LLM 推理启动慢?华为用一个「可编程 Page Cache」把模型加载砍了 79%
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

LLM 推理启动慢?华为用一个「可编程 Page Cache」把模型加载砍了 79%
原文:Accelerating Model Loading in LLM Inference by Programmable Page Cache(USENIX FAST 2026)
1. 前言
你有没有遇到过这种情况:一个 LLM 推理服务,业务流量一上来,需要紧急扩容,但新起一个实例,光是模型加载就要等一两分钟,有时甚至更长?
这不是什么小概率踩坑,这是 MaaS(Model-as-a-Service)场景下普遍存在的痛点。Qwen2.5-72B 这类大模型,光文件就 130+ GB,加载到 NPU/GPU 上是个实实在在的 I/O 密集操作。论文里测了一组数据:模型加载的开销占推理服务整个启动时延的 50% 以上,这还是算上了容器初始化、KV cache 初始化的情况。
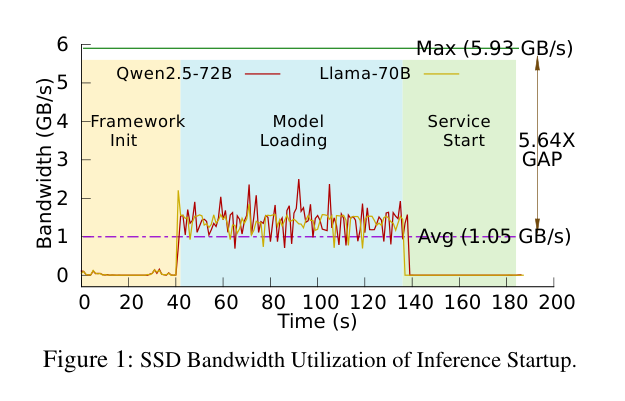
更细思极恐的是:SSD 的理论最大带宽是 5.93 GB/s,但实测过程中平均带宽只有 1.05 GB/s,只用了约 17%!SSD 在那儿闲着,但模型就是加载不快。
这是整个行业在 LLM 大规模部署上面临的核心矛盾之一:存储硬件的性能远没有被充分利用,瓶颈卡在了软件层——具体来说,是 Linux 内核的 page cache 策略。
这篇来自华为的论文(发表在 FAST 2026)就是专门冲着这个问题去的。他们提出了 PPC(Programmable Page Cache) 框架 + MAIO(Model-Accelerated I/O) 缓存策略,最终实现模型加载时延降低 79%,在弹性部署场景下 inference throughput 提升 36%。
2. 背景:为什么是 page cache?
先交代下背景。
LLM 推理服务启动分三个阶段:
- Framework Init:容器初始化、推理框架启动
- Model Loading:从 SSD 文件系统把模型权重逐 tensor 加载到 XPU(NPU/GPU)
- Service Start:KV cache 初始化、推理服务就绪
瓶颈在 Model Loading 阶段。模型文件存在 SSD 上,通过内核文件系统读取,数据先进 page cache(内存),再传到 XPU 显存。
内核默认的 page cache 策略对通用场景设计,对模型加载这种特殊 I/O 场景非常不友好:
观察一:prefetch 机制无法充分利用 SSD 并发带宽
如下图,可以很清晰地看到 SSD 带宽利用率的变化曲线——峰值能到 5.93 GB/s,均值只有 1.05 GB/s,足足差了 5.64x。原因是内核的 prefetch 策略受限于 kworker 线程数量,SSD 本身的高并发能力根本发挥不出来。另外,prefetch 的时机也不对,在 framework init 阶段(这段时间 CPU 在忙别的,I/O 本来可以提前做)根本没有 prefetch。
观察二:prefetch 的精度很低,大量无效数据被预取
内核 page cache 只会对同一文件内相邻偏移的数据做顺序预取,完全感知不到模型加载的实际 I/O 顺序——不同 tensor parallelism 配置下,每个 XPU worker 的读取顺序是不一样的。预取了不该预取的数据,反而挤占了内存。
观察三:eviction 策略在内存受限场景下引发 cache thrashing
当可用内存不够放下整个模型时(比如只给模型加载留了 64GB 内存),内核用 LRU 驱逐页面,但完全不知道哪些数据”用了就不会再用”,导致后面要用的数据被驱逐,引发 cache thrashing,加载反而更慢。
3. 现有方案的问题:性能好但兼容性差
行业里不是没有人尝试优化这个问题。ServerlessLLM 通过改造推理框架的 model loading 逻辑来做 pipeline prefetch;BlitzScale 利用 NVLink/RDMA 实现多机间模型共享。
但这些方案有个共同问题:为了性能牺牲了兼容性。
- 依赖特定推理框架(比如只支持 vLLM,不支持 Transformers)
- 依赖特定硬件(NVLink、HCCS 等互连硬件)
- 需要修改内核,而内核升级在生产集群里是几年才能完成的大工程
- 需要转换模型格式,额外存储开销
华为的出发点是:在 MaaS 生产环境里,你不能假设所有节点都是同款硬件,也不能随意改推理框架。必须做到高性能、高兼容性两手都要抓。
4. 解法:PPC + MAIO
4.1 PPC:可编程 Page Cache 框架
PPC 的核心思路是——在不修改内核、不改推理框架的前提下,让用户可以自定义 page cache 策略。
如下图,有几种控制 page cache 的技术路线:
| 方案 | 是否非侵入 | 灵活性 | 轻量性 |
|---|---|---|---|
| FUSE-based(RFUSE、XFUSE) | ✓ | ✓ | ✗(overhead 高) |
| eBPF-based(PageFlex、FetchBPF) | ✗(需要改内核) | ✗(策略复杂度受限) | ✓ |
| fadvise(内核原生) | ✗ | ✗(无法深度协作前端 I/O) | ✓ |
| PPC(本文) | ✓ | ✓ | ✓ |

PPC 分两个核心组件:
RFS(Routing File System):基于 stacked filesystem 机制(类似 OverlayFS),在不修改底层文件系统的情况下,通过重写 VFS 接口来拦截 I/O 操作。当应用发起文件读取,RFS 检查 page cache 是否命中:命中则直接返回;miss 则通过 UPC(Userspace Procedure Call) 把事件异步发送到用户态,同时调用底层文件系统的原生读取流程——整个过程非阻塞。
CPRT(Cache Policy Runtime):运行在用户态的策略执行引擎。它维护一个线程池,监听 RFS 发来的 I/O miss 事件,解析事件信息(文件、偏移、长度、PID),然后调用用户自定义的 prefetch/evict 函数。用户只需要编译一个动态链接库,通过 reg_policy 注册进来就行,策略可以随时热切换。
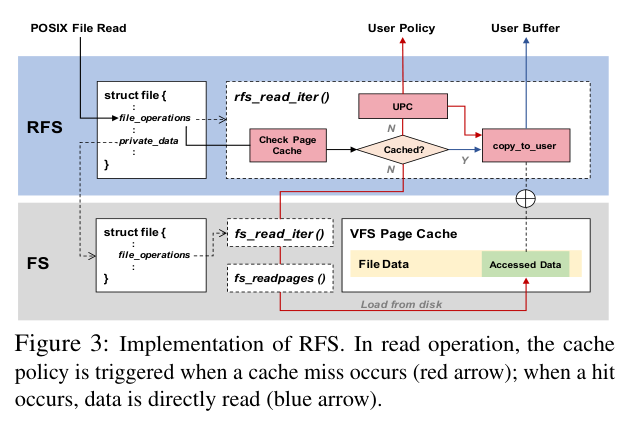
这个设计非常干净:PPC 作为一个独立内核模块存在,不需要修改现有内核模块,对前端 I/O 性能影响极小(实测引入的额外 overhead 只有 3.7%~6.4%,而 RFUSE 有 14%~15%)。
4.2 MAIO:面向模型加载的 I/O 策略
有了 PPC 这个编程框架,接下来就是设计具体的缓存策略 MAIO。
MAIO 的核心洞见是:同一个 LLM 推理服务实例,每次启动时的 I/O 序列是完全一致的。模型、tensor parallelism 配置确定之后,每个 XPU worker 按照固定顺序读取固定的 tensor 文件分片,这是可以预测的。
基于这个观察,MAIO 做了三件事:
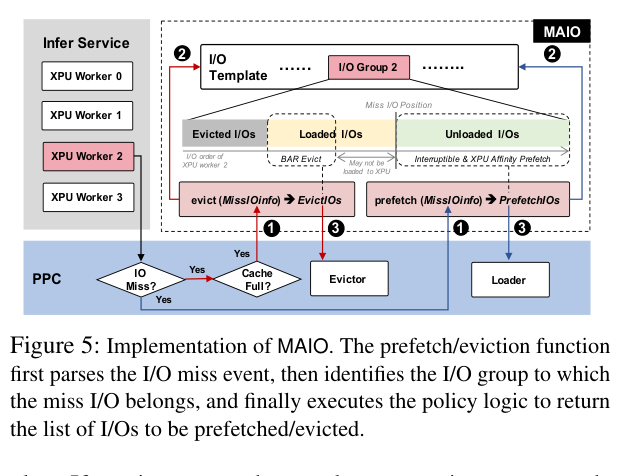
① I/O 模板生成(第一次启动时)
MAIO 通过 PPC 的 miss 事件机制,透明地追踪每个 XPU worker 的 I/O 序列,生成一个 I/O 模板文件。这个模板记录了每个 XPU worker 按时间顺序读取的文件路径、偏移、长度。模板存储极度紧凑——即使是 DeepSeek-R1-671B(662B 参数,双节点 16 NPU),I/O 模板也只有 545KB。
② 基于模板的精确 prefetch + XPU affinity loading
有了 I/O 模板,MAIO 在 framework init 阶段就能提前知道后面 model loading 要读什么、哪个 XPU worker 要用。它实现了可中断的 prefetch:维护一个高并发线程池充分利用 SSD 的并发能力,当内存不足时可以立即中断当前 prefetch,避免资源浪费。
更关键的是 XPU affinity loading:prefetch 的数据会直接放到目标 XPU 所在的 NUMA node 的内存里,减少 host-to-device 传输的跨 NUMA 开销。
③ BAR(Burn-After-Reading)驱逐
这是 MAIO 在内存受限场景的杀手锏。传统 LRU 驱逐策略不知道哪些数据”用完就不会再用”;MAIO 利用 I/O 模板,精确知道哪些数据已经被对应的 XPU worker 消费完了,可以立即将其标记为可回收,为后续 prefetch 腾出空间,彻底避免 cache thrashing。
如下图是 MAIO 的整体执行流程:
5. 实验设置
实验平台:4 个 48 核 Kunpeng 920 CPUs,8 个 Ascend 910B2 NPUs,1TB DRAM,3.75TB SSD。软件栈:vLLM-Ascend 0.9.2,PyTorch 2.5.1,Linux kernel 5.10。推理服务部署为容器,默认跑在 4 个 NPU 上。
测试模型:Qwen2.5-7B/32B/72B,Llama-7B/70B。
对比基线:
- Native:原始内核 page cache 策略,模型存 SSD
- PreCache:直接把整个模型预缓存进内存(高性能但吃内存)
- EagerLoad:第一次 I/O miss 时触发全量 prefetch,无 eviction 优化
- SLLM-NPU:ServerlessLLM 的 NPU 适配版本(不兼容方案代表)
两种内存场景:充足内存(无限制)vs 内存受限(64GB 限制,用 cgroup 控制)
6. 实验结果分析
6.1 模型加载时延
如下图:
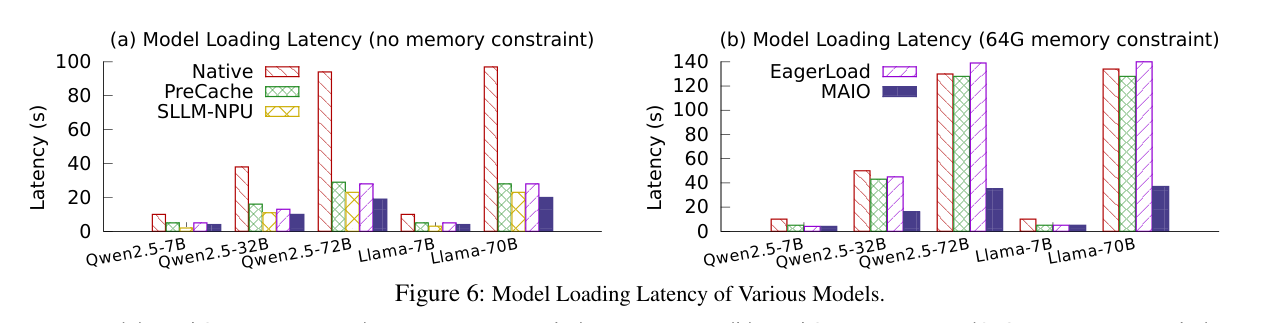
充足内存场景(上图 a):
- MAIO vs Native:最多快 79%
- MAIO vs EagerLoad:最多快 32%(EagerLoad 没有精确 prefetch,不知道 XPU affinity)
- MAIO vs PreCache:最多快 37%(PreCache 没有 XPU affinity 感知)
- MAIO vs SLLM-NPU(不兼容方案):大模型场景还要快 17%!原因是 MAIO 在 framework init 阶段就开始 prefetch,而 SLLM-NPU 只在 model loading 阶段才做,错过了大量可以利用的带宽窗口。
内存受限场景(上图 b):
- MAIO vs 其他所有方案:最多快 74%
- PreCache 和 EagerLoad 在这个场景下几乎没有优势,甚至比 Native 更差——原因是它们的盲目 prefetch 触发了 kernel 原生 eviction,产生严重 cache thrashing。
- MAIO 的 BAR eviction 精确感知了 I/O 位置,evict 已用数据,只 prefetch 接下来要用的,彻底绕开了 cache thrashing。
6.2 推理服务总启动时延
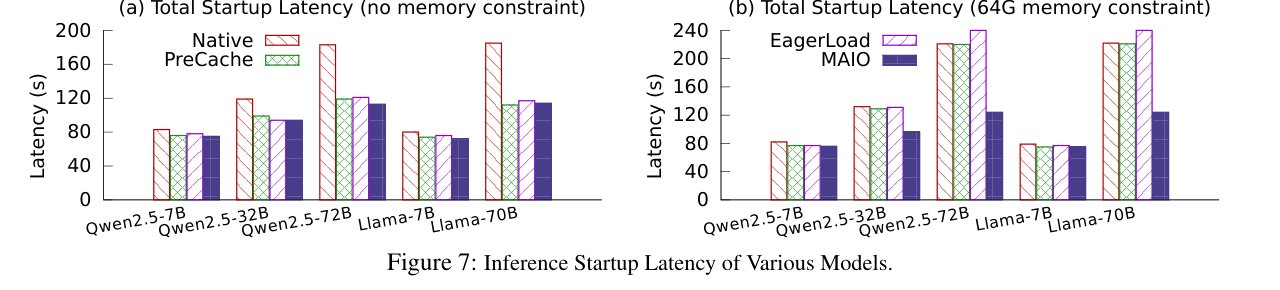
充足内存场景下,MAIO 比 Native 降低最多 38% 的总启动时延;内存受限场景下,比其他所有方案降低最多 51%。
6.3 SSD 带宽利用情况
如下图:
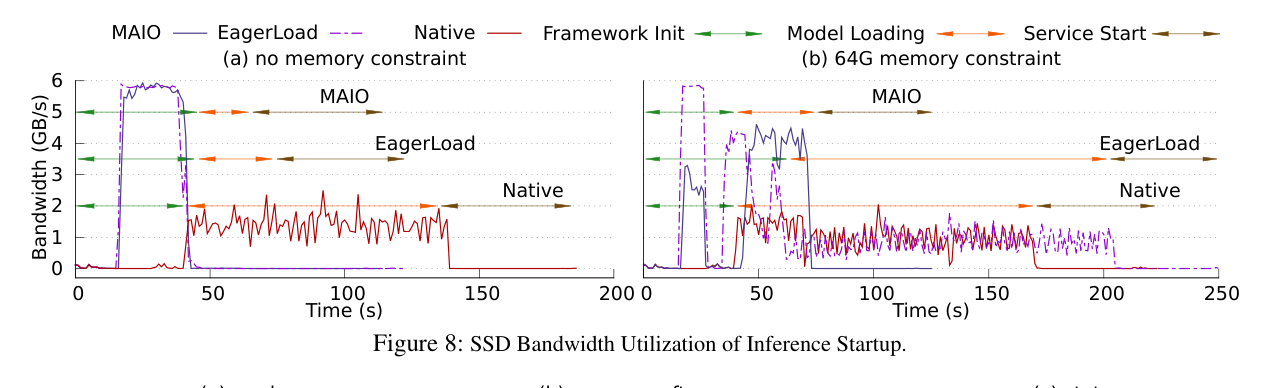
上图直观展示了 MAIO 和其他方案的 SSD 带宽利用曲线:MAIO 在 framework init 阶段就开始高并发 prefetch,几乎打满了 SSD 带宽,到 model loading 阶段大部分数据都已经 cache 命中了。而 Native 只在 model loading 阶段才有 I/O,还跑不满带宽。
6.4 MAIO 各组件消融分析
如下图:
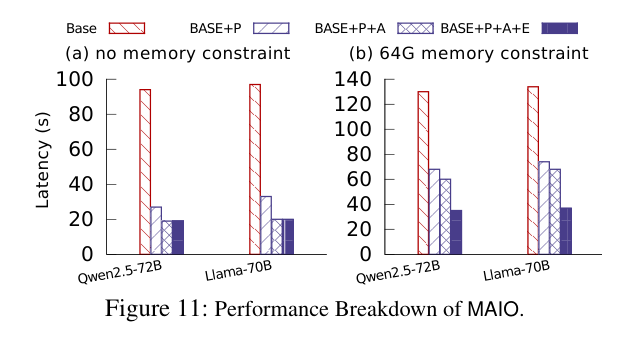
充足内存场景:interruptible prefetch(Base+P)贡献了 65%+ 的降幅,XPU affinity loading(+A)再砍 8.5%,BAR eviction(+E)影响不大(因为内存够用,eviction 不是瓶颈)。
内存受限场景:三个组件各有显著作用,BAR eviction 在这里的贡献达到 19%~23%,是内存受限场景的关键设计。
6.5 弹性部署端到端 throughput
在弹性部署场景(Qwen2.5-72B → Llama-70B → Qwen2.5-72B 循环,不同空闲时间间隔),MAIO 的 token throughput 比 Native 最多提升 36%。这个场景最贴近实际 MaaS 生产环境——模型频繁热换,快速加载直接影响整体算力效率。
6.6 真实业务验证:DeepSeek-R1-671B
华为在自家 Intelligence BooM 平台上部署 DeepSeek-R1-671B(662B 参数,双节点,16 NPUs),验证了 MAIO 的实际效果:
- 原始直接加载:649 秒
- MAIO 优化后:452 秒(降低约 30%)
- 有趣的对比:把模型整个 cache 进 DRAM 的时延是 561 秒,MAIO 比全量内存缓存还快!
原因在于 MAIO 的 XPU affinity loading 加速了 host-to-device 传输,而全量 DRAM 缓存方案缺乏这个优化。
7. 个人 take
这篇论文技术上挺扎实的,几个点值得关注:
选了一个被忽视的优化角度。大家做模型加载优化都在改推理框架、改硬件互联,这篇直接从 OS page cache 层入手,而且不修改内核、不改推理框架,兼容性是真的强。在生产集群里这种约束现实存在,所以这个出发点很有价值。
I/O 模板这个 insight 简洁有力。”同一推理服务的 I/O 序列是确定性可重复的”——这个观察直接打通了精确 prefetch 的可能性,模板生成完全透明,只有第一次启动时有开销,后续使用几乎零代价(DeepSeek-R1-671B 模板才 545KB)。
XPU affinity loading 是个容易被忽视的细节。很多人优化 prefetch 只关注带宽,但数据放在哪个 NUMA node 的内存里影响很大,这个细节被单独提出来并做了消融实验,说明作者是真的在生产环境里踩过坑。
BAR eviction 在内存受限场景是关键。内存受限是现实部署中常见的约束,特别是大模型多实例共存时。传统方法在这里直接翻车(cache thrashing),MAIO 的 BAR 策略实现了”用完即扔”,精准控制内存水位。
当然也有些局限:目前 RFS 是只读的,只支持 model loading 这类读场景;I/O 模板依赖推理服务规格不变,一旦 tensor parallelism 改变就需要重新生成。不过这些在 MaaS 场景里算是可接受的约束。
欢迎评论区交流,有踩过类似坑的可以聊聊~