KVCOMM:让多 Agent 系统的 KV Cache 真正“通起来”,TTFT 直接砍掉 7.8 倍
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

KVCOMM:让多 Agent 系统的 KV Cache 真正“通起来”,TTFT 直接砍掉 7.8 倍
原文:KVCOMM: Online Cross-context KV-cache Communication for Efficient LLM-based Multi-agent Systems(Duke / MIT / NVIDIA,OpenReview 投稿) 代码:https://github.com/FastMAS/KVCOMM
1. 前言吐槽
最近一年,但凡和 LLM 沾点边的方向,几乎都被 multi-agent system 卷了一遍:CoT 不够就上 Debate,Debate 不够就上 Society of Mind,再不够就拉一堆 agent 排成 DAG 互相喂消息。学术上看起来很热闹,但工程上跑过的人都知道,这玩意儿是真的慢。
慢在哪?慢在每个 agent 收到上游的消息之后,整段 prompt 要从头 prefill 一遍。一个 8B 的 Llama 在 H100 上 prefill 一个 3K 的 prompt 大概要 ~430ms,而五个 agent 全连接互相发消息,重复 prefill 的开销直接是 $O(M^2)$。结果就是:你写了一个看起来很优雅的 multi-agent pipeline,跑起来 TTFT 高得离谱,根本没法做实时协作。
KV cache 不是早就解决重复计算了吗?——单 agent 场景下是。 在 multi-agent 里,每个 agent 把上游消息塞进自己的 system prompt 之后,前缀变了,KV cache 的位置编码、attention 上下文都跟着变,没法直接复用。这篇 KVCOMM 想做的事情很直接:让多 agent 之间的 KV cache 真的能“通起来”。
下面我把这篇 paper 的核心思路、insight 和实验结果做个 take。
2. 问题到底卡在哪
先把场景说清楚:把 multi-agent 系统建模成一张有向图 $G=(M, E)$,每个节点是一个 agent,边表示一个 agent 把消息发给另一个。每个 agent 的 prompt 大致长这样:
[role-specific system prompt]
[placeholder_1: 上游 agent 的输出 / 用户 query / 工具结果]
[fixed prefix_1]
[placeholder_2: ...]
[fixed prefix_2]
...
里面既有固定的 prefix 段(每个 agent 自己的角色模板),也有运行时才填进去的 placeholder 段(来自上游或用户)。问题就出在:同一段“共享内容”在不同 agent 里,前面接的 prefix 不一样,导致它的 KV-cache 完全不同。
作者把这个现象拆成两个层面来看:
如下图,对同一个 token,把它放到 10 个不同的 prefix 后面,统计 KV cache 相对“基础上下文”(即 token 单独算时)的偏移量($\ell_2$ norm),结果非常稳定——偏移量随层数变化的曲线几乎是同一条线,shaded region(标准差)也很窄。
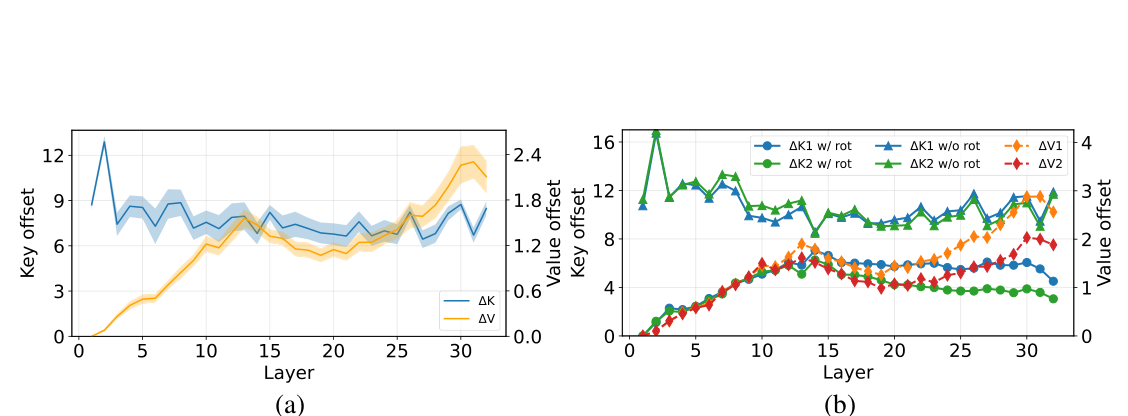
这意味着:KV cache 的“偏移”是有结构的,不是随机噪声。 同一个 token 在不同上下文里的 KV,可以拆成“基础值 + 上下文偏移”两部分,而这个偏移在统计上是可预测的。
更重要的是右图——embedding 相近的两个 token,它们的 KV 偏移也相近(前提是位置编码先做对齐 / RoPE rotate)。这就给“用历史样本预测当前 KV 偏移”留下了空间。
2.1 现有方案为什么不够用
目前减 prefill 开销的工作大致四类:prompt-level reuse、selective recomputation、cache 压缩、kernel 优化。如下图,作者把自己和最接近的两类做了对比:

- No Cache Reuse(baseline):每个请求重头 prefill 所有 token。准但慢。
- Selective Recomputation(CacheBlend 这类):复用大部分 KV,只对“关键部分”重算。固定一个比例(比如 80%),不管 workload 什么样都按这个走。
- KVCOMM:全部复用 KV,但给每段共享内容加上一个“context-aware offset”,把不同 prefix 引入的偏差对齐回来。这个 offset 不是重算出来的,是从历史相似请求里近似出来的。
一句话总结:别人是“砍掉一部分重算”,KVCOMM 是“全都不算,靠查历史 anchor 把偏差补回来”。
3. KVCOMM 怎么做
3.1 总体架构
如下图,KVCOMM 在每个 agent 的 prompt 模板里识别出 placeholder,为每个 placeholder 独立维护一个 anchor pool。新请求进来时:

- 拿到 placeholder 内容,去 anchor pool 里做 Anchor Matching——找几个 embedding 最近的历史样本;
- 用这几个 anchor 的“已知 KV 偏移”做加权(softmax over 距离),Offset Approximation 出当前 placeholder 应该有的 KV cache;
- 如果一个 agent 的所有 placeholder 都能这么补齐,直接跳过 prefill,进入 decoding;否则 fallback 到 dense prefill,并把这次结果写回 anchor pool 更新。
整个过程不需要训练,纯在线维护,对接受 RoPE 的 LLM 都适用。
3.2 Anchor 池里到底存什么
每个 anchor 存三件东西:
- Base KV-cache:placeholder 内容单独算的 KV(不带任何上下文);
- Within-agent offset:在该 agent 自己的 prefix 里,相对于 base KV 的偏移;
- Cross-agent offset:跨 agent 时,不同 prefix 引入的额外偏移。
近似公式很直观:
\[(\hat k / \hat v)_{\phi_{(m,i)}} = (k/v)_{\phi_{(m,i)}} + \sum_{\psi \in A_{\phi_{(m,i)}}} w_{\phi_{(m,i)} \to \psi} \cdot \Delta(k/v)^\phi_{(m,\psi)}\]也就是 base 值 + 用 embedding 距离做 softmax 加权的偏移项。Prefix 段的 KV 也走类似流程。
3.3 为什么“近邻 token”的偏移能复用
作者花了 §3.2 一整节做实验来证明这个 insight。如下图,把 token 按 embedding 距离分成 near / mid / far 三组,分别看:

- (a)(b) 同一前缀下,embedding 越近的 token,KV cache 的 $\ell_2$ 距离也越近,Spearman 相关系数在 0.5~0.9 之间;
- (c)(d) 不同前缀下,KV 偏移本身也保持这个性质——near 组的偏移更接近,相关性同样高。
这就是 anchor 机制能 work 的根本:embedding space 上的邻近性,能传递到 KV-cache 偏移空间。所以你只要在 anchor 池里找几个 embedding 最近的历史样本,它们的 KV 偏移就是一个不错的“参考答案”。
4. 实验结果:精度不掉,速度起飞
4.1 精度对比
跑了 MMLU、GSM8K、HumanEval 三个任务,对比 No Reuse / CacheBlend / KVCOMM,agent 数从 2 到 5:

几个看点:
- HumanEval 上 CacheBlend 直接崩了(Pass@1 从 86.3% 掉到 31.1%),代码生成对 KV 的精度极敏感,砍 20% 重算根本不够。
- GSM8K 上 CacheBlend 也越多 agent 越拉垮(5 agent 时 57.1%)。
- KVCOMM 三个数据集全程贴近原始精度:HumanEval 81.4~83.2%,GSM8K 79.6~81.7%,MMLU 也在 ±2% 内。
- Reuse Rate 70%~87%:注意这里 KVCOMM 的 reuse rate 定义比 CacheBlend 严——是“整 agent 全跳过 prefill”的频率,不是 token-level。
结论:CacheBlend 的固定策略在工作负载敏感的任务上撑不住;KVCOMM 的 anchor 机制能根据数据自适应,精度几乎不掉。
4.2 TTFT 加速
更直观的是延迟数字:

5 agent 设置下,Agent 5 的 TTFT 从 428.6ms 干到 17.5ms,加速 7.82×。注意这里 Agent 1 加速比只有 1.11×——因为它是入口,没有上游内容可复用,这也符合预期。越靠后的 agent 受益越大,因为它们要 prefill 的“上游内容”越长。
输入越长加速越明显(1024 prefix + 512 output 时能到 4.75× 左右),这正好打中 multi-agent 系统真实场景:真正卡 TTFT 的就是那种 agent 互相累积上下文的长 prompt。
5. 我的 take
这篇工作我觉得最有价值的地方有两个:
1. 把 multi-agent 的 KV 复用问题正式定义清楚了。 之前大家做 KV reuse,要么是 prefix caching(单 agent,前缀必须完全一致),要么是 selective recomputation(不管什么 workload 都按固定比例砍)。KVCOMM 第一次明确指出:multi-agent 的核心矛盾是“offset variance”——同一段共享文本因为前缀不同,KV 不同。这个抽象一旦立住了,后面的解法就顺了。
2. Anchor pool 这个设计有点像在 KV 空间里做“近邻检索 + 残差预测”。 思路上很 RAG——只不过 RAG 检索的是文本,KVCOMM 检索的是 KV 偏移。这种 “retrieve-then-approximate” 的范式,本质上还是在用历史经验摊平推理时的计算开销,和我之前在 ExpertFlow 里做 MoE 专家激活预测的味道有点像:都是承认“完全精确的代价太高”,转而用结构化的近似换吞吐。
不过也有几个我自己关心、但 paper 里着墨不多的点:
- Anchor pool 的内存开销:每个 placeholder 存 base KV + 多个偏移,agent 多 / placeholder 多的时候,pool 会不会成为新的瓶颈?paper 提到在线维护和淘汰,但没给详细的内存曲线。
- Out-of-distribution 输入:如果一个新请求和 anchor pool 里的所有样本都“不近”,它的 fallback 到 dense prefill 是必然的。长尾分布下的 reuse rate 是否会断崖,值得在真实业务场景里压测一下。
- 和 vLLM / SGLang 这类推理框架的集成成本:anchor matching、offset approximation 都需要插到 prefill pipeline 里,不是简单挂个 plugin 能搞定的,落地工程量我估计不小。
总体上,这是 multi-agent 推理优化方向上一个挺有 insight 的工作,把“prefix 变了 → KV 不能复用”这个老问题,用 anchor + offset 的方式给出了一个训练无关、可在线更新的解。如果你在做 multi-agent 系统的工程落地,TTFT 卡得比较死,这篇 paper 值得仔细看一下。
代码已经开源在 https://github.com/FastMAS/KVCOMM,感兴趣的可以 clone 下来跑跑看。
欢迎评论区交流,特别是踩过 multi-agent prefill 坑的朋友,分享下你们的 workaround~