EuroSys'26 | IBP 用无损 bit 压缩缓解 PCIe 瓶颈,GNN/DLRM/LLM 推理都能用
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

EuroSys’26 | IBP 用无损 bit 压缩缓解 PCIe 瓶颈,GNN/DLRM/LLM 推理都能用
原文:Reducing the GPU Memory Bottleneck with Lossless Compression for ML
1. 前言
你有没有想过,很多 ML workload 慢,并不是 GPU 算不动,而是数据到不了 GPU?
GNN training 的 node features、DLRM 的 embedding tables、LLM long-context inference 的 KVCache,经常大到 GPU HBM 放不下。于是系统只能把数据放在 CPU memory、disk 或 network storage,需要时再通过 PCIe 搬到 GPU。
这就很尴尬了:A100/H100 算力很猛,但 PCIe 带宽就那么点。GPU 在那边等数据,牛马在这边看 profiler,大家都不开心(笑)。
这篇 EuroSys 2026 的 IBP 工作关注的就是这个问题:能不能用 compression 减少 CPU-to-GPU transfer?
以往大家一提压缩,首先想到 quantization、pruning、lossy compression。但工业系统里 lossy compression 很烦,因为它可能影响 accuracy,而且影响程度和 workload/model 强相关。IBP 选择了一条更保守的路:
做 lossless compression,不牺牲任何数据 fidelity,只压掉 ML tensor 里跨样本不变的 bits。
2. 背景:为什么 PCIe 是瓶颈?
论文讨论了三类典型 workload。
第一是 GNN training。GNN 的 graph topology 和 feature vectors 通常很大,训练时每个 mini-batch 都要 sample 一批节点/边,再把对应 feature 搬到 GPU。很多系统会做 GPU cache,但 cache 放不下全部数据,miss 后仍要走 PCIe。
第二是 DLRM inference。推荐模型里的 embedding tables 可以有上亿行,GPU memory 放不下时,lookup 需要从 CPU memory 搬 embedding entries 到 GPU。
第三是 LLM KV-cache offloading。长上下文 LLM 中 KVCache 可能远超 HBM,系统会把部分 KVCache offload 到 CPU,再在 decode 时按需搬回 GPU。对于 long-context inference,KV transfer 本身就会变成 critical path。
传统思路是用 lossy compression,比如 quantization。但问题是:lossy 方法需要针对模型和数据调参,出了 accuracy regression 很难 debug。lossless compression 看起来安全,但很多通用算法如 Huffman、LZ4、zStd、GDeflate 在 GPU critical path 上 decompression overhead 太高,反而变慢。
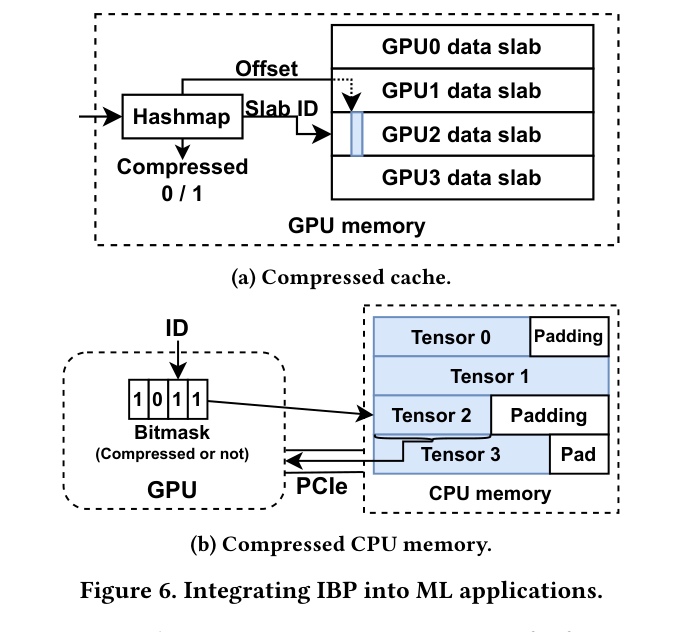
论文前面有一个很有意思的表:很多算法压缩率不错,但 transfer + decompression 后速度不一定快。比如 zStd 在 sparse GNN 上 space saving 很高,但 transfer speedup 并不好。如下是论文 Table 1 的 transfer speedup 对比,IBP 在几乎所有场景都排第一,但这并不是靠最高压缩率换来的——IBP 的核心是压缩后搬得更快,解得更快。
3. 核心观察:ML tensor 的 bit pattern 有结构
普通 bit packing 会看一个 tensor 内部的数值范围,删除高位不需要的 bits。但 ML tensor 里的浮点值范围常常比较大,所以传统 bit packing 空间有限。
IBP 的观察是:很多 ML 数据虽然数值看起来分散,但在 bit level 上有低熵结构。比如 floating-point 的 sign bit、exponent bits,在很多 tensors 之间可能高度一致。也就是说,同一个 bit position 在大量 tensor 中都是同一个值。
论文把这种 bits 叫 invariant bits。IBP 会把这些跨 tensor 不变的 bits 记录在很小的 metadata 里,然后在每个 tensor 的 compressed data 中删掉它们。
如下图,左边是 conventional bit packing,右边是 invariant bit packing。红色 bits 被移除,蓝色部分是真正传输的数据。

这个设计很适合 ML pipeline:metadata 很小,可以常驻 GPU;tensor data 仍在 CPU memory,GPU 需要时发起读取并解压。
4. 方法:IBP 怎么压、怎么解?
IBP 的 metadata 主要有两个:
-
Mask:哪些 bit positions 是 invariant。 -
Bitval:这些 invariant bits 的具体值。
压缩时,IBP 会扫描一批 tensors,找出满足 threshold 的 invariant bit positions。之后每个 tensor 只保存非 invariant bits,加上一点 participation bits,用来处理某些 tensor 不适合压缩的情况。如果压缩后不省空间,IBP 直接保留原始 tensor,避免 compressed dataset 反而变大。
解压更关键,因为它在 critical path 上。IBP 用一个 warp 解压一个 tensor,每个 thread 负责一个 chunk,整个过程尽量只在 warp 内通信,避免跨 warp synchronization。
解压大概分几步:
- warp 协作从 CPU memory 读一段 compressed data 到 workspace;
- 每个 thread 读自己的 Mask chunk,统计需要恢复多少 bits;
- warp 内做 exclusive scan,确定每个 thread 的 offset;
- 异步预取下一段 data;
- 根据 Mask/Bitval 把 invariant bits 填回去。
这套流程的重点是:PCIe transfer 和 decompression overlap,且 CPU 不在 critical path 上。
论文还专门优化了 GPU-initiated PCIe transfer。相比 CPU 发 DMA,GPU zero-copy 对小块随机 tensor transfer 更合适,但要做 aligned access。IBP 保证 warp 尽量发起 128B-aligned transactions,减少 PCIe transaction overhead。
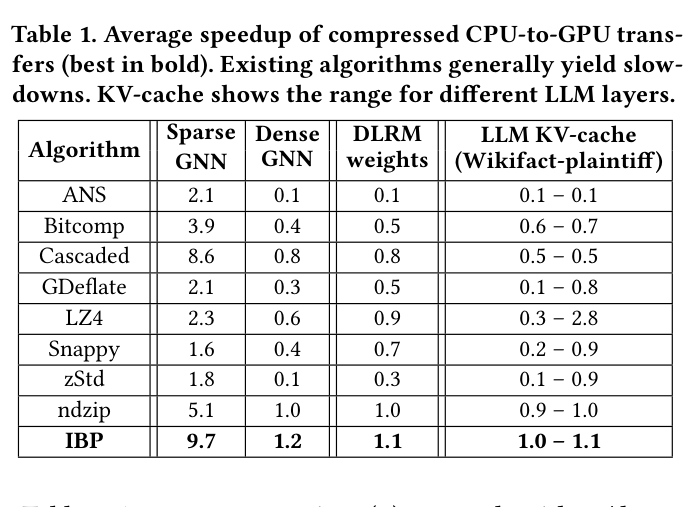
如下图是 IBP 集成到 ML 应用中的两种方式:(a) 把 GPU cache 里的数据压缩存储,(b) 把 CPU memory 中等待搬运的数据压缩,两种方式都让 PCIe 每次传输更少的 bits。
5. 实验设置
IBP 的实验平台是一张 A100 GPU,CPU memory 300GB,CPU-GPU interconnect 是 16-lane PCIe Gen 4,理论单向 32GB/s,实测约 25GB/s。软件栈是 CUDA 11.7、Python 3.8、PyTorch 1.13.1。
baseline 包括 NVIDIA nvCOMP v3.0.1 和 ndzip-gpu。系统集成上,作者把 IBP 接到三个方向:
- GNN:DGL v2.1 和 Legion;
- DLRM:Colossal-AI 的 CachedEmbeddingBag;
- LLM:InfiniGen,一个 KV-cache offload 系统。
数据集也覆盖了几类:
- GNN:Pubmed、Citeseer、Cora、Reddit、Products、MAG240M;
- DLRM:Criteo 1TB 上训练的 NVIDIA DLRM embedding weights;
- LLM:Meta OPT 系列,输入 1920 tokens,输出 128 tokens,batch size 20。
6. 结果一:压缩率不是最高,但 transfer 最快
IBP 在 sparse GNN 上空间节省很高,在 dense GNN、DLRM、LLM KVCache 上空间节省相对 modest,但很稳定。论文报告 IBP 在 dense GNN 上大约 10% 到 12% space saving,在 DLRM 上约 8%,LLM KVCache 上最高约 10%。
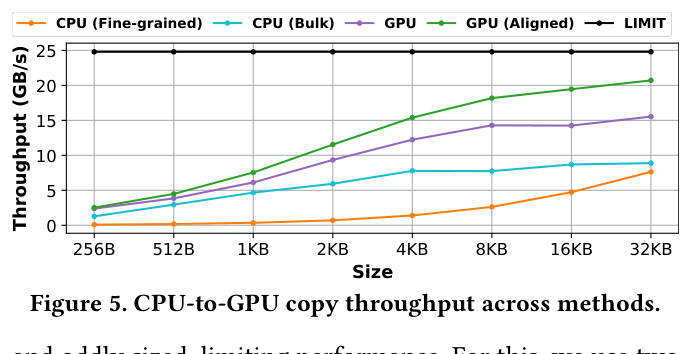
这听起来不夸张,但关键是 transfer + decompression throughput。如下图是不同传输方法的 CPU-to-GPU copy throughput(Figure 5),GPU aligned transfer 最接近理论带宽上限(LIMIT 黑线),而 CPU fine-grained 方法在小 tensor 上几乎没有吞吐可言。IBP 的 speedup 正是建立在 GPU aligned transfer 这个基础上的。
IBP 在各类数据上都有比较好的 transfer speedup:Table 1 中 IBP 在 Sparse GNN 上 9.7×,Dense GNN 1.2×,DLRM 1.1×,LLM KVCache 1.0 到 1.1×。很多通用算法虽然压得更小,但解压开销会抵消收益。
论文还做了 sampling 实验:只采样 1%、5%、10% 数据来生成 Mask/Bitval,compression ratio 基本和全量接近。这对 streaming 或大规模 dataset 很重要,因为 preprocessing 不能太重。
7. 结果二:GNN、DLRM、LLM 都有收益
GNN 上,IBP 接入 DGL 后平均加速 56%;接入 Legion 后平均加速 74%。在 Legion 中,IBP 同时做 compressed cache 和 PCIe traffic compression,最大 throughput 提升到 2.7×。
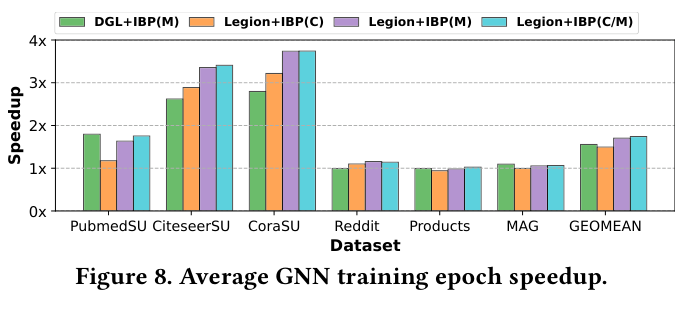
如下图(Figure 8),IBP 对不同 GNN dataset 的训练 epoch speedup 有明显提升,CoraSU 上 Legion+IBP(C/M) 最高接近 3.5×,跨 6 个 dataset 的几何平均大约 1.7×。
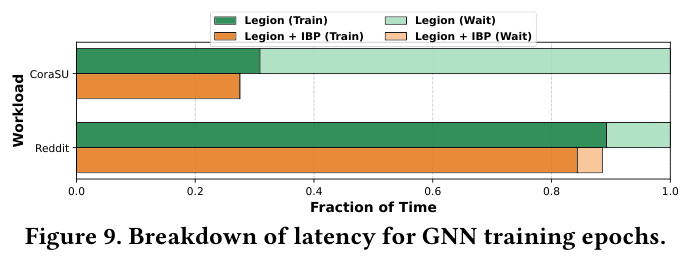
更细粒度的 latency breakdown 也揭示了 IBP 的作用机制。如下图(Figure 9),IBP 主要把 Legion 的 Wait 时间(等 PCIe 传输)压缩,Train 时间基本不变,说明加速完全来自 PCIe transfer,没有额外的 compute overhead。
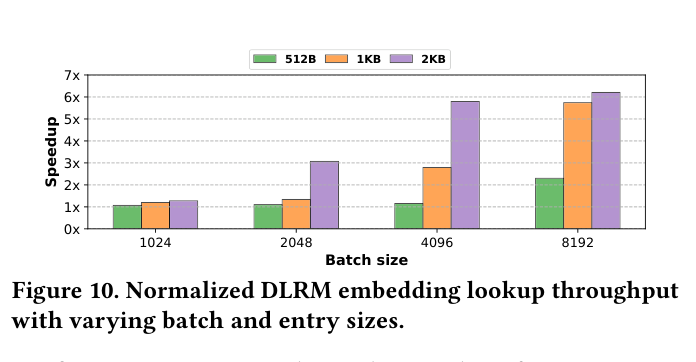
DLRM 上,IBP 的收益主要来自 GPU-based lookup/transfer。baseline 需要 CPU 做 table lookup,然后把结果搬到 GPU;IBP 用 GPU zero-copy 直接并行读 CPU memory。随着 batch size 和 embedding entry size 增大,IBP 的优势更明显。如下图(Figure 10),在 entry size 为 1KB 和 2KB 时,batch size=8192 的 speedup 最高超过 6×。论文摘要里给出的平均提升是 DLRM embedding lookup 快 180%。
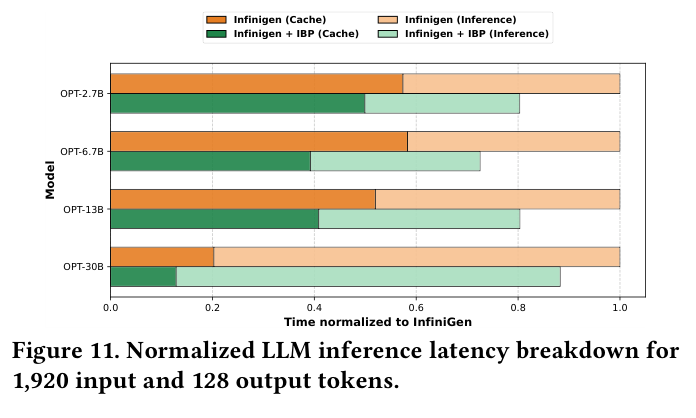
LLM 上,作者把 IBP 接入 InfiniGen 的 KV-cache fetching 路径。实验使用 OPT-2.7B、6.7B、13B、30B,1920 input tokens,128 output tokens,batch size 20。IBP 让 KV-cache movement latency 最高降低 37%,整体 inference latency 最高降低 27%,平均约 25%。如下图(Figure 11),蓝/绿色是 Infinigen+IBP,橙/红色是 baseline,IBP 明显压缩了 Cache 传输时间。
有个细节值得注意:LLM 场景下 IBP 不提前 preprocess 全部数据,而是在每次 prefill 阶段采样 prompt tokens 的 K/V 生成 Mask/Bitval,用于 decode 阶段压缩 output token K/V entries。这样 prefill 会增加约 10% 开销,但因为 prefill 占总时间不到 20%,decode transfer 省下来的时间覆盖了这部分成本。
8. 结果三:为什么 GPU-initiated transfer 很关键?
论文专门比较了 CPU fine-grained copy、CPU bulk copy、GPU zero-copy、GPU aligned copy。对于小块随机 tensor,CPU fine-grained DMA overhead 很高;CPU bulk copy 要先在 CPU 侧 gather 成连续 buffer;GPU zero-copy 可以让 GPU warp 直接发起读取。
更进一步,aligned transfer 比普通 GPU copy 高 25% throughput。这个点很工程,但很关键。很多时候系统 paper 的优化不是一个惊天动地的新算法,而是把数据路径上的每个 transaction overhead 都算清楚。
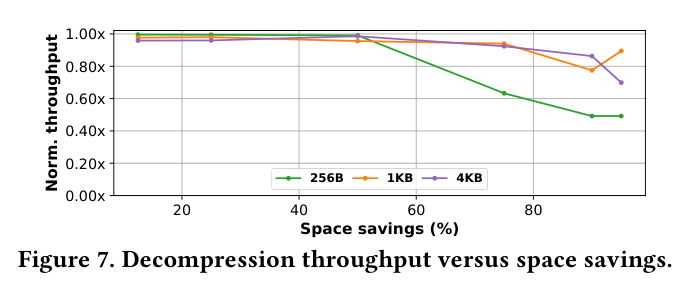
IBP 的 decompression throughput 在 space saving 小于 50% 时能达到 ideal 的 95% 以上。如下图(Figure 7),三种 chunk size(256B/1KB/4KB)在压缩率不太高时,throughput 都非常接近上限,说明 decompression overhead 基本被 GPU parallelism 和 PCIe transfer overlap 掩盖掉了。也就是说,对于 dense ML tensors 这种压缩率不算极高的场景,decompression 开销几乎是”免费”的。
9. 我的 take
IBP 这篇 paper 的味道很系统:它没有承诺“压缩率最高”,而是明确盯着 ML pipeline 里的真实瓶颈:PCIe transfer latency。
很多 compression 方法只看 compression ratio,其实对 serving/training 不够。因为数据压小了以后还要解,解压如果在 critical path 上太慢,就会把省下来的 PCIe 时间吃回去。IBP 的核心取舍是:牺牲一点理论压缩率,换取极低 metadata、warp-level decompression、GPU-initiated aligned transfer。
我觉得这个思路对 LLM inference 特别有意思。现在 KVCache 优化有很多 lossy 方向,比如 eviction、quantization、sparsification。但 production 里有时候你就是不想动模型语义,不想解释为什么某个 prompt 下质量掉了。lossless 方法虽然收益可能不如 aggressive quantization,但落地阻力小很多。
当然,IBP 也不是银弹。LLM KVCache 上的 compression ratio 只有几个百分点到 10% 左右,OPT 这种每个 head 的 K/V entry 又小,压缩收益有限。论文也提到,新模型如果 K/V entry 更大,收益可能更明显。另一个边界是 preprocessing 和 metadata 对 workload distribution 的依赖,如果数据分布变化大,Mask/Bitval 可能需要重新估计。
但总体看,这篇工作提醒我们一个很朴素的事实:GPU 系统优化不只是算得快,还要搬得聪明。 在 GNN、DLRM、LLM 这些越来越依赖大规模 memory hierarchy 的 workload 里,lossless tensor compression 可能会成为一个很实用的系统组件。