巴西「主权大模型」翻车:当模型可以随便融合,怎么证明它偷了你的权重?
巴西「主权大模型」翻车:当模型可以随便融合,怎么证明它偷了你的权重?
1. 先从一个翻车现场说起
前几天有个挺戏剧性的事:巴西里约热内卢市政的 IT 机构 iPlanRIO 高调发布了一个叫 Rio 3.5 Open 397B 的开源大模型(相关介绍),号称是公帑资助、自主研发,性能还吊打 DeepSeek v4 Pro 和 Qwen 3.7 Plus,背后是 50 万雷亚尔的公共投入。
听起来很提气是吧。结果没几天就被扒了。
有分析团队(上海的 Nex-AGI)放出了一套可复现的检测方法,结论是:这个所谓的「主权模型」,大概率是把别人的模型权重直接融合(merge)出来的——大约 60% 来自 Nex N2 Pro,40% 来自 Qwen 3.5。证据也很硬核:
来源: https://aiweekly.co/alerts/iplanrio-rio-35-exposed-as-nex-qwen-weight-merge
- 跨 60 层算下来的共线性高达 0.993,这种程度的相似不可能是独立训练出来的;
- 更离谱的是,把 system prompt 去掉之后,这个模型有 79.2% 的概率自报家门说自己是「Nex」,一次都没说过自己是「Rio」。
后来官方解释说是「上传错了版本,传成了融合的中间产物,而不是最终蒸馏的模型」。这个解释你信几分另说,但它结结实实把一个被低估的问题摆上了台面:
当模型融合(model merging)变得这么容易,「这个模型到底是不是你的」,要怎么证明?
今天就想借这个由头,介绍一篇专门解决「融合之后怎么追溯版权」的工作——RouteMark。但在讲它的方法之前,得先把几个概念递进着捋清楚。
2. 什么是 model merging
先说人话。
大模型时代,想让一个模型在很多任务上都能打,常规做法是针对每个任务各 fine-tune 一个。但任务一多,这个成本就爆炸了。
model merging 的思路是:别重训了,直接把多个已经 fine-tune 好的模型「合」成一个。 最朴素的做法就是权重平均(weight averaging)、task arithmetic、Ties-Merging 这一类——本质上就是把各个模型的参数按某种比例加权混在一起,得到一个能同时干多件事的模型,几乎不需要额外训练。
上面巴西那个 Rio 模型,用的就是这种静态融合(static merging)——固定比例,把两个 dense 模型的权重直接搅在一起。
这种方式很省事,但有两个老毛病:一是固定比例不够灵活,不同输入来了都用同一套混合权重,任务一冲突性能就掉;二就是今天的主角问题——融合之后,每个「源模型」的产权就糊成一锅粥了,你很难证明里面有没有人偷用了你的模型。
3. 顺便说说 MoE 为什么强
要解决「不够灵活」这个毛病,很自然会想到 MoE(Mixture-of-Experts,混合专家)。
MoE 的精髓就四个字:稀疏激活。它不是把所有参数一股脑全用上,而是用一个学出来的 router(路由器),根据输入动态地只挑几个相关的「专家」来算。这样既能把模型容量做大,又不用让计算量同比例增长,天然适合「多任务、各管一摊」的场景。
那把 MoE 和 model merging 结合起来会怎样?这就引出了更现代的范式。
4. MoE-based model merging:更优雅,但也更难追责
把每个 fine-tune 好的 dense 模型,当成 MoE 里的一个 expert,再学一个 router 来动态组合它们——这就是 MoE-based model merging。
比起静态融合,它的好处很直接:不再是死板的固定比例,而是 input-dependent(随输入而变)——什么样的输入来了,router 就把它更多地派给对应擅长的那个 expert。每个 expert 还能保住自己的「专精」,扩展性也更好。
但硬币的另一面是:追责变得更难了。
因为每个 expert 的贡献是随着输入和层数动态变化的,单个 expert 的影响被「路由」这层机制给搅浑了。更麻烦的是,MoE 这种模块化结构,给了对手非常多「洗白」的手段。假设有人把你的模型当 expert 偷偷塞进了他的 merged MoE,他能从两个层面动手脚:
- 参数级篡改(专家数量不变,只动内部参数):把你的 expert 继续 fine-tune 几千步、用 pruning 压掉一部分权重、或者把隐藏维度做个 permutation(置换)打乱参数对齐——模型功能基本不变,但权重层面的痕迹被搅乱了。
- 结构级篡改(直接改动专家池的构成):把你的 expert 替换(replace) 成别的、删除(delete) 只留其中几个、或者 新增(add) 一批专家进来混淆视听。
这两类操作——参数级的 fine-tune / prune / permute,结构级的 replace / delete / add——都能在不影响整体性能的前提下,把「这是谁的模型」这条线索抹得干干净净。后面第 7 节的实验,评估的正是 RouteMark 在这每一种篡改下,还认不认得出原来的真专家。
那现有的指纹/水印方法行不行?基本都顶不住:
- 基于权重的方法(如 PCS、ICS):比对参数相似度,一个简单的 permutation 就废了——权重重排一下,参数对不上了,但模型功能没变。
- 基于激活的方法(如 REEF,用 CKA 比中间层表示):能看出「整体像不像」,但没法定位到底是哪个 expert 被盗用了。而且融合之后,各个 expert 的激活通路已经混在一起,粒度根本不够。
一句话总结这个困境:真正需要的,是一种能精确到「单个 expert 级别」、又能扛住各种篡改的指纹。 这正是 RouteMark 想做的事。
原文:RouteMark: A Fingerprint for Intellectual Property Attribution in Routing-based Model Merging
5. 核心 insight:会变的都靠不住,路由偏好不会变
讲方法之前,得先把核心观察讲透,因为整个方法的合理性全都建立在这一个点上。
RouteMark 的出发点是一个很朴素的问题:融合之后,一个 expert 身上还有什么东西是「抹不掉」的?
权重可以剪、可以置换、可以微调;激活可以被搅浑。这些都靠不住。但作者发现了一个非常稳的东西——
task-aligned routing(任务对齐的路由行为):融合之后,每个 expert 依然对它「原始训练领域」的输入最敏感,router 还是会大概率把对应任务的输入派给它。
论文做了个实验来验证这件事。把五个分别在 SUN397、Cars、RESISC45、EuroSAT、SVHN 上 fine-tune 的 CLIP 专家融合成一个 MoE,然后看它的路由行为,结果如下图:
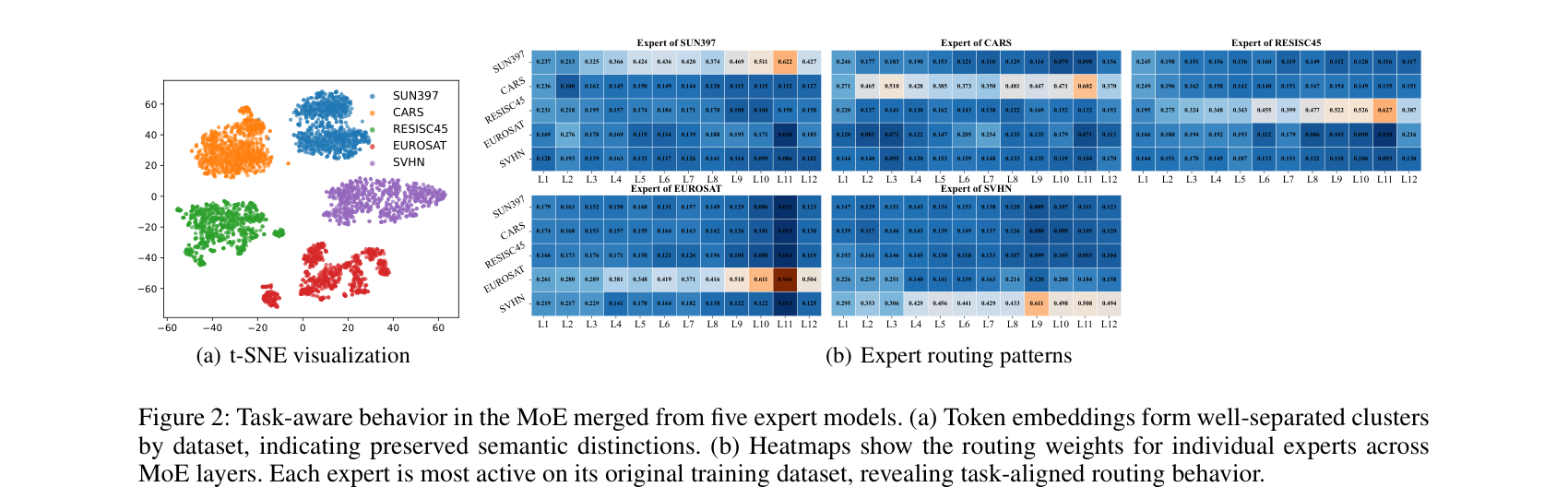
左边是 token 表示的 t-SNE,可以看到不同任务的数据在隐空间里清清楚楚地分成了几簇,说明语义区分被保留了下来。右边更直接——每个 expert 的路由热力图,对角线明显最亮:每个 expert 都在自己原始训练的那个数据集上被激活得最强烈。
这个现象为什么重要?因为它提供了一个功能性的、而非参数性的指纹来源。
说人话就是:你可以把一个 expert 的权重剪掉一半、把维度打乱、再 fine-tune 几千步,但只要它还在干「识别遥感图像」这件活,router 对它的那份「偏爱」就不会变。 路由行为刻画的是「这个 expert 擅长什么」,而擅长什么是任务决定的,不是某几个具体权重决定的——这恰恰就是各种篡改攻击够不着的地方。
指纹设计的合理性,本质上就这一句话。
6. 方法有多简单:两个统计量 + 一次相似度匹配
想清楚了 insight,方法就简单得不像话了。整个 RouteMark 不需要访问权重、不需要 activation、不需要重训,只要拿一组固定的「探针数据」喂进 merged MoE,记录 router 吐出来的 routing logits,就够了。
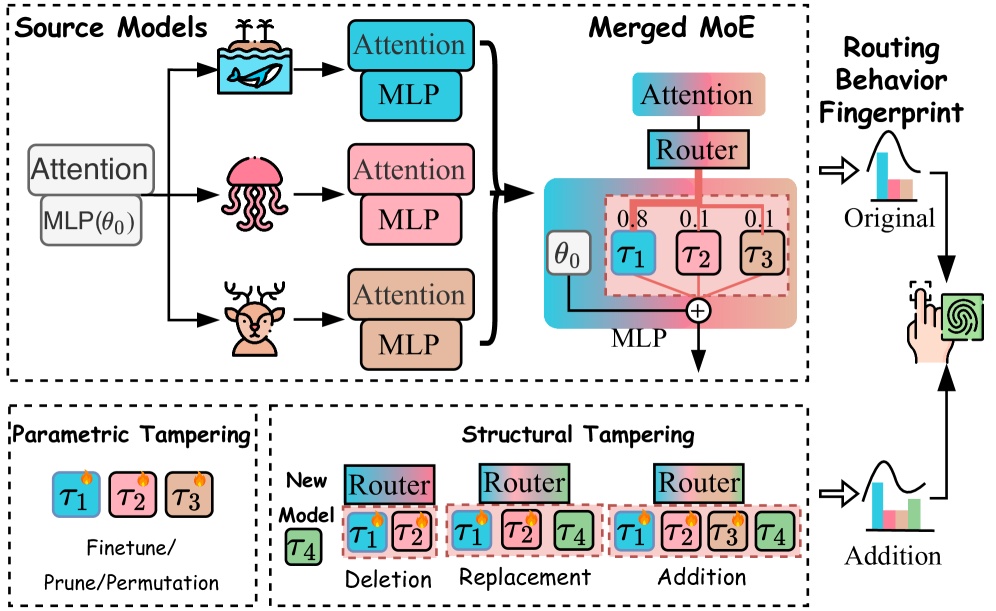
探针数据怎么选?就用这些 expert 各自原始训练领域对应的那 N 个数据集,全程固定不变,保证 victim(被保护方)和 suspect(嫌疑方)两边的指纹是在同一套标准下构造的。
然后给每个 expert 算两个互补的指纹:
① RSF(Routing Score Fingerprint,路由强度指纹)
对每个任务 i、每个 expert j、每一层 l,统计「该 expert 在该任务数据上的平均 routing logit」,得到一个任务 × 层的矩阵。为了去掉不同层之间的尺度偏差,再做一个 expert 维度上的 mean-centering (减掉同层所有 expert 的均值)。
直观理解:RSF 刻画的是 「这个 expert 在各个任务、各层上被激活得有多强」,是一张细粒度的行为画像。
② RPF(Routing Preference Fingerprint,路由偏好指纹)
把 RSF 沿着层方向求和,再过一个 softmax,得到一个在各任务上的概率分布。
直观理解:RPF 刻画的是 「这个 expert 整体上更偏爱哪个任务」,是一张粗粒度的偏好画像。Victim 的真专家会在自己的目标任务上呈现一个尖锐的尖峰,哪怕被各种篡改过;而对手新加进来的「外来 expert」,因为没有这种任务对齐,分布会相对均匀——这一下就把「李逵」和「李鬼」区分开了。
匹配怎么做? 给定 victim 的 expert j 和 suspect 的 expert k:
- RSF 之间算 cosine 相似度;
- RPF 之间算 Jensen-Shannon 散度,再转成相似度(1 − JSD);
- 两个一平均,得到最终的指纹相似度。
最后看一个 suspect expert 跟所有 victim expert 的相似度 profile:如果有唯一一个明显的尖峰,就判定它是被盗用的,并归属到对应的 victim expert;如果一片均匀没有明显赢家,就当它是新引入的。
就这么简单。没有花哨的训练,没有额外的网络,全是可解释的统计量。
7. 效果:该扛住的全扛住了
光说思路漂亮没用,得看它在各种「攻击」下扛不扛得住。下图是六种场景下的指纹相似度矩阵——对角线越红(越高)说明真专家被认得越准,新专家那几列越均匀说明越不会被误判:
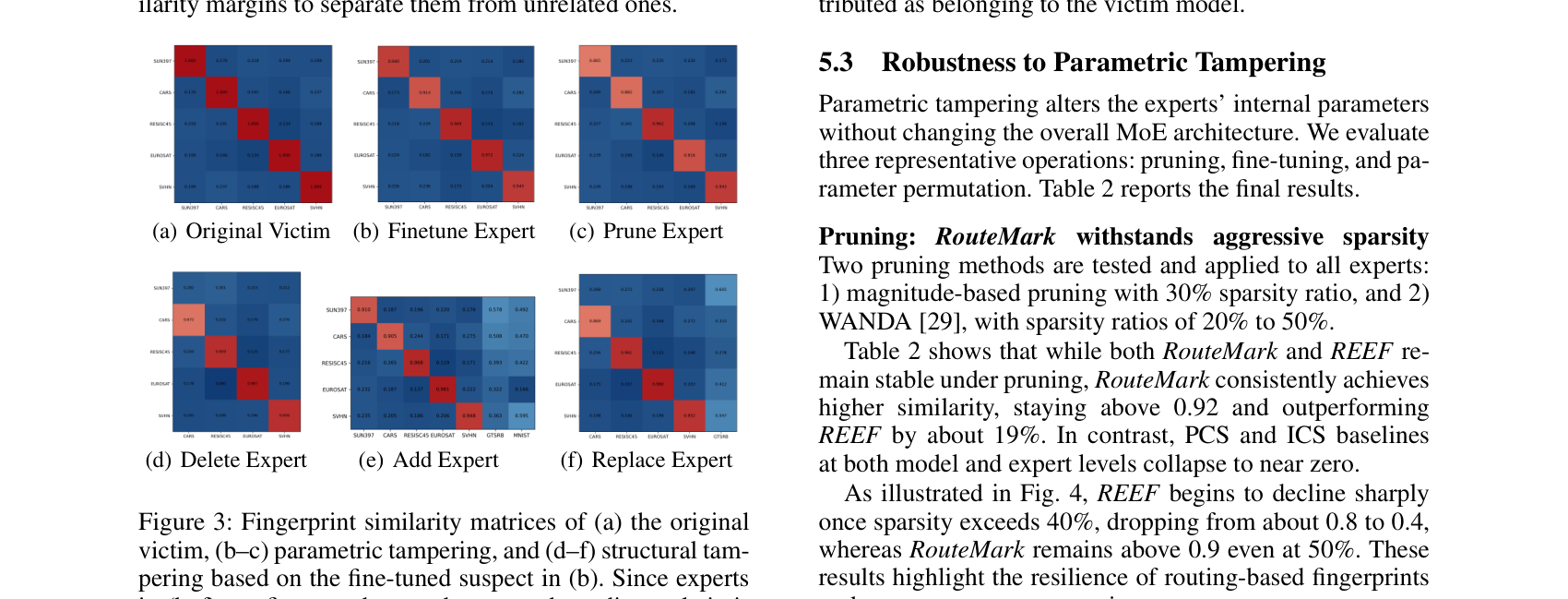
几个最能说明问题的数字(victim 是 5 个专家的 CLIP MoE,前三项是参数级篡改,第四项是结构级篡改):
- 参数置换(permutation):相似度 1.000,完美识别。而基于权重的 PCS/ICS 直接塌到接近 0——因为权重一重排它们就瞎了,但路由行为压根不受影响。
- 剪枝(pruning):哪怕用 WANDA 剪到 50% 稀疏度,RouteMark 依然 >0.92;作为对比,基于激活的 REEF 一过 40% 稀疏就从 0.8 一路掉到 0.4,权重类方法接近 0。
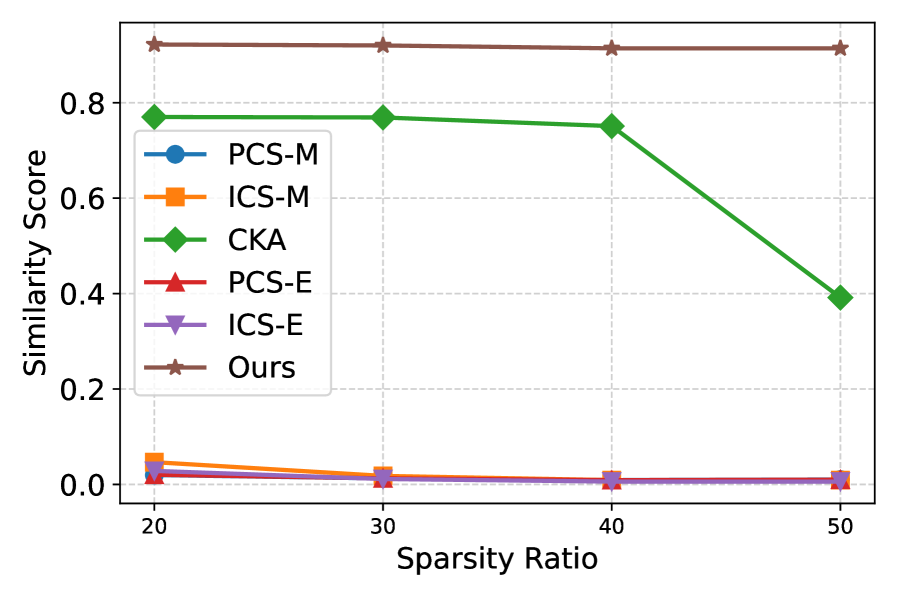
- 微调(fine-tuning):再训 8000 步,相似度还有 0.956;PCS-M 从 0.84 掉到 0.72。
- 结构篡改(替换 / 删除 / 新增 1~3 个专家):被复用的真专家平均相似度稳定在 0.94 以上,而新塞进来的外来专家相似度分布很均匀(margin 只有 0.05~0.10),不会被错误归属。
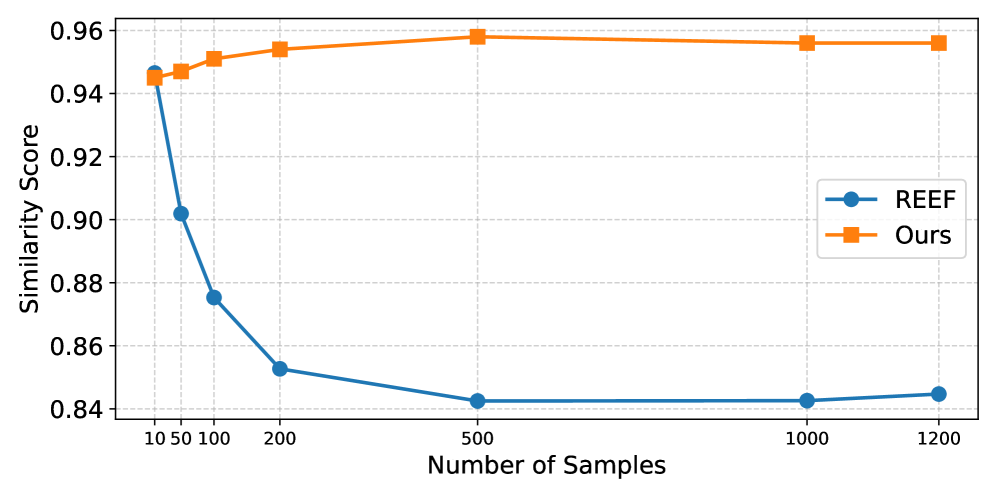
- 样本效率:只用 10 个探针样本,相似度就稳定在 0.94 以上;有意思的是 REEF 反而是样本越多越差——因为样本一多,MoE 中间激活被越来越多专家搅得越来越噪。
总结起来就一句:路由行为是一个比权重、比激活都更稳、更可靠、还能精确到 expert 级别的归属信号。
8. 最后泼盆冷水:这事还没做完
当然,再漂亮的工作也有边界。客观看,RouteMark 至少还有这么几个可以接着做的点:
-
目前是白盒 / 灰盒设定,黑盒才是真正的硬骨头。 先别误会,RouteMark 的用法其实很顺:你怀疑某个 suspect MoE 盗用了你的模型,直接把你自己那套原始探针数据丢进去,读出它的 routing logits 算指纹,再跟你自己 MoE 的指纹比相似度就行——你本来就清楚自己每个专家是干嘛的,所以「得知道专家领域」根本不算门槛。但这背后隐含一个前提:你能拿到 suspect 模型、并且能读到它内部的 routing 信息(白盒 / 灰盒)。真正难啃的是黑盒场景——如果对方只开放一个 API、只给你最终输出,根本拿不到 router 的中间结果,这套指纹还怎么提取、怎么追溯?这才是更现实、也更值得继续做的延伸方向。
-
目前只在 CLIP 视觉专家上验证。 LLM 的 MoE merging、多模态 MoE merging 还没试,这也是论文结尾明确写的未来方向。
-
还没考虑「自适应攻击」。 如果对手知道 RouteMark 这套思路,故意去重训 router、把这种 task-aligned 的路由偏好人为抹平,指纹还守不守得住?这是攻防博弈里绕不开的一环,论文里暂时还没深挖。
但反过来看,正是因为这些坑还没填完,这个方向才有得做。 model merging 只会越来越普及,而「融合时代的版权追溯」这个命题,现在还远没到被解决的程度。RouteMark 提供的是其中一个角度——用「路由行为」来做 expert 级别的追溯;至于黑盒场景、LLM 与多模态的 MoE 融合、以及对抗自适应攻击这些更硬的骨头,都还等着人去啃。
感兴趣的同学可以去翻原文,公式和实验细节都在里面:RouteMark (arXiv 2508.01784)。欢迎评论区交流,有想法或者觉得哪里不对,都可以直接来拍。
整理:marsggbo|知乎 / GitHub: marsggbo