KV Cache 的两层存储到底卡在哪?FAST'26 这篇论文给出了答案
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

KV Cache 的两层存储到底卡在哪?FAST’26 这篇论文给出了答案
1. 前言
你有没有想过,像 Replika、Duolingo 这类依赖多轮对话的 LLM 应用,在底层到底有多”重”?
用户问一句话,LLM 要回一段话。下一轮用户再问,LLM 不仅要理解新问题,还要”记住”之前说过的所有内容——这个”记住”在工程上的实现,就是把历史轮次产生的 KV tensor 全部加载进 GPU 重新计算。
问题来了:GPU 显存就那么大,每轮对话产生的 KV 不可能一直堆在 GPU 里。所以业界的常规做法是,把历史 KV 缓存在一个两层存储(host memory + SSD)里,下次用到的时候再从存储里 load 进来。
听起来很合理对吧?但现实是——用了两层存储之后,latency 能高出 3.8×,throughput 能跌掉一半。
这篇来自 FAST’26 的工作(清华大学团队)提出了 Bidaw,核心洞察是:现有方案里,compute engine 和两层存储完全互不知情,一个 I/O 盲调度 + 一个不懂对话规律的 eviction,凑在一起把性能搞塌了。
2. 背景:多轮对话的 KV 缓存有多贵?
先交代下背景。
多轮对话的 LLM serving,每一轮的计算都需要用到前面所有轮次的 KV tensor(Key 和 Value 矩阵)。如果这些 KV 不缓存,每次都要重算,开销是指数级上涨的。论文里用真实工业 workload 测了一下:
平均每个用户有 22.4 轮对话,冗余计算占到总计算量的 93.1%!
就是说,绝大多数 GPU 算力都在做无效的重复工作。
为了解决这个问题,有两类方向:
- 分布式内存池(如基于 RDMA 的方案):性能好,但需要专用硬件,成本高,很多垂直领域的公司根本部署不起
- 本地两层存储(host memory + SSD):容量大、成本低,CachedAttention 和 FlashGen 是这条路上的代表工作
下图是两层存储的基本架构——GPU 做计算,KV 从 host memory(快层)或 SSD(慢层)里 load 进来:
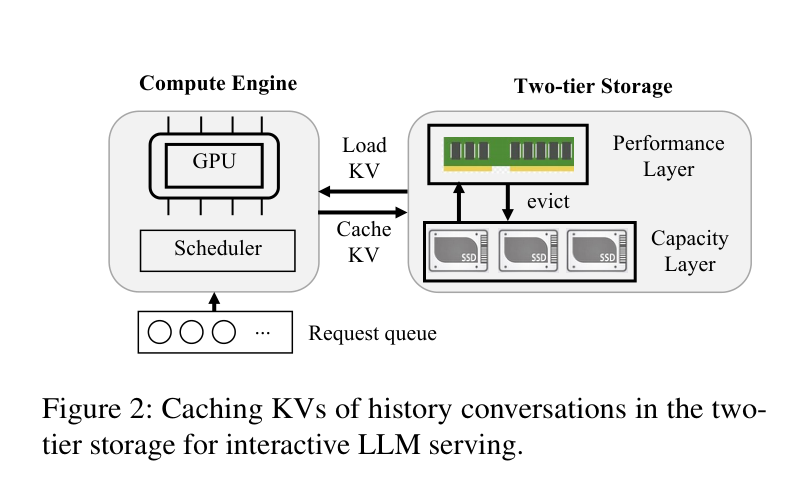
但问题是,这条路上的性能实际上被卡死了。
论文在同一个 workload 上跑了一组对比实验:CachedAttention 和 FlashGen 的 response latency 比”理想情况下所有 KV 都放在 host memory 里”高出 3.8×,throughput 低 2.0×。
这个 gap 不小,足以让人怀疑两层存储这条路是否走得通。
3. 根因分析:compute 和 storage 各自为政
论文花了大量篇幅刻画真实 workload 的特征,找出了两个根本问题,都指向同一个根因:compute engine 和两层存储完全不通信。
3.1 KV 加载时间差异极大
不同请求的历史对话长度差异非常大,加上 host memory 和 SSD 之间带宽差了好几个量级,导致 KV loading time 的变异系数(CV)高于 90%。
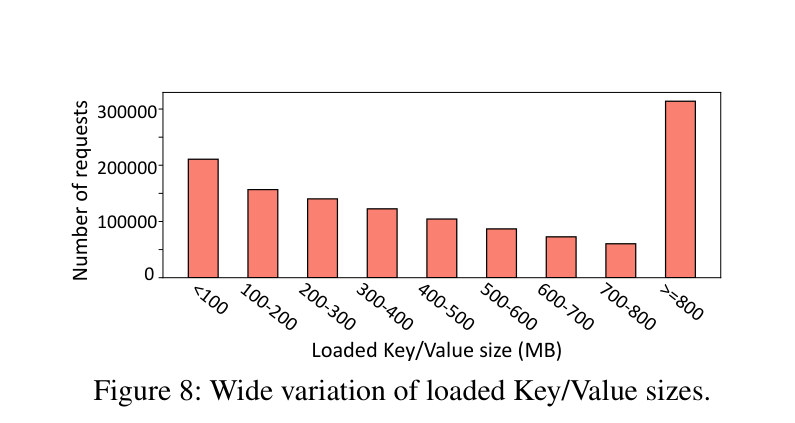
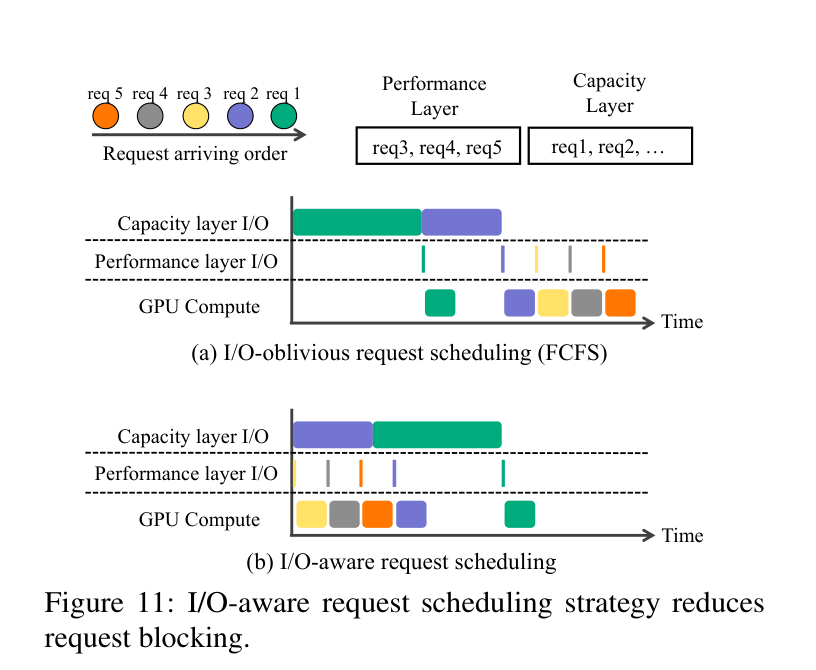
现有的 I/O-oblivious 调度策略(FCFS)完全无视这件事。一个历史很长、KV 在 SSD 里的请求被排到最前面,GPU 就干等着——后面那些 KV 在 host memory 里、几十毫秒就能 load 完的请求,也只能傻等。这就是所谓的请求阻塞(request blocking)问题。
3.2 KV 访问时间局部性极差,命中率惨不忍睹
多轮对话有个特性:用户问完一个问题,得等模型回答,然后再思考下一个问题。这个时间窗口里,服务系统会处理大量其他用户的请求。
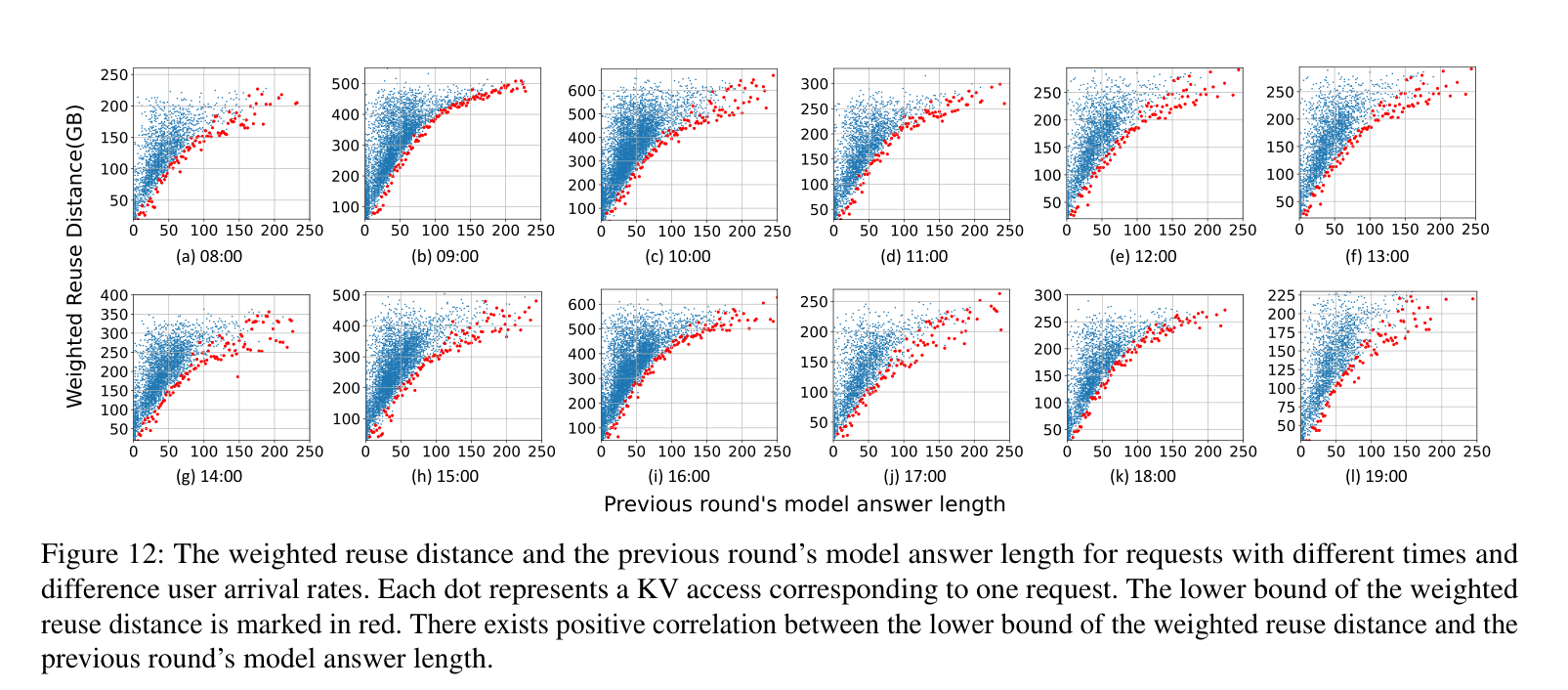
论文引入了”加权重用距离”(weighted reuse distance)——即两次访问同一用户 KV 之间,其他 KV 的总访问量。结果发现:80% 的 KV 访问的加权重用距离超过了 host memory 的容量(200GB)。
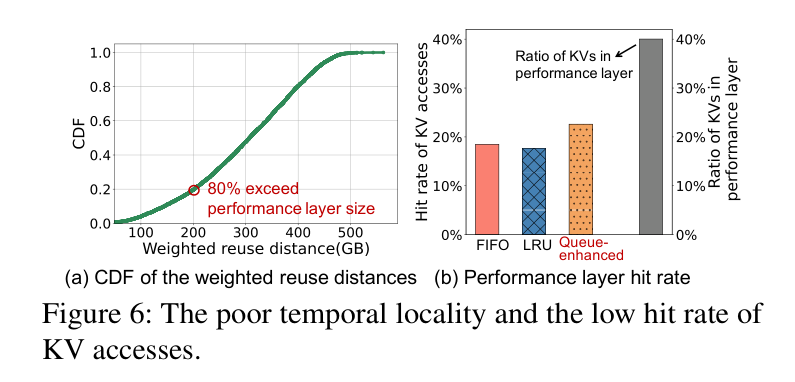
换句话说,两次访问之间已经有太多其他用户的 KV 进来又出去了,传统的 LRU/FIFO 根本没法利用这种局部性。结果就是:即使 host memory 能容纳 40.1% 的 KV,命中率也只有大约 20%,大量请求的 KV 要从慢速 SSD 里 load。
这也是整个行业在两层 KV 存储上面临的核心矛盾:容量层和性能层的带宽鸿沟本来就存在,再加上调度和 eviction 都不考虑对话语义,性能就彻底垮了。
4. Bidaw:双向感知的 KV 缓存
Bidaw 的核心思路很直接:让 compute engine 和 storage 互相知道对方在干什么。
- Compute engine 侧:调度时感知 KV 的 I/O latency,避免 blocking
- Storage 侧:利用模型回答的长度来预测下次 KV 被访问的时间,指导 eviction
下图是 Bidaw 的系统架构:
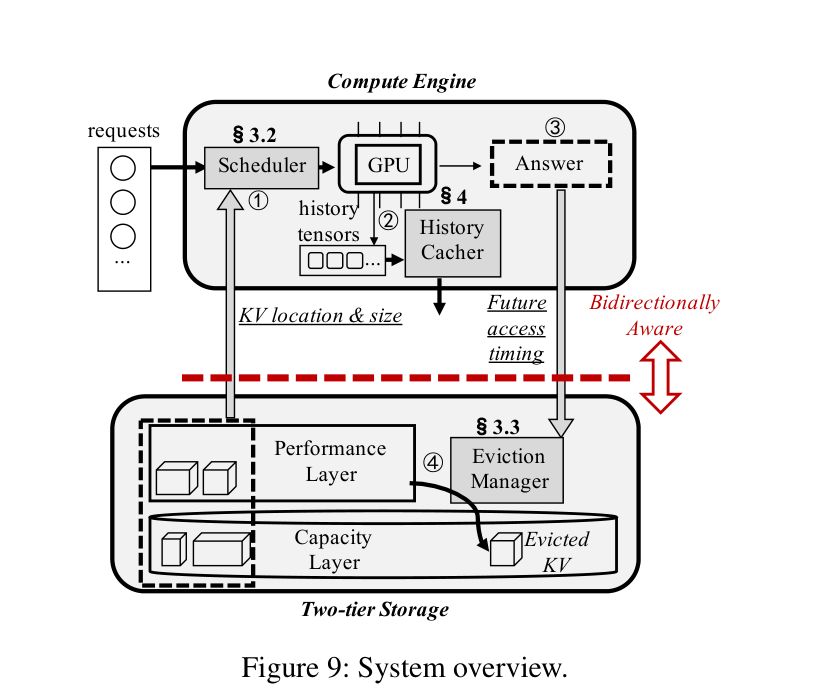
4.1 I/O-aware 请求调度:双队列 + Disk-HRRN
双队列分离
Bidaw 把请求按 KV 所在存储层分成两个队列:
- Ready Queue:KV 在 host memory 里,可以直接调度上 GPU
- Preparing Queue:KV 在 SSD 里,正在 load 中,load 完才会升到 ready queue
GPU 只调度 ready queue 里的请求,preparing queue 里的请求在 SSD I/O 完成后才升队。这样,不会因为一个 SSD I/O 慢的请求挡住一堆快请求。
下图对比了 I/O-oblivious 和 I/O-aware 调度的效果——同样 5 个请求到来,I/O-aware 策略让 req3/4/5(KV 在 host memory)先跑起来,req1/2 在 SSD load 的同时 GPU 不空转:
Disk-HRRN 优先级策略
Preparing queue 里的请求在 SSD 上发 I/O 也有先后顺序。直觉上应该优先 load 小 KV(load 快,早点升到 ready queue),但纯粹按大小来会饿死大 KV 请求。
Bidaw 借鉴了 HRRN 调度算法(Highest Response Ratio Next),设计了一个 disk-HRRN:
\[\text{Response Ratio} = 1 + \frac{\text{Request waiting time}}{\text{KV size}}\]等待时间越长,优先级越高;KV 越小,优先级越高。这样既能快速处理小请求,又不会让大请求一直饿着。
4.2 基于模型回答长度的 KV Eviction 策略
这是论文里我觉得最有意思的一个观察。
观察:回答越长,下次访问越晚
模型回答越长,用户读/听/理解的时间越长,再发下一个请求的间隔就越长。在这段时间里,其他用户的请求会不断进来,加权重用距离自然就越大。
论文在不同时间段、不同压力下跑了 12 组实验,计算了”加权重用距离的下界”与”上一轮回答长度”的 Spearman 相关系数:全部在 0.94 到 0.98 之间,强正相关。
Hit Potential 驱动的 Eviction
有了对加权重用距离的预测,还需要判断:一个 KV 的”下次访问还能命中 host memory 吗?”
论文定义了三种重用距离范围:
- small:重用距离小于 host memory 容量,命中率 1.0
- promising:重用距离超出容量但还在一定范围内,有概率命中
- extreme:距离太远,即使 Belady 最优算法也没法命中,命中率 0.0
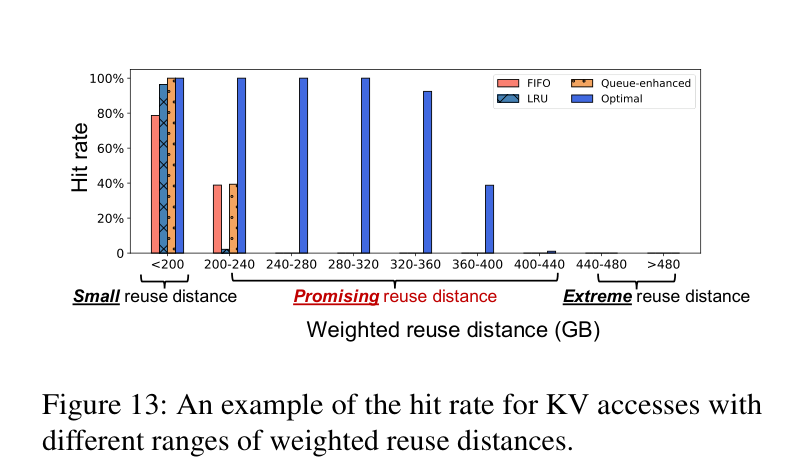
对于 promising 区间,Bidaw 维护了一个后台运行的 ghost cache(用 Belady 最优算法做 eviction),从历史 trace 里统计各个距离 bucket 的命中率。
最终,每个用户 KV 的 hit potential 是这样算的:
\[\text{Overall\_potential} = p_{\text{small}} \times 1.0 + p_{\text{extreme}} \times 0.0 + \sum_{i=1}^{m} p_{\text{promising}(i)} \times \text{hit\_promising}(i)\]hit potential 最低的 KV 优先 evict,而不是按时间顺序或访问频率来。
4.3 存储高效的 Tensor 缓存
还有一个工程优化值得单独说一下。
现有方案(CachedAttention、FlashGen)直接缓存 KV tensor。但 Bidaw 发现,LLM 推理过程中有多种中间 tensor,它们大小不同,转换成 KV 所需的计算量也不同。
如果我们缓存的不是 KV tensor,而是某个更小、转换代价低的中间 tensor,就可以在同样的存储空间里放更多用户的数据,host memory 命中率自然上去了。
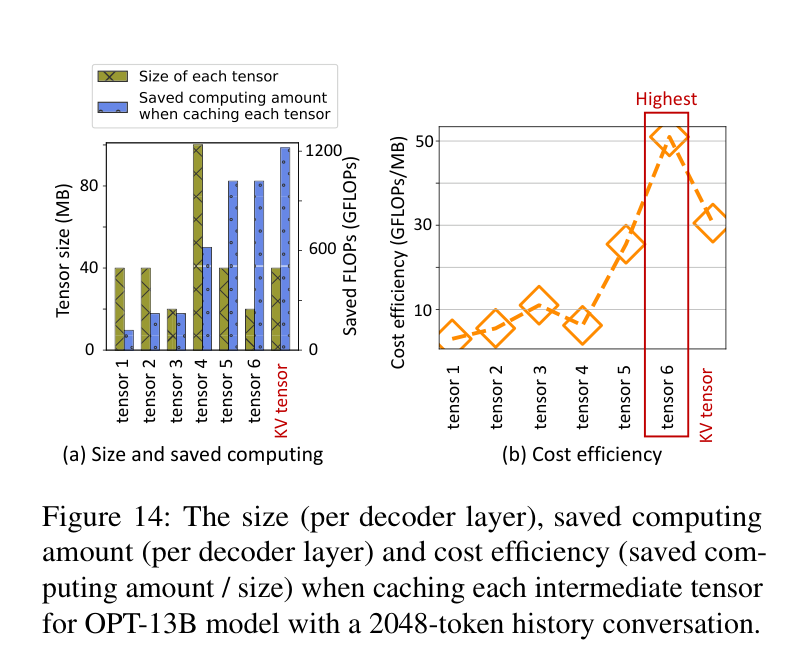
论文定义了 cost efficiency(saved FLOPs / required space),发现 tensor 6(归一化激活值)的 cost efficiency 为 51.0,远高于直接缓存 KV tensor 的 30.5。
实现上,把 storage-efficient tensor 转换成 KV tensor 的操作,分配给一个低优先级 CUDA stream,利用推理时闲置的 GPU SM 来做,对 latency 影响可以忽略不计(实测只有几十毫秒,而整体延迟是几百到几千毫秒量级)。
需要注意:这个优化对 MHA-based LLM(Llama、Qwen、OPT 等)适用;对于 GQA-based LLM,KV 本身已经比较小了,直接缓存 KV 更合适。
5. 实验设置
硬件环境:
- 单卡 A800 80GB GPU,PCIe Gen 4 连接
- 200GB host memory(performance layer)
- 4 块 SATA SSD 组成 RAID-5,带宽约 1.5 GB/s(capacity layer)
测试 workload:
- 自有工业 workload(100 万+ 轮对话,平均 22.4 轮/用户)
- 公开 ShareGPT workload(平均 5.7 轮/用户)
对比 baseline:
- vLLM(re-computation,不缓存 KV)
- CachedAttention(ATC’24,两层存储 + queue-enhanced eviction)
- FlashGen(两层存储 + inclusive caching)
- 理想上界:所有 KV 都在 host memory 里的仿真场景
测试模型:OPT-6.7B、Qwen-7B、OPT-13B、Qwen-14B、OPT-30B
6. 实验结果
6.1 整体性能
下图展示了在各个模型上,随着用户到达率增加,平均响应延迟的变化:
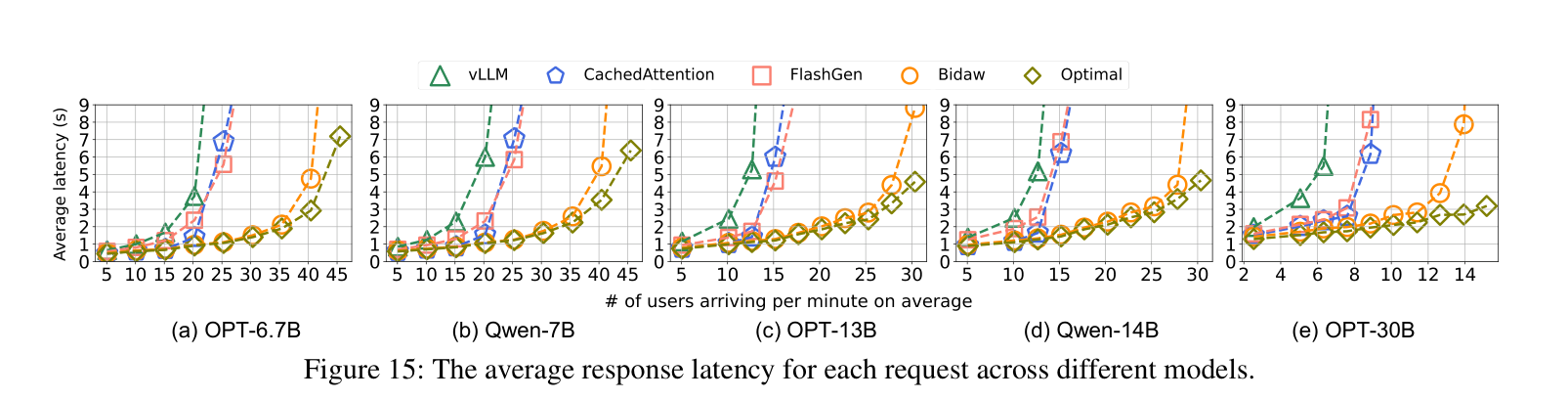
几个关键数字:
- Bidaw 最高能把响应延迟压低 3.58×(OPT-13B,对比 state-of-the-art)
- 对比 CachedAttention 和 FlashGen,延迟平均降低 83.9%
- 吞吐量提升 1.43× 到 1.83×(用每分钟支持的用户数量来衡量)
- 即使把 SSD 带宽提升到 5 GB/s,FlashGen 从 15.18 users/min 提升到 20.23,而 Bidaw 从 27.81 提升到 30.35——差距依然显著
注意:Bidaw 是 lossless 的——只是重新排了请求调度顺序,不影响模型回答的准确性。
6.2 host memory 大小敏感性
在 host memory 从 120GB 到 200GB(对应 GPU 显存的 1.5× 到 2.5×)变化时,Bidaw 依然明显优于 CachedAttention 和 FlashGen——在各种 memory 配置下,Bidaw 支撑的用户到达率是对比方案的 1.75× 到 2.19×。
6.3 公开 workload(ShareGPT)
在 ShareGPT 上,Bidaw 对 FlashGen 的提升约为 1.40× 吞吐量,响应延迟最高压低 56.9%。提升幅度略低于自有 workload,原因是 ShareGPT 缺少真实时间戳(只能用 Poisson 分布仿真),previous-answer-based eviction 的效果有所打折。
6.4 命中率对比
Bidaw 的 eviction 策略把 host memory 的 miss rate 压低了 57.6%(对比 queue-enhanced)和 69.9%(对比 FIFO/LRU/LFU 等通用策略)。
6.5 请求排队时间
I/O-aware scheduler 把请求的平均排队时间从 5.76s 压低到 2.45s,降低了 57.5%。
6.6 系统开销
Bidaw 的 overhead 非常低:
- 调度操作:平均 0.62ms/次
- eviction 操作:0.35ms/次(ghost cache 后台运行:2.86ms/次)
- storage-efficient tensor 转换:几十毫秒,用低优先级 CUDA stream 并行执行
6.7 消融实验
论文把三个组件分别拆开测了一遍(OPT-30B):
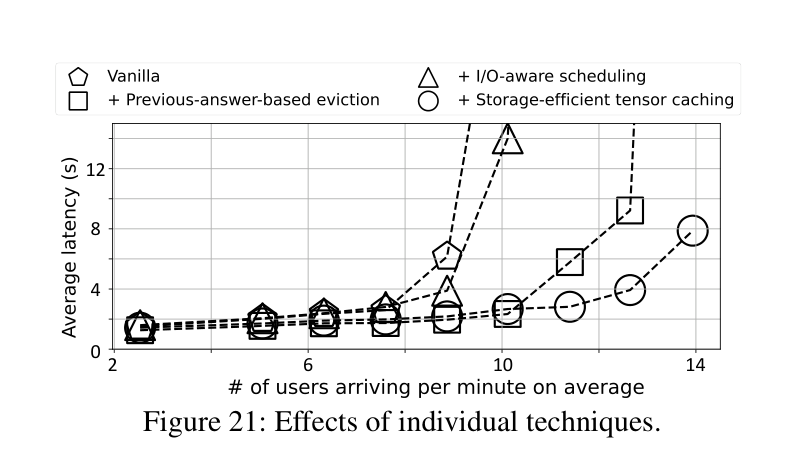
- 只加 I/O-aware 调度:latency 降低 1.58×
- 再加 previous-answer-based eviction:throughput 进一步提升 1.25×
- 再加 storage-efficient tensor caching:throughput 再提升 1.10×
三个技术叠加才是完整的 Bidaw,缺一不可。
7. 个人 take
这篇工作的切入点很务实——不搞新的模型压缩,不搞分布式,就专注于”本地两层存储方案的实际瓶颈在哪”这一个问题,然后给出了系统性的解法。
几个让我印象深刻的点:
第一,”compute 和 storage 互不知情”这个 root cause 分析得很准。很多系统优化工作喜欢把 I/O 优化和 scheduling 优化当成独立问题,但在多轮对话场景下,两者耦合得非常紧——I/O latency 的方差高达 90% CV,任何不感知 I/O 的调度策略都是在赌运气。
第二,用”模型回答长度”来预测下次 KV 访问时间,这个洞察很 elegant。它背后的直觉是:LLM 回答越长 → 用户思考时间越长 → 两次访问间隔越长 → 重用距离越大。Spearman 相关系数 0.94-0.98,这种规律在 12 组不同时段的实验里都成立,说明这不是 overfitting,是 interactive LLM serving 场景的一个基本性质。
第三,storage-efficient tensor caching 这个 trick 挺有意思。不是所有中间 tensor 都一样大,选对缓存的 tensor 可以让同样空间装更多用户的数据。当然这需要 transformer 架构支持(MHA 系列),GQA 的话 KV 本来就小,用处不大。
一个值得讨论的局限:论文的 eviction 策略依赖真实时间戳,在有时间戳的工业 workload 上效果显著,但 ShareGPT 这种时间戳仿真的公开数据集上提升就弱了。这其实说明这个方案对 workload 的假设比较强——用户确实在”交互式”地使用,而不是脚本化批量发请求。
总体来说,这是一篇偏系统的实实在在的工程优化工作,代码开源在 GitHub(interactive-conversation-workload),感兴趣的可以去看看。
欢迎评论区交流!如果你们在自己的 LLM serving 系统里也踩过类似的两层存储坑,欢迎分享一下经验。