EuroSys'26 | KUNSERVE 把冗余参数副本临时让给 KVCache,P99 TTFT 最快降 72×
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

EuroSys’26 | KUNSERVE 把冗余参数副本临时让给 KVCache,P99 TTFT 最快降 72×
1. 前言
你有没有想过,当一个在线 LLM 服务突然遇到一波流量 spike 时,GPU 上最先爆掉的到底是什么?
很多人第一反应是:当然是 KVCache。这个答案没错,但只说对了一半。因为在真实 serving 系统里,GPU HBM 里除了 KVCache,还有一坨非常扎实的 model parameters。更关键的是,这些参数在多副本 serving 集群里经常是重复存的。
KUNSERVE 这篇 EuroSys 2026 的工作就抓住了这个点:以前大家处理 memory overloading 基本都围绕 KVCache 打转,drop、swap、migrate,都是在 KVCache 上做文章。但 KUNSERVE 反过来问了一个很系统的问题:
既然参数是 replicated 的,为什么不能临时丢掉一部分参数,把 HBM 让给 KVCache?
这个思路乍一听有点离谱,因为 LLM 没参数还怎么推理?但这篇 paper 有意思的地方就在这里:它不是“丢了就不管”,而是把多个 GPU 重新组织成一个 cooperative group,用 pipeline parallelism 拼出一份完整模型继续 serving。
如下图,作者先展示了常见 LLM serving 形态:多个 serving instance,每个 instance 里有模型参数、prefill/decode batch,以及不断膨胀的 KVCache。
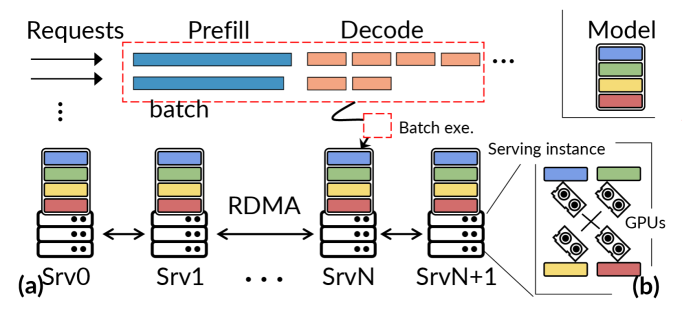
2. 背景:KVCache-centric 方法为什么不够?
LLM inference 有两个核心阶段:prefill 和 decode。prefill 通常 compute-bound,decode 通常 memory-bound。为了避免每生成一个 token 都重复算历史上下文,系统会把每层 attention 的 key/value 存下来,也就是 KVCache。
问题是 KVCache 会随着 batch size、context length、output length 线性增长。平时看起来还能扛,一旦请求扎堆或者生成特别长,HBM 很快就顶住了。
已有方法大体有三类:
- Drop KVCache:把部分请求的 KVCache 丢掉,后面重新排队重算。
- Swap KVCache:把 KVCache 换到 CPU DRAM,再需要时换回来。
- Migrate KVCache:把 KVCache 迁移到别的 GPU。
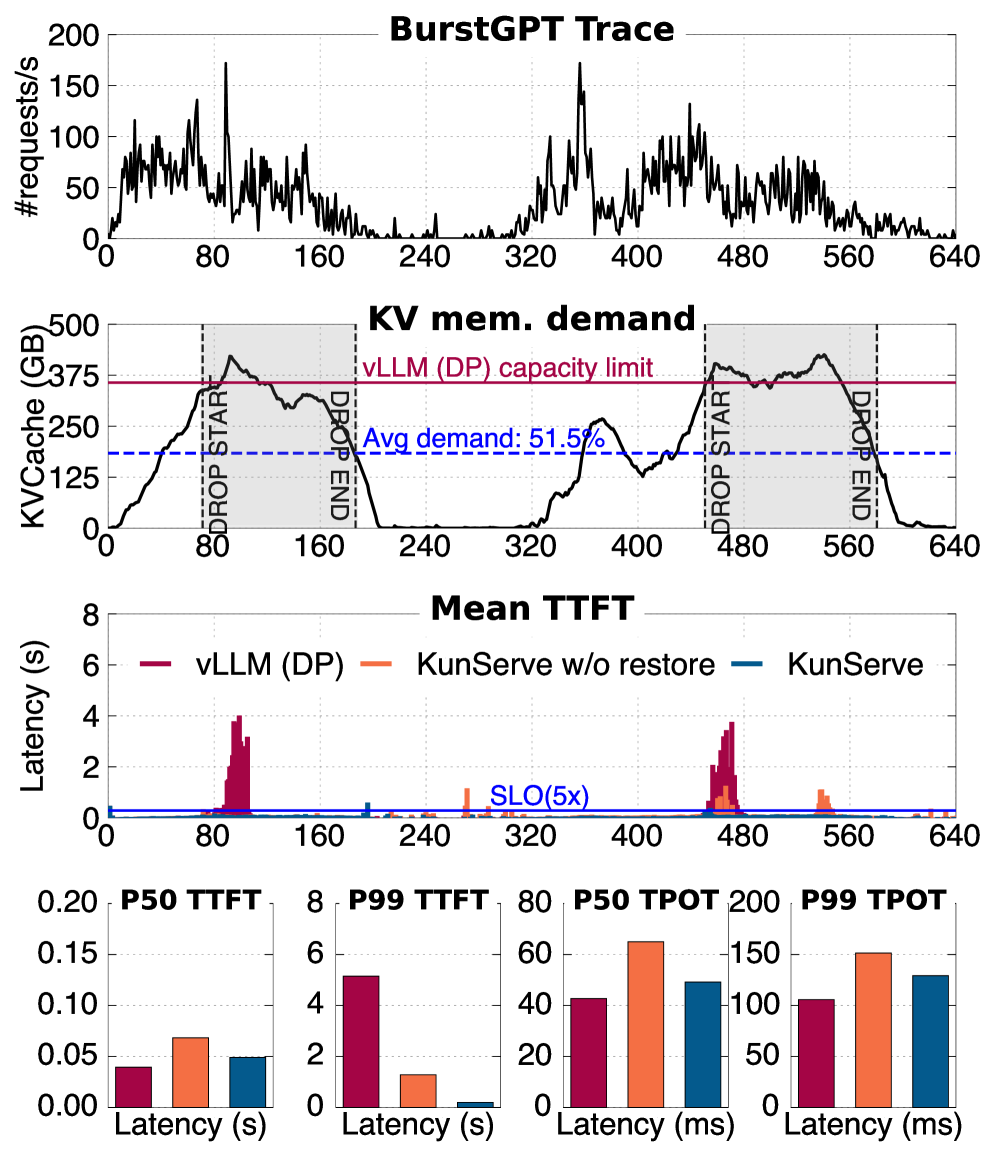
它们的问题都挺现实:要么浪费已经做过的计算,要么引入 PCIe/RDMA 数据搬运,要么仍然释放不出足够空间。论文里用 BurstGPT trace 做了一个很直观的实验:即使平均 memory usage 只有 58.43%,一旦 burst 导致 KVCache demand 触顶,TTFT 还是会突然飙升。
如下图可以看到,drop、swap、migrate 这些 KVCache-centric 策略,在 overloading 时都会出现明显 TTFT spike。

所以 KUNSERVE 的判断是:只围绕 KVCache 做局部调整,本质上是在排队请求和正在执行的请求之间互相伤害,并没有真正创造更多可用 HBM。
3. 核心观察:参数其实也是一块可调度内存
这篇文章最关键的观察有两个:
第一,model parameters 占 HBM 的比例并不小。论文给出的例子里,Qwen-2.5-14B 参数占单卡 80GB 的 34.4%,Qwen-2.5-72B 占 4 卡 320GB 的 42.3%,DeepSeek-V3-671B 占 32 卡 2560GB 的 61.4%。也就是说,参数不是“背景噪声”,而是一块相当大的 memory resource。
第二,在线 LLM serving 通常会部署多个 replica。参数在不同 instance 上有完整副本。既然参数跨 instance 有冗余,那在 memory pressure 来的时候,就可以选择性丢掉某些 layer 的 replicated copy。
KUNSERVE 的基本动作如下图:当 GPU0/GPU1 都因为 KVCache 不够而要排队时,系统可以让 GPU0 丢掉后半层参数,让 GPU1 丢掉前半层参数;两张卡合起来仍然有一份完整模型,然后用 pipeline parallelism 服务请求。
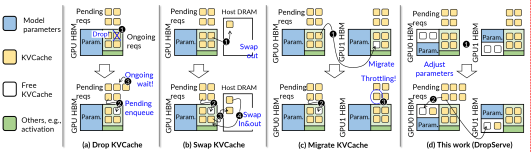
这里的关键不只是“丢参数”,而是三件事一起做:
- 生成一个 drop plan,决定哪些 instance 合并成 group、哪些 duplicated layers 可以丢。
- 用 CUDA virtual memory management 把释放出来的物理 HBM remap 到 KVCache buffer 后面,让现有 PagedAttention kernel 不用改。
- 在参数不完整的情况下,通过 cooperative execution、KVCache exchange 和 lookahead microbatch formulation,把 pipeline bubbles 尽量压低。
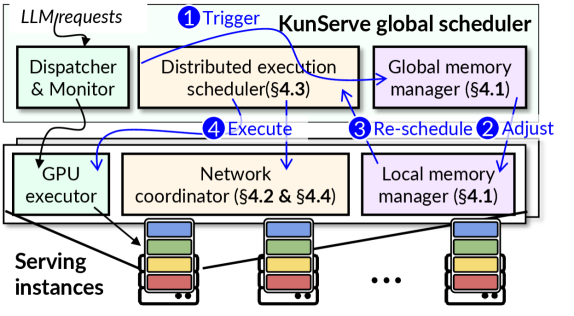
系统结构如下图。全局 scheduler 负责监控 memory pressure,global memory manager 生成 drop plan,local manager 真正调整 GPU memory,distributed execution scheduler 负责重新调度请求。
4. 方法细节:难点不在丢,而在丢完还能跑得快
如果只是把参数丢掉,然后让几个 GPU pipeline 起来,其实很容易把 latency 搞炸。KUNSERVE 主要解决了三个工程问题。
4.1 Drop plan:尽量少拉人组队
参数 drop 后,一个请求可能需要跨多个 instance cooperative execution。参与的 GPU 越多,pipeline overhead 越大。所以 drop plan 的目标不是“丢越多越好”,而是在满足 queued requests 的 memory requirement 前提下,尽量少合并 instance。
论文用了一个 greedy plan generation:每次从 priority queue 里取出 size 最小的两个 group 合并,丢掉它们之间重复的 layers,直到释放出足够 memory。

这个设计挺朴素,但适合 serving 场景:overloading 发生时不能慢慢求最优解,系统需要很快给出可执行 plan。
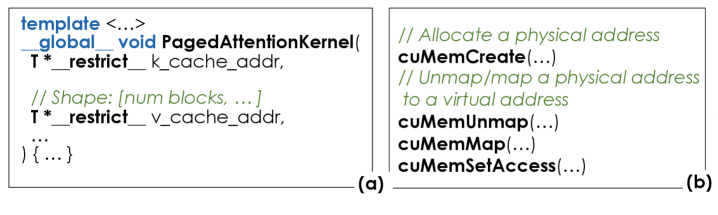
4.2 Unified GPU virtual memory:不改 kernel 也能用新内存
如果丢掉参数后只是得到一段空闲物理 HBM,还不够。现有 attention kernel 通常假设 KVCache buffer 有固定虚拟地址布局。KUNSERVE 用 CUDA virtual memory API 把释放出来的 physical memory 映射到 KVCache buffer 的虚拟地址空间尾部。
说人话就是:底层换了一块物理内存,但上层 kernel 看到的还是同一块连续 KVCache。
这点很工程,因为它避免了重写 PagedAttention kernel。
4.3 Lookahead batch formulation:减少 pipeline bubbles
参数 drop 后,系统进入 pipeline execution。pipeline 最大的问题就是 bubbles:前后 stage 执行时间不均衡,GPU 会空等。
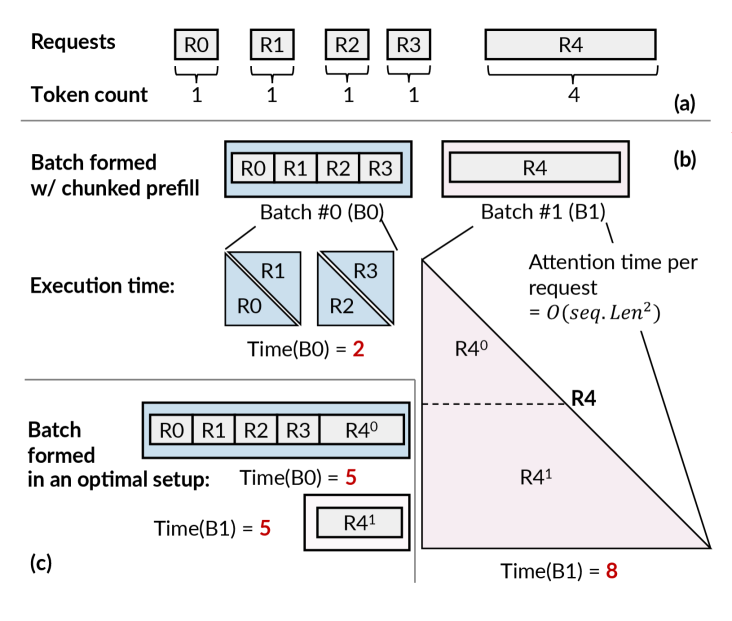
KUNSERVE 观察到 LLM batch 的执行时间不是简单由 token 数决定,attention 里的 prefix-attn 和 self-attn 也会影响 cost。于是它提出一个 cost model,再配合 lookahead batch formulation,把请求组织成更均衡的 microbatches。
如下图,普通 chunking 会让不同 microbatch 执行时间差很大,而 KUNSERVE 尝试提前看后续请求,生成更平衡的 batch 配置。
5. 实验设置
KUNSERVE 的实验主要回答一个问题:遇到真实 burst 时,它能不能减少 tail latency,同时不要把 TPOT 搞得太差。
实验平台有两组:
- Cluster A:8 台服务器,每台 1 张 A800 80GB,scale-out 网络 200Gbps RDMA。
- Cluster B:2 台服务器,每台 8 张 H800 80GB,单机 NVLink 300GB/s,scale-out 400Gbps RDMA。
模型选择 Qwen-2.5-14B 和 Qwen-2.5-72B。workload 使用 BurstGPT trace,并结合三个 dataset:
- BurstGPT:平均 input/output length 分别是 642/262。
- ShareGPT:平均 input/output length 1660/373,最长 input 到 4K。
- LongBench:更偏 long-context 场景。
baseline 包括 vLLM default、vLLM with PP、InferCept 和 Llumnix。指标主要看 TTFT、TPOT、throughput 和 SLO violation。
6. 结果分析
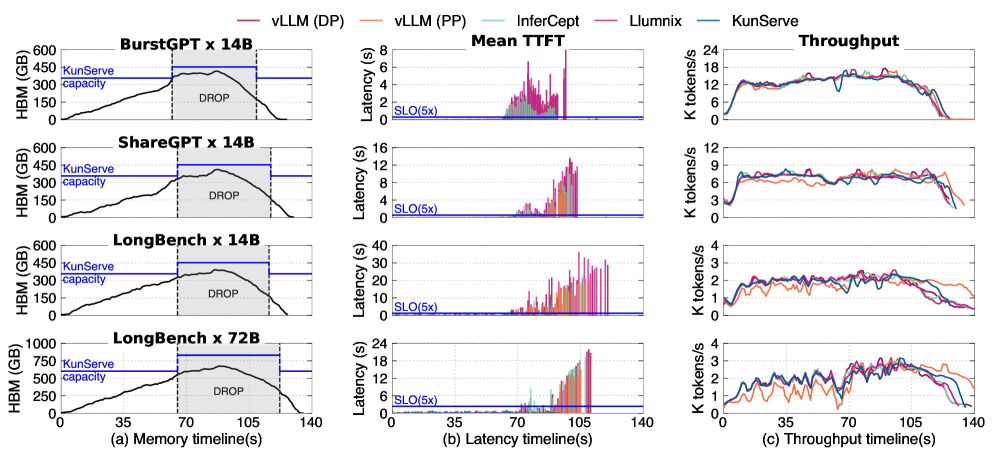
主结果很直接:KUNSERVE 在 memory overloading 下显著降低 P99 TTFT。论文报告相对其他 baseline,KUNSERVE 的 P99 TTFT 最多快 72.2×。
如下图,第一列是 KVCache memory timeline,第二列是 mean TTFT,第三列是 throughput。可以看到 baseline 的 TTFT spike 基本和 KVCache demand spike 对齐;KUNSERVE 在触发 drop 后把 capacity 撑上去,避免请求长时间排队。
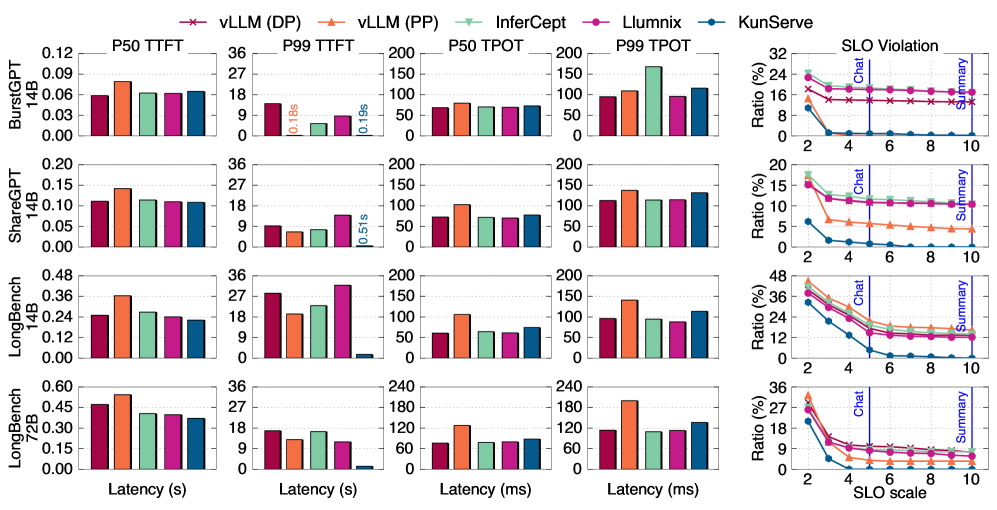
更细的 latency 分布如下图。KUNSERVE 的 trade-off 也很清楚:为了消除 queueing,它会用更大的 batch 和 pipeline execution,因此 P50/P99 TPOT 会有轻微上升。比如 LongBench-14B 上,P50 TPOT 比 baseline 高 15.8% 到 22.7%。但这个开销比排队导致的 TTFT 爆炸小太多,而且仍在应用 SLO 内。
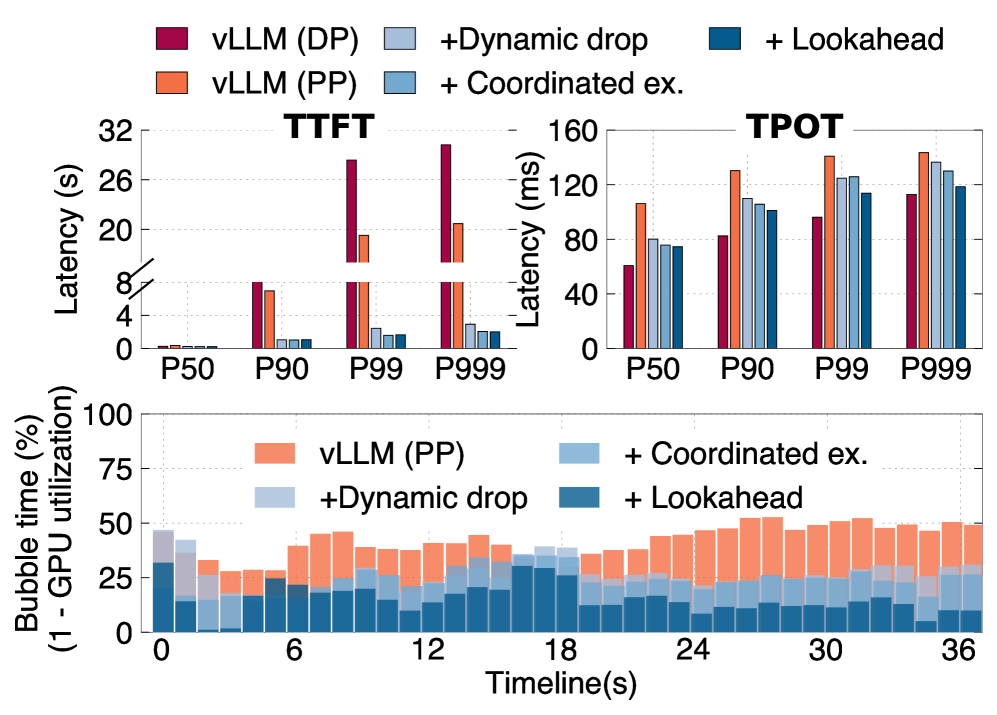
ablation 也挺有说服力。dynamic parameter drop 是主要贡献,在 LongBench + Qwen-2.5-14B 上,P90/P99/P999 TTFT 分别相比 vLLM(DP) 降低 8.8×、11.7×、10.3×。coordinated exchange 又进一步降低 P99/P999 TTFT 1.5×/1.4×。lookahead batch formulation 则把 bubble time 从 21.9% 降到 8.3%,throughput 提升 20%。
动态恢复参数也很重要。否则系统过了 burst 还一直按 pipeline mode 跑,正常负载下反而慢。论文在 640s BurstGPT long run 中显示,dynamic restoration 让 P50 TTFT/TPOT 分别降低 28%/23%,P99 TTFT 提升 6.4×。
7. 我的 take
我觉得这篇 paper 最有意思的点是,它把 LLM serving 的 memory management 从 KVCache-centric 往 parameter-centric 推了一步。
过去大家默认“参数必须常驻,KVCache 才是可动的”。KUNSERVE 说:这个假设在 replicated serving 集群里未必成立。参数虽然是模型正确性的基础,但某一张 GPU 上的某一份参数副本不是神圣不可动的。只要全局仍然有完整参数,并且 pipeline overhead 可控,丢掉 redundant copy 反而是一个很自然的系统动作。
当然,它也有边界。第一,drop 能释放的 memory 上限就是参数大小,遇到超长 burst 还是要 autoscaling。第二,pipeline cooperative execution 对调度和网络都提出了更高要求。第三,MoE 虽然理论上适配,但 expert parallelism 下不同 expert 的热度和路由分布,可能会让 drop plan 更复杂。
但总体来说,这篇工作抓住了一个 LLM serving 里的核心矛盾:KVCache 是状态,参数是冗余;当状态撑爆 HBM 时,不该只折腾状态,也应该动冗余。
作为研究 LLM inference 系统的牛马,我挺喜欢这个角度。它不是又造一个 attention kernel,而是从 serving cluster 的资源冗余里挖了一块新空间出来。这个方向后面应该还有不少东西可以做。