FAST'26 | SolidAttention 把 SSD 搬进 LLM 推理,笔记本也能跑 128k 上下文
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

FAST’26 | SolidAttention 把 SSD 搬进 LLM 推理,笔记本也能跑 128k 上下文
原文:SolidAttention: Low-Latency SSD-based Serving on Memory-Constrained PCs(FAST 2026,上海交通大学 IPADS 实验室)
1. 前言
你有没有想过,在自己的笔记本上本地跑一个长上下文的 LLM,体验一下”私有 AI 助手”到底是什么感觉?
这个想法很美好,现实很骨感。
现在主流的笔记本——就是那种配个 16GB 内存、8GB 显存的标配机器——在面对 128k token 上下文时,连 KV cache 都装不下。一个 8B 参数的模型,光 KV cache 就需要 16GB 内存,比模型权重本身多 4 倍多。
所以现在的本地部署方案(llama.cpp、Ollama 这些)基本默认你的内存够用,但大多数人的机器其实根本不够用。
今天想和大家聊聊 FAST 2026 的这篇工作——SolidAttention。他们的思路是:内存不够,SSD 来凑。但怎么凑,里面有很多讲究。
2. 核心矛盾:KV Cache 的内存危机
先交代下背景。
LLM 的 autoregressive decode 阶段,每生成一个 token,都需要把之前所有 token 的 Key 和 Value 矩阵拿出来做 attention。为了不重复计算,就把这些 K/V 缓存下来,这就是 KV cache。
问题在于,KV cache 随着序列长度线性增长。如下图左,Llama-3.1-8B(INT4 量化权重)在 128k context 下,KV cache 需要 16GB,是模型权重的 4 倍多。而右图说明了 SSD 的特性:读取单元越大,带宽越高。4KB 小块随机读约 1GB/s,1MB 以上大块读能到 6GB/s——相差 6 倍。
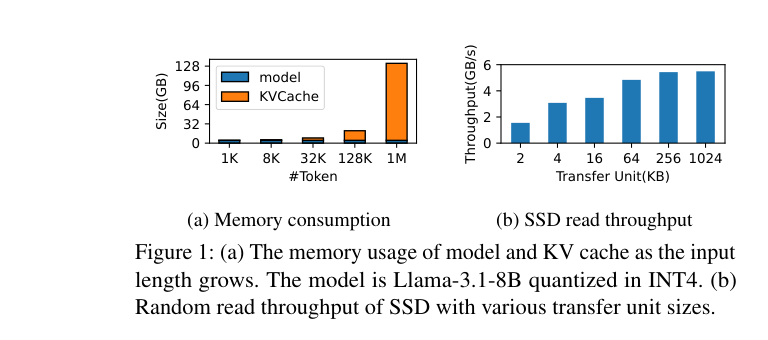
更难受的是,市面上大部分笔记本只有 8-16GB 内存、6-8GB 显存。在这种机器上,128k context 不是说”慢一点”,是直接装不下。
那量化 KV cache 行不行?
INT4 量化之后效果很差——KV cache 里有很多异常值(outlier),激进量化直接把精度打烂了(Qwen-2.5-7B 的精度从 71.39% 暴跌到 18.63%)。
那把 KV cache 卸载到 SSD 呢?
这个方向是对的,但之前的工作(比如 FlexGen)有一个核心假设:系统里有足够多的并发请求,让 SSD 加载数据的时候,GPU 还有别的请求可以算。
如下图,高并发场景(上):Request 1 在等 KV cache 的时候,GPU 可以跑 Request 2 的 FFN——I/O 延迟被”藏住”了。低并发场景(下):只有一个请求,KV cache 加载期间 GPU 完全空转(GPU Idle),SSD 等 GPU 算完也在空转(SSD Idle)。
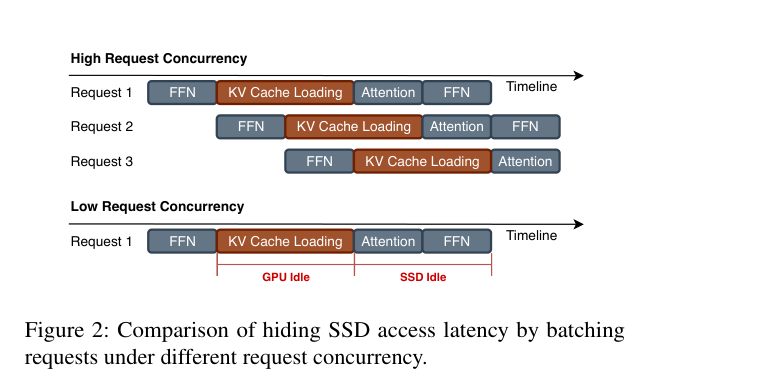
笔记本本地推理的场景,根本就没有并发。只有你一个人在用,batch size=1。SSD 加载数据的时候,GPU 只能干等。加载 1k token 的 KV cache(128MB)大约需要 40ms,这能占一次 decode step 将近一半的时间。
3. 问题的根源:SSD 和稀疏 Attention 天生相克
现有 SSD offloading + attention sparsity 方案的毛病,不只是”并发不够”这一个。
更深层的矛盾是:动态稀疏 attention 的访问模式,和 SSD 的特性天生相克。
动态稀疏 attention 每个 decode step 都要根据当前 query,动态选出需要的 KV 块,加载进来。这些块是按 token 粒度选的,单块可能只有几 KB,产生大量细粒度随机 I/O,SSD 带宽利用率极低。
SolidAttention 的核心 insight:要把稀疏 attention 算法和 SSD 存储管理协同设计(co-design),让数据访问的粒度对齐 SSD 的特性,同时精细编排计算和 I/O 的重叠。
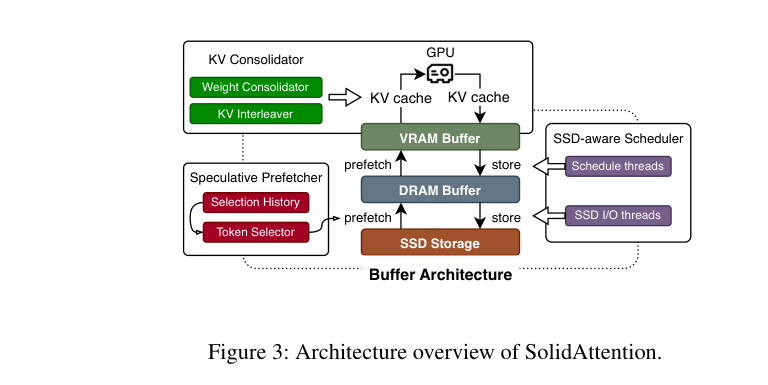
4. SolidAttention 整体架构
三个核心挑战,三个解决模块:
- 挑战 1:如何在不牺牲精度的情况下,把细粒度访问变成粗粒度访问?→ KV Consolidator
- 挑战 2:动态 attention 在算完才知道需要哪些块,来不及提前加载,怎么办?→ Speculative Prefetcher
- 挑战 3:内存受限时,GPU 读数据和 SSD 预取数据可能发生冲突,怎么安全调度?→ SSD-aware Scheduler
如下图,SolidAttention 系统架构:整个 KV cache 存在 SSD 里,decode 时按需动态加载到 GPU VRAM。三个模块协同工作,把 I/O 延迟尽量藏在计算背后。
Block-wise 注意力稀疏。SolidAttention 把 KV cache 按 context 长度切成三类 block。如下图,用当前 query Q 和每个 block 的 representative vector(代表向量)做相似度计算,选出 Top-K 个 block 参与 attention 计算:
- Init Block(绿色):固定覆盖开头几个 token,处理 attention sink 现象
- Local Block(蓝色):滑动窗口,覆盖最近生成的 token
- Selected Block(棕色):每次 decode 时动态选出的高相关 block
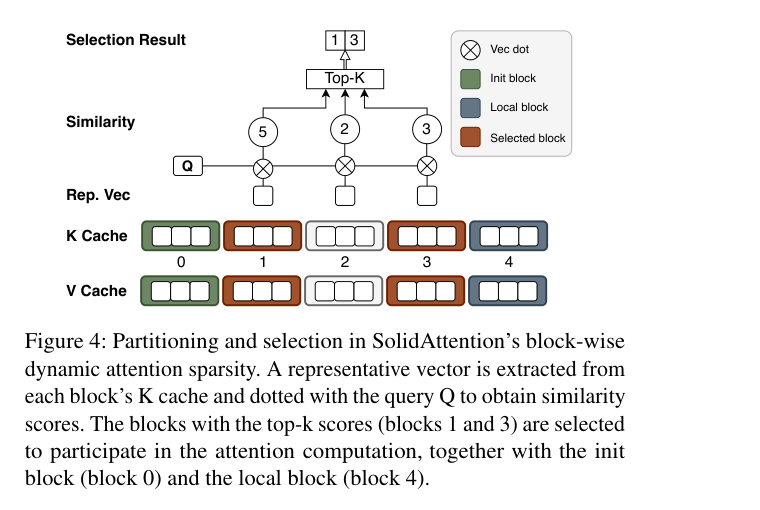
类比理解:把整本书按段落分好,每次提问不是把整本书都翻一遍,而是先看每段的”摘要”(representative vector),只把最相关的几段拿出来精读(attention 计算)。大幅减少了需要从 SSD 加载的 KV cache 量。
5. KV Consolidator:让 K 和 V “手拉手”走,翻倍带宽
问题:Block 越大,SSD 读的粒度越大,带宽利用率越高——但每个 block 的 representative vector 要概括更多 token,精度会下降。
如下图,block size 从 32 增大到 256,两个模型的 recall rate 都明显下降,从约 90% 跌到约 60%:
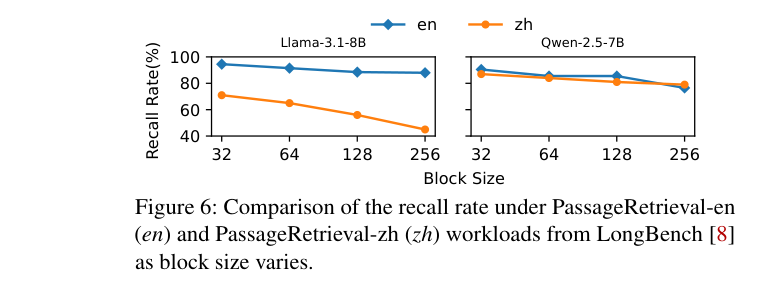
所以 SolidAttention 选用 block size=32,精度损失很小。但 32 token 的 block 在 SSD 上读起来还是太碎了——怎么在不增大 block 的情况下提高传输粒度?
解法:把 K 和 V 交织在一起,把每次 I/O 的传输单元翻倍。
K 和 V 的形状完全一样(都是 N×H 的矩阵)。如下图:
- Typical(上):K 和 V 分开存、分开读,同一块 block 要读两次 SSD
- Interleaved(下):按 token 粒度交织,K₁V₁K₂V₂…,一次 SSD 读把 K 和 V 都搬过来
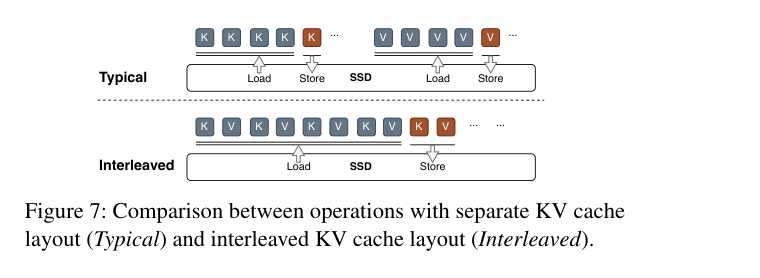
传输单元翻倍,I/O 次数减半,SSD 带宽利用率 double。精度完全不受影响——每个 block 里的 token 数量没变,representative vector 质量不变。
工程实现:如下图,对比两种 projection 计算方式:
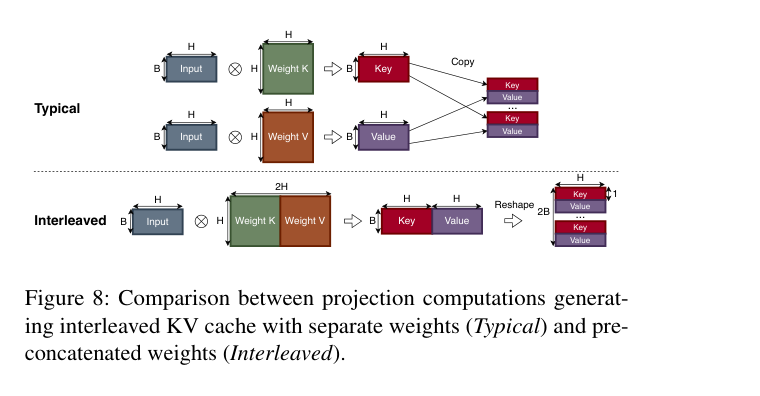
在模型初始化时把 K projection 和 V projection 的权重矩阵预先拼接成一个矩阵(Weight K+V),用一次矩阵乘法直接生成交织的 K/V 输出,避免运行时 reshape 开销。attention kernel 里用 stride=2H 的访问模式来逻辑上分开 K 和 V,实测延迟开销 ≤2%。
6. Speculative Prefetcher:历史会重演,让 SSD 提前读
问题:每一层选哪些 KV block,是根据这一层的 query 计算出来的。在计算这一层 attention 之前,下一层要哪些 block 根本不知道。
等到上一层算完再去 SSD 读,就产生了 blocking latency——GPU 干等 SSD。
突破口:相邻层之间的 block 选择结果高度相似。
如下图,在 LongBench 的 8 个 benchmark 上统计,跨层的 block 选择相似度平均在 75%~90% 之间,两个模型都一致:
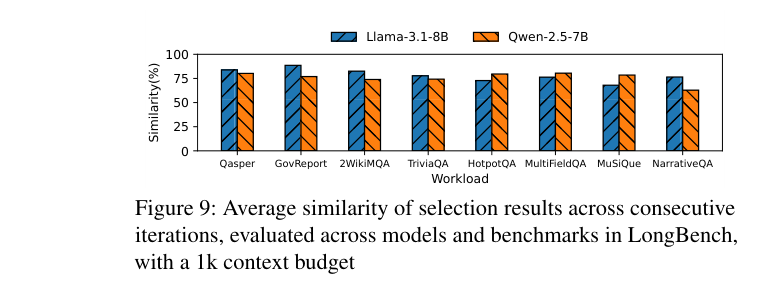
直觉也说得通:模型在处理同一个输入时,不同层关注的 context 区域往往差不多(比如处理代码补全,每层都在关注函数定义那几个 token)。
有了这个观察,就可以做 speculative prefetching:用上一层的选择结果预测下一层需要哪些 block,提前发起 I/O。如下图:
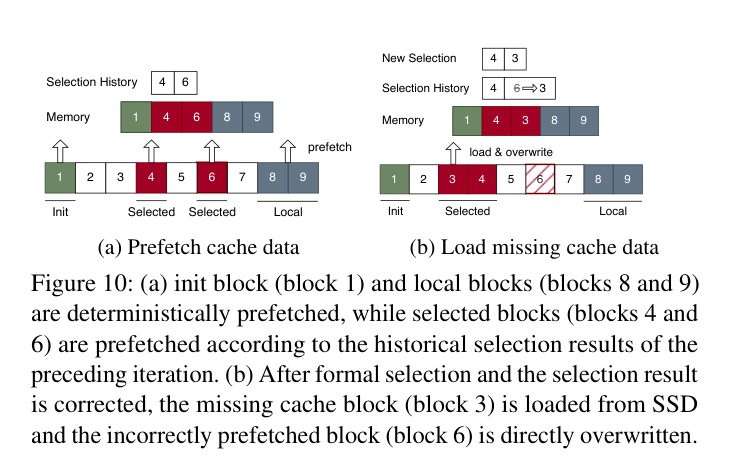
- (a) 预取命中:上一层选的块 {1,3},提前加载到 DRAM,下一层实际也选 {1,3},直接用
- (b) 预取失误:预取了块 6,但实际需要的是块 3,把块 3 直接覆写上去,不需要重排序
整个单层的数据流时间线如下图。可以看到,SSD 预取(蓝色箭头)是在上一层的 FFN 计算期间就提前开始了:
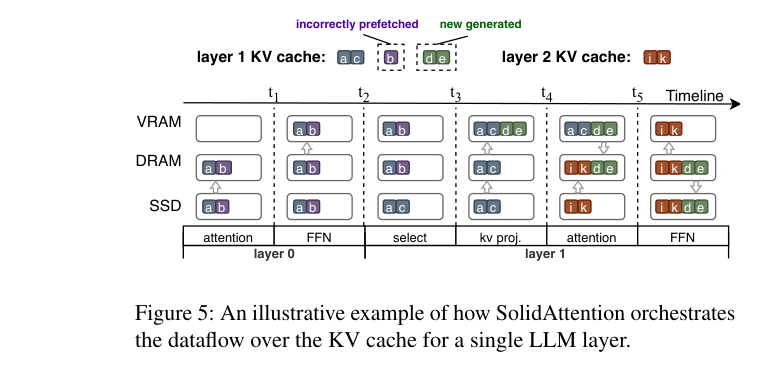
时间线解读(以 Layer 1 为例):
- t₁→t₂:Layer 0 的 FFN 运行期间,SolidAttention 就开始 prefetch Layer 1 需要的 KV 块(VRAM←SSD)
- t₂→t₃:Layer 1 执行 token selection(select),确认命中 {a,c},miss 了 {b}(橙色虚线框)
- t₃→t₄:补传 miss 的块 {b},同时 GPU 算当前 token 的 kv proj,新 KV pair 写到 DRAM
- t₄→t₅:Layer 1 self-attention 计算,同时异步 prefetch Layer 2 的 KV 块(DRAM←SSD)
- FFN 期间:把 DRAM 里预取的数据传到 VRAM,同时把 Layer 1 新 KV pair 写回 SSD
GPU、CPU、SSD 几乎全程都在忙,没有大段空闲。
7. SSD-aware Scheduler:DAG 调度,同步点复用
问题:内存受限时,同一块 DRAM 缓冲区既要给 GPU 提供数据,又要接收 SSD 预取来的数据。Naive 实现是等所有 I/O 完成 GPU 再开始算——GPU 和 SSD 串行,效率极低。
如下图,三种调度方案对比(一层 attention module 的完整时间线):
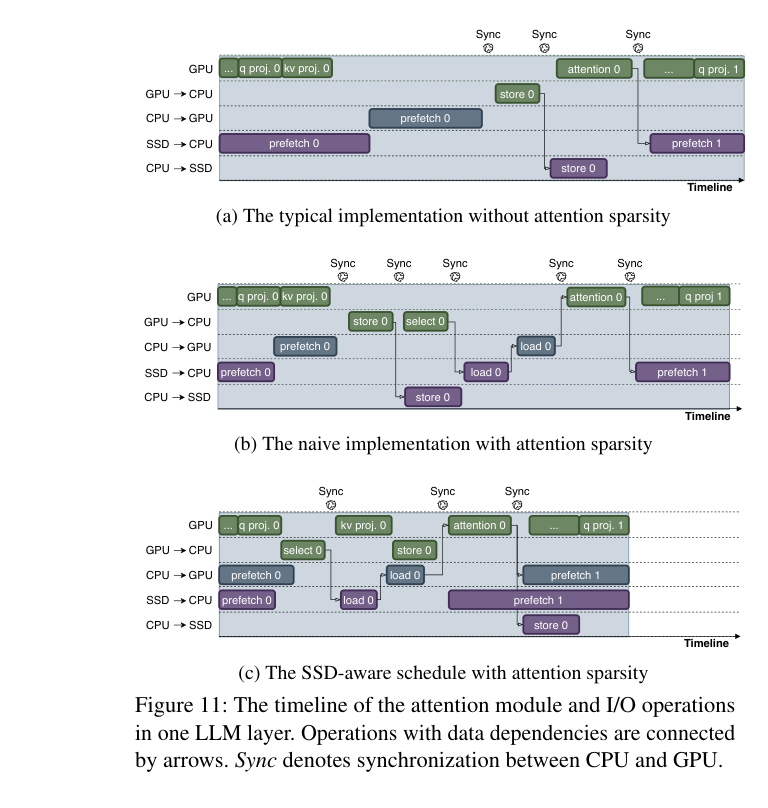
- (a) 不用 attention sparsity:没有 select/load 步骤,但 GPU 和 SSD 之间有多个 Sync 等待点
- (b) Naive + attention sparsity:有 5 个 Sync 点,大量 GPU 空等,是最慢的方案
- (c) SSD-aware schedule(SolidAttention):只有 3 个 Sync 点,GPU 计算和 SSD I/O 大量重叠,关键路径更短
两个核心设计:
1. 微任务分解 + 细粒度重叠
把 attention module 分解成微任务:q proj → kv proj → select → prefetch → load → attention → store
用 DAG(有向无环图)建模任务依赖关系。调度器找出关键路径,优先执行关键路径上的任务。非关键任务(比如写回新 KV 到 SSD)在不影响关键路径的情况下尽量并行。
2. 同步点复用
多个 microtask 共享一个同步点,减少 CPU-GPU 之间的握手频率。例如:把”等待 selected block 加载完成”和”等待 init/local block 加载完成”两个同步点合并成一个。少同步 = 少停顿 = 更快。
8. 实验:到底快了多少?
8.1 实验设置
两台真实笔记本:
- CUDA 后端:Intel Ultra 9 185H + RTX 4070 Laptop GPU(8GB VRAM)+ 64GB DDR5 + 1TB Samsung 990 PRO PCIe 4.0 SSD
- SYCL 后端:Intel Ultra 7 255H + Intel Arc 140T 集成显卡 + 64GB DDR5 + 同款 SSD
测试模型:Llama-3.2-3B、Llama-3.1-8B、Qwen-2.5-7B(权重 INT4,KV cache FP16),DRAM 限制 16GB,batch size=1。
8.2 端到端性能
如下图,CUDA 后端三个模型在不同 context 长度下的推理速度(token/s):

如下图,SYCL 后端(集成显卡)的性能:

关键数字汇总:
| 对比 | 加速比 |
|---|---|
| CUDA + 128k,vs Offload+Sparse(3个模型) | 2.4×、2.8×、3.1× |
| CUDA + 16k,vs FlexGen | 58.9× |
| SYCL + 128k,vs Offload+Sparse | 1.9×~2.5× |
FlexGen 在 batch=1 的情况下惨不忍睹——大量 page fault 触发的细粒度 SSD 随机访问,带宽浪费严重,没有并发可以隐藏 I/O 延迟。
8.3 内存占用
SolidAttention 只在 DRAM 里保留一层 1k token 的 KV cache buffer,其余全在 SSD:
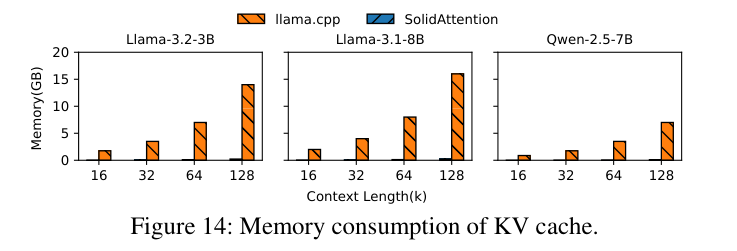
KV cache 内存占用比 llama.cpp 降低 62×(约 98%),三个模型全都一样。
8.4 精度
如下图,Table 1 对比精度,Figure 16 展示投机预取的 blocking latency 降低效果:
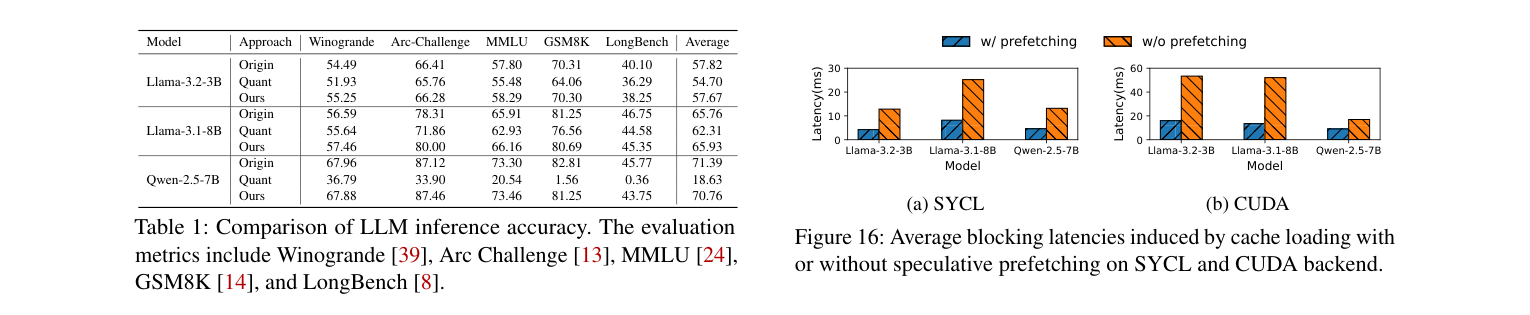
精度方面:
- INT4 KV 量化(Quant):Qwen-2.5-7B 从 71.39% → 18.63%,直接废了
- SolidAttention:各项 benchmark 精度与原始模型差距 ≤2%
投机预取的 blocking latency 降低:
- SYCL 后端:3.1×
- CUDA 后端:3.9×
CUDA 收益更大是因为 RTX 4070 算得快,对 I/O blocking 更敏感。
8.5 和纯内存方案对比
SolidAttention 把 KV cache 全部卸到 SSD,但和纯内存推理(InDRAM)差多少?
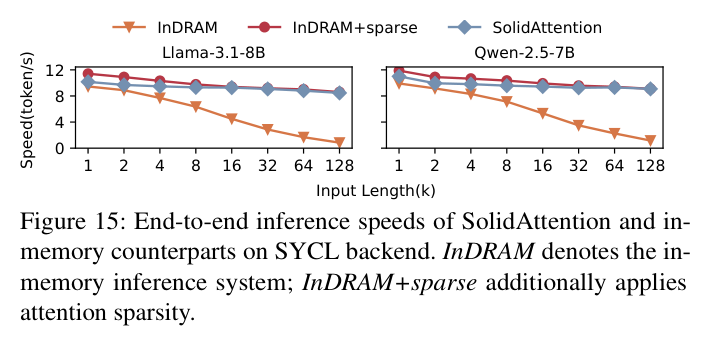
结果:仅 ≤11% 的吞吐量损失。把 KV cache 从内存搬到 SSD,速度几乎不变,但内存节省了 98%。
8.6 消融实验
如下图,左:KV 交织 vs 不交织的 attention 延迟对比;右:调度方案的逐步叠加效果:
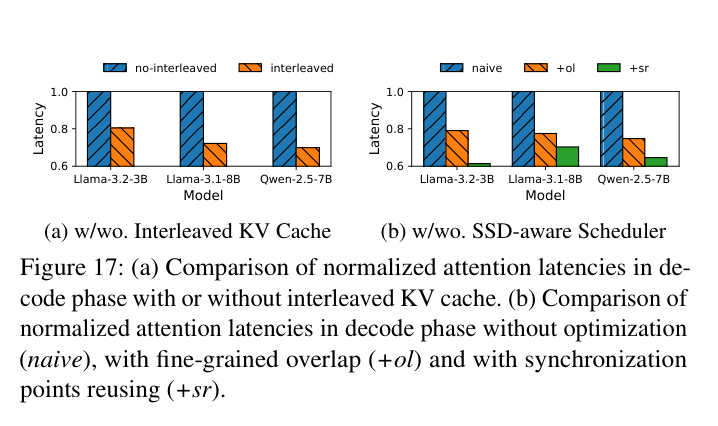
三个模块的独立贡献:
| 模块 | 效果 |
|---|---|
| KV Consolidator(交织) | attention 延迟降低 22% |
| SSD-aware Scheduler(细粒度 overlap) | 性能提升 25% |
| 同步点复用 | attention 延迟再降 22% |
9. 总结
SolidAttention 这篇工作的切入点很准:
- 确认了一个核心矛盾:动态稀疏 attention 和 SSD 特性天生不匹配,细粒度随机 I/O 导致 SSD 带宽严重浪费
- co-design 思路:不把 attention 算法和存储系统看作两个独立的问题,而是协同设计,让数据访问粒度对齐 SSD 特性
- 三个技术点都很实在:KV 交织(纯工程技巧,不影响精度)、投机预取(利用跨层选择相似性)、DAG 调度(精细化计算/I/O 重叠)
工程完成度也不错:CUDA + SYCL 双后端,约 25k 行代码,在真实笔记本上跑出了这些数字。
对做本地推理的同学来说,这个工作提供了一种不量化 KV cache 就能大幅降低内存占用的路子。现在还是研究原型,能不能接进 llama.cpp/Ollama 主线还是个问题,但思路是对的。
欢迎评论区聊聊你对本地部署 LLM 的看法——有没有在自己的笔记本上实际跑过长上下文推理,感受如何?