ICLR'26 Workshop Spotlight | Lang-PINN:让 LLM 多智能体帮你从自然语言一键搭建物理信息神经网络
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

ICLR’26 Workshop Spotlight | Lang-PINN:让 LLM 多智能体帮你从自然语言一键搭建物理信息神经网络
原文:Lang-PINN: From Language to Physics-Informed Neural Networks via a Multi-Agent Framework
1. 这是一篇跨界论文
写这篇 post 需要解释一下背景——我做 AutoML 和 NAS 出身,然后做 LLM 推理系统,Lang-PINN 这个工作看起来有点”出圈”:怎么又跑去做物理信息神经网络(PINN)了?
其实逻辑很直接:PINN 的搭建本质上是一个 AutoML 问题,需要:
- 把问题描述转化为偏微分方程(PDE)形式——等价于问题形式化
- 选择合适的神经网络架构——这是 NAS 问题
- 生成正确的 loss 函数和训练代码——这是代码生成
- 调试、验证和迭代——这是超参数优化+反馈
以前这四步全靠专家手工完成。现在有了 LLM,就可以把这四步自动化——于是就有了 Lang-PINN。
2. PINN 是什么?为什么搭建它这么麻烦?
PINN(Physics-Informed Neural Network)是一种把物理方程嵌进神经网络训练过程的方法。核心思路:不只用数据训练,而是把 PDE(偏微分方程)的残差作为 loss 的一部分,让网络在满足物理定律的前提下拟合数据。
总 Loss = 数据拟合 loss + PDE残差 loss + 边界条件 loss
好处是在数据稀缺场景(物理实验数据贵!)也能训练出合理的模型。应用在流体力学、热传导、电磁场等科学计算领域。
但是为什么难用? 一个科学家想用 PINN 解一个实际问题,需要:
- 把问题描述翻译成严格的 PDE 数学形式(算子、边界条件、初始条件)
- 选择合适的网络架构——MLP、CNN、GNN、Transformer,不同 PDE 适合不同架构
- 手写 loss 函数代码(要正确实现 PDE 残差)
- 还得懂梯度病态、激活函数选择、采样策略……
对领域科学家(非 DL 专家)来说,这是极高的门槛。对 DL 工程师来说,每换一个物理问题又得重来一遍。
3. Lang-PINN:四个 Agent 的流水线
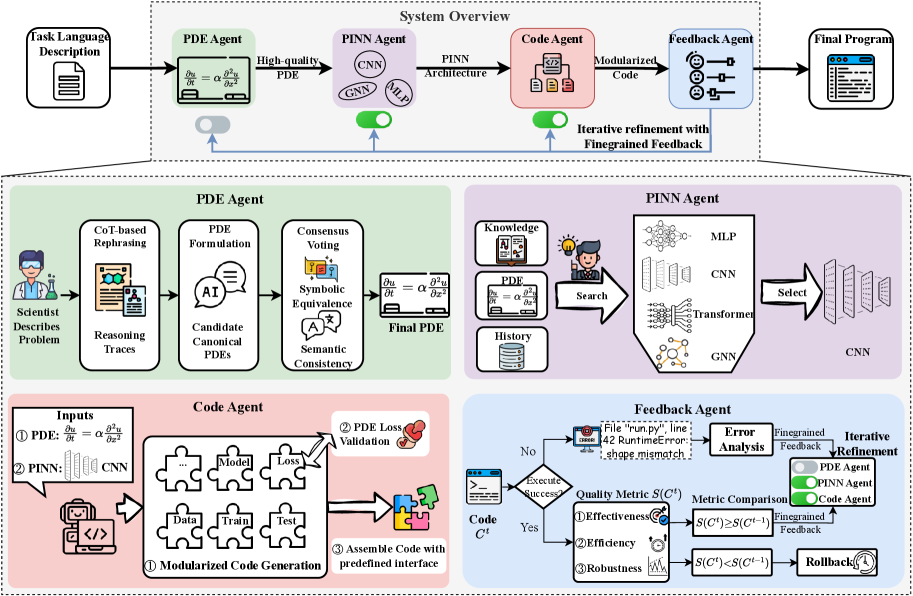
Lang-PINN 把整个 PINN 构建流程分解为四个专门的 Agent:
Agent 1:PDE Agent —— 把自然语言翻译成 PDE
问题:同一个物理问题,不同科学家的描述方式差异极大。有人说”热扩散方程”,有人说”温度随时间变化满足拉普拉斯算子”,有人描述里还夹杂了不相关的背景信息(”今天实验室咖啡机声音很大”)。
直接让 LLM 翻译 PDE,在描述复杂度增加时准确率急剧下降:
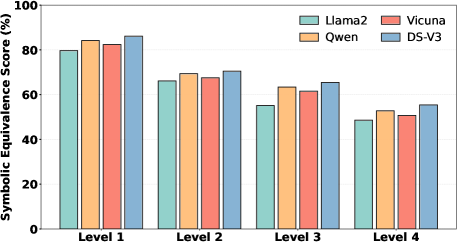
解决方案:PDE Agent 采用三步流程:
- CoT 多路采样:采样 K 条思维链,每条生成一个候选 PDE
- 双重验证:符号等价(AST 树匹配)+ 语义一致性(embedding 余弦相似度)
- 共识投票:选择与其他候选平均相似度最高的那个
这样即使输入有噪声,也能鲁棒地输出正确 PDE 形式。
Agent 2:PINN Agent —— 不是所有 PDE 都适合 MLP
这张图说明了一个反直觉的事实:
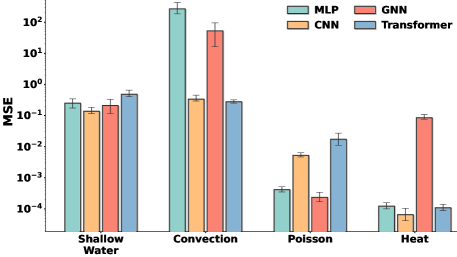
- Shallow Water 方程:各架构差不多
- Convection(对流)方程:MLP 和 GNN 差了两个数量级以上
- Poisson 方程:CNN 最好
- Heat 方程:MLP 和 GNN 几乎不收敛
所以 PINN Agent 做的是:根据 PDE 的物理特征(周期性、几何复杂度、多尺度需求),把每个架构的”能力向量”和 PDE 的”特征向量”做加权余弦相似度匹配,选出最合适的架构。
还有一个 History Reuse 机制:如果遇到之前见过的相似 PDE,直接复用历史上效果最好的架构选择,不重复搜索。
Agent 3:Code Agent —— 模块化代码生成
整段代码一次生成(monolithic)的问题:一个地方出错,整个脚本报废,只能全部重写。
改为模块化生成:
① model definition ② PDE loss ③ data preprocessing
④ training loop ⑤ validation ⑥ main function
六个模块独立生成,标准化接口连接,出错了只修那个模块,不影响其他部分。
实验验证:模块化比 monolithic 在六类 PDE 上成功率翻倍以上。
Agent 4:Feedback Agent —— 闭环迭代
执行代码后,Feedback Agent 做两件事:
- 错误定位:把 runtime error 归因到具体模块(model/loss/training),指导 Code Agent 只重生成那部分
- 质量评估:从三个维度打分——Effectiveness(MSE)、Efficiency(收敛速度)、Robustness(loss 平滑度 + 梯度健康度)
质量分 $S(C^t) \geq S(C^{t-1})$ 才接受新版本,否则回滚。
4. 实验结果
4.1 端到端成功率
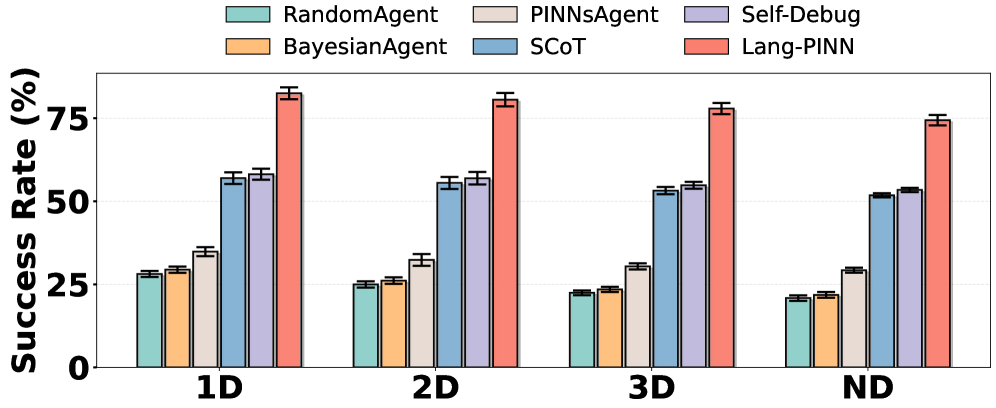
在 1D 和 2D PDE 上,Lang-PINN 成功率超过 80%,而最强基线(SCoT、Self-Debug)只有 55-60%。
注意:Lang-PINN 是从自然语言开始的,其他 baseline 是直接给 canonical PDE 作为输入。换言之,Lang-PINN 多做了一步(NL→PDE),还取得了更好的结果。
4.2 MSE 精度
在 14 个不同 PDE 上:
- KS 方程(Kuramoto-Sivashinsky,混沌系统):Lang-PINN MSE = 1.62e-3,baseline 最好 1.09(差了近 3 个数量级)
- Poisson-MA(任意形状 Poisson):Lang-PINN MSE = 2.25e-3,baseline 最好 1.83(差 3 个数量级)
- Heat-ND(高维热方程):Lang-PINN MSE = 4.72e-4,PINNacle reference = 8.52(差近 4 个数量级)
4.3 时间效率
Lang-PINN 平均 8 次迭代收敛,比最差基线(BayesianAgent,31 次)节省 74% 的迭代开销。
5. 这个工作的定位
Lang-PINN 是 ICLR 2026 的 Workshop Spotlight(AI with Recursive Self-Improvement 方向)。
Workshop paper 的好处是可以做一些比较探索性的工作,不需要 full paper 那么大的 benchmark 体量。这个工作的贡献更多在于:提出了一个框架,证明了”自然语言→可执行 PINN”这条路是通的。
从我自己的视角来看,这是我把 AutoML 思想(架构搜索 + 超参优化 + 自动评估)和 LLM Agent 结合的一次尝试。PINN 只是一个验证场景,背后的逻辑可以推广到更多科学计算工具的自动化。
如果你是做科学机器学习(Scientific ML)的,这个框架可能有直接参考价值。如果你是做 LLM Agent 的,这里面的 modular code generation + feedback-driven refinement 思路也可以复用。
6. 局限性(没必要回避)
- 场景限制:目前只在 PINNacle benchmark 上测试,都是标准 PDE,真实工业场景的不规则几何、多物理耦合还没验证
- LLM 依赖:PDE Agent 的质量高度依赖底层 LLM(用的是 DeepSeek-V3、Qwen 等),不同 LLM 效果差异较大
- 时间开销:虽然比 baseline 少 74%,但 8 次迭代对于简单问题仍然有点重——未来应该有更快的 cold-start 路径
7. 总结
Lang-PINN 用一句话概括:四个专门化的 LLM Agent 协作,把”用自然语言描述的物理问题”全自动转化为”可执行的 PINN 训练代码”。
| 维度 | Lang-PINN | 最强 baseline |
|---|---|---|
| 是否支持 NL 输入 | ✓ | ✗(需手写 PDE) |
| MSE 改善 | 3-5 个数量级 | - |
| 成功率提升 | >50% | - |
| 收敛迭代数 | 8 次 | 14-31 次 |