LLMRouterBench:当所有 routing 方法被拉到同一起跑线,结果有些尴尬
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

LLMRouterBench:当所有 routing 方法被拉到同一起跑线,结果有些尴尬
原文:LLMRouterBench: A Massive Benchmark and Unified Framework for LLM Routing 作者:Hao Li, Yiqun Zhang 等(上海 AI Lab)
1. 前言:LLM Routing 到底在解决什么问题
你有没有想过一个很现实的问题:
现在模型这么多——GPT-5、DeepSeek-R1、Qwen3-235B、Claude 4、Gemini 2.5 Pro——每个模型都有自己擅长和拉胯的领域。那是不是可以搞一个 router,每来一个 query 就智能选一个最合适的模型?
这就是 LLM routing 的核心想法。听起来太对了。Model complementarity 是显而易见的——没有任何一个模型在所有任务上都是最好的(这个事实在本文的实验里也再次被确认了)。
但问题在于:这个方向的研究现状比较混乱。 大家各用各的模型池、各用各的评测数据集、各用各的指标,你说你比别人好 2%,但你们用的模型都不一样,怎么比?
所以这篇 LLMRouterBench 做的事情很直接:把所有主流 routing 方法拉到同一个模型池、同一个数据集、同一套评价标准下,重新跑一遍。
结果嘛……有些发现挺让人清醒的。
2. Benchmark 长什么样
先快速过一下 LLMRouterBench 的规模:
- 400K+ instances,来自 21 个数据集(涵盖数学、代码、逻辑、知识、情感、指令遵循、工具使用)
- 33 个模型:20 个 ~7B 轻量模型(performance-oriented setting)+ 13 个 flagship 模型(performance-cost setting)
- 10 个 routing baseline:RouterDC、EmbedLLM、MODEL-SAT、GraphRouter、Avengers、HybridLLM、FrugalGPT、RouteLLM、Avengers-Pro、OpenRouter
- 花了 ~1000 GPU hours + $2,771 API cost 收集数据
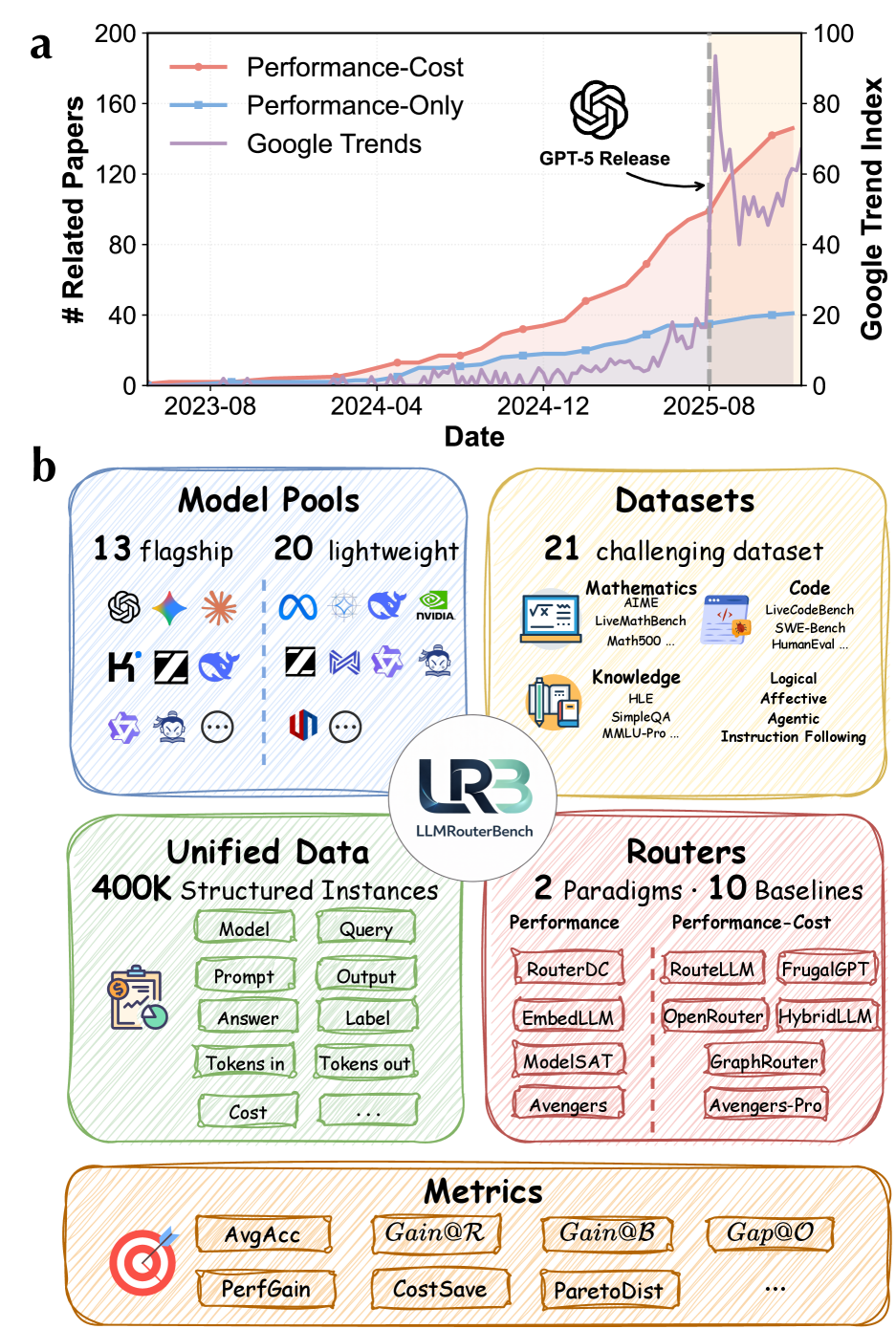
它支持两种 routing 范式:
- Performance-oriented routing:只看准确率,不管成本——从一堆相近大小的模型里挑最好的
- Performance-cost tradeoff routing:同时考虑准确率和推理成本——在更好和更便宜之间找平衡
这个设定比之前的 benchmark 合理得多。之前的 RouterBench 只有 8 个数据集 + GPT-4/Claude v1 这种老模型,RouterArena 甚至各 router 用的模型池都不一样。LLMRouterBench 终于把基本的公平性给补齐了。
3. 实验结果:几个让人清醒的发现
3.1 Model complementarity 是真实存在的——routing 的前提成立
先确认好消息:模型确实互补。
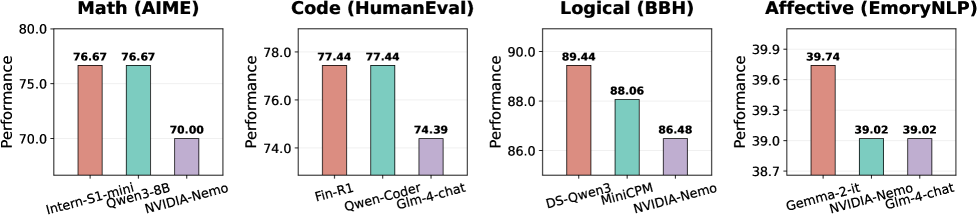
- 数学:Intern-S1-mini 和 Qwen3-8B 领先
- 代码:Fin-R1 和 Qwen-Coder 最强
- 逻辑:DS-Qwen3 和 MiniCPM 占优
- 情感:Gemma-2-it 最好
没有一个模型通吃所有 domain。这说明 routing 的基本前提——”不同问题交给不同专家”——是成立的。
3.2 但所有 routing 方法的表现……几乎一样
这才是本文最关键的发现。当你把 5 种 performance-oriented routing 方法拉到同一起跑线上看:
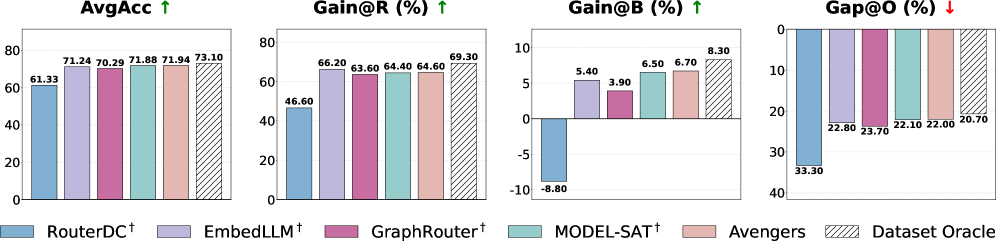
EmbedLLM (71.24)、GraphRouter (70.29)、MODEL-SAT (71.88)、Avengers (71.94)——差距只在 1-2 个点之内。
更值得玩味的是:Avengers 用的只是 k-means clustering + 简单的聚类分配,完全不需要训练神经网络。它的效果和需要 7B/14B 参数训练的 RouterDC、MODEL-SAT 几乎一样好。
这说明什么?论文给的解释我觉得很到位:
目前 routing 方法能学到的,主要是粗粒度的 domain structure(比如”这是数学题应该给 Qwen3”、”这是代码题应该给 Fin-R1”),而不是 fine-grained 的 instance-level 判断。证据就是这些方法的表现都非常接近 Dataset Oracle(按数据集级别选最优模型)。
说白了:现有的 router 本质上只是在做 task classification,不是真正的 per-query routing。
3.3 距离 Oracle 还有巨大 gap——问题出在 model-recall failure
虽然各方法之间差不多,但它们和 Oracle(per-instance 选最佳模型)之间的差距还是很大的:Gap@Oracle 在 20-33% 之间。
为什么?论文分析了一个很关键的现象——model-recall failure:
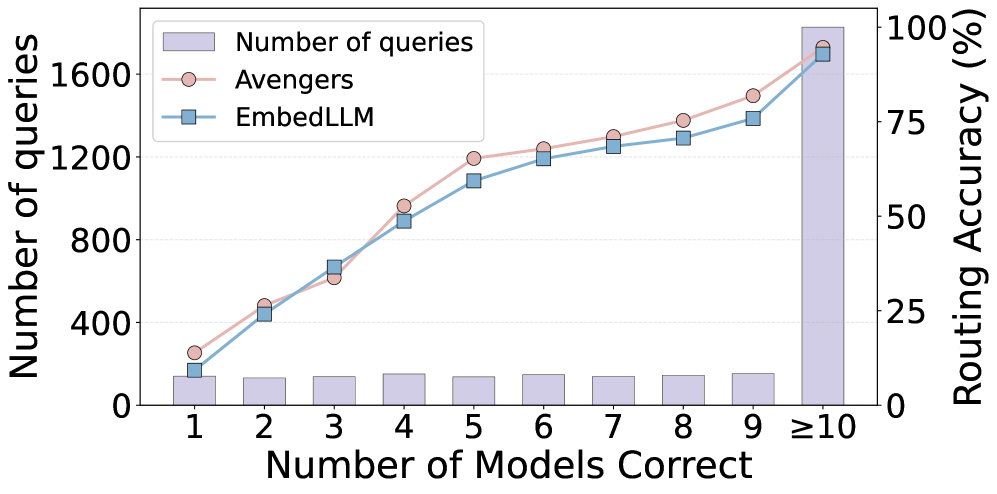
当一个 query 只有 1-3 个模型答对时(占测试集约 11.9%),现有 router 的准确率只有 ~24%。也就是说:越是需要 routing 发挥作用的”难题”,router 反而越不行。
这其实挺反直觉的:routing 的全部价值就应该体现在”找到那个唯一答对的模型”上。但目前的方法在这种最关键的场景下,做得最差。
3.4 Embedding 模型几乎不影响结果
很多 routing 方法(GraphRouter、EmbedLLM、Avengers)都依赖 embedding 模型来表征 query。你可能会觉得,换个更好的 embedding 应该能提升 routing 质量吧?
实验结论:几乎没差别。
把 7B 的 gte-qwen2-7B-instruct 换成 22.7M 参数的 all-MiniLM-L6-v2(小了 300 倍),routing 性能差异不到 2 个点。
这进一步说明:当前 routing 的瓶颈不在 query representation,而在于 routing decision mechanism 本身。 你再好的 embedding 也救不了一个只能做 domain-level classification 的 router。
3.5 模型池越大不一定越好——精选子集更有效
这个发现对工程实践很有价值:
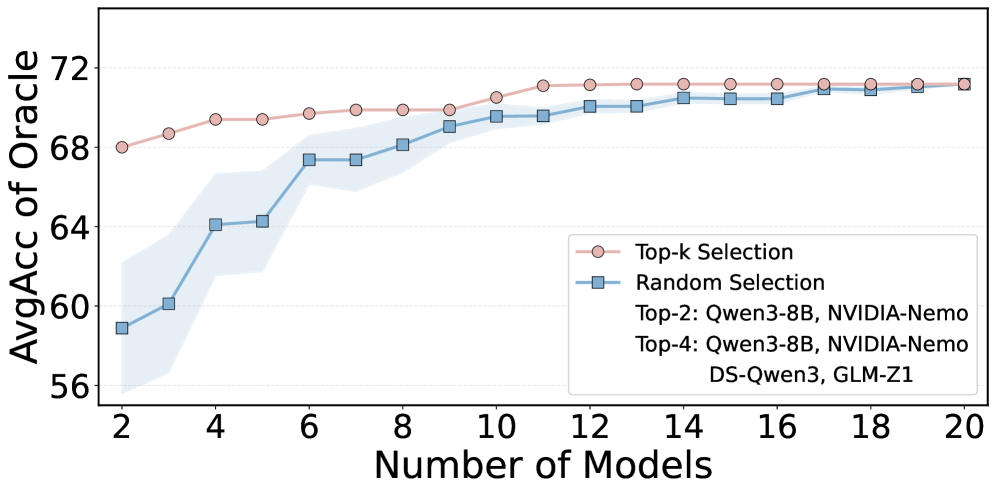
- 随机加模型到池子里,收益递减非常明显——从 2 个到 6 个模型时 Oracle 提升很大,之后几乎就平了
- 精心挑选的 top-4(Qwen3-8B, NVIDIA-Nemo, DS-Qwen3, GLM-Z1)就能达到接近 20 个模型随机组合的效果
启示:与其维护一个巨大的模型池,不如花精力做好 model curation——选一组互补性强的模型子集。
4. Performance-Cost 场景:商业 router 翻车了
在 performance-cost 场景下,结果更有意思:
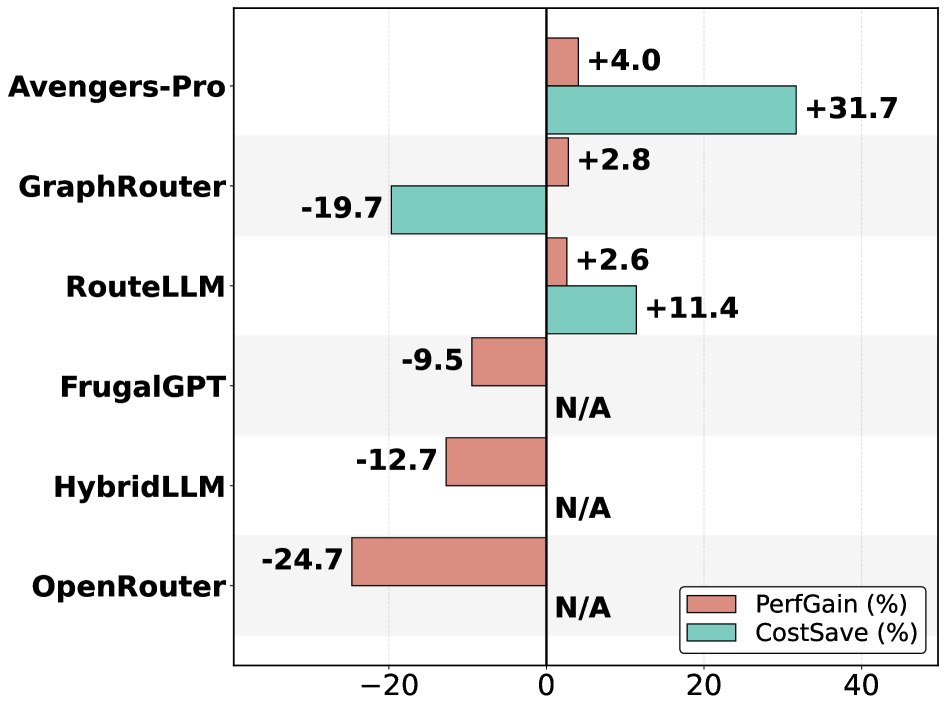
- Avengers-Pro:+4% 准确率、节省 31.7% 成本,是唯一一个同时做到”更好”且”更便宜”的方法
- RouteLLM:+2.6% 准确率、节省 11.4% 成本
- OpenRouter(商业 router):准确率反而下降 24.7%,成本还没省下来(N/A)
没错,花钱用的商业 routing 服务,效果还不如直接用 Best Single 模型(GPT-5)。
Pareto frontier 分析更直观:
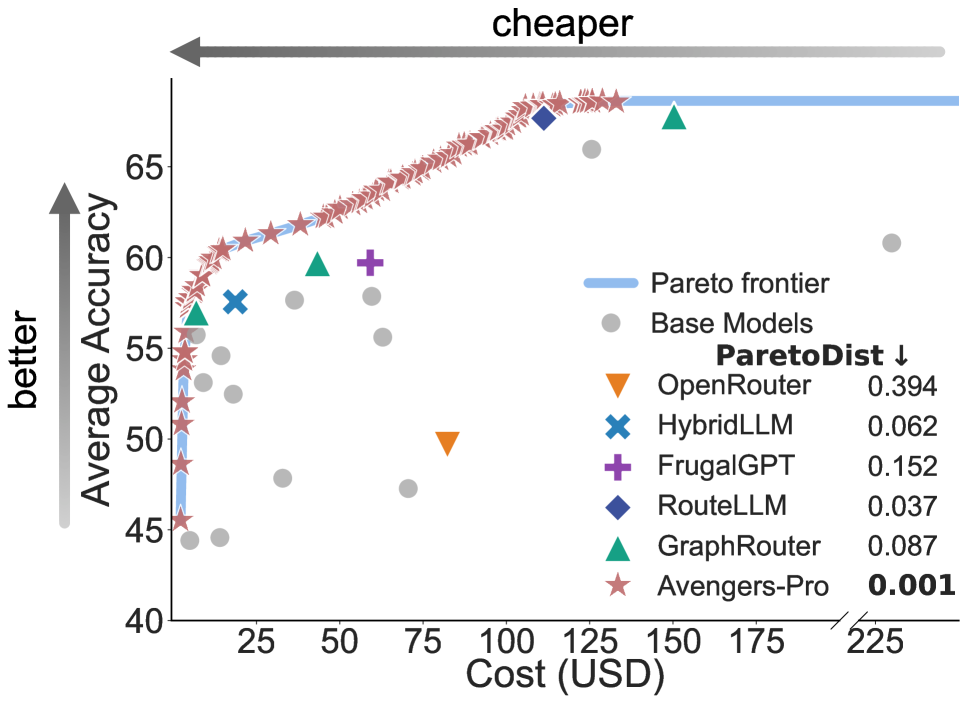
Avengers-Pro 几乎霸占了整条 Pareto frontier(ParetoDist = 0.001),而 OpenRouter 离 frontier 最远(0.394)。也就是说:一个基于 k-means clustering 的免训练方法,在性能-成本 tradeoff 上全面碾压了商业 router。
这个结论对行业的冲击挺大的。
5. 为什么 LLM Routing 这个方向依然值得做
看完上面的结果你可能会想:routing 是不是不行了?
不是。恰恰相反——Oracle 和现有方法之间巨大的 gap 说明这个方向远没有到头。问题只是目前的方法还太”粗”了。
几个我觉得值得继续挖的方向:
1. 从 domain-level routing 到 instance-level routing
当前 router 基本只学会了”数学题给数学模型”这种粗粒度分配。但 Oracle 告诉我们:即使是同一个 domain 内,不同 instance 的最优模型也差异巨大。如何做到 per-query 的精准 routing——尤其是那些只有 1-2 个模型能答对的 hard cases——这是核心挑战。
2. Model curation 和 routing 应该联合优化
论文已经证明了:精选子集 > 简单堆模型。但目前没人在认真做”routing-aware model selection”——先选一组互补性最强的模型子集,再针对这个子集训练 router。这两件事应该是 joint 的。
3. 超越 accuracy/cost:latency 是第三个维度
论文还展示了一个 latency 分析:Qwen3-Thinking 和 GLM-4.6 在准确率和成本上差不多,但 latency 差了 8 倍(262s vs 32s)。用户体验角度看,这完全是两个东西。Performance-cost-latency 三目标优化几乎没人做。
4. Routing 需要 uncertainty estimation
Model-recall failure 的本质是:router 不知道自己不确定。如果 router 能估计自己的 confidence,在低 confidence 时尝试多个模型或走 ensemble,那 recall rate 会好很多。
5. 训练数据效率问题
RouterDC 需要 7B 参数训练,MODEL-SAT 需要 14B,但效果和不需要训练的 Avengers 一样。这说明当前的训练方式效率极低——大部分参数都在学 domain boundary 而不是 instance-level signal。
6. 对工程实践的建议
如果你现在要在产品里加 LLM routing,这篇论文的结论其实给了非常实操的指导:
-
别急着上复杂 router。一个简单的 k-means clustering(Avengers/Avengers-Pro 方案)就能达到 SOTA 水平,而且免训练、轻量、好维护。
-
模型池不要贪多。4-6 个精选的互补模型 > 20 个随机堆的模型。把精力放在选对模型上,而不是 router 算法上。
-
别信商业 router 的宣传。至少 OpenRouter 在这个 benchmark 下的表现是显著低于 Best Single 的。在你用之前,先验证它在你的 use case 上是否真的比直接调 GPT-5 好。
-
Embedding 模型不值得纠结。一个 22M 参数的小 embedding 模型就够用了,不需要上 7B 的 embedding backbone。
7. 结尾
回到最开始的问题:LLM routing 这个方向有前景吗?
我的判断是:前景巨大,但当前方法还太初级。
Oracle 告诉我们上限在 91.64%(performance-oriented)和 85.66%(performance-cost),而现有最好的方法只到 71-68%。这个 20+ 个点的 gap 全是研究机会。
但这篇 benchmark 也给出了一个很清醒的 warning:不要假装自己在做 fine-grained routing,实际上只是在做 domain classification。 如果你的方法不能在 “只有 1 个模型答对” 的 hard cases 上显著超过 random,那你本质上没有解决 routing 的核心问题。
这也是整个行业需要直面的核心矛盾:model complementarity 是真实的、巨大的,但当前的 routing mechanism 远没有 good enough 去 exploit 它。
谁能解决这个 gap,谁就定义了下一代 LLM serving 的基础设施。