KV Cache 复用的第三条路:FAST 2026 CacheSlide 是怎么解决 Agent 推理的位置漂移问题的
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

KV Cache 复用的第三条路:FAST 2026 CacheSlide 是怎么解决 Agent 推理的位置漂移问题的
原文:CacheSlide: Unlocking Cross Position-Aware KV Cache Reuse for Accelerating LLM Serving
1. 前言:两种方案都不够用
作为一个天天和 LLM 推理打交道的牛马,我对 KV Cache 这个话题有复杂感情——它是 LLM serving 里最核心的优化点,但研究来研究去,工程上每次都会冒出新的问题。
今天想聊一篇 USENIX FAST 2026 的工作:CacheSlide,来自上海交通大学和华为云的联合工作,专门解决 Agent 场景下 KV Cache 复用的一个根本性矛盾。
先交代背景。现有的 KV Cache 复用策略被划分成两类:
-
PDC(Position-Dependent Caching):代表是 vLLM 的 prefix caching、ContextCache。要求共享内容必须在固定绝对位置(通常是 prompt 开头)。一旦前面插入了动态内容,位置变了,缓存就失效了。
-
PIC(Position-Independent Caching):代表是 CacheBlend、EPIC。不限制位置,但引入了一个叫 PMKD(Positionally Misaligned KV Drift)的问题——缓存的 KV 和实际推理时的 KV 因为位置编码不同产生漂移,导致精度下降。
Agent 场景偏偏是两种方案的共同盲区。
这就是这篇论文出发的地方。
2. Agent 场景到底是什么样的结构?
在 Agent 系统里,prompt 通常是”固定+动态”的混合结构:有些段(系统 prompt、历史记忆、工具描述)是不变的,有些段(当前轮输入、新的工具调用结果)每轮都在变。
如下图,给了两个典型例子:
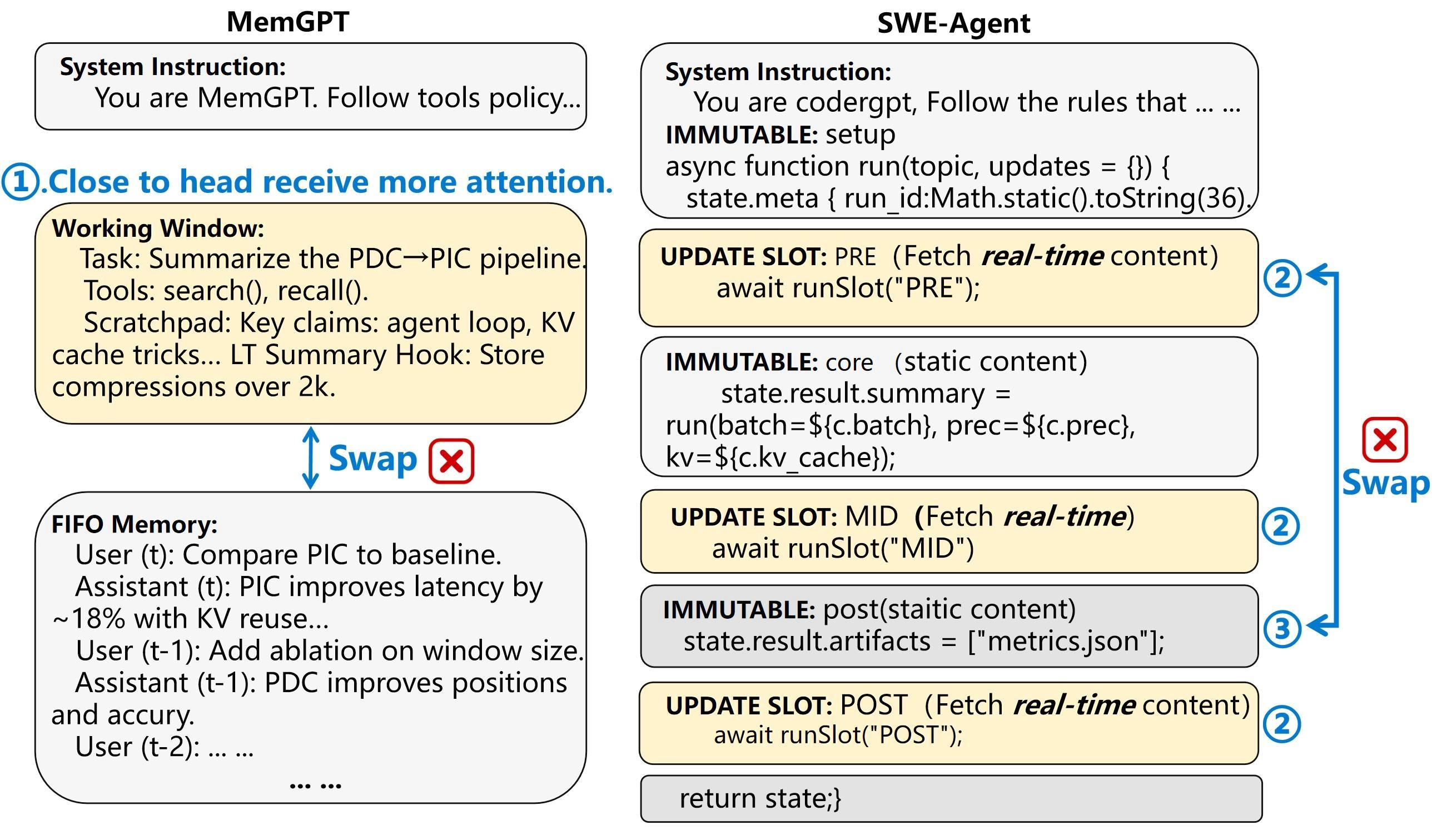
- MemGPT:系统 prefix + Working Window(FIFO 工作窗口,每轮滚动更新)+ 历史 suffix。固定段和动态段交错排列。
- SWE-Agent:系统指令 + 多个 Updated Slot(代码调试时每轮注入新的运行结果)+ 各个不可变段。
这些设计不是随意的——MemGPT 把近期记忆放在 prompt 头部是因为 attention 机制对头部更敏感,调换顺序会降低推理质量;SWE-Agent 的 Updated Slot 和 Immutable 段之间有数据依赖,不能随意挪位置。
也就是说,你没法通过重排段的顺序来满足 PDC 的前缀要求,又没法用 PIC 来无损复用(位置漂移太大)。
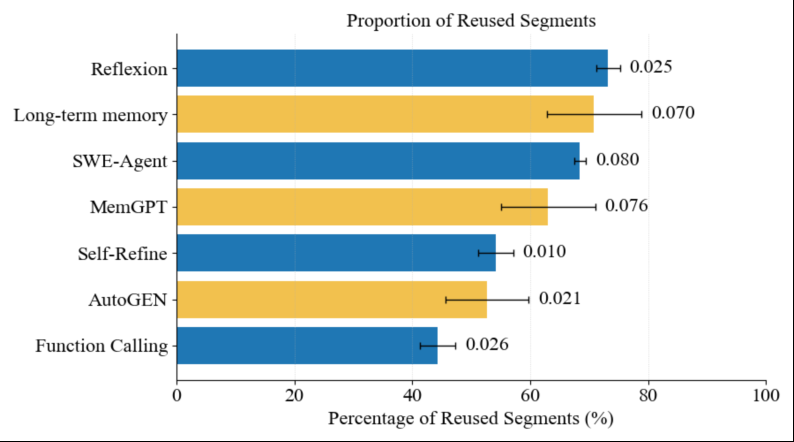
实际测量下来,MemGPT、SWE-Agent 等 Agent 系统中可复用的 KV Cache 占 prompt 总长度的比例非常高——但这些可复用段几乎全部被现有方案浪费掉了:
3. 问题根源:PMKD 有多严重?
论文用 CKSim(cosine similarity between cached and recomputed KVs)来量化 KV 漂移。结论是:
用 RoPE 的系统,位置偏移 0-1000 token 时,CKSim 下降超过 90%。
也就是说,cached KV 和从头算出来的 KV 几乎完全不同了,直接复用 = 直接污染推理质量。
而换成 CoPE(一种对位置变化敏感度低的位置编码),同样的偏移下 CKSim 只下降 28%:
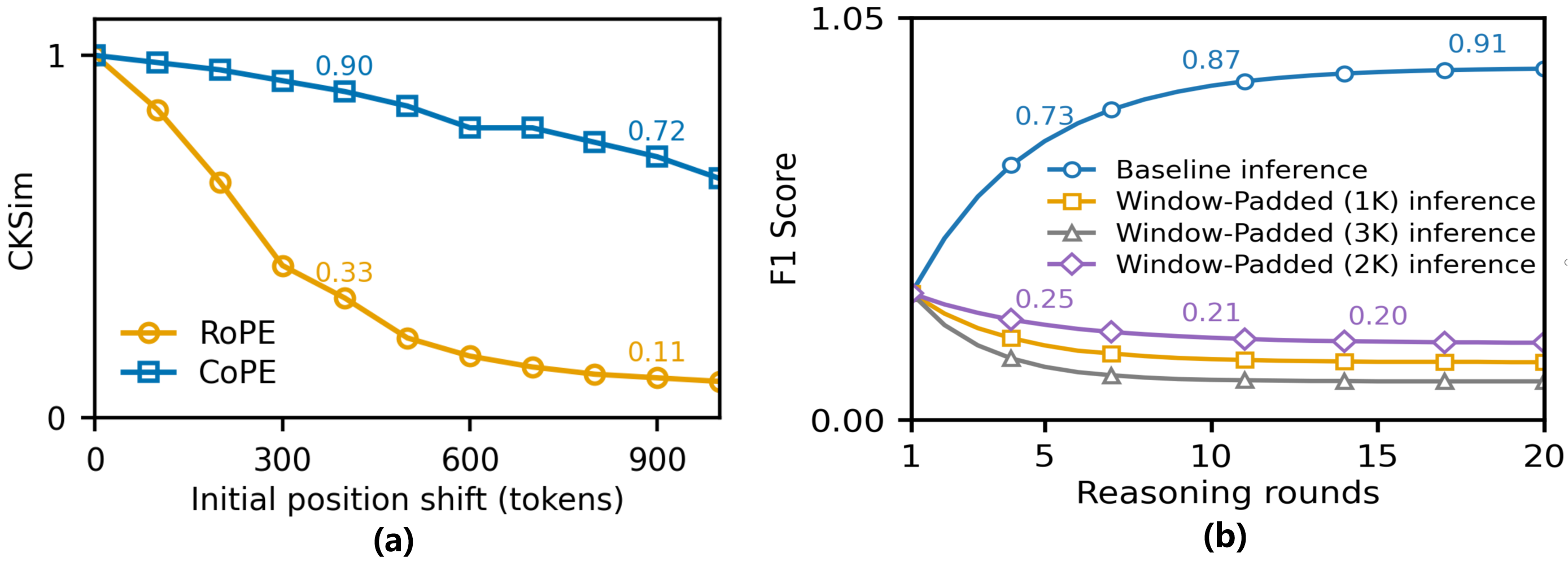
背后的原因:RoPE 给每个 token 分配一个绝对位置旋转角,位置变了旋转就变了;CoPE 是按语义边界索引、而非单个 token,相邻 token 可以共享索引,绝对偏移对它的影响更平滑:
这就给了 CacheSlide 的核心设计方向:把 RoPE 换成 CoPE,再把 prompt 按固定段/动态段切块,对固定段分配稳定的位置编码范围。
4. RPDC 范式:第三条路
论文提出了一个新概念 RPDC(Relative-Position-Dependent Caching):
reusable segments maintain consistent relative ordering despite absolute position shifts.
说人话:固定段的相对顺序不变,但绝对位置会因为动态段长度变化而漂移。这是 Agent 场景的本质结构——既不是 PDC(绝对位置固定),也不是 PIC(完全位置无关),而是”相对位置固定”这个中间状态。
如下图,直观对比了三种范式:
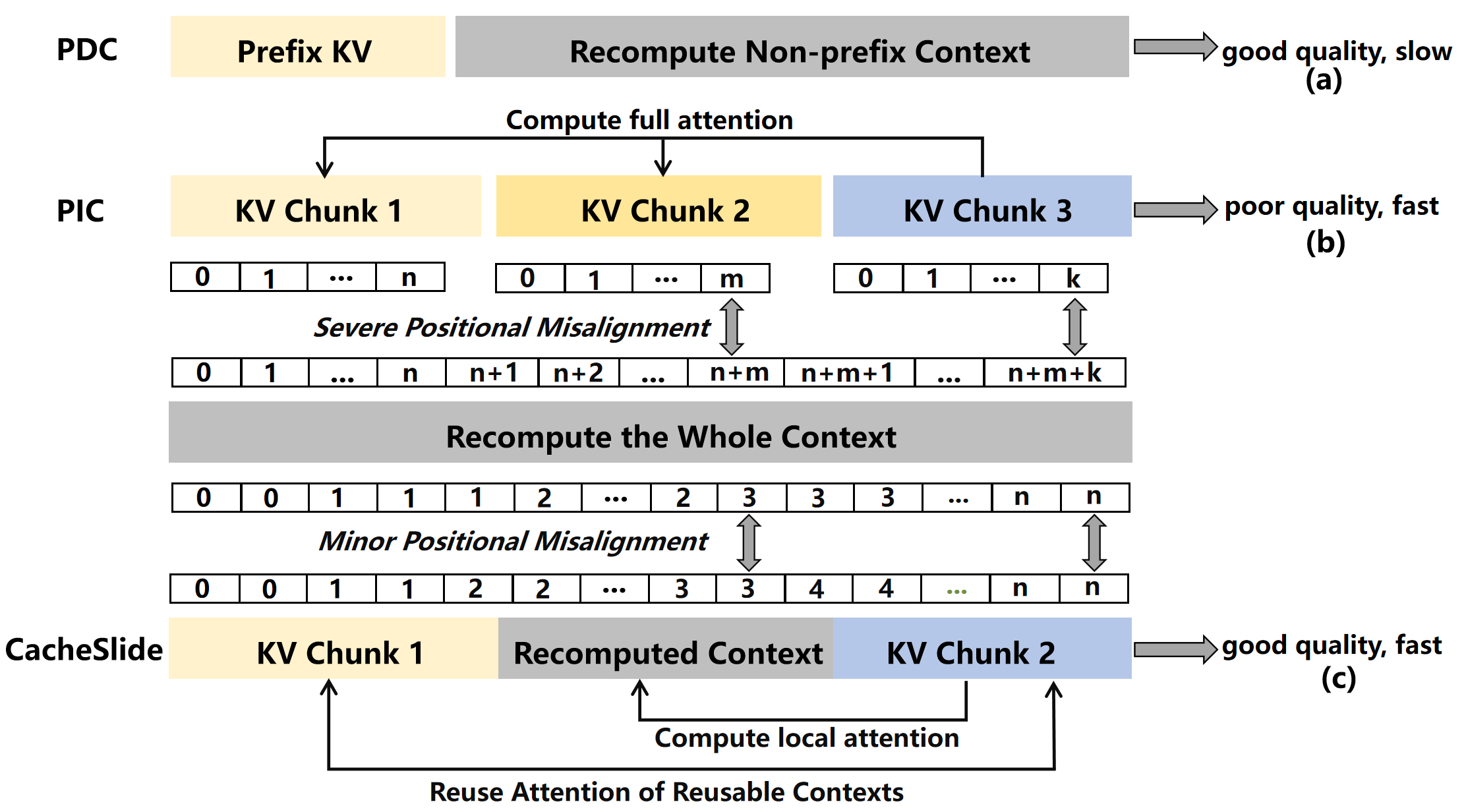
RPDC 保留了段间的相对顺序,所以固定段内部的 attention 和固定段之间的 cross-attention 都可以近乎无损地复用。唯一需要修正的是固定段和动态段之间的 cross-attention——这是 update 之后新产生的依赖,必须重算,但重算的 token 数量可以很少。
5. CacheSlide 的三板斧
CacheSlide 的整体流程如下:
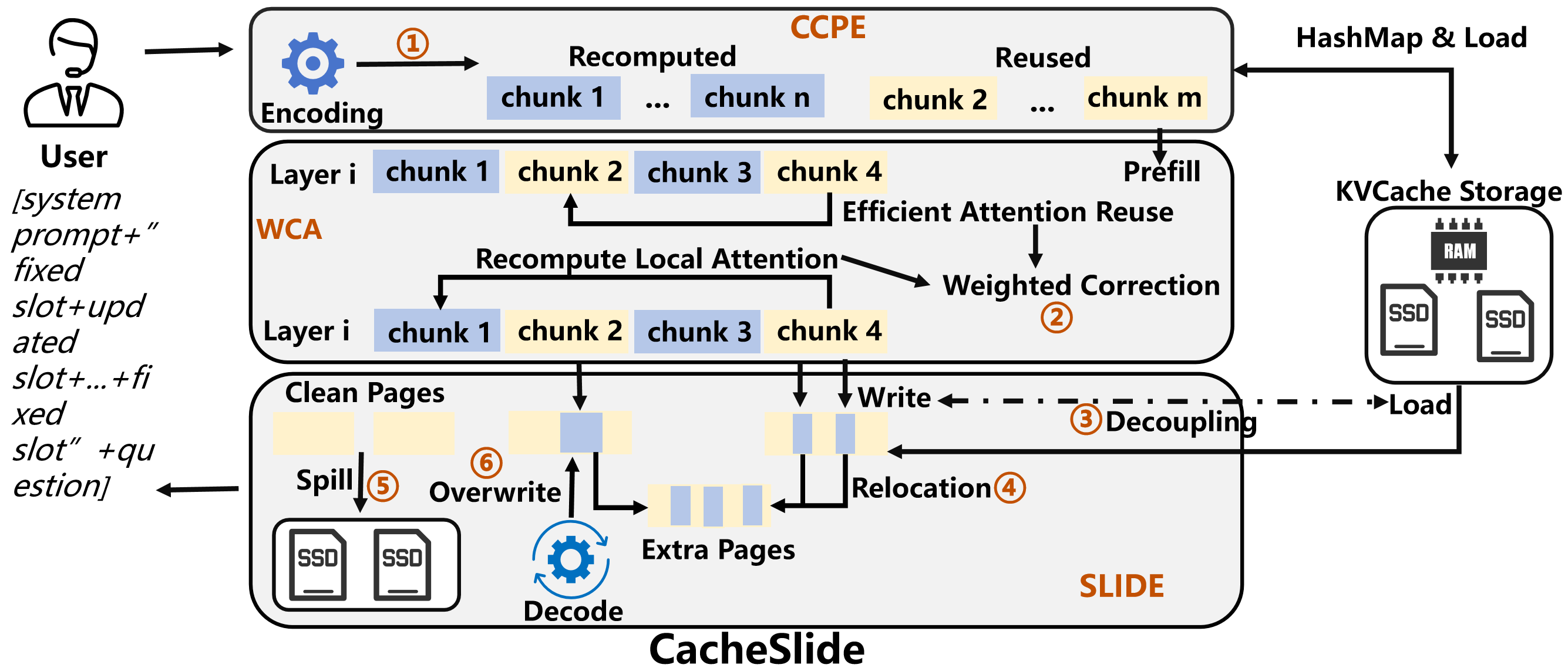
三个核心组件:CCPE + Weighted Correction Attention + SLIDE。
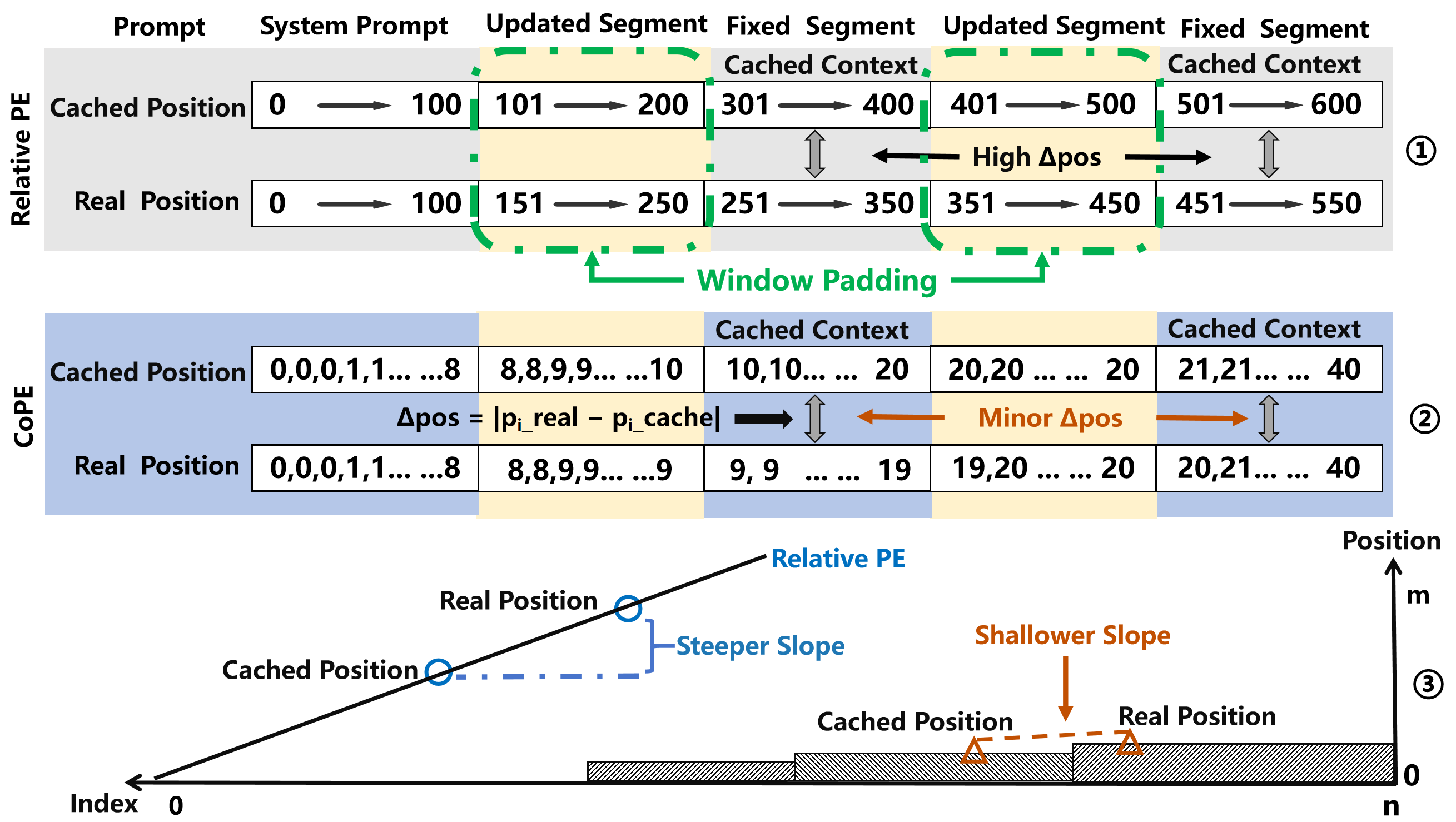
5.1 CCPE:Chunked Contextual Position Encoding
CCPE 做的事情是:把 prompt 按模板切成若干 chunk,标注哪些是”reuse chunk”(固定段),哪些是”recompute chunk”(动态段);然后对 reuse chunk 分配稳定的位置编码范围,让每次推理时 cache 的位置和实际推理的位置尽量接近。
具体实现上,先在同类任务上做一轮 CoPE-based 预训练,识别 reuse chunk 的最高频编码模式 e*,然后在实际推理时把这个 e* 固定分配给对应 chunk。
如下图:
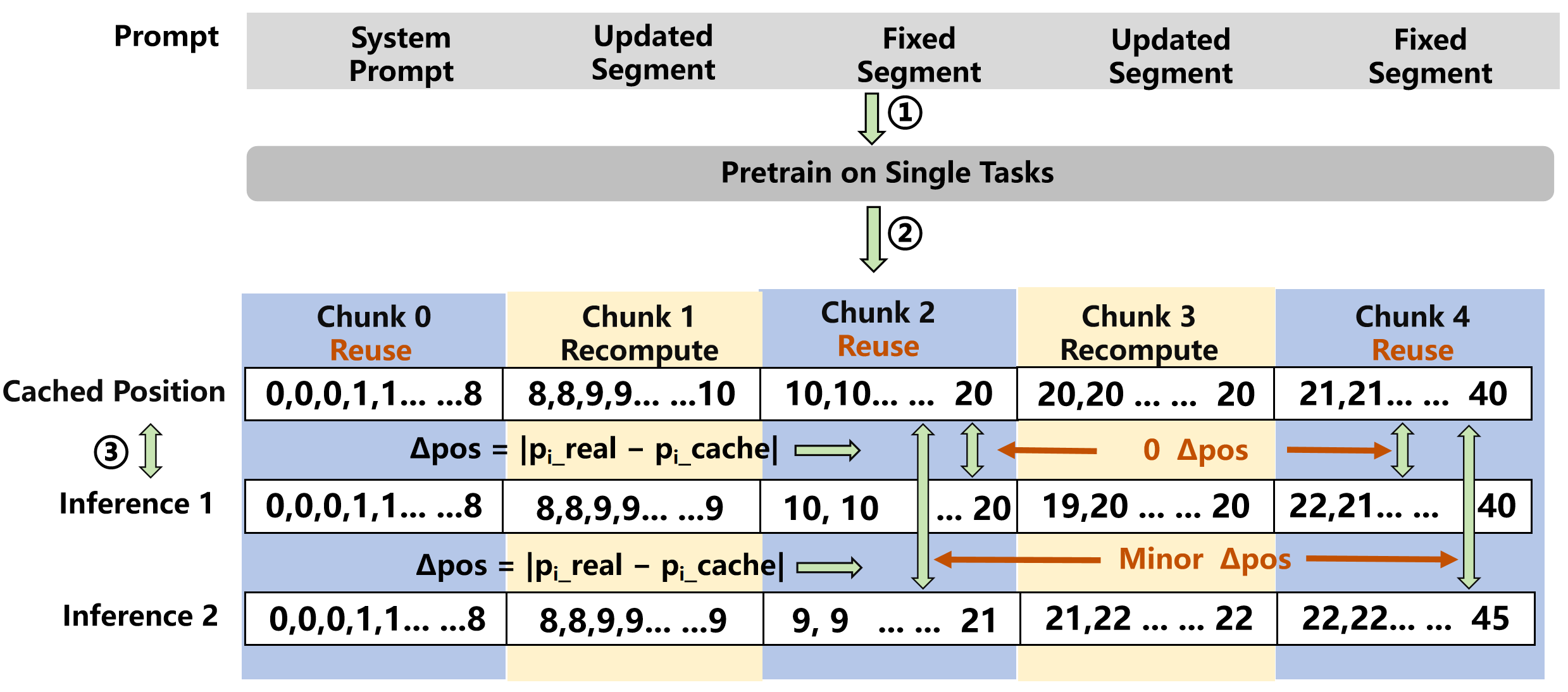
结果是:cached positional indices(比如 10-20)和实际推理时的索引(9-21 或 10-20)几乎没有偏差,∆pos 极小,CKSim 保持在高位。
本质上还是换掉 RoPE 加上静态范围分配,但因为先做了预训练对每类任务学了最优编码,比暴力用 CoPE 效果要好很多。
5.2 Weighted Correction Attention:只修正真正漂移的 token
即使 CCPE 大幅降低了漂移,固定段和动态段之间的 cross-attention 仍然需要修正——毕竟新的输入 token 进来了,固定段里有些 token 的 KV 受到了影响。
全部重算的话开销太大;完全不管的话精度不够。Weighted Correction Attention 的思路是:只找出漂移最大的 top-k 个 token,精准修正这些 token 的 KV。
如下图:
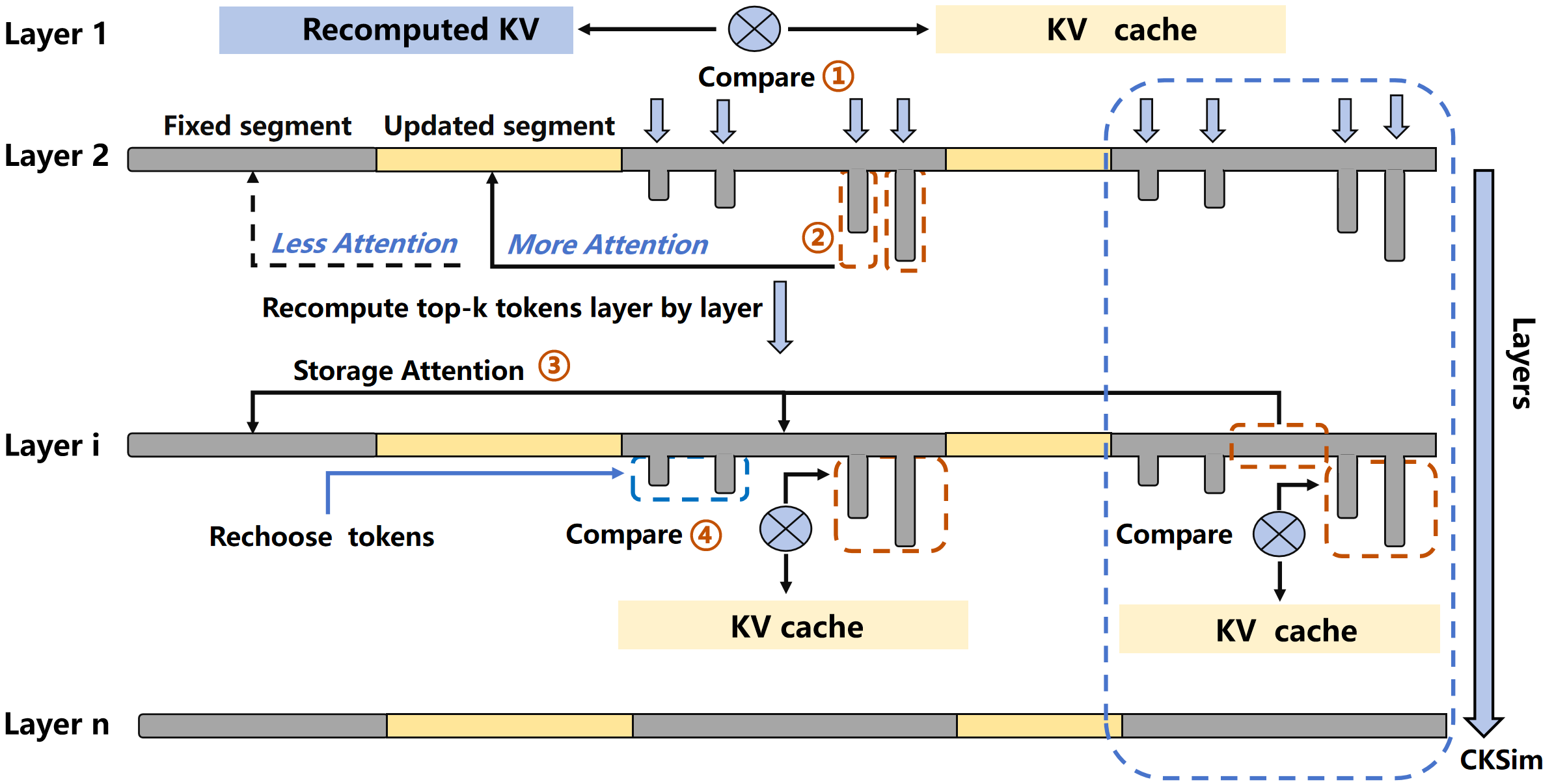
-
Layer 1:对全部 token 做一次完整 recompute,计算每个 token 的偏差
d_i = ||K_recompute - K_reuse||²,取 deviation 最大的 top-k 个 token 放入集合Sk。 - Layer 2 以后:只对
Sk里的 token 重算 KV,然后用加权融合:Kᵢ = αᵢ · Krecompute + (1 - αᵢ) · Kreuse权重
α根据 deviation 动态计算,漂移大的 token 更偏向 recompute,漂移小的 token 更偏向 cache。 - 每 4 层评估一次 CKSim:如果某个 token 的 CKSim < 阈值 τ,说明它已经修正得差不多了,从
Sk里移出;同时把S里下一个偏差最大的 token 加入。
这个设计的核心在于:大部分固定段 token 在 CCPE 之后已经高度相似,真正需要修正的只是少数边界处的 token。只修正 k 个 token,计算量大幅缩减。
5.3 SLIDE:把系统层的坑填掉
Weighted Correction Attention 引入了一个工程问题:因为要 layer-by-layer 地 load KV cache 然后写回修正后的结果,会出现:
- load-before-write 锁:同一层要先 load 老的 KV,才能写新的 KV,变成串行。
- dirty page SSD 写入放大:当容量不够需要把 KV spill 到 SSD 时,被修正过的 dirty page 分布零散,引发大量随机小写,WAF(Write Amplification Factor)飙升。
SLIDE(Spill-aware & Load-write decoupling Intra-layer & Dirty-page Eviction)专门解这两个问题:
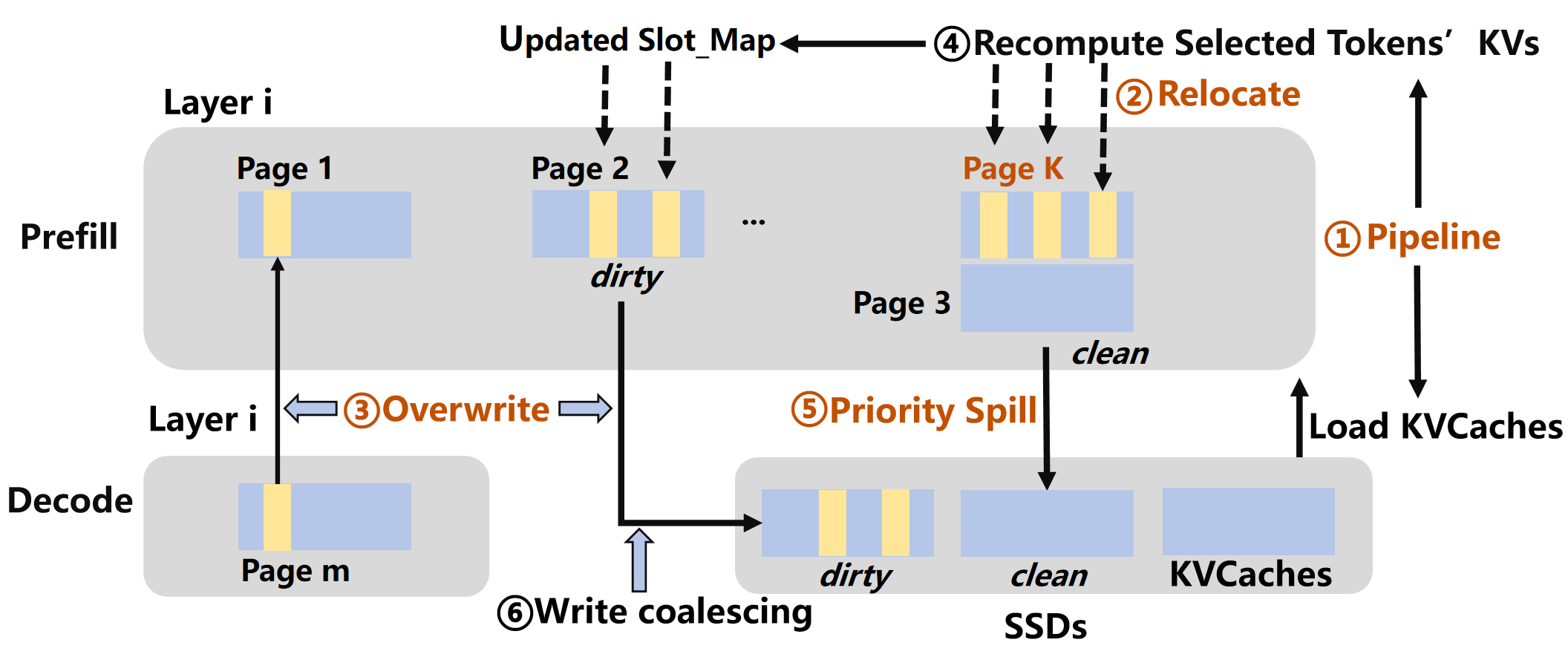
- Load-write decoupling:在 layer i 开始 recompute 的同时,pipeline 地异步加载该层的 KV cache。如果 recompute 先完成,直接写到新分配的 page K,不阻塞等 load;之后 decode 阶段再优先 overwrite 原始 slot。
- Dirty-aware eviction:把含有 selected token 的 page 标记为 dirty,eviction 时优先驱逐 clean page;dirty page 按 selected token 数量降序驱逐,确保写入尽量连续,减少随机写。
6. 实验结果
TTFT(首 token 延迟)对比,三个模型(Mistral-7B、MPT-30B、Llama-3 70B),三个 Agent(Reflexion、MemGPT、SWE-Agent):
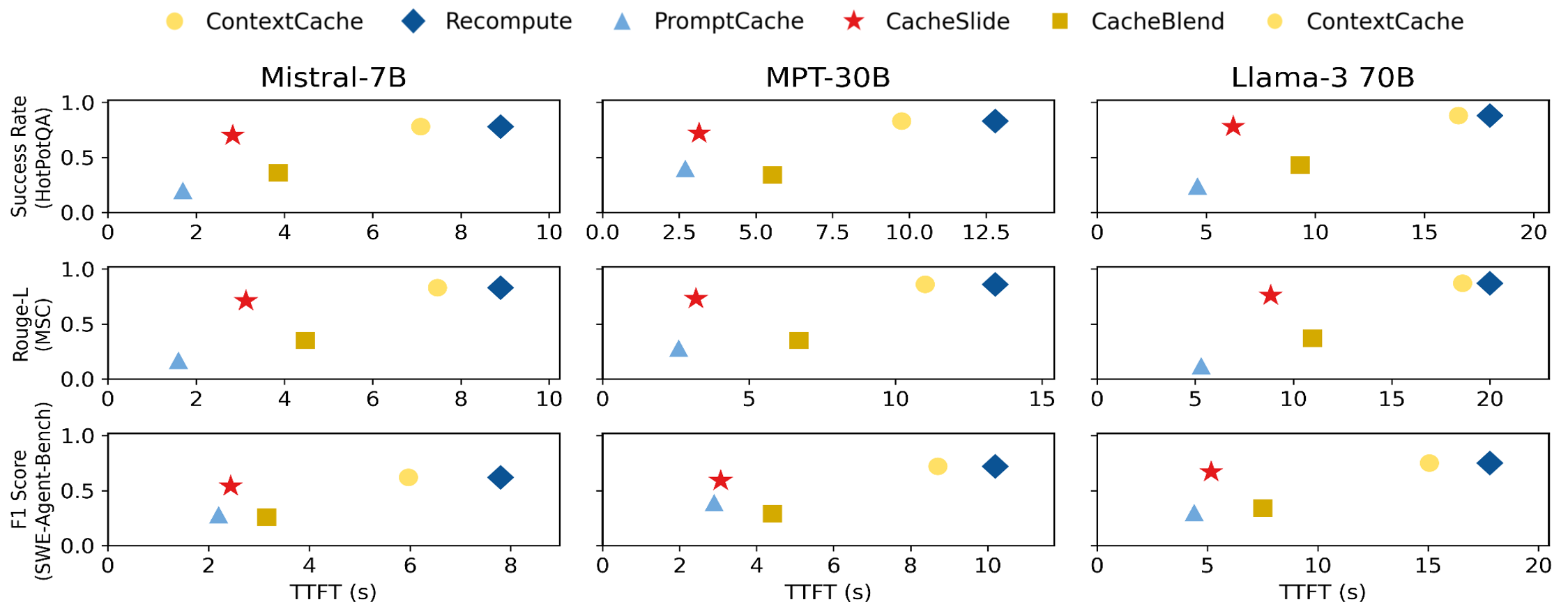
- vs ContextCache(PDC 代表):TTFT 降低 2.4-3.3x,精度可比
- vs CacheBlend(PIC 代表):TTFT 降低 1.21-2.11x,精度提升 1.97-2.28x
- vs PromptCache:TTFT 降低 1.12-2.45x,精度提升 1.41-3.95x
CacheSlide 是唯一一个在效率和精度上同时占优的方案。
并行推理和 Beam Search 下的 throughput,batch size 从 2 扩到 6:
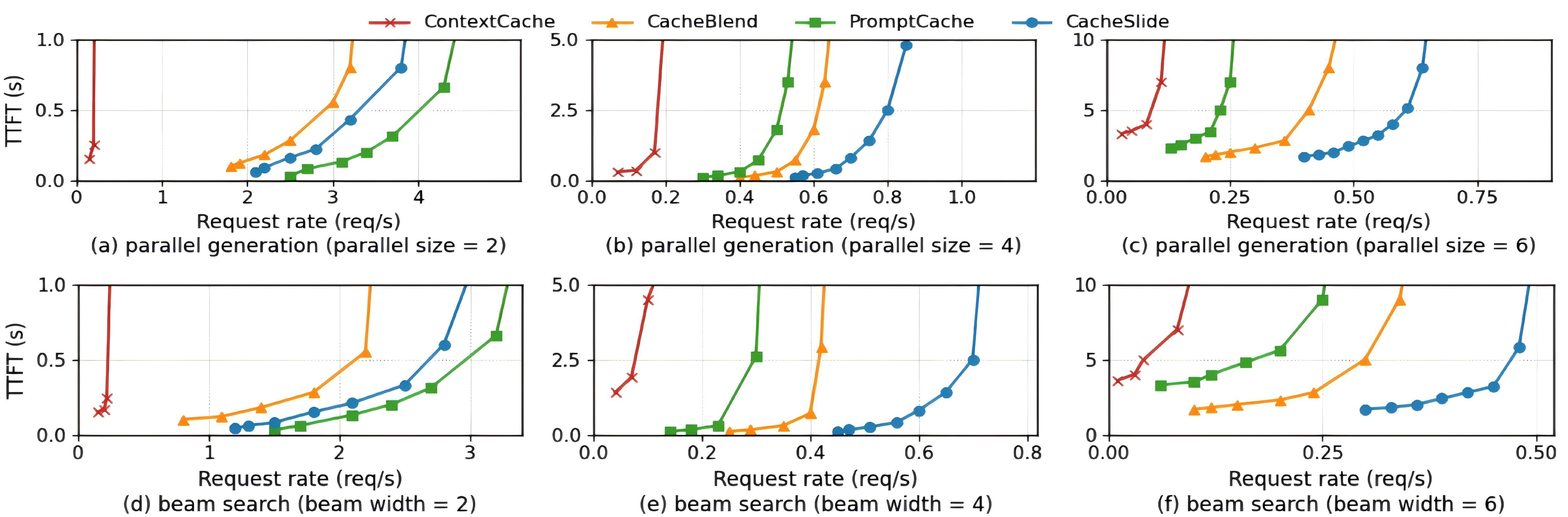
随着 batch size 增大(存储压力上升,KV cache 开始 spill),其他方案的 TTFT 快速劣化,CacheSlide 的优势从 1.2x 扩大到 2.3x。因为 SLIDE 的 dirty-page eviction 避免了对已修正 KV 的反复 I/O。
SLIDE 组件消融:

- Layer-wise Load-write decoupling(LWD):层并行等待时间降低 26.7-51.5%(batch 2→6)
- Dirty-page eviction:write stall 降低 66.9-73.5%
- SSD 写放大(WAF):降低 3.11-3.62x
- GPU storage 占用 vs PromptCache:降低 1.63-1.9x
Throughput 稳定性,Mistral-7B 和 MPT-30B,Reflexion + HotPotQA,batch size=8:
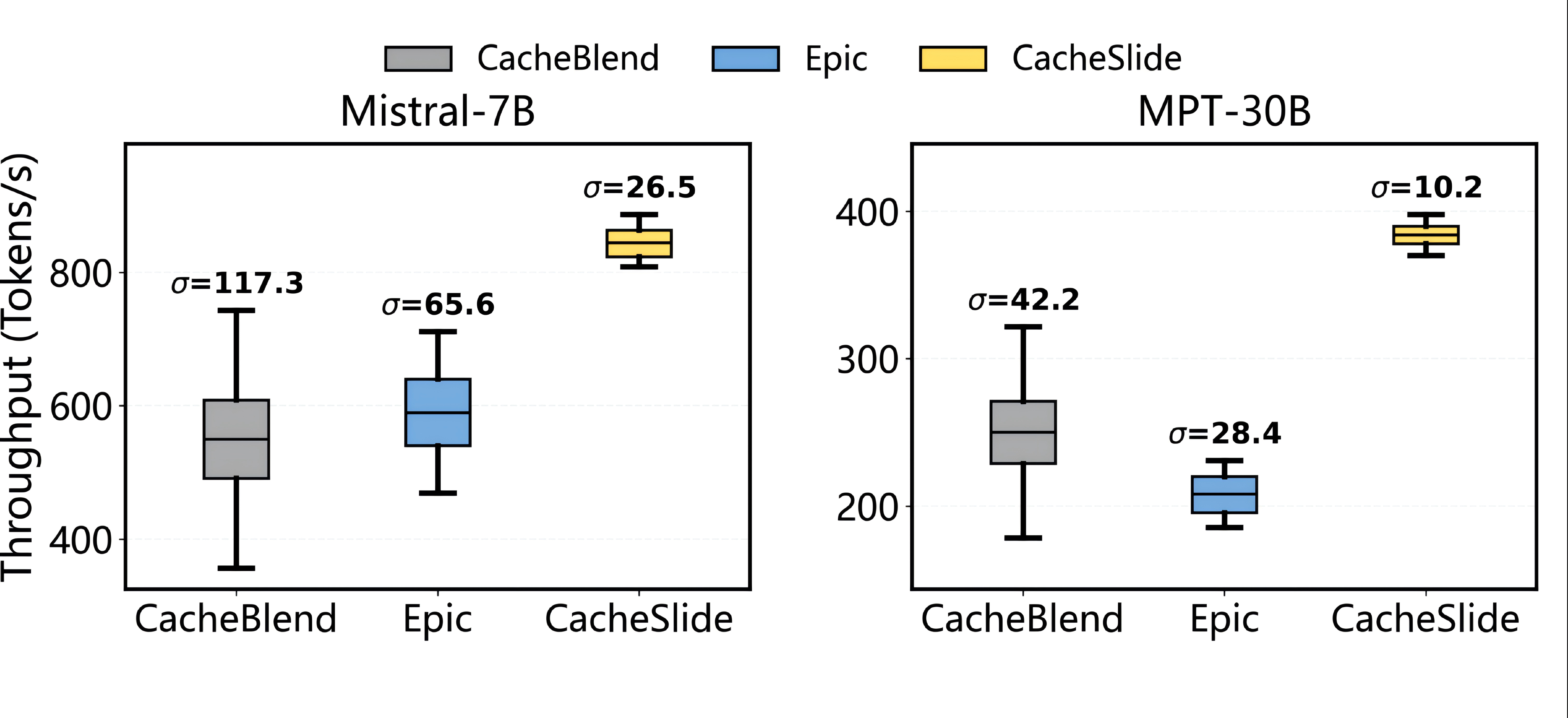
- Mistral-7B:throughput 比 CacheBlend/EPIC 高 49.6%/45.2%,throughput 标准差(σ)低 77.4%/58.6%
- MPT-30B:throughput 比 CacheBlend/EPIC 高 75-82.2%,σ 低 75.8-64.1%
注意 σ 这个指标——lower variance 说明 CacheSlide 不只是快,而且稳,SLIDE 消除了 SSD random I/O 带来的尾延迟抖动。
Top-k 和 CKSim 阈值的影响,QPS heatmap:
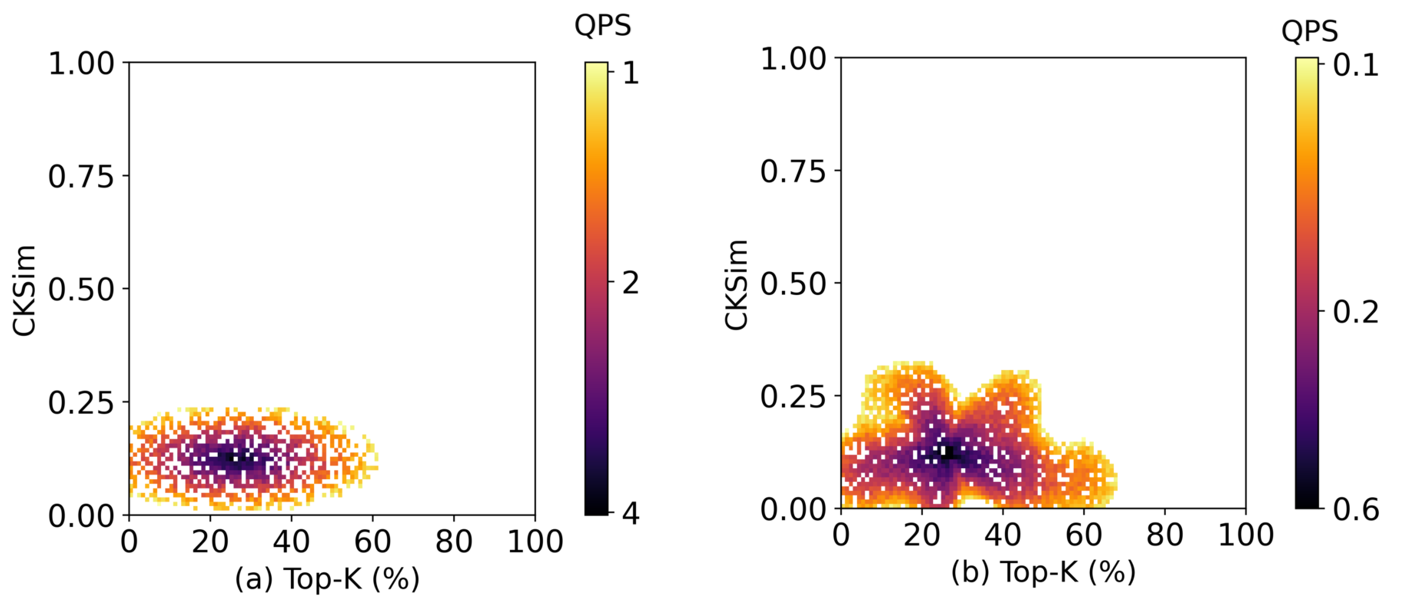
这两个参数控制了 WCA 的修正深度,有个 sweet spot——top-k 太大,修正太多 token,反而 overhead 高;top-k 太小,修正不足,精度掉。实际部署可以根据负载动态调整。
7. 个人评价
这篇工作最值得学习的一点是问题的精确定义。在提出 CacheSlide 之前,论文先花了大量篇幅把 RPDC 这个范式讲清楚——Agent 系统里的 KV Cache 复用问题,既不是 PDC(不能假设固定绝对位置),又不是 PIC(不能完全位置无关),而是一个有独特结构的中间状态。给问题起名、量化它、然后专门设计解法——这是系统论文里比较规范的做法。
几个设计细节写得也比较扎实:
-
CCPE 的预训练不是拍脑袋决定用 CoPE,而是先量化了 RoPE vs CoPE 的 PMKD 差异(90% vs 28%),再针对性地在 CoPE 上做任务级预训练学稳定编码范围。
-
Weighted Correction Attention 里的 similarity-gated 动态 token 集合是个不错的设计——每 4 层重新评估哪些 token 仍然需要修正,真正需要修正的 token 数量会随层数增加而减少(inter-layer similarity 随深度增大),避免了无效计算。
-
SLIDE 里对 dirty page 按 selected token 数降序排 eviction 优先级,这个细节直接决定了 SSD 写入是否连续,工程上真的很重要。
唯一的疑虑是 CoPE adapter-based 预训练会不会影响基础模型的泛化能力,论文里测的三个 Agent 可能不能完全覆盖所有 agentic 场景,这块的鲁棒性还有待观察。
不过整体来说,这是今年 FAST 上我认为做得比较完整的一篇 LLM serving 系统论文,工程性和理论分析兼具,推荐给做 Agent/LLM 推理的同学精读。
如有错误欢迎评论区指出。