多 Agent 协作不需要说「人话」?LatentMAS 让 LLM 在隐空间里直接协作
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

多 Agent 协作不需要说「人话」?LatentMAS 让 LLM 在隐空间里直接协作
1. 前言
你有没有想过,当我们让多个 LLM agent 协作解题的时候,它们之间到底在交流什么?
答案是:文本。一个 agent 花了几千个 token 把推理过程写成自然语言,传给下一个 agent,下一个 agent 再花几千个 token 来理解和继续推理。整个过程就像两个程序员用微信聊天来 pair programming——能用,但效率低得离谱。
这个问题在当前的多 Agent 系统(MAS)里是普遍存在的。无论是 AutoGen、CAMEL 这类经典框架,还是 Chain-of-Agents 这种流水线设计,agent 之间的通信全部依赖自然语言。每个 agent 都要先把”想法”编码成离散 token,传给下一个 agent,再从 token 解码出”想法”——这个过程本身就在丢信息、加延迟。
但仔细想想,LLM 内部推理的时候,用的根本不是 token,而是 hidden states——一个高维连续向量空间里的表示。token 只是最后被 LM head 解码出来给人看的”翻译”。那一个自然的问题就来了:agent 之间能不能直接传 hidden states,跳过文本这个”中间商”?
来自 Princeton、UIUC 和 Stanford 的一个团队最近提出了 LatentMAS,一个完全在隐空间(latent space)里实现多 Agent 协作的框架——不训练、不微调、不生成中间文本,agent 之间直接通过 KV cache 传递”思维”。在 9 个 benchmark 上,准确率最高提升 14.6%,推理速度快 4-4.3×,token 消耗减少 70.8%-83.7%。
今天想和大家聊聊这个工作背后的设计思路,以及它为什么可能是多 Agent 系统的一个新范式。
2. 为什么文本通信是瓶颈?
先交代下背景。现在的 LLM-based MAS 主要有两种架构:
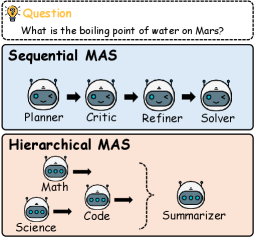
- Sequential(链式):planner → critic → refiner → solver,前一个 agent 的输出喂给后一个
- Hierarchical(层级式):多个领域专家 agent 各自推理,最后由一个 summarizer 汇总
不管哪种架构,agent 之间的通信介质都是文本。这带来三个问题:
| 第一,信息瓶颈。LLM 内部 hidden state 的维度通常是 2048-5120,一个向量就能编码丰富的语义信息。但编码成 token 之后,每个 token 只是一个离散符号,从 $ | V | \approx 150000$ 的词表里选一个——信息密度断崖式下降。论文里有个很直观的定理:**要用 token 无损表达 $m$ 步 latent thoughts,需要的文本长度至少是 $\Omega(d_h \cdot m / \log | V | )$,其中 $d_h$ 是 hidden dimension。对于 Qwen3-8B($d_h = 3584$),这意味着 latent thoughts 可以比文本高效 **377 倍。 |
第二,延迟爆炸。每个 agent 都要做一轮完整的 auto-regressive 解码(一个 token 一个 token 地吐),然后下一个 agent 再把这堆 token 全部 prefill 进去。4 个 agent 的 sequential MAS,光文本生成和重新 prefill 就要跑 8 轮前向传播。
第三,错误放大。文本是有歧义的。planner 写的方案可能措辞不精确,critic 理解偏了,refiner 基于偏了的理解做修改……表面文字传递中每一环都可能引入误解,而 hidden states 是精确的数学向量,不存在”理解偏差”。
3. LatentMAS 的核心设计
LatentMAS 的完整流程如下图:
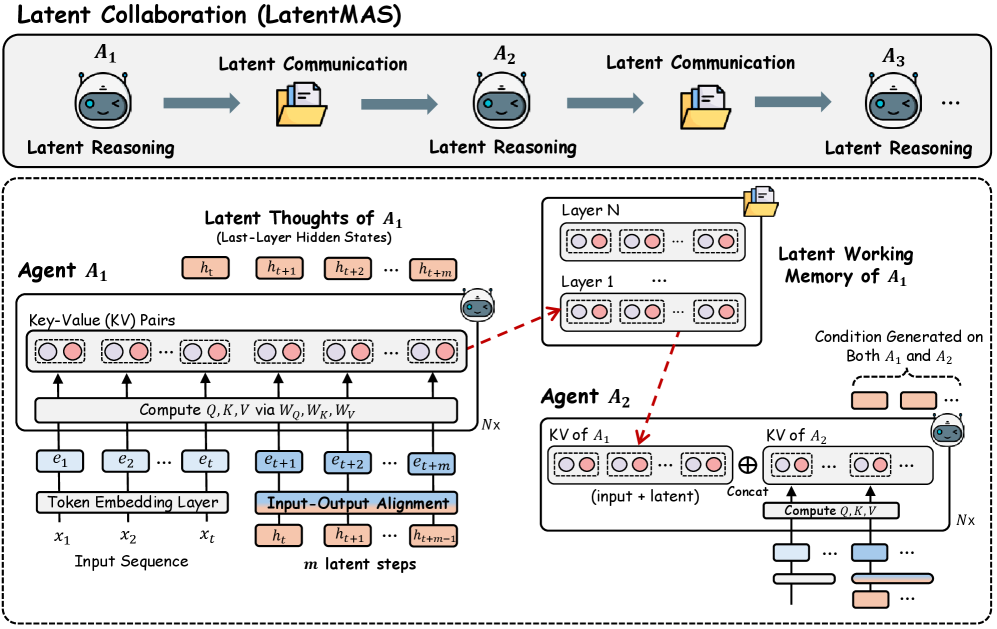
整个设计分两块:agent 内部的 latent thoughts 生成和agent 之间的 latent working memory 传递。
3.1 Latent Thoughts:让 Agent 在隐空间里”思考”
标准 LLM 推理的流程是:hidden state $h_t$ → LM head 解码成 token $x_{t+1}$ → token embedding $e_{t+1}$ → 进入下一轮前向传播。
LatentMAS 把中间的”解码-重编码”去掉了:直接把最后一层的 hidden state $h_t$ 当作下一步的输入 embedding,跳过 token 这个中介。
但这里有个工程上的坑:$h_t$ 是最后一层输出,分布和输入 embedding $e$ 差异很大。直接把 $h_t$ 塞回浅层会出现 out-of-distribution 的问题。怎么解?
论文提出了一个很巧妙的 Input-Output Alignment:构造一个对齐矩阵 $W_a$,把 $h_t$ 映射回输入 embedding 空间:
\[e = h \cdot W_a, \quad \text{其中} \quad W_a \approx W_{out}^{-1} \cdot W_{in}\]这里 $W_{out}$ 是 LM head,$W_{in}$ 是 token embedding 层。$W_a$ 只需要算一次,后面所有 latent step 复用。实际实现用的是 ridge regression 的闭式解来保证数值稳定性。
这个设计完全不需要训练——只用了模型自带的 $W_{in}$ 和 $W_{out}$,是一个纯推理时的操作。
3.2 Latent Working Memory:用 KV Cache 做跨 Agent 通信
这是全文最有意思的部分。
agent $A_1$ 完成 $m$ 步 latent thoughts 生成后,它的所有 transformer 层都积累了一整套 KV cache。这些 KV cache 不仅包含了原始输入的信息,还包含了 $m$ 步 latent reasoning 产生的新信息。论文把这整套 KV cache 定义为 agent $A_1$ 的 latent working memory:
\[\mathcal{M}_{A_1} = \{(K^{(l)}_{A_1,cache}, V^{(l)}_{A_1,cache}) \mid l = 1, 2, \ldots, L\}\]下一个 agent $A_2$ 接手时,做一步简单操作:把 $A_1$ 的 KV cache 拼接到自己对应层的 KV cache 前面。就这样,$A_2$ 就”看到”了 $A_1$ 所有的思考过程——包括它对原始 prompt 的处理和 $m$ 步 latent reasoning 的结果。
论文还证明了一个关键定理:通过 KV cache 传递 working memory 和直接把前序 agent 的完整输出重新 prefill 一遍,产生的结果是完全等价的(信息无损)。
实现上,KV cache 的传递直接通过 HuggingFace Transformers 的 past_key_values 接口完成——不需要改任何模型代码。
3.3 只有最后一个 Agent 需要”说人话”
整个流水线里,前面所有 agent 都在隐空间里思考和传递,只有最后一个 agent 负责解码出文本答案。这大幅减少了 token 生成量和相应的解码开销。
4. 实验结果
4.1 全面压制文本 MAS
如下图,在 9 个 benchmark 上(包括数学推理、常识推理、代码生成),分别用 Qwen3-4B / 8B / 14B 三种规模测试:
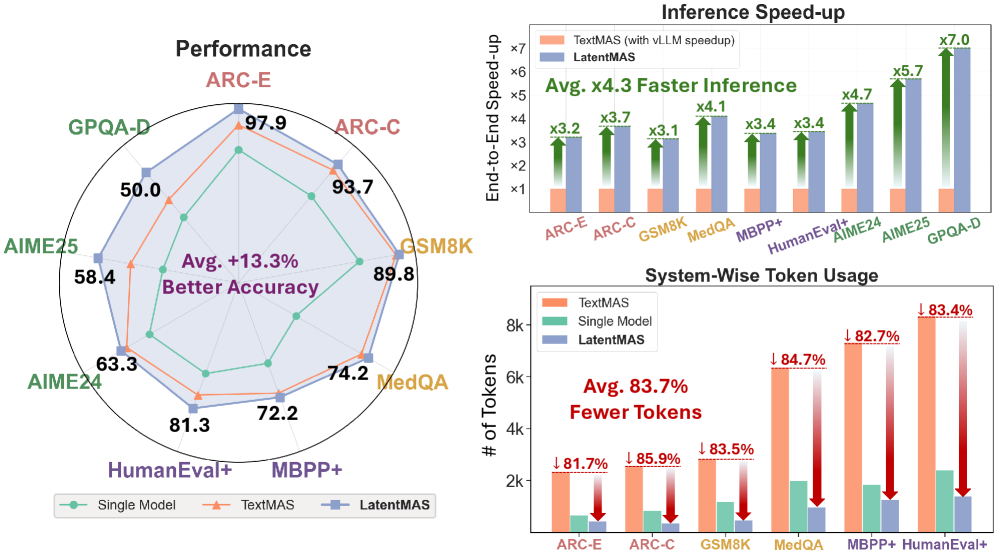
几个关键数字:
- 准确率:比单模型平均提升 13.3-14.6%,比 TextMAS 平均提升 2.8-4.6%
- 推理速度:比 TextMAS 快 4×-4.3×(即使 TextMAS 已经用了 vLLM 加速)
- Token 用量:减少 70.8%-83.7%
下面这张效率对比图更直观:
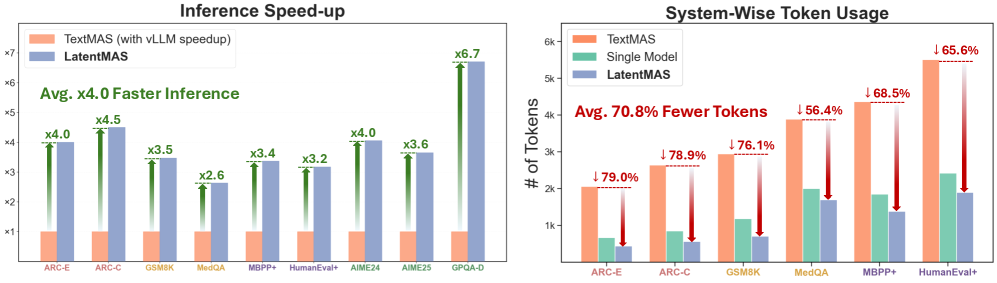
左图是推理速度对比,右图是 token 用量对比。注意 TextMAS 的 baseline 已经用了 vLLM 做加速了,LatentMAS 还能在这个基础上快 2.6×-7×。
在推理密集型任务(AIME24/25、GPQA-Diamond)上,TextMAS 动辄需要 20K+ token 来完成完整的 text-based CoT,而 LatentMAS 只用不到 50 步 latent step 就能达到同等甚至更好的效果。
4.2 Latent Thoughts 是否真的在”思考”?
一个合理的怀疑是:latent step 生成的 hidden states 到底有没有语义?会不会只是无意义的噪声恰好歪打正着?
论文做了一个很有说服力的分析。如下图,把 LatentMAS 生成的 hidden embeddings(红色)和 TextMAS 生成的 token embeddings(蓝色)做 t-SNE 可视化:
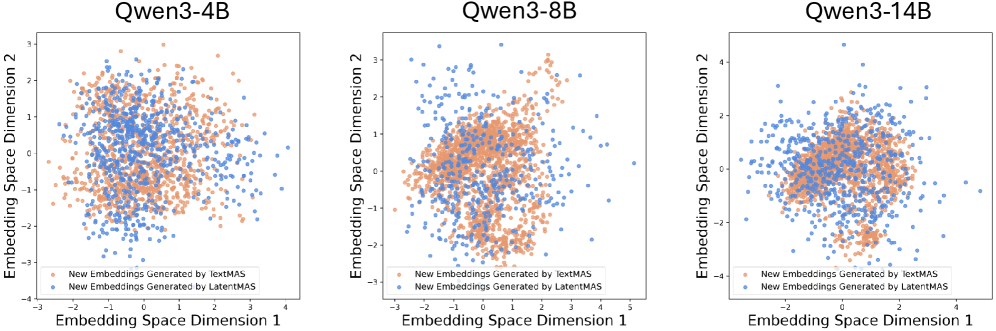
两个关键观察:
- LatentMAS 的 hidden embeddings 和 TextMAS 的 token embeddings 覆盖了几乎相同的 embedding 区域——说明 latent thoughts 编码了和正确文本回答相同的语义
- LatentMAS 的分布更广——说明 latent thoughts 比离散 token 具有更高的多样性和表达能力
4.3 对齐矩阵 $W_a$ 的作用
如下图,不做对齐的 hidden state $h_t$(橙色)和原始 input embedding $e_t$(蓝色)分布差异很大。做完 $W_a$ 对齐后的 $e_{t+1}$(绿色)重新和 $e_t$ 对齐了:
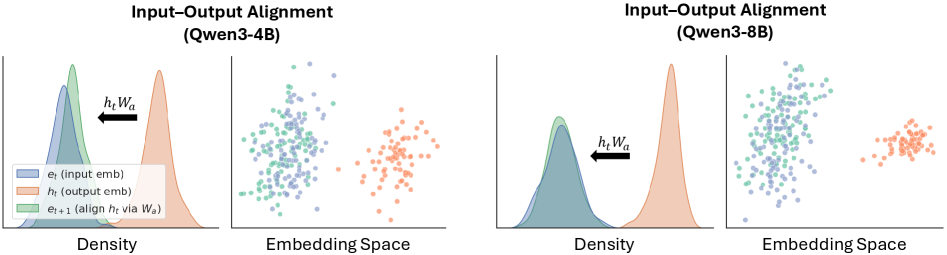
去掉 $W_a$ 后,下游任务准确率下降 2.3%-5.3%。
4.4 最佳 Latent Step 深度
Latent step 并不是越多越好。论文在三个任务上做了 ablation,发现 40-80 步是最佳范围。超过这个范围,性能会平台期甚至下降——过多的 latent step 可能引入冗余信息。
5. 几点个人 Take
这篇工作最让我兴奋的地方不是具体的数字提升,而是它开辟了一个新的思路:多 Agent 之间的通信介质不必是人类可读的文本,可以是模型内部的连续表示。
几个值得关注的点:
1. 完全 training-free 这件事很 impressive。$W_a$ 的构造只用了现有的 $W_{in}$ 和 $W_{out}$,KV cache 传递用的是 HuggingFace 原生接口。没有额外参数、没有训练数据,直接即插即用。这大大降低了实际落地的门槛。
2. 但同构 agent 的假设是个限制。LatentMAS 要求所有 agent 使用相同架构的模型(same transformer layer shape),因为 KV cache 的 dimension 要对齐才能拼接。现实中,强大的 MAS 往往需要不同规模甚至不同架构的模型分工协作。论文也提到了可以用 adapter 做异构对齐,但这就引入了训练,breaking 了 training-free 的优势。
3. 和 KV cache 通信的结合值得深挖。这篇工作的 KV cache 传递策略非常朴素——全量拼接。随着 agent 数量增加和 latent step 加深,KV cache 会持续膨胀。能不能结合 KV cache 压缩(比如上一篇聊的 SemShareKV 的思路)做选择性传递?这可能是一个有意思的后续方向。
4. 对 latent reasoning 本身的理解还有空间。论文证明了 latent thoughts 的理论表达上界,但对于”模型到底在 latent step 里做了什么”这个问题,目前主要靠 t-SNE 可视化来间接验证。更深入的 mechanistic interpretability 分析会让这个 story 更完整。
总体来说,LatentMAS 把”在隐空间里做多 agent 协作”这个想法走通了,而且效果很好。从文本通信到 latent 通信,本质上是信息传递的效率升级。这个方向和我们做 MoE 推理优化的思路有异曲同工之处——核心都是减少不必要的计算和数据搬运,把算力花在真正重要的地方。
欢迎评论区交流,特别是做多 Agent 系统或 LLM 推理优化的同学,欢迎讨论哈哈。