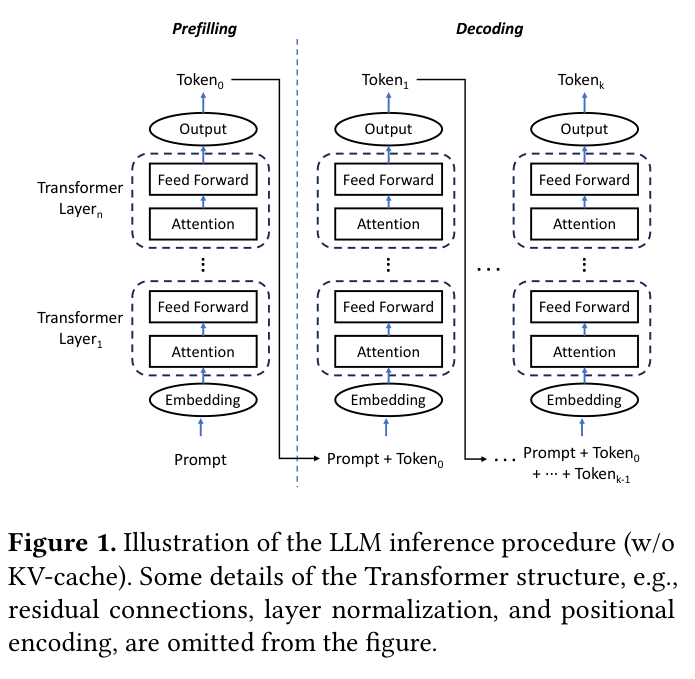
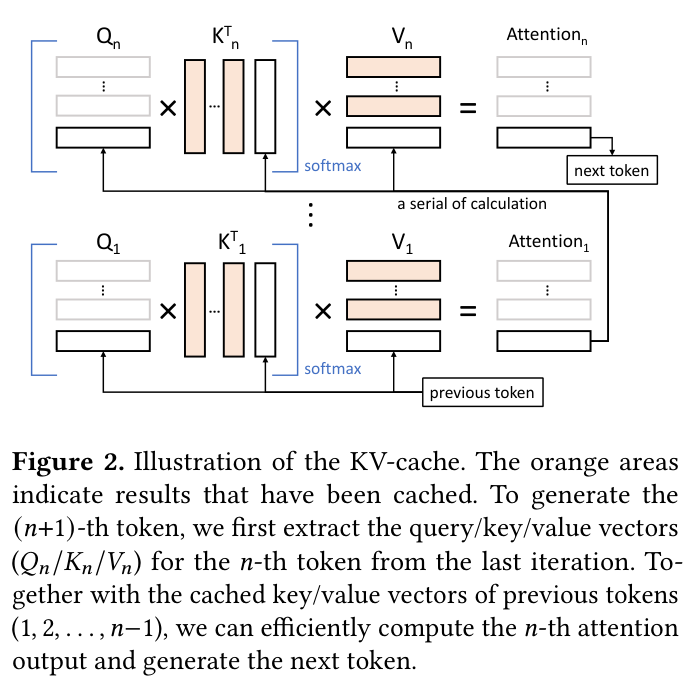
为了避免重复计算历史 token 的 K/V,系统会把每层的 K、V 矩阵缓存下来,就是 KVCache。如下图,橙色区域代表已缓存的 K/V 结果,生成第 n+1 个 token 时只需计算当前 token 的 Q,再与历史 K/V 做 attention,而不是重算所有历史。
3. 机会:模型家族不是完全无关的
MFS 的出发点有三个观察。
第一,Transformer 本身有 redundancy。很多工作都观察到,丢掉一些 attention heads 或 layers 后,模型能力不一定立刻崩掉。
第二,同一 model family 结构高度相似。它们可能 layer 数、head 数、hidden size 不一样,但整体都是 stacked Transformer layers。
第三,LLM 服务正在走向 model-less interface。用户未必关心你到底用 7B 还是 13B,而是关心 latency、quality、price。
所以 MFS 想做的是:用一个 multi-tiered model 提供多个 QoS tier。小 tier 对应小模型,大 tier 对应大模型。请求可以指定 tier,也可以由调度策略选择 tier。
这就是 Knowledge Precipitation 的位置:把大模型切成不同 tier,并让每个 tier 都具备语言建模能力。
4. 方法:Knowledge Precipitation 到底做了什么?
MFS 尝试过一些直接方案,比如 early exiting 或给浅层加 LoRA adapter。但作者发现效果不行,低 tier 会生成不成句的内容。这也挺符合直觉:decoder-only LLM 的浅层不是天然为最终 token distribution 服务的。
Knowledge Precipitation 的做法是:
- 从 family 中最大的 pre-trained model 出发。
- 按 layer/head 切分出多个 nested tiers。
- 每个 tier 都接一个 loss。
- 用 weighted sum 联合训练:
L = L0 + λ1 L1 + ... + λi Li
这样训练后,小 tier 不只是被迫“提前退出”,而是被显式训练成一个可用的小模型。更重要的是,所有 tier 是嵌套共享参数的,所以大 tier 可以复用小 tier 的中间结果和 KVCache。
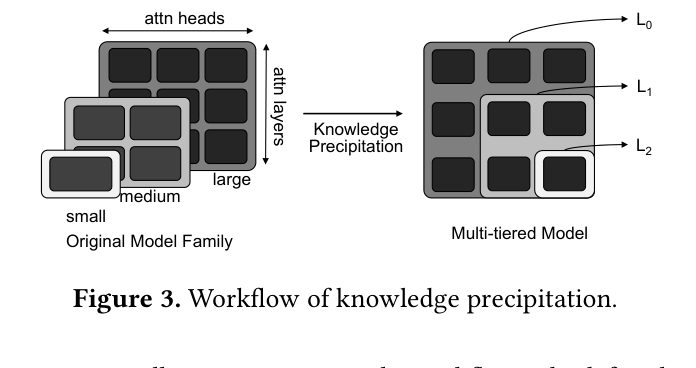
如下图是论文中的流程示意:原始 model family(左边三个大小不同的模型)经过 Knowledge Precipitation 变成一个 multi-tiered model(右边),小 tier L0 嵌套在大 tier L2 内部,参数共享。
5. Serving 侧优化:tier-level batching 和 KVCache sharing
有了 multi-tiered model 之后,MFS 在 serving 侧主要做三件事。
第一是 tier-level batching。不同 tier 的请求可以在共享的 lower layers 上一起 batch,到了高 tier 才分流。这样比独立模型分别 batch 更容易把 GPU 吃满。
第二是 intermediate feature 和 KVCache sharing。比如一个请求先由 lower tier 生成/验证,再切到 higher tier,传统独立模型之间 KVCache 不兼容,需要重新算;MFS 因为 tier 嵌套在同一个模型里,所以 KVCache 可以继续用。
第三是 multi-level sampling。它可以自然支持 speculative sampling:lower tier 做 draft,higher tier 做 verify,而且两者共享参数和 KVCache,减少额外 memory waste。
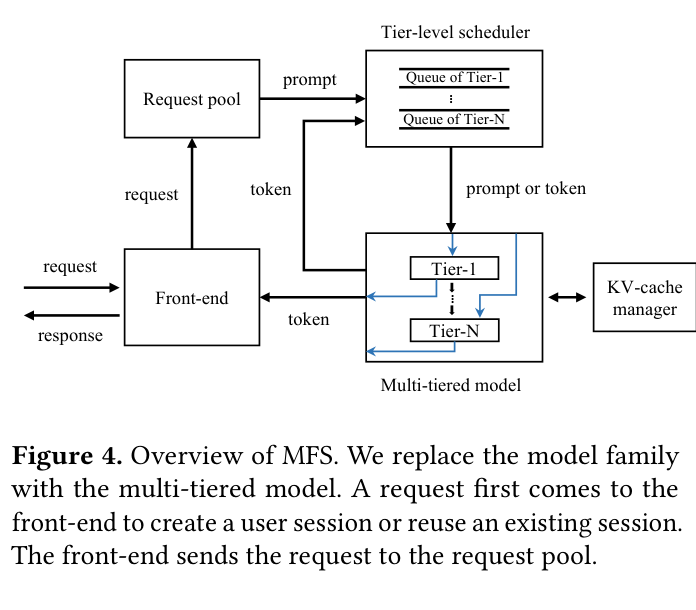
如下图是 MFS 的系统总览:前端接收请求后送入请求池,tier-level scheduler 决定分配给哪个 tier,multi-tiered model 执行推理,KV-cache manager 统一管理缓存。
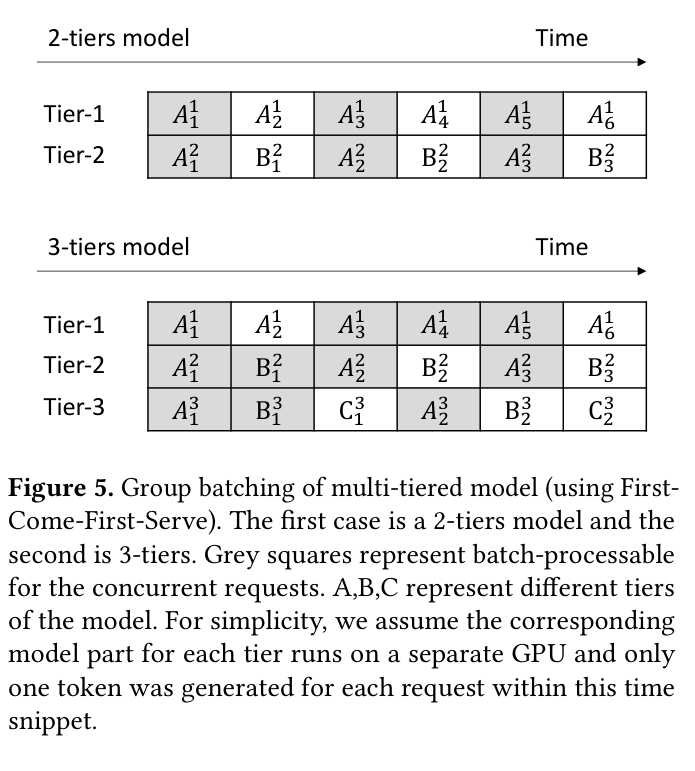
MFS 的 group batching 策略是核心优化之一。如下图,2-tier 和 3-tier 模型都可以把不同 tier 的请求在 lower layers 上合并成一个 batch,直到分流点才按 tier 拆分,充分利用 GPU 吞吐。
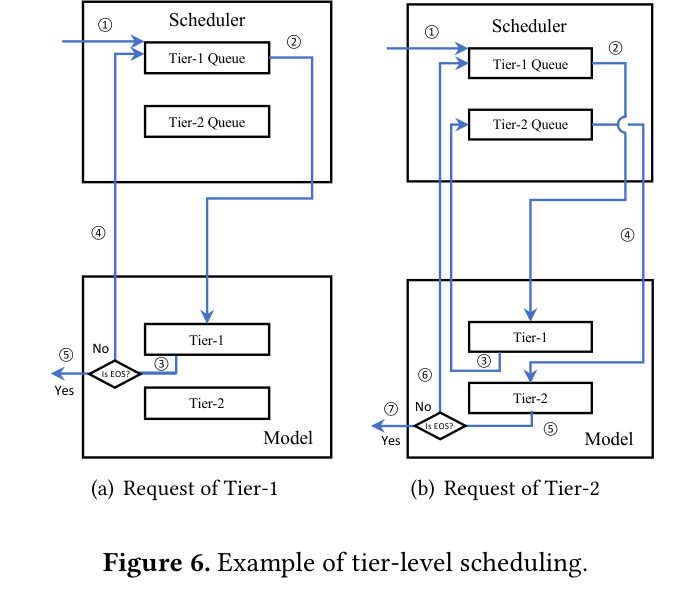
tier-level scheduling 还要处理 EOS 检测和 tier 切换。如下图,Tier-1 请求生成到 EOS 就直接结束,Tier-2 请求则需要等 Tier-1 的共享计算完成后再继续。
6. 实验设置
MFS 的实验分两类:模型质量和系统性能。
模型质量方面,作者验证了 Llama2 和 Qwen family。主要 benchmark 包括 MMLU、PIQA、OpenBookQA、HellaSwag、BoolQ、ARC-Easy、ARC-Hard、ANLI-R1/R2/R3。
fine-tuning 设置也给得比较具体:使用约 0.66T tokens 的 generation/dialogue mixed dataset,训练 2500 iterations,大约 24 小时;learning rate 为 2e-5,half-periodic cosine scheduler,weight decay 0.1,gradient clipping 0.3,equivalent batch size 64,sequence length 4096。
系统性能方面,作者没有直接和 vLLM 比,因为 vLLM 优化目标是分布式执行和 KV memory management,而 MFS 改的是模型结构和 family serving 架构。主要 baseline 是 ORCA 风格的独立模型 serving。
指标包括:
- generated content quality;
- request execution time;
- end-to-end token latency;
- GPU memory footprint;
- GPU utilization。
7. 结果:质量有没有崩?
先看质量。MFS 的一个关键风险是:把 13B 切成 7B tier 后,这个 7B tier 还能不能打?
实验显示整体还可以。比如 Llama2-13B 转成 13B/7B two-tier 结构后,MFS-13B 在 MMLU、OpenBookQA、ARC-Hard、ANLI 等多个指标上和 Llama2-13B 接近,有些还略高。MFS-7B 也和 Llama2-7B 大体可比。
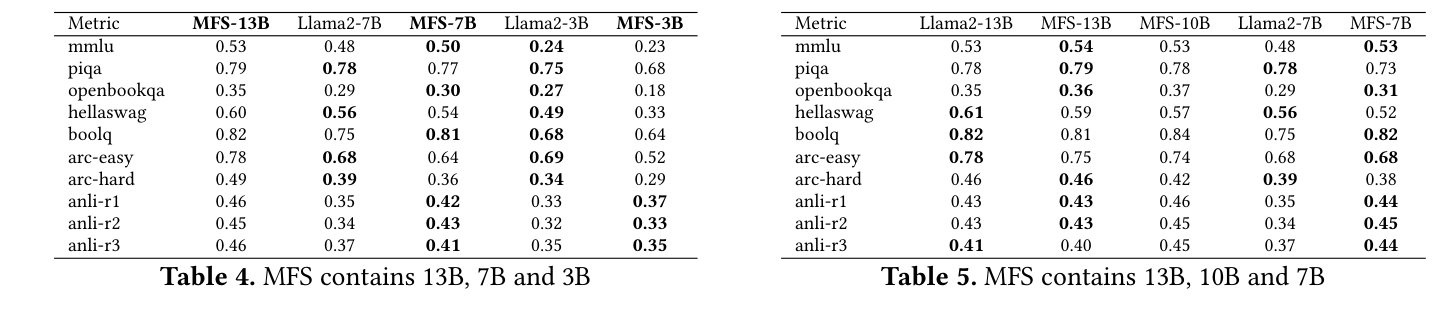
论文还做了三层结构:13B/7B/3B 和 13B/10B/7B。比较有意思的是,MFS-10B 这种原 family 中没有的中间 tier,也能给出介于 13B 和 7B 之间的 QoS。这说明 MFS 不只是压缩部署成本,还可能给 serving 提供更细粒度的 quality-latency trade-off。
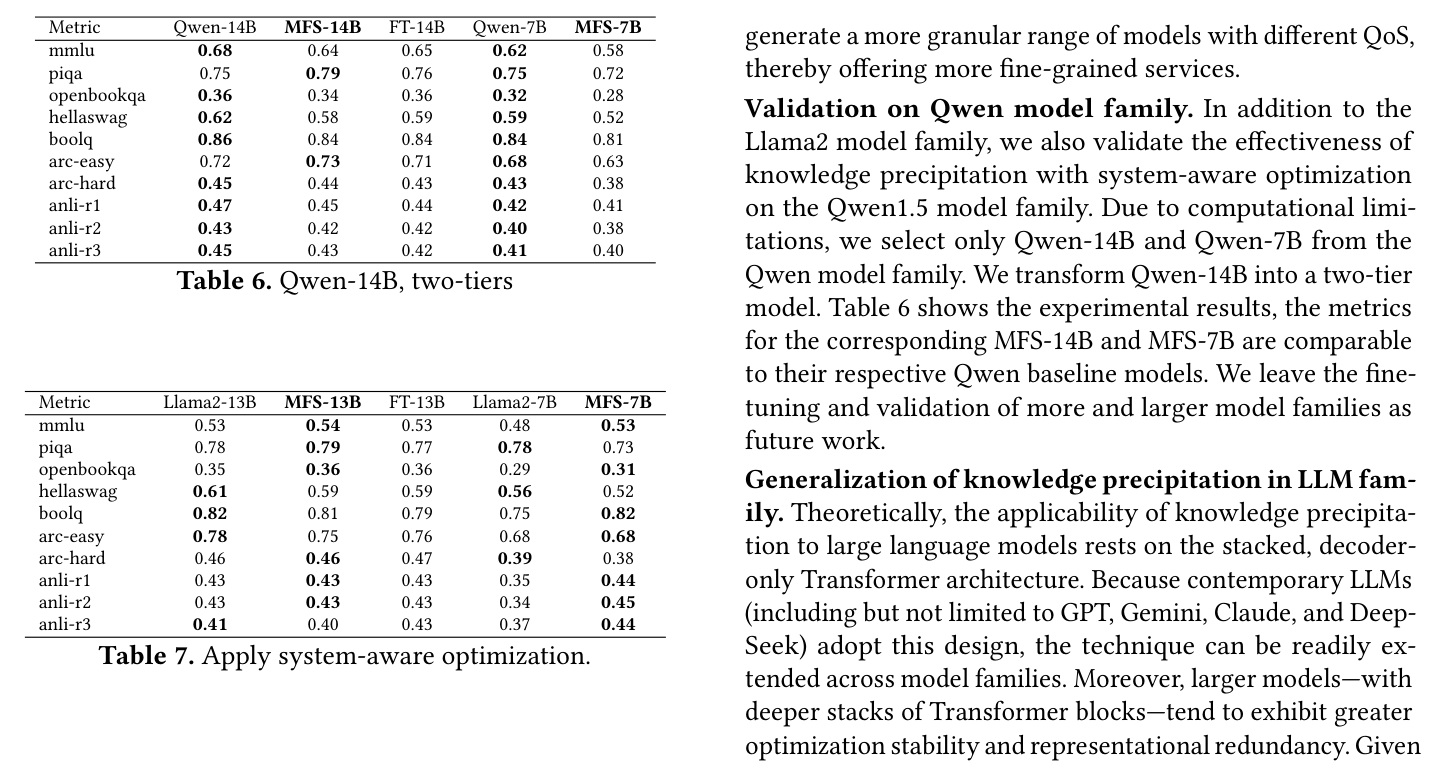
Qwen-14B/7B 上也做了验证,MFS-14B 和 MFS-7B 整体接近对应 baseline,但 Qwen 的部分指标会有一定下降,比如 MMLU 上 Qwen-14B 是 0.68,MFS-14B 是 0.64,MFS-7B 是 0.58。这提醒我们:Knowledge Precipitation 不是免费午餐,不同 family 的可沉淀程度会不一样。
如下是 Llama2 family 的质量对比。MFS-13B 和 MFS-7B 在 MMLU、OpenBookQA 等指标上和对应独立模型接近,MFS-10B 这种”新 tier”也能给出中间档位的 QoS。
Qwen-14B/7B 的结果相对谨慎一些,部分指标有所下降。下表还对比了 fine-tuning 后(FT)的结果,说明 Knowledge Precipitation 的质量主要来自联合训练而非单纯 fine-tuning。
8. 系统结果:为什么 MFS 更快更省?
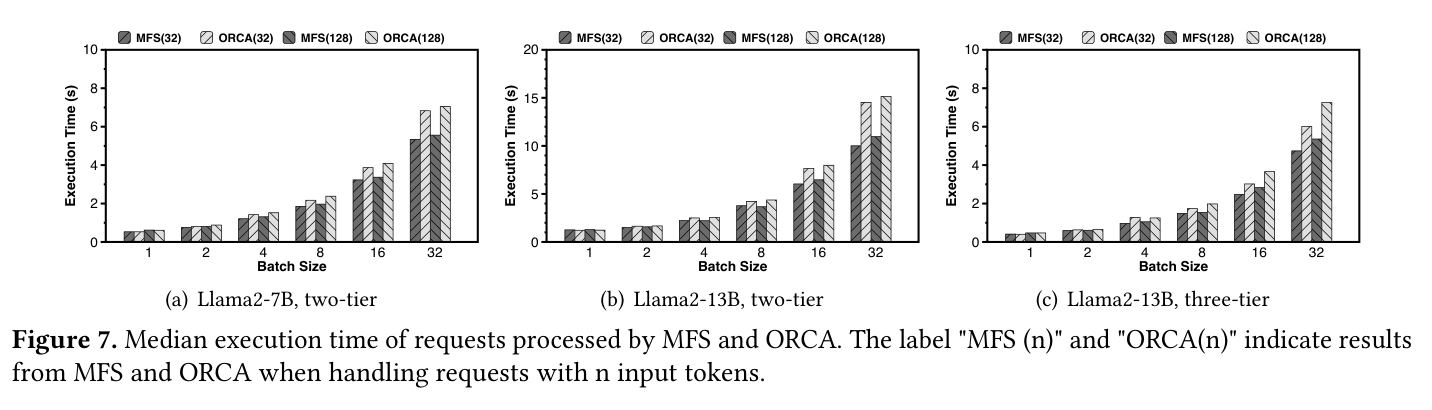
系统实验里,随着 batch size 增大,MFS 相比 ORCA 的优势更明显。batch size 为 1 时,两者差不多,因为没有 batch processing 空间;batch size 上去后,MFS 的 cross-tier batching 和共享计算开始发挥作用。
如下图,MFS 在不同 batch size 下的 median execution time 明显优于 ORCA,尤其是 Llama2-13B two-tier 和 three-tier 场景(三组柱状图,每组对比 batch size 从 1 到 32 的结果)。
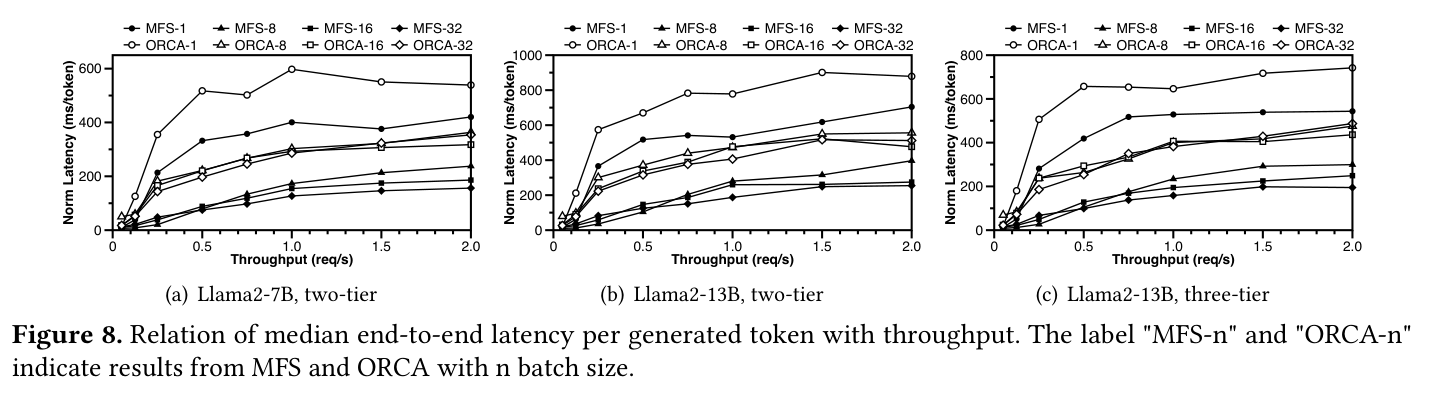
end-to-end per-token latency 的结果也类似。如下图,在相同 throughput 下,MFS 的 normalized latency 明显低于 ORCA,decode 阶段是 memory-bound,MFS 更好地 batch 和复用 cache 带来了明显收益。摘要里给出的总体结果是:MFS 能减少 56.1% end-to-end token generation latency,并降低 47.8% GPU memory footprint。
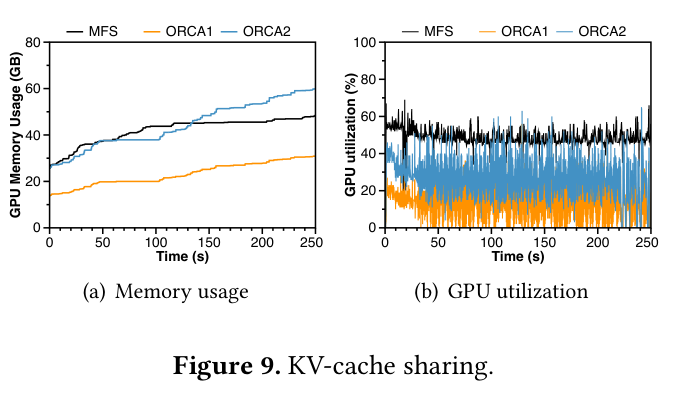
KVCache sharing 实验最直观。论文构造了 MFS 和两个 ORCA-style 系统对比:ORCA1 和 ORCA2 因为小模型和大模型分开,KVCache 不能共享,GPU memory usage 持续攀升;MFS 因为 lower tier 和 higher tier 嵌套共享 KVCache,memory usage 更稳定,GPU utilization 也更高。
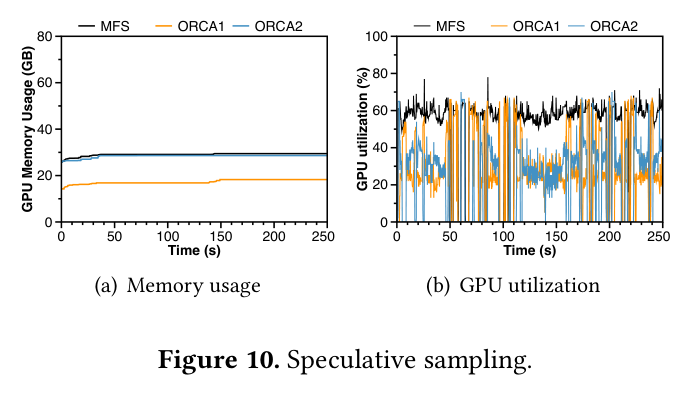
speculative sampling 实验也单独给了结果。如下图,在 speculative sampling 模式下(lower tier 做 draft,higher tier 做 verify),MFS 的 memory usage 更低、更平稳,因为两个 tier 共享参数和 KVCache,不需要额外维护两套独立的 KVCache。
9. 我的 take
我觉得 MFS 的价值不在于“又提出一个小模型加速大模型”的套路,而在于它把 model family serving 这个问题重新定义了。
以前我们默认 family 里的模型是多个独立 artifact:7B 是 7B,13B 是 13B,70B 是 70B。系统只能在外面做调度。MFS 则把 family 变成一个 nested artifact:小模型是大模型的一部分,调度从“选哪个模型”变成“跑到哪个 tier”。
这个变化会带来很多系统优化空间,尤其是 KVCache sharing 和 speculative sampling。因为 LLM serving 的核心矛盾之一就是:计算可以省一点,但 KVCache 和参数一旦重复,HBM 立刻开始肉疼。
读这篇论文的时候,我脑子里一直在冒一句话:Make AutoML Great Again。
这套思路和 NAS 时代的 Once-for-All(OFA,韩松组 2020 年 ICLR 的工作)几乎是同一个灵魂。OFA 的核心思想是:与其为每个硬件目标单独训练一个模型,不如训练一个 supernet,让它的不同 sub-network 天然对应不同的精度-效率 trade-off,部署时按需”切片”就好。MFS 的 Knowledge Precipitation 做的是同一件事,只是把它搬到了 LLM 的 model family serving 场景——大模型是 supernet,各 tier 是 sub-network,serving 时按请求 QoS 决定跑到哪一层退出。
其实我博士阶段就是做 AutoML 和 NAS 方向的,自己也维护过一个叫 hyperbox 的 AutoML 框架,里面实现了 MLP、Attention、Norm layer 的 once-for-all 模块。当时就想:这套东西能不能直接用到 LLM 上?苦于资源有限,加上懒,一直没推进下去。现在看到 MFS 把类似的想法在 LLM serving 场景落地,既有点”我当初就该做”的惋惜,又挺高兴这个方向终于被认真对待了。
不过,把多个模型融进一个模型能实打实地降低部署开销,但随之而来的难题和 MoE 有点类似,甚至更复杂。
MoE 的问题是:不同 token 激活不同 expert,同一个 batch 里的请求走不同 expert,计算图就不再对齐,GPU 并行度很难打满。MFS 的情况类似但更难处理——不同 tier 的请求不是”选哪个 expert”,而是”运行到第几层就退出”,这意味着同一个 batch 里,有些请求跑完全部 layer,有些只跑前面一半,layer 维度的不对齐比 expert 维度的不对齐更伤,因为它直接破坏了 GPU kernel 的 shape 假设。论文里的 group batching 本质上是在尽量让同 tier 的请求凑在一起,缓解这个问题,但在 tier 分布不均匀的情况下,latency 还是很难保证稳定的下界。
这也是为什么 MFS 目前没有直接给出严格的 P99 latency 数字,而是以 median execution time 为主要指标——soft tail latency 的保证其实还是个开放问题。
当然,MFS 也有很现实的门槛。它需要对最大模型做 full-parameter fine-tuning,而且训练数据和 recipe 会影响每个 tier 的质量。对于商业闭源模型,这个成本不一定小。另一个问题是,改变模型结构后,生态里的 kernel、quantization、serving runtime 是否都能无缝适配,也需要工程验证。
但从研究角度看,这篇工作挺有启发:LLM serving 不一定只能在 runtime 层优化,有时候把 model family 的结构重塑一下,runtime 才能拿到真正好用的共享边界。NAS 时代积累的一整套 once-for-all 训练方法论,也许正在以一种新的形式在 LLM 时代重新发光。