DAC'26 | ExpertFlow:让 MoE 大模型在单卡上跑起来,内存省 93%、速度快 10 倍
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

DAC’26 | ExpertFlow:让 MoE 大模型在单卡上跑起来,内存省 93%、速度快 10 倍
1. 前言
作为研究 LLM 推理效率的牛马,我们组最近有一篇工作被 DAC’26(63rd ACM/IEEE Design Automation Conference)接收了,今天想和大家聊聊这篇工作到底解决了什么真问题,以及我们踩过哪些坑。
先交代下背景:MoE(Mixture-of-Experts)模型最近非常火——DeepSeek、Mixtral、Qwen-MoE 这些模型的核心都是 MoE 架构。MoE 的核心思路是”稀疏激活”:一个有 46.7B 参数的 Mixtral-8×7B,每次推理只激活约 12.9B 参数,理论上算力消耗比同体量的 dense 模型少很多。
听起来很美?但我们自己跑的时候,结结实实踩了个大坑:
Mixtral-8×7B 需要超过 96GB 显存才能跑全参数,直接超出了 80GB 的 A100 容量。
这是整个行业 MoE 落地的核心矛盾:参数是稀疏激活的,但内存必须全量加载。如果你只有一张消费级 GPU(24GB、48GB),直接跑 MoE 大模型是不可能的。
一个自然的解决思路是 offloading——把暂时用不到的 expert 放到 CPU 内存里,用时再加载。但现有方法要么预测不准,要么加载策略太笨,throughput 损耗严重。
我们做的 ExpertFlow 就是为了解决这个问题。
2. MoE 推理的三个核心瓶颈
要理解我们为什么要设计这三个组件,先得搞清楚 offloading 推理里到底被什么卡死了。
2.1 Expert 预测不准
做 offloading 的关键是:提前知道下一步要用哪些 expert,提前把它们加载到 GPU。
现有方法分两类:
- 回归类(如 Pregated-MoE):训练一个 MLP 来预测 router 的打分,但分数稍有偏差就影响输出质量,而且需要大量 fine-tuning。
- 启发式类(如 LRU、时间局部性):轻量但完全忽略了 input-dependent 的路由行为,预测精度差。
更关键的问题是:现有方法都是逐层预测,当上一层执行完才知道下一层要用哪些 expert——留给调度和预取的窗口极短。
2.2 Expert 利用率低
在 decode 阶段,一个典型的糟糕情况是:每个 batch 里的 token 激活了不同的 expert,导致每个 batch 几乎要加载所有 expert,而每个 expert 只处理一个 token。
这意味着每处理一个 token 就要做一次 CPU→GPU 的传输,IO overhead 极大,实际吞吐量惨不忍睹。
2.3 Expert 缓存策略差
最常用的 LRU 策略只看”最近用没用”,完全不考虑路由模式,在 MoE 动态路由下 cache hit rate 极不稳定。SE-MoE 的 ring buffer 设计会把两层的全部 expert 都缓存进来,显存浪费严重。
3. ExpertFlow 的设计思路
我们提出了 ExpertFlow,核心是三个协同工作的组件:RPP + TS + ECE。
如下图,用两个 batch 的例子展示整个流程:

① RPP(Routing Path Predictor)在 MoE 计算开始前,一次性预测出所有层的 expert 激活情况; ② TS(Token Scheduler)根据预测结果,把路由路径相似的 token 重新分组; ③ ECE(Expert Cache Engine)只加载需要的 expert,并实时纠正预测错误。
下面逐一细讲。
4. Routing Path Predictor(RPP):一次性看穿所有层
4.1 核心设计
现有 predictor 的问题在于逐层预测——必须等第 l 层执行完,才能开始预测第 l+1 层的 expert,调度窗口极短。
我们把 RPP 设计成 T5 风格的 encoder-decoder 架构:
- Encoder 对整个输入序列做 embedding;
- Decoder 一次性输出所有 MoE 层的 expert 激活预测(shape: B×S×L×E);
- 每一层挂一个轻量 classification head,直接输出该层各 expert 的激活概率。
如下图:
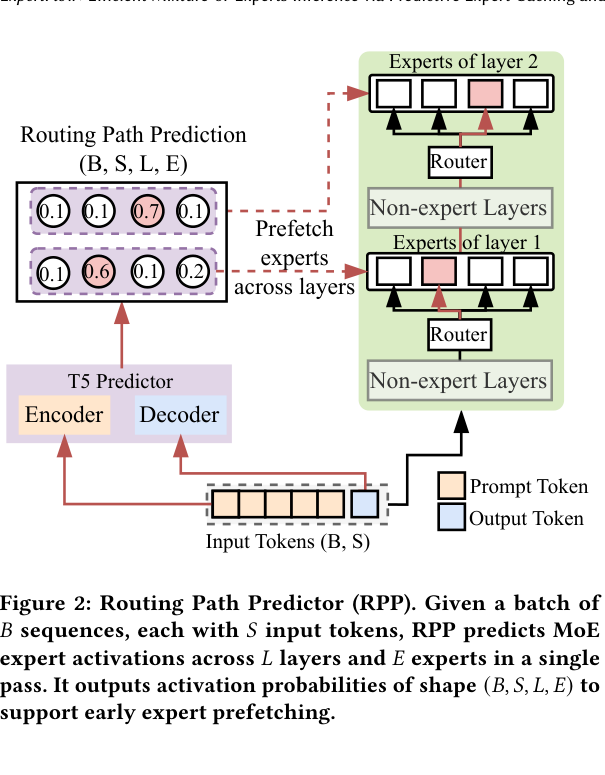
整个预测在第一个 MoE 层执行之前就完成,给调度和预取留出充足的时间。
4.2 训练方式
训练非常简单:把每个 token 的 expert 选择记录为二值矩阵 r ∈ {0,1}^(L×E),predictor 输出概率矩阵 p,用 binary cross-entropy 训练即可。最终的 RPP 模型只有 7.21 MB,极其轻量。
4.3 效果
在 Qwen1.5 上,in-domain 精度超过 95%;即使跨域(在 Alpaca 上训练,在 XSUM/WMT16 上预测),精度仍维持在 80-90%,而 TLP、SLP 等启发式方法在很多情况下不到 20%。
5. Token Scheduler(TS):让 token 不再”各奔东西”
5.1 问题直觉
想象 decode 阶段,Batch1 的 4 个 token 各自激活了不同的 expert,Batch2 也一样——结果每个 batch 都要加载全部 expert,每个 expert 只处理 1 个 token:
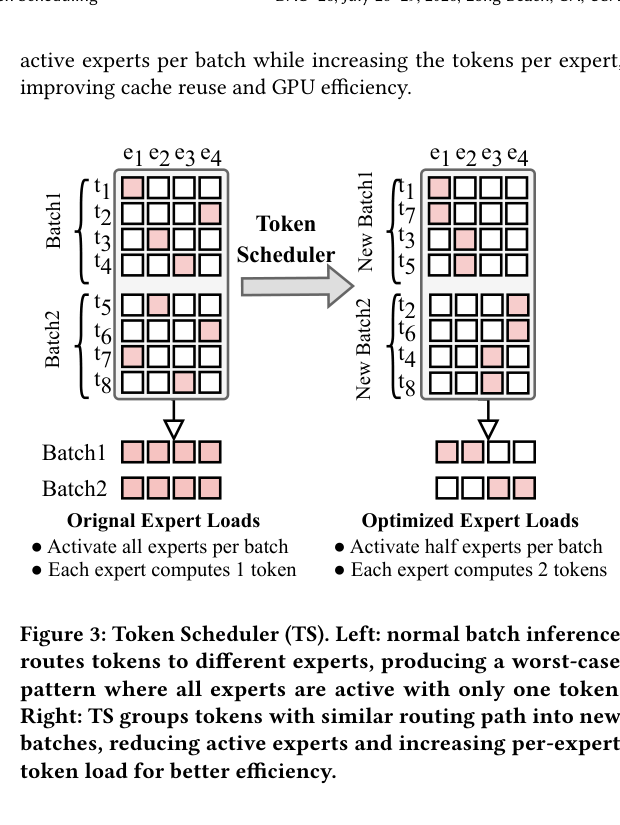
TS 的思路:把两个连续 batch 的 token 合并,然后根据路由路径相似度重新分组。路由相似的 token 归同一个 batch,这样每个 batch 激活的 expert 数量减半,每个 expert 处理的 token 数量翻倍,cache reuse 和 GPU 利用率大幅提升。
5.2 实现:K-Means 近似
精确求解最优分组是 NP 难的,我们用 K-Means 风格的近似:基于 Hamming 距离构造相似度矩阵,把 2T 个 token 聚成 2 组,CPU overhead < 10ms。
5.3 KV Cache 的一致性问题
重排 token 会打乱 attention 的 KV cache 顺序。TS 加入了 Merge 和 Reindex 两个原语,保证 attention 语义的正确性。
5.4 Dual-Batch 流水线
RPP 和 TS 的计算本身有 overhead。我们设计了双 batch 流水线:当前 batch 做 prefill/decode 时,RPP 和 TS 已经在异步处理下一个 batch,完全隐藏 overhead。

6. Expert Cache Engine(ECE):预测性缓存 + 实时纠错
6.1 PLEC:预测驱动的 cache 分配
传统 LRU 对所有层平均分配 cache slots,完全不考虑实际需求。
PLEC(Predictive Locality-aware Expert Caching)根据 RPP 的预测结果,按需分配 cache slots:预测某层需要 3 个 expert、另一层需要 2 个 expert,就按 3:2 的比例分配,并提前把最可能用到的 expert prefetch 进 GPU。
如下图展示了 ECE 的完整工作流:
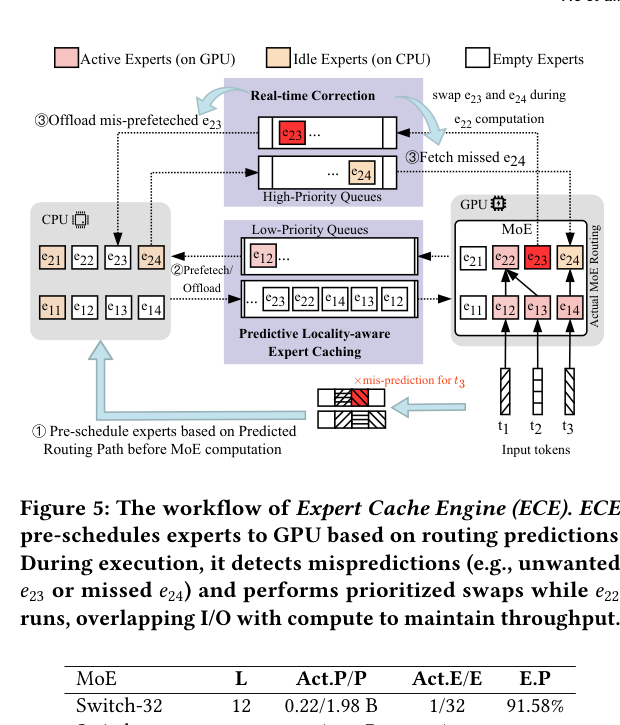
早层 expert 计算完成释放 slots 后,这些 slots 会立即被复用来加载后续层的 expert,I/O 和计算完全重叠。
6.2 Real-time Correction:预测错了怎么办?
预测不是 100% 准确的。ECE 在计算过程中实时检测 misprediction:
- 如果某个预测的 expert 实际没用到(unwanted),把它放到低优先级队列;
- 如果某个 expert 没被预测到但实际用到了(missed),立刻以高优先级加载。
整个纠错过程和正在运行的 expert 计算并行,最大化 throughput。
7. 实验结果
实验平台:单张 NVIDIA A40 GPU(48GB)+ Intel Xeon Gold CPU。 测试模型:Switch-32/64/128、Mixtral-8×7B、Qwen1.5-MoE、Deepseek-MoE。 测试任务:Alpaca(对话)、WMT16(翻译)、XSUM(摘要)、AIME2024(数学)。
7.1 吞吐量提升
如下图,我们在多个模型和数据集上对比了三个基线(Cache-MoE、SE-MoE、Pregated-MoE):
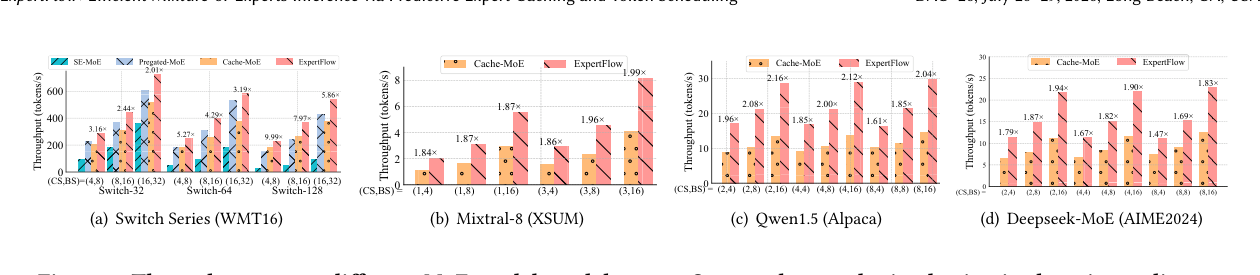
关键数字:
- Switch 系列(WMT16):随着 expert 数量增多,优势越来越大。Switch-128 在 CS=16/BS=32 时比 SE-MoE 快 5.86×;收紧 cache(CS=4)时加速比进一步提升到 9.99×。
- Mixtral-8×7B:比 Cache-MoE 快 1.99×
- Qwen1.5-MoE:比 Cache-MoE 快 2.12×
- Deepseek-MoE:比 Cache-MoE 快 1.94×
跨域测试(RPP 在 Alpaca 上训练,在 XSUM/WMT16 上测试):
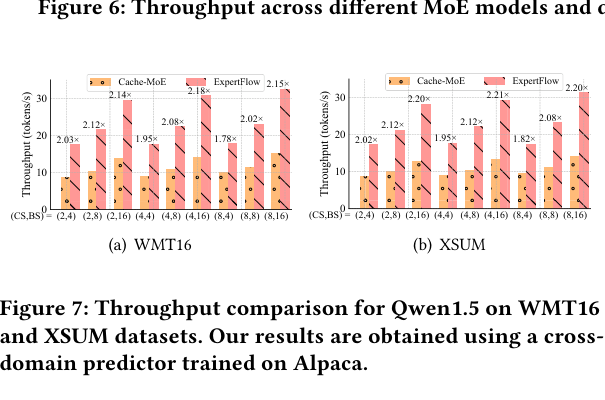
即使用 cross-domain predictor,在 CS=4/BS=16 时仍有 2.18×(WMT16)和 2.21×(XSUM)的加速,说明 RPP 学到的 expert 激活模式确实能泛化。
7.2 显存节省
对比 All-In-GPU(AIG)基线(所有参数常驻 GPU):
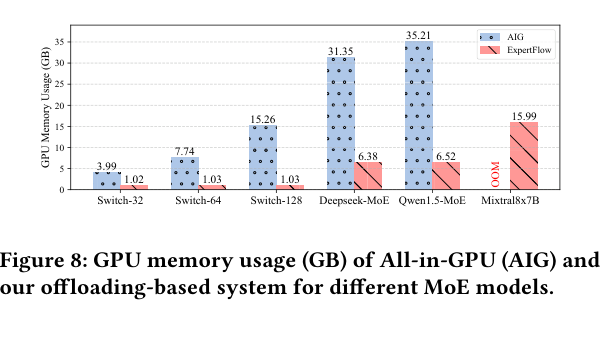
- Switch-128:15.26 GB → 1.03 GB(节省 93.25%)
- Deepseek-MoE:31.35 GB → 6.38 GB
- Qwen1.5-MoE:35.21 GB → 6.52 GB
- Mixtral-8×7B:AIG 直接 OOM,ExpertFlow 仅用 15.99 GB 顺利完成推理
7.3 RPP 预测精度
如下图,在 6 种 MoE 模型上的 layer-wise 预测精度:
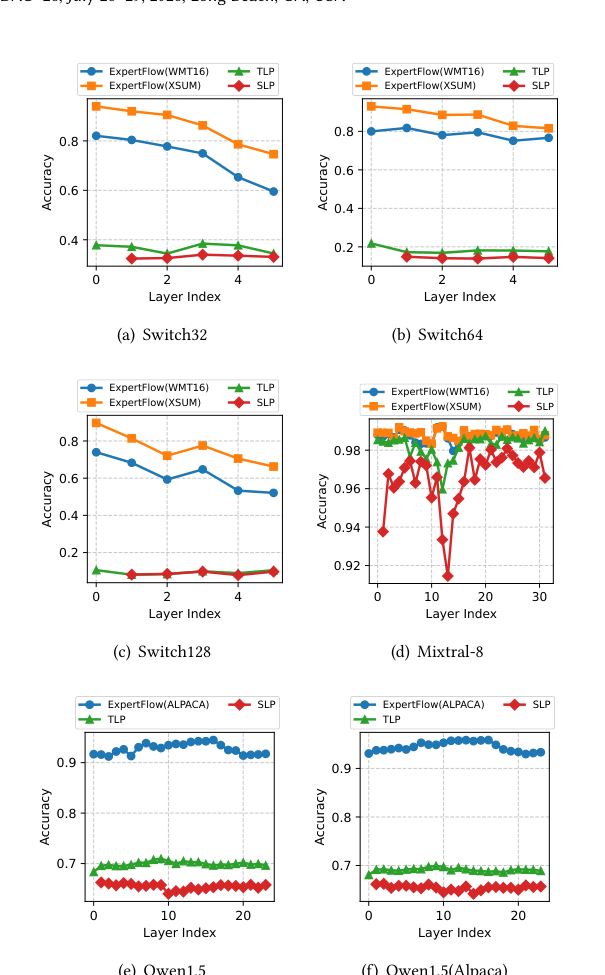
- 大多数 in-domain 场景超过 90% 精度
- Cross-domain 只下降 5-10%
- 而 TLP、SLP 两个启发式 baseline 在大多数情况下精度不超过 20-30%
7.4 Cache Hit Rate vs 消融
如下图,PLEC 在不同 batch size 和 cache size 下都稳定优于 LRU:
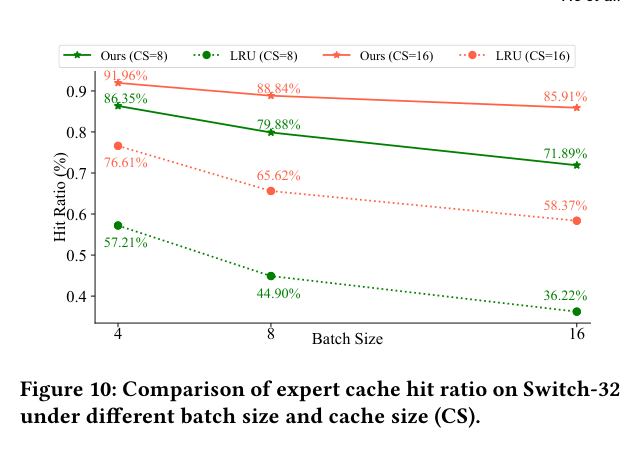
CS=16 时,PLEC 在 BS 从 4 增大到 16 的过程中命中率仅从 91.90% 下降到 85.91%(下降 6.05%);而 LRU 从 76.61% 暴跌到 58.37%(下降 18.24%)。
Token Scheduler 的效果随 expert 数量增大而提升:Switch-32 有 1.03× 提升,Switch-64 有 1.15×,Switch-128 有 1.17×。
8. 总结和思考
ExpertFlow 整体就是把”预测”这件事做到极致,然后让整个系统围绕预测结果协同工作:
- RPP 提供全局、提前的路由预测(不是逐层、事后的)
- TS 利用预测来消除 token 分散导致的 expert 碎片化
- ECE 利用预测做 cache 分配和 prefetch,再用实时纠错兜底
三者缺一不可,拿掉任何一个效果都会大幅下降(论文里有消融实验验证)。
这个工作让我最有感触的一点: MoE 的”稀疏激活”优势在训练时体现得很好,但推理系统如果不做专门设计,这个优势会被内存管理开销完全抵消。系统层面的设计和算法层面的分析同样重要,这也是为什么 DAC 这种 design automation 的顶会非常适合这类工作。
代码已开源,有兴趣的同学可以 star 一下:https://github.com/marsggbo/ExpertFlow
欢迎在评论区讨论,或者在知乎私信我,有什么问题一起聊聊。