LLM Agent Memory 全景拆解:从 RAG 到 KV Cache 到参数写入,100+ 篇工作的方法演进与真实取舍
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

LLM Agent Memory 全景拆解:从 RAG 到 KV Cache 到参数写入,100+ 篇工作的方法演进与真实取舍
原文:LLM Agent Memory: A Survey from a Unified Representation–Management Perspective 作者:Zhenheng Tang, Xin He, Tiancheng Zhao 等(A*STAR CFAR / HKUST)
1. 先交代下背景:为什么我们觉得这篇综述有写的必要
你有没有发现一个现象:2024-2025 年几乎所有做 LLM agent 的团队都说自己”加了 memory”,但你去看它们的实现,有人在做向量库检索,有人在做 KV cache eviction,有人在做 LoRA 持续学习——表面同名,底层完全不是一个问题。
这就导致了一个很尴尬的局面:reviewer 问你 “和 XXX memory system 比怎样”,你根本没法比,因为你们根本不在同一层解决问题。
所以这篇综述不是又列一遍论文清单。它想做的事情是:把 memory 这个被滥用的词还原成一个可拆分、可比较、可设计的系统问题。
核心切法很清晰——任何 LLM memory 机制都可以拆成两个正交维度:
- 表示层 (Representation):信息以什么形式存在——文本 token、KV cache 中间状态、还是模型参数?
- 管理层 (Management):信息怎么建、怎么改、怎么取——construction、update、query 三件事哪个是瓶颈?
下图是整个框架的总览:
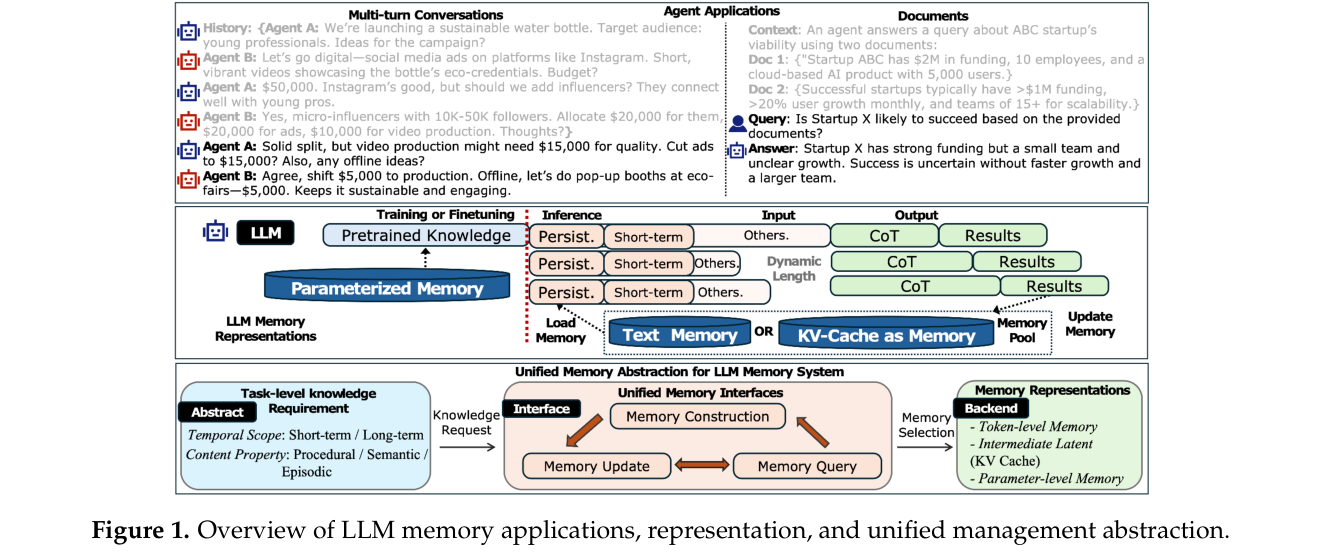
上层是应用场景(多轮对话、文档问答),中间层是三种 memory 表示,下层是统一的管理接口抽象。这张图最有价值的地方不是分类本身,而是它揭示的一个事实:不同 memory 方向的研究者其实在用同一套管理语义(构建、更新、查询)去操作不同的存储后端。
一旦你接受了这个统一视角,很多看似不相关的工作就突然可以互相对话了。
2. Token-level Memory:检索的演进远比你以为的深
2.1 RAG 的真实演进路线:从 naive retrieval 到可控 pipeline
大部分人对 RAG 的印象还停留在”向量检索 + 拼 prompt”,但如果你把最近两年的方法按技术路线排开,会发现它其实已经经历了三代演进:
第一代:静态检索。 BM25 或 dense embedding 做一次检索,把 top-k 结果直接拼到 prompt 里。问题很明显——query 和检索 granularity 不匹配的时候,结果很差。
第二代:Query 重构与增强。 这里出现了一批很重要的工作:
- CoVe (Dhuliawala et al., 2023):先让模型对自己的答案做 verification,再检索,减少 hallucination
- Step-back prompting (Zheng et al., 2024):把具体 query 抽象成更高层的问题再去检索,拿到互补证据
- HyDE (Gao et al., 2022):先让模型生成一个假设性答案,再用这个假设答案去检索真正的文档
这一代的共同 insight 是:检索质量的瓶颈往往不在索引端,而在 query 端。一个精心重构的 query 比更好的 embedding 模型带来的提升大得多。
第三代:动态可控检索。 这才是真正让 RAG 从”管道”变成”系统”的一步:
- DSP (Khattab et al., 2022):把检索和生成拆成可组合的模块化 pipeline
- FLARE (Jiang et al., 2023):在生成过程中动态判断何时需要检索——只在 confidence 低的时候触发
- Self-RAG (Asai et al., 2023):训练模型本身输出 reflection token,让它自己决定是否检索、检索的结果是否有用、自己的生成是否 faithful
Self-RAG 之所以重要,不只是因为它好用,而是它代表了一个范式转移:检索不再是外部系统强加的,而是模型自身 reasoning 流程的一部分。这就把 memory query 从 “engineering heuristic” 提升到了 “learnable decision”。
2.2 Agentic Memory:从 log 到 evolving knowledge
RAG 处理的是相对静态的外部语料。Agentic memory 要解决的是一个更难的问题:agent 自己的交互历史怎么变成可复用的知识。
关键区别在于:agent memory 不只是”存下来再查”,而是需要持续演化。
看一下这条技术线的演进:
- MemoryBank / RET-LLM (Zhong et al., 2024; Modarressi et al., 2023):最早的做法,对对话历史做摘要存下来
- HippoRAG (Gutiérrez et al., 2024):引入 knowledge graph 结构,让记忆之间有 relation
- A-MEM (Xu et al., 2025):不只是存储,而是让 memory 自己去合并、裂变、重组
- Synapse (Zheng et al., 2024) / SCM (Wang et al., 2024):引入 self-reflection 和 memory blending
这里最值得注意的 insight 是:区分一个 agentic memory 系统是不是真正有价值的,关键不在于它怎么存,而在于它怎么”忘”和怎么”变”。
单纯存得多没有用,甚至有害。一个 agent 跑 1000 轮之后,如果不做 memory evolution(选择性遗忘、冲突消解、抽象化),它的 memory 就会退化成一个高噪声的 log——这几乎必然拖垮 query 质量。
Reflexion (Shinn et al., 2024)、BoT (Yang et al., 2024) 和 ReAct (Yao et al., 2022) 代表了另一条相关的线:让 agent 对自己的经验做 reasoning 和 self-reflection,把”经历”变成”教训”再存入 memory。这比 raw experience replay 有效得多。
3. KV Cache Memory:一个被低估的系统问题
3.1 四条技术路线与它们的 OS 对应物
这是我个人觉得这篇综述整理得最有价值的一节。KV cache 的工作数量爆炸式增长,但如果你站远一步看,几乎所有方法都可以映射到操作系统或数据库里的经典问题:
| KV Cache 方法类别 | OS/DB 对应概念 | 代表工作 |
|---|---|---|
| Eviction & dropping | Page replacement (LRU/LFU) | H₂O, StreamingLLM, FastGen, NACL |
| Merging & compression | Data deduplication / compaction | CaM, D2O, similarity-based merge |
| Quantization & low-rank | Lossy compression / tiered storage | KIVI, KVQuant, Gear |
| System-aware allocation | NUMA-aware / disaggregated memory | vLLM PagedAttention, Mooncake |
H₂O (Zhang et al., 2023) 本质上做的事情是:统计每个 token 在过去所有 attention 计算中被关注的累积分数,优先保留”重度命中”的 token。这几乎就是 LFU (Least Frequently Used) 的翻版。
StreamingLLM (Xiao et al., 2024) 更有意思:它发现”第一个 token 的 attention sink 现象”——模型总会把一些 attention 分配给第一个 token,不管内容是什么。于是它永久保留前几个 token + 最近几个 token 的 KV,中间全部丢掉。这本质上就是 pinned pages + sliding window。
QUEST (Tang et al., 2024) 和 TokenSelect (Wu et al., 2025) 走的是 query-dependent selection:不是对所有 query 用同一套 cache,而是每次 attention 计算只选择和当前 query 最相关的 KV subset。这非常接近 demand paging——只有被”访问”到的 page 才加载进来。
3.2 为什么我说 KV cache 不只是”推理优化”
很多人会把 KV cache 压缩归类到”推理加速”里。但从这篇综述的视角看,它其实在回答一个更本质的问题:
当 context 越来越长,模型内部的 working memory 该怎么管理?
考虑一个实际场景:一个 agent 在执行 100 步的长任务。每步生成都需要 attend to 前面所有步骤的 KV cache。到第 80 步时,可能 step 3-20 的信息完全不会再被用到了,但 step 45 的关键决策需要一直被记住。
这时候 KV cache management 面对的就不是”压缩”问题,而是一个真正的在线内存管理问题——你需要在 latency constraint 下做出 evict/keep/merge 的实时决策,而且这个决策的质量直接决定了 agent 后续推理的正确性。
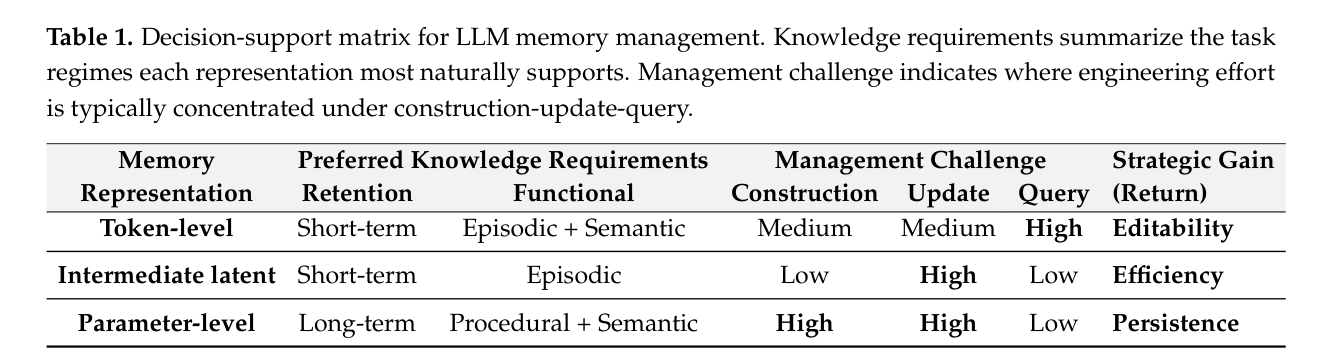
Table 1 给出的判断非常精准:Intermediate latent memory 的核心瓶颈在 update(什么时候丢什么),而不是 construction 或 query。
3.3 Steering Vectors:一种被低估的”行为记忆”
这篇综述还把 steering vectors 归入了 intermediate latent memory,我觉得这个归类相当有洞察。
Steering vectors 是什么?简单说就是一组方向向量,注入到模型中间层的 activation 里,可以持续改变模型的行为倾向(比如让它更 truthful、less toxic、或者更像某个 persona)。
演进路线:
- PPLM (Dathathri et al.):最早的尝试,用梯度引导 hidden states
- Turner et al., 2023:contrastive 方法——用”好行为”和”坏行为”的 activation 差作为 steering direction
- Arditi et al., 2024:把 refusal behavior 定位到具体的 steering direction 并移除
- Hernandez et al., 2023:optimization-based,用单个样本就能学出 steering vector
为什么说它是”行为记忆”?因为 steering vector 本质上编码的是持久的行为偏好(不是事实知识),以一种不需要在每次推理时重新指定的方式存在于模型里。它和 KV cache 的区别是:KV cache 存的是”当前会话的上下文状态”,steering vector 存的是”跨会话的行为倾向”。
但 steering vector 目前的局限也很明显:contrastive method 依赖精心构造的对比数据,很容易捕获到 spurious correlation 而非 causal direction。这也是为什么 probe-based 和 low-shot 方法(Li et al., 2024; Cao et al., 2024)在尝试解决鲁棒性问题。
4. Parameter-level Memory:写入成本决定了研究格局
4.1 为什么这条线的工作最”碎”
如果你看参数层面的 memory 工作,会发现一个有趣现象:研究方向极其分散——continual learning、knowledge editing、PEFT、model merging、task arithmetic 都算,但大家之间几乎不互引。
原因在于:参数写入的成本太高了,没有任何一个方法能做到”对所有类型的知识都通用”,于是每种方法都只能在自己的 niche 里深耕:
- EWC / TaSL / POCL:防灾难性遗忘——先算哪些参数对旧知识重要,再限制这些参数的更新幅度
- Knowledge editing (ROME, MEMIT):精准改一个事实,但只能处理”单跳事实”,multi-hop 效果就崩
- LoRA / PEFT:轻量级适配,但本质上是在编码 task-specific bias,不是 factual memory
- Model merging (TIES, DARE, Model Breadcrumbs):把多个 fine-tuned model 合成一个,用参数空间的向量运算解决
这些方法看似差异巨大,但如果用这篇综述的框架来看,它们都在回答同一个问题:
如何在不破坏已有能力的前提下,让参数空间对新信息产生可控的、局部的响应。
4.2 Task Arithmetic 与 Model Merging:参数空间的”向量记忆”
这里面我觉得最有启发性的方向是 task arithmetic(Ilharco et al., 2023)。
它的核心思想很简单但很漂亮:把 fine-tuning 后的模型减去 base model,得到一个”任务向量”(task vector)。这个向量可以被加减组合——加上它就获得某种能力,减去它就移除某种能力。
这意味着参数 memory 在某种意义上可以被”可编辑化”了。你不需要重新训练,只需要做向量运算就能组合多种知识。
当然,现实没这么美好。Task vector 之间会有 interference(两个任务向量加在一起可能互相抵消),这也催生了 TIES(修剪冲突参数)、DARE(随机 drop 低幅度参数)等后续工作。
但方向是对的:让参数层面的写入变得更 composable、更 reversible,是参数 memory 最有前景的演进方向之一。
5. 三层之间的真正 insight:瓶颈转移定律
如果你把上面三节的分析放在一起看,会发现一个非常有意思的规律:
Memory 的写入成本和查询成本成反比。写入越便宜的 memory,查询越贵;写入越贵的 memory,查询越廉价。
具体来说:
- Token memory:写入几乎无成本(直接存文本),但查询极贵(要在海量文档中精确检索)
- KV cache:写入成本中等(forward pass 自然产生),但维护成本高(要不断 evict/merge/compress)
- Parameter memory:写入极贵(需要 fine-tune 或 editing),但查询几乎为零(推理时自动激活,不需要额外检索步骤)
这不是巧合。这和计算机体系结构里的 存储层次 (memory hierarchy) 规律完全一致:寄存器快但小且贵,DRAM 大但慢,磁盘最大最便宜但最慢。
所以论文给出的 practical guideline 非常实用:
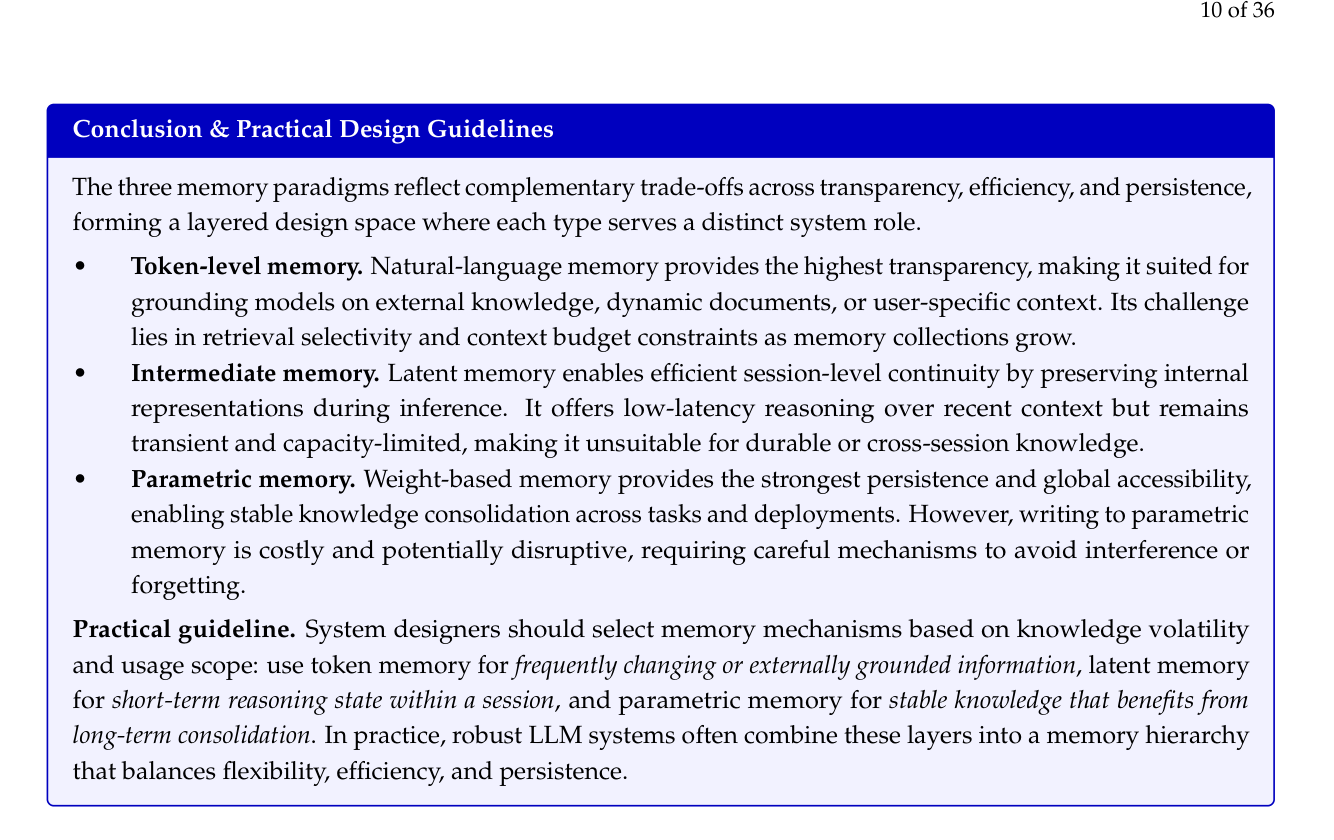
翻译成工程语言就是:
- 频繁变动的信息 → token memory(向量库、RAG)
- 会话内的推理状态 → KV cache(intermediate latent)
- 稳定的长期知识 → 参数(fine-tune、model merge)
一个健壮的 LLM agent 系统,最终一定是多层 memory 的组合,就像操作系统同时有 L1/L2 cache、RAM、SSD 一样。问题只是:谁来做跨层的 routing 和 scheduling。
6. 未来方向:不是更 fancy 的方法,而是更成熟的系统思维
6.1 跨层 Memory Routing 与联合调度
目前几乎所有系统都是各层独立工作:RAG 是一套检索逻辑,KV cache 有自己的 eviction policy,参数更新走单独的 fine-tuning pipeline。三者都在试图让模型”记住对的信息”,但没有人在做统一的调度。
想象一下:如果一个 agent 发现某条信息被 RAG 检索了 50 次,是不是应该考虑把它”下沉”到 KV cache(prefix caching)甚至直接 consolidate 到参数里?反过来,如果某个参数化的知识过时了,是不是应该”浮上来”到 token memory 层用新数据覆盖?
这就是 memory tiering——数据库和存储系统里早就成熟的东西,但在 LLM 领域几乎没有工作在认真做。
6.2 从 OS 借鉴的不只是 eviction policy
这篇综述在 Appendix C 明确指出了三个跨学科迁移方向:
- OS page management → KV cache:不只是 LRU/LFU,还有预取(prefetch)、copy-on-write、huge pages 等概念都有对应
- 数据库 query optimization → RAG query:Cost-based optimizer、query plan selection、materialized view 都可以借鉴
- 分布式系统 → 多节点 memory 协同:Mooncake、DistServe 这类工作已经开始把 KV cache 做成 disaggregated service
最有潜力的方向可能是 “LLM memory 也该有 garbage collector”。目前 agent memory 几乎都是 append-only 的——信息只增不减(或者简单地按时间丢弃)。但一个真正长期运行的 agent 需要类似 GC 的机制:定期检测 unreachable 或 contradicted 的记忆碎片并回收。
6.3 Unified Training–Inference:模糊训练和推理的边界
这是最激进但也最有前景的方向。
目前 LLM 的训练和推理是严格分离的:训练时学知识,推理时只能读。但长期运行的 agent 必然需要在使用过程中不断学习新东西。
- Continual learning(EWC, TaSL)已经在做这件事,但成本太高
- PEFT + online fine-tuning 能做轻量级适配,但精度有限
- Memory consolidation——像人类睡眠时做的那样,把 episodic memory 定期整合进 semantic memory(参数)
未来可能出现的架构:agent 在推理时用 token memory + KV cache 做”快思考”,定期(比如空闲时)把高频使用的 memory pattern consolidate 成参数更新,实现真正的”学习-使用”闭环。
7. 看完之后的一些个人 take
-
Memory research 的下一个爆发点不在任何单层,而在跨层协同。谁先把 memory routing 做好,谁就定义了下一代 agent 基础设施。
-
KV cache 方向已经进入”方法论内卷期”。eviction + merging + quantization 排列组合可以无限水文章,但真正有影响力的下一步应该是 system-level memory management(像 vLLM PagedAttention 那样改变整个范式的东西)。
-
Agentic memory 的关键不在”记住”而在”忘记”和”重组”。A-MEM、Synapse 这类做 memory evolution 的工作比单纯做 memory bank 有前途得多。
-
Steering vectors 作为”行为记忆”被严重低估了。如果未来每个 user 的 persona preference 都能编码成一个 steering vector 并在推理时注入,这就是真正 zero-cost 的个性化——不需要 per-user fine-tuning。
-
系统领域的同学应该认真看 LLM memory。这里面大量问题(cache replacement、tiered storage、query optimization、garbage collection)都是你们已经解决过的——只是换了个 domain。
写到这里差不多了。如果让我用一句话总结这篇综述给我最大的启发:
LLM memory 不是一个功能模块的设计问题,而是一个完整的存储系统设计问题——带着所有存储系统该有的层次、调度、一致性和生命周期管理。
谁先用系统的视角去设计 memory,谁就能做出真正能长期运行的 agent。