EuroSys'26 | LLMFolder 用常量折叠把 FFN 参数砍 80%,精度反超剪枝方法 65%
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

EuroSys’26 | LLMFolder 用常量折叠把 FFN 参数砍 80%,精度反超剪枝方法 65%
原文:LLMFolder: Revisiting Constant Folding in Large Language Models(EuroSys 2026) 作者:Gansen Hu, Zhaoguo Wang, Wei Huang, Jinglin Wei, Haibo Chen(上交 IPADS 实验室)
1. 前言
今天想和大家聊一篇角度很新颖的工作——LLMFolder,来自上交 IPADS 实验室,发在 EuroSys 2026。
这篇论文的出发点是个很自然的问题:LLM 太大了,部署成本高。缓解这个问题的主流手段是剪枝(pruning)——把不重要的权重去掉。但剪枝有个大坑:压缩比一高,精度掉得很厉害。比如压缩到 80%,accuracy 可能就已经难以接受了。
作者换了个角度:既然剪枝是”选择性地丢掉权重”,能不能换一种不丢权重、而是把权重合并的思路?
这个思路的灵感来自编译器里的经典优化:常量折叠(Constant Folding)。
先看一张图感受一下背景:LLM 推理的时间花在哪里?
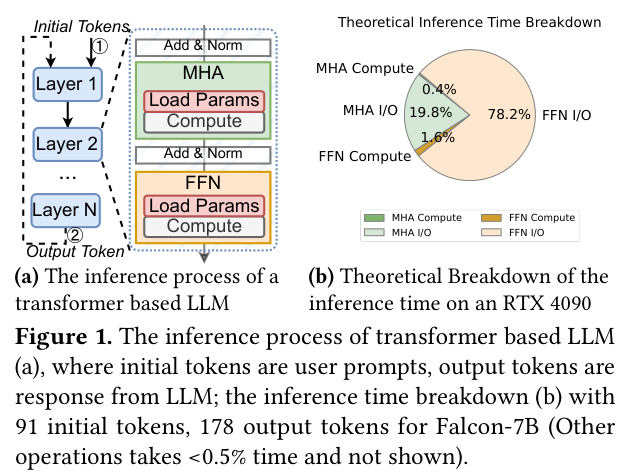
图(b)是一块 RTX 4090 上的理论时间分解:FFN 的 I/O 占了 78.2%,而实际计算(FFN Compute)只有 1.6%。LLM 推理是一个极度内存带宽受限的任务,FFN 权重的 I/O 是最大瓶颈。减少 FFN 参数量 = 直接减少 I/O 压力。
2. 背景:编译器里的常量折叠是什么?
先解释下什么是常量折叠,这是这篇论文核心 insight 的出发点。
在编译器优化里,常量折叠是指:把对常量的计算在编译期就预先算好,运行期直接用结果。
最简单的例子:
x = 2 + 3 // 编译期就能算出 x = 5,不需要运行时再算
y = x * 2 // y = 10,同样可以预计算
更重要的是对线性函数的折叠:如果 f(x) = Ax + b 和 g(x) = Cx + d 都是线性变换,那么:
\[g(f(x)) = C(Ax + b) + d = (CA)x + (Cb + d)\]两个矩阵乘法可以合并成一个!参数量直接减半。
现在把这个思路搬到 Transformer 的 FFN 层上。
3. 为什么 FFN 可以「折叠」?
先看一下常量折叠应用到 FFN 的直观图示:
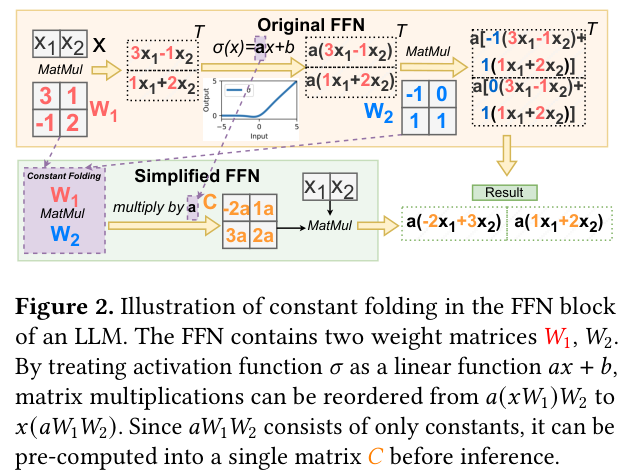
Transformer FFN 层的结构是:
\[\text{FFN}(x) = W_2 \cdot \sigma(W_1 x + b_1) + b_2\]其中 $\sigma$ 是激活函数,$W_1 \in \mathbb{R}^{4d \times d}$,$W_2 \in \mathbb{R}^{d \times 4d}$。
如果激活函数 $\sigma$ 是线性的(比如直接是恒等映射),那么:
\[\text{FFN}(x) = W_2(W_1 x + b_1) + b_2 = \underbrace{(W_2 W_1)}_{\text{折叠后的} W_\text{fold}} x + \underbrace{(W_2 b_1 + b_2)}_{b_\text{fold}}\]原来需要存 $W_1$($4d \times d$)和 $W_2$($d \times 4d$),参数量 $8d^2$;折叠后只需要存 $W_\text{fold}$($d \times d$),参数量 $d^2$,直接砍掉 87.5%!
这就是常量折叠思路应用到 LLM 的核心逻辑。
4. 核心挑战:GELU 不是线性的
问题来了——现代 LLM 基本都用 GELU(或者 SwiGLU)这类非线性激活函数,不能直接套常量折叠。
GELU 的定义是:
\[\text{GELU}(x) = x \cdot \Phi(x)\]其中 $\Phi(x)$ 是标准正态分布的 CDF,这是光滑的非线性函数。有了非线性,$\sigma(W_1 x)$ 就没法和 $W_2$ 合并了。
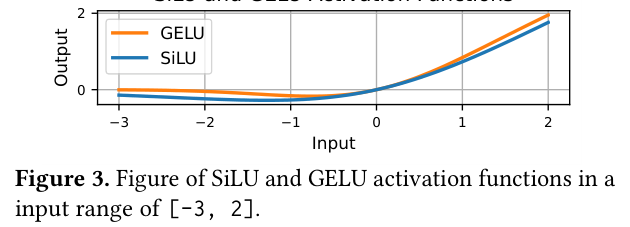
从图中可以看到:在输入接近 0 的区间,GELU 曲线确实接近线性;但在大正值区域增长率与线性不同,在负值区域则会压制到接近 0。这个「部分接近线性」的特性是 LLMFolder 能成立的关键直觉。
那怎么办?
5. LLMFolder 的解法:分段线性近似 + 在线回退
LLMFolder 的核心思路是:观察 GELU 的输入分布,在高频出现的输入范围内,用线性函数近似 GELU。
从实践中观察到:Transformer 的 pre-activation 值大多集中在一个相对固定的数值范围内(绝大部分值不是极端大或极端小的 outlier)。
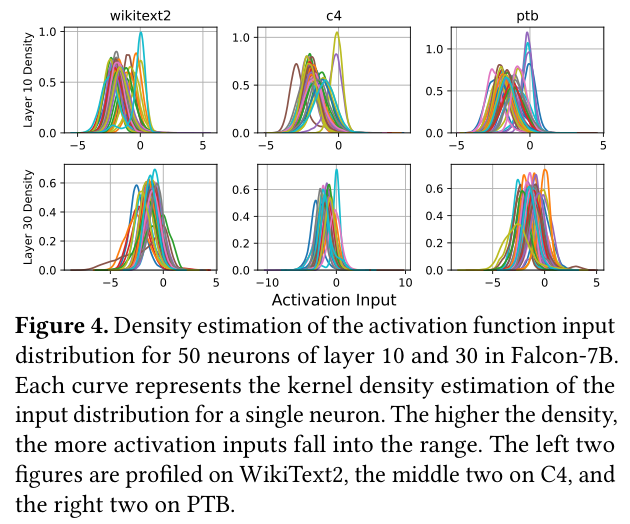
上图是不同模型的 pre-activation 分布密度图。可以看到绝大多数输入值集中在一个相对窄的范围内(分布峰值明显,尾部很轻),这为线性近似提供了统计基础。
在这个「常见范围」内,GELU 的曲线近似于一条直线:
\[\text{GELU}(z) \approx \alpha z + \beta \quad \text{(对于高频输入范围内的 } z \text{)}\]有了这个线性近似,FFN 就可以折叠了:
\[\text{FFN}(x) \approx W_2 \cdot (\alpha W_1 x + \beta \mathbf{1}) + b_2 = (\alpha W_2 W_1) x + (W_2 \beta \mathbf{1} + b_2) = W_\text{fold} x + b_\text{fold}\]对于绝大部分 token:只需要加载 $W_\text{fold}$(参数量 $d^2$),不需要加载 $W_1$ 和 $W_2$(参数量 $8d^2$)。
但对于少数落在「常见范围」以外的 outlier 输入,线性近似误差太大,不能用。
下面是 LLMFolder 的整体架构:
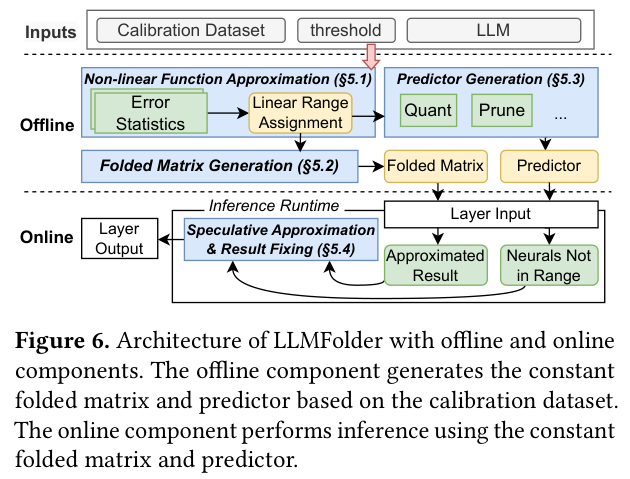
离线阶段:用标定数据集计算激活函数的线性范围,生成折叠矩阵和在线预测器。在线阶段:推理时先用 Speculative Approximation 走折叠路径,如果输入不在范围内则触发 Result Fixing(fallback)。
LLMFolder 引入了一个在线预测器(Online Predictor):
- 在 inference 时,lightweight predictor 检测当前 token 的 pre-activation 是否落在常见范围内
- 如果是:走折叠路径(快,参数少)
- 如果是 outlier:fall back,临时加载原始 $W_1$、$W_2$,用原始 GELU 计算
这个设计的关键点:
- 折叠是离线完成的:训练后将 $W_1$、$W_2$ 折叠成 $W_\text{fold}$,部署时只存 $W_\text{fold}$
- 原始权重按需加载:对于 outlier token,才需要从存储加载原始权重(这是少数情况)
- predictor 开销极小:只需判断输入是否在范围内,不影响主路径
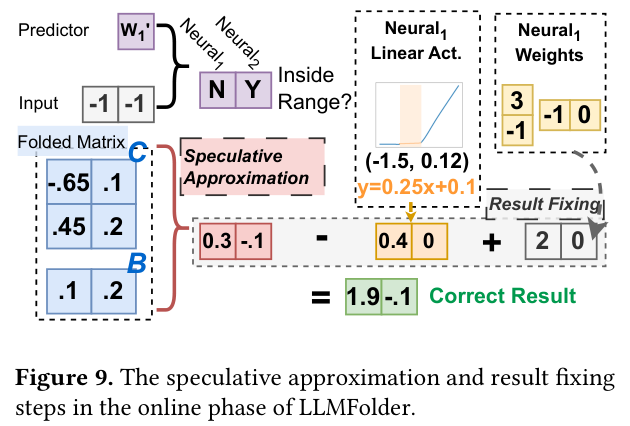
图中直观展示了「推测近似」流程:先用折叠权重计算结果,再检查哪些 neuron 的输入实际上超出了线性范围,对这些 neuron 用原始权重修正结果(Result Fixing)。这样大多数 token 只需访问压缩后的 $W_\text{fold}$,内存带宽节省显著。
6. 与 Pruning 的本质区别
LLMFolder 经常被拿来和 pruning 比较,但两者的思路截然不同:
Pruning:直接把部分权重置零或移除。高压缩比时,模型”能力”实实在在地少了,精度掉是必然的。
LLMFolder:权重不丢,而是重新组织——把两个矩阵”合并”成一个,信息量没有损失(对线性激活而言是精确等价,对 GELU 近似情况下是高频输入范围内的精确近似 + outlier 的精确 fallback)。
这是本质差异,也是 LLMFolder 在精度上大幅领先 pruning 的根本原因。
7. 实验设置
实验在多个 7B 级别模型上进行(论文测了 Llama 系列等模型),对比基线包括:
- 原始模型(无压缩)
- SOTA 剪枝方法(如 SparseGPT、Wanda 等)
- 量化方法
实验平台:使用了 vLLM 和 HuggingFace 两套推理栈,分别评估 end-to-end 性能。
评估维度:
- FFN 参数压缩比
- 下游任务 accuracy(与 SOTA pruning 对比)
- end-to-end 推理加速比
- 与量化/剪枝组合后的联合效果
8. 实验结果分析
8.1 FFN 参数压缩:80%
LLMFolder 在 FFN 层实现了 80% 参数压缩,接近理论上限(线性激活下 87.5%)。对于一个 7B 的 Llama 模型,这意味着显存占用和内存带宽需求大幅下降。
8.2 精度 vs 剪枝方法:领先高达 65%
这是最亮眼的数据。在同等压缩比下,LLMFolder 的 accuracy 比 SOTA 剪枝方法高 最多 65%。
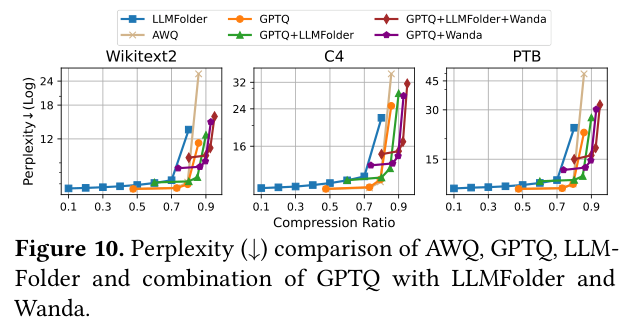
图中横轴是压缩比,纵轴是 Perplexity(越低越好)。蓝色方块是 LLMFolder,在 0.1~0.8 的压缩比区间内 perplexity 几乎平稳,而其他方法(GPTQ、AWQ 等)在高压缩比时急剧劣化。Table 3 有更完整的数字对比:
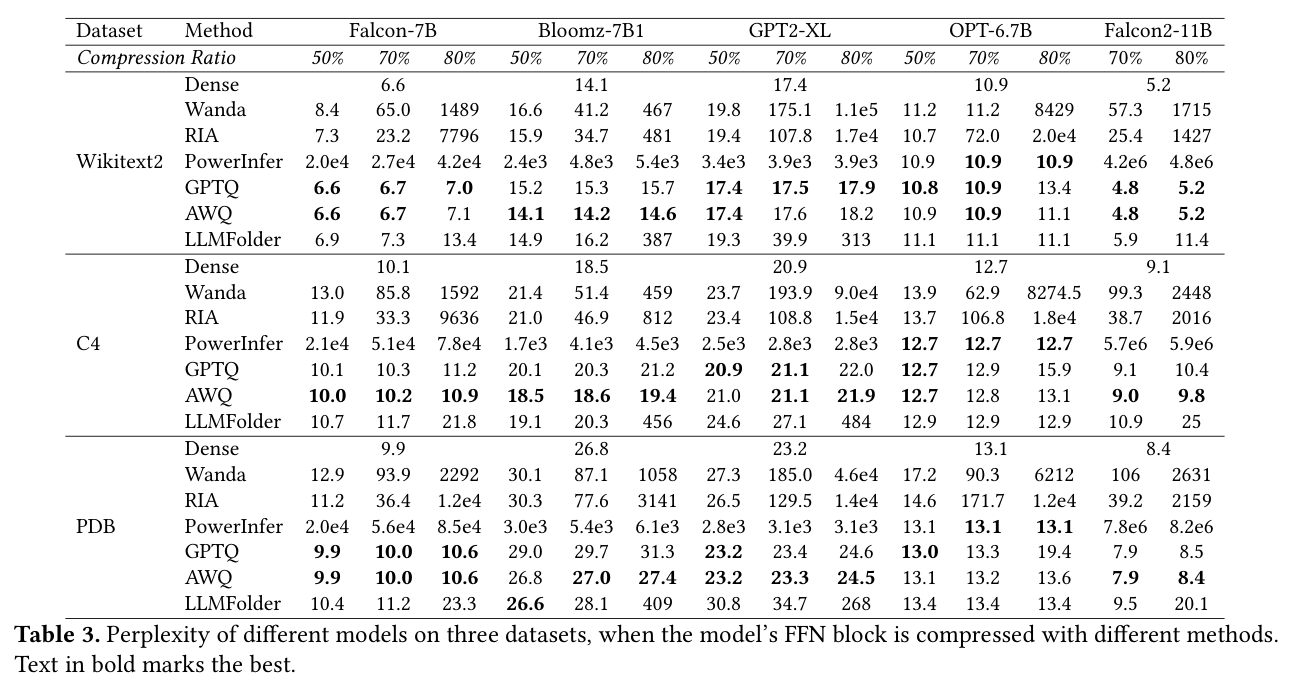
本质原因:
- Pruning 以高压缩比运行时,丢失的权重信息无法恢复,精度崩塌
- LLMFolder 的折叠操作对高频输入是精确的(线性近似误差小),outlier 有 fallback 兜底,精度损失被控制在很小的范围
8.3 与量化+剪枝组合:92.5% 参数压缩,仅 4.4% 精度损失
更惊艳的是:把 LLMFolder 和量化(Quantization)、剪枝(Pruning)三者组合起来,对 7B 模型实现了 92.5% 参数压缩,而 average accuracy 只损失了 4.4%。
论文专门强调:单独用量化或单独用剪枝,或者两者组合,都无法同时实现这个压缩率和精度。LLMFolder 打开了一个新的组合空间。
8.4 端到端推理加速
- vLLM:1.6× 加速,10.9% accuracy 损失
- HuggingFace:1.4× 加速,同样是 10.9% accuracy 损失
vLLM 比 HuggingFace 加速更多,原因是 vLLM 的 continuous batching 对内存带宽更敏感,参数量减少带来的 memory-bandwidth 收益在 vLLM 上放大更明显。
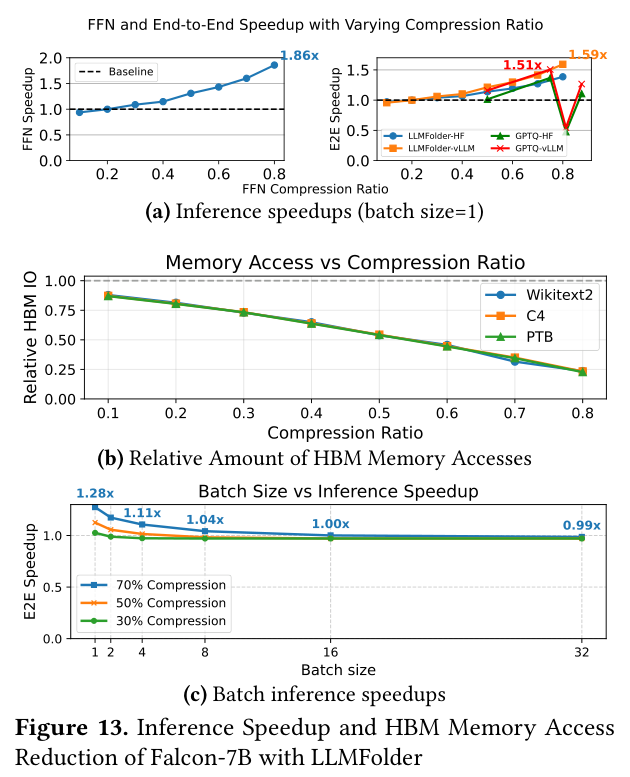
图(a):随着 FFN 压缩比提高,FFN 层加速比线性增长,最高约 1.86×;E2E 加速在压缩比 0.7~0.8 时达到约 1.5×。图(b):HBM 内存访问量随压缩比单调下降,Wikitext2/C4/PTB 三个数据集表现一致,说明折叠效果与 calibration dataset 的选择无关。图(c):batch size 增大后 E2E 加速比有所下降,但 batch=1 时仍有 1.28× 加速。
对于大模型(如 Falcon-40B),加速更为显著:

压缩比 70% 时,Falcon-40B 推理加速可达 6.97×!大模型在单卡上内存带宽更紧张,LLMFolder 的 I/O 节省带来的收益倍增。
另外,实际访问的原始权重比例随压缩比降低:
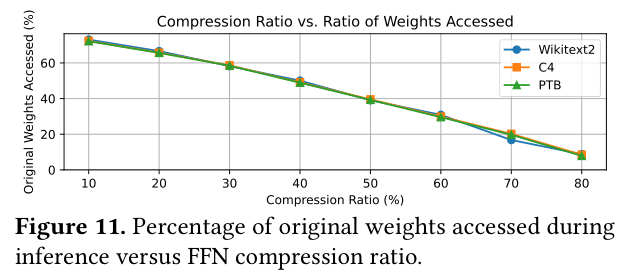
压缩比 80% 时,推理实际访问的原始权重只剩不到 10%——说明大部分 token 都走了折叠路径,fallback 比例极低。
1.6× 加速 + 10.9% 精度代价,这个比值在需要高 throughput 的实际部署场景里相当有吸引力,尤其是对时延不敏感、更在意 cost 的 batch inference 场景。
9. 个人 take
这篇论文让我觉得眼前一亮的点:跨领域 analogy 用得非常漂亮。
常量折叠是编译器里几十年前的经典优化,把它迁移到 LLM 权重压缩这个场景,思路非常简洁——不是”丢掉权重”而是”合并权重”。对模型语义的破坏远小于剪枝,这也直接解释了精度为什么大幅领先。
GELU 的线性近似是这篇工作成立的关键假设。其实这个假设并不显然——pre-activation 分布的「高频区间」到底有多宽?如果模型的 pre-activation 分布不集中(比如在极端 fine-tune 后),线性近似是否还能成立?论文里对这个分布做了充分的 empirical 验证(虽然我这里没有原图),但这个假设在不同模型、不同任务上的鲁棒性值得持续关注。
在线 predictor 的设计也是个 tricky 的地方。Predictor 本身要轻量(否则 overhead 反而把加速吃掉),但也要准确(预测错了 outlier 会导致精度损失)。这里有一个 precision-recall 的 tradeoff:如果太保守(把很多正常值也判断为 outlier,走 fallback),加速比会下降;如果太激进(把 outlier 误判为正常值),精度会损失。
与量化结合的 92.5% 压缩率是最重要的实用贡献。三种技术的正交性是真的强:量化减少每个参数的比特数,剪枝减少参数数量,LLMFolder 减少需要激活路径上的参数量,三者作用维度不同,可以叠加。
当然也有值得关注的局限:
- 目前只针对 FFN 层(Attention 层的 Q/K/V/O 矩阵没有处理)——但 FFN 占 LLM 参数的大头,所以影响够大
- Outlier fallback 的延迟:如果某个 batch 里 outlier token 比例高,实际加速比会下降,worst case performance 值得关注
- SwiGLU(现在最流行的激活)的处理:SwiGLU 引入了 gate 机制,折叠逻辑更复杂,论文里的处理方式值得仔细看
总体来说,这是一篇思路新颖、技术扎实、数字好看的工作,”从编译器借一把刀来砍 LLM 参数”这个角度本身就值得一读。
欢迎评论区讨论,有用过类似折叠思路的同学可以聊聊实践经验~