KDD'25 | BurstGPT:我们收集了 1031 万条 Azure OpenAI 真实 trace,LLM 推理系统没你想的那么稳
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

KDD’25 | BurstGPT:我们收集了 1031 万条 Azure OpenAI 真实 trace,LLM 推理系统没你想的那么稳
原文:BurstGPT: A Real-world Workload Dataset to Optimize LLM Serving Systems 数据集:github.com/HPMLL/BurstGPT
1. 一个让人不舒服的真相
做 LLM 推理系统优化的人都知道,系统好不好,要跑 benchmark 才算数。
但问题是:大多数 benchmark 用的 workload 是假的。
要么是用微软 Azure Functions(MAF)这类非 LLM 的 serverless workload,要么是靠参数化的合成数据(比如 Zipf 分布的 request length)自己捏一个。这些 workload 跟 LLM 的真实使用场景差距很大:
- 请求频率:MAF 平均 1.64 RPS,真实 ChatGPT 对话服务只有 0.019 RPS(差了近 100 倍)
- 并发模式:合成数据基本是稳定的,而真实 LLM 服务充满突发和不规律
- 响应长度:LLM 的输出长度是 auto-regressive 生成的,不确定性极高
我们在香港科技大学(广州)和华为合作,采集了一家区域性 Azure OpenAI GPT 服务提供商(3000+ 用户)的数据,拿到了 213 天、1031 万条真实 trace,做成了 BurstGPT 数据集。
2. BurstGPT 是什么?

每条 trace 包含:
| 字段 | 说明 |
|---|---|
| Service Type | API 或 Conversation(对话) |
| LLM Type | GPT-3.5 / GPT-4 / GPT-4v |
| Request Start Time | 请求开始时间 |
| Request Length | 输入 token 数 |
| Response Length | 输出 token 数(0 = 失败) |
数据构成:
- ChatGPT API:869 万条
- GPT-4 API:95 万条
- ChatGPT 对话:30 万条
- GPT-4 对话:16 万条
两种服务模式(Conversation vs API)的使用模式完全不同,这一点很关键。
3. 关键发现:真实 workload 长什么样
3.1 并发模式:对话服务周期性,API 服务随机突发
对话服务(用户主动使用):
- 长期:工作日高、周末低,明显周期性
- 短期:工作时间高(9-18 点),夜间低
API 服务(程序调用):
- 长期:完全不规律,无明显周期
- 短期:随机突发,burst 强度变化剧烈
用 Gamma 分布建模并发度,参数 $\alpha$(形状,$\alpha$ 越小 burst 越强)和 $\beta$(速率)每 20 分钟都在变:
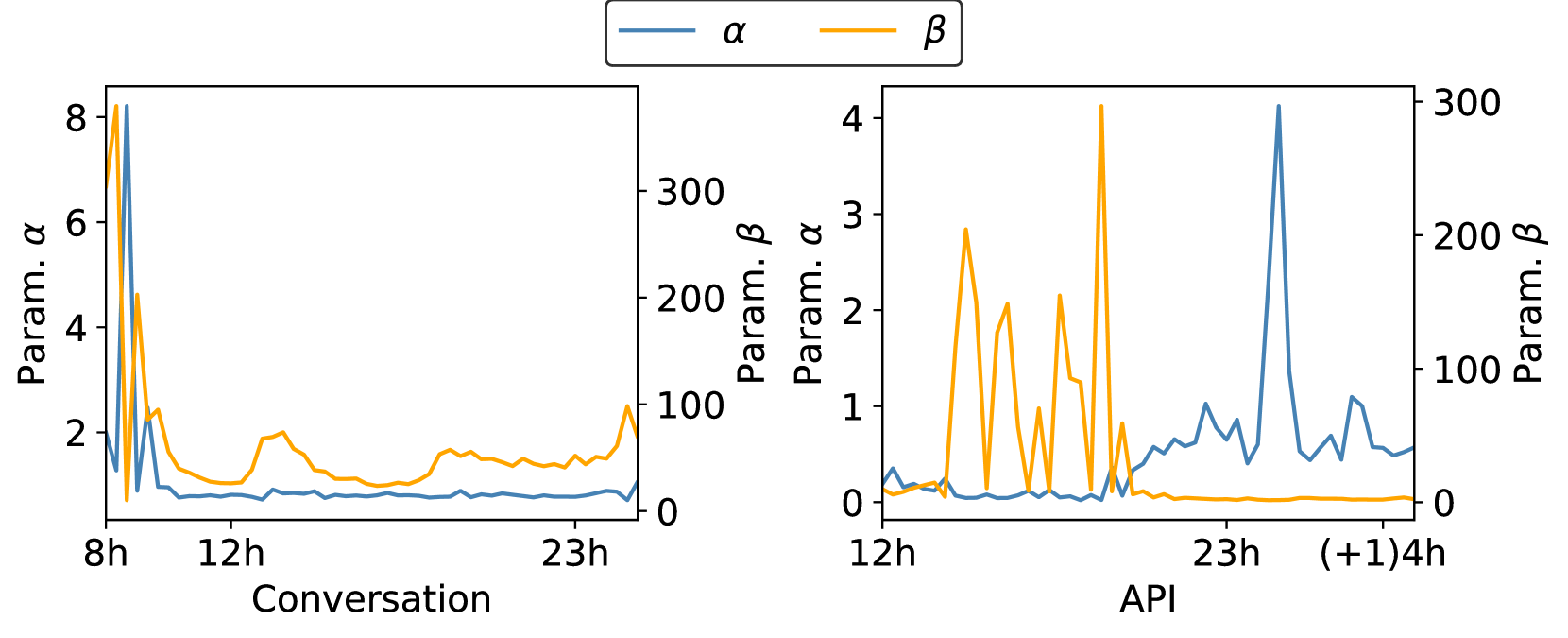
对话服务的 $\alpha$ 在上班高峰时剧烈变化,API 服务的 $\alpha$ 和 $\beta$ 整天都在高频波动。这说明:用固定的合成 workload 评估 LLM 系统,看到的稳定性是假象。
3.2 Token 分布:输入短但输出差异大
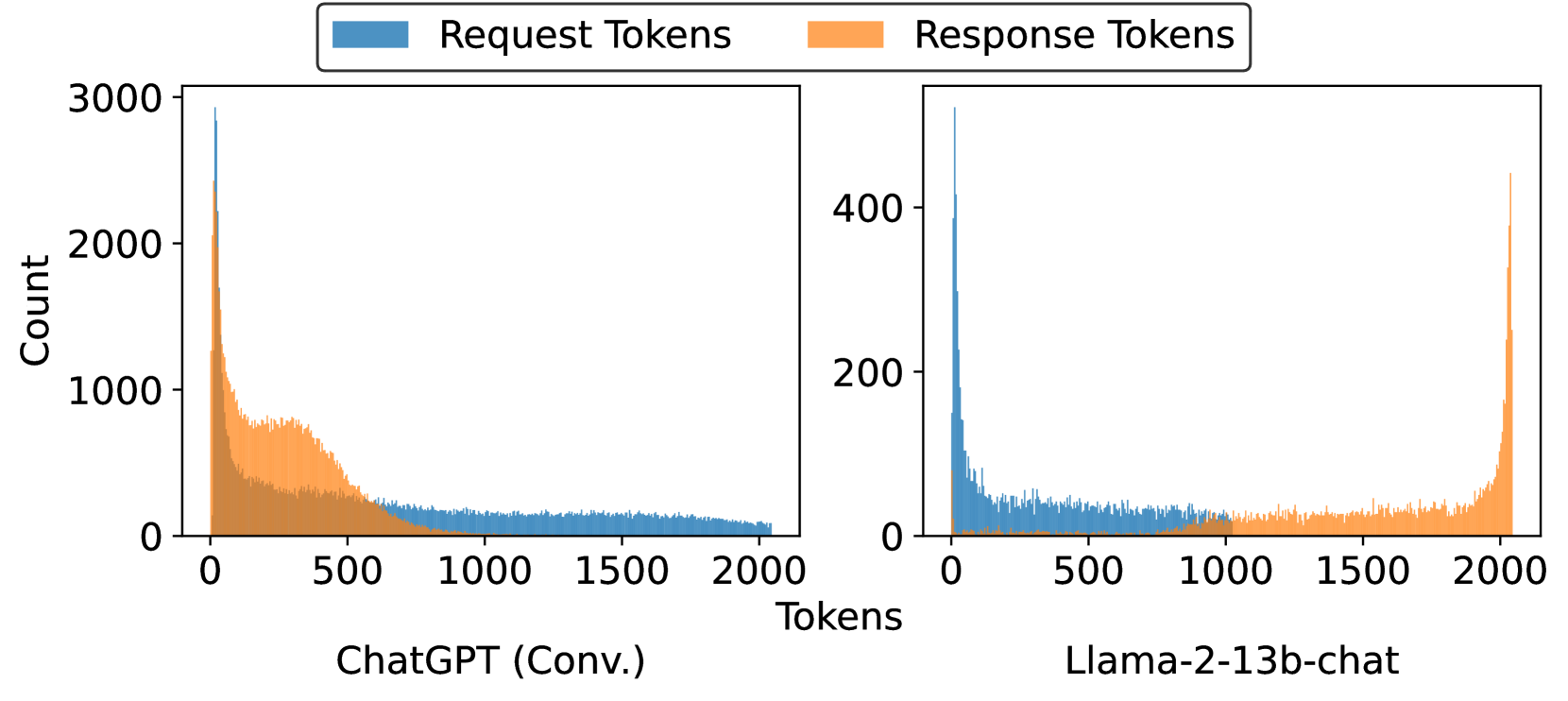
ChatGPT 对话服务:
- Request token:Zipf 分布,短请求居多
- Response token:双峰分布——一堆很短的(直接回答),一堆很长的(长文本生成)
Llama-2-13b-chat:
- Response token:大量请求直接打到 2048 token 上限
这个双峰现象对 KV cache 管理影响很大——你无法预测一个请求到底会用多少内存。
3.3 失败率:ChatGPT 对话失败率超过 5%
这个数据出乎意料。
一般云服务的失败率在 0.1% 以内,但我们测到的 ChatGPT 对话服务平均失败率 >5%,显著高于 API 服务。
原因分析:突发请求导致 KV cache 内存耗尽,系统来不及驱逐就 OOM,直接失败。这是 KV cache 管理不够精细的直接体现。
4. BurstGPT-Perf:配套 benchmark 工具
数据集有了,但怎么用?我们同时开源了 BurstGPT-Perf:
- Workload Generator:把 BurstGPT trace 缩放到目标系统规模(RPS 缩放 or 参数化缩放)
- Prompt Pool:按 Zipf 分布采样 prompt 长度,对齐真实 input 分布
- Metrics:涵盖效率(latency、throughput)、稳定性(latency jitter)和可靠性(failure rate)
两种缩放方式:
- RPS Scaling:直接用参数 $c$ 乘时间戳,让平均 RPS 对齐目标系统
- Modeled Scaling:调整 Gamma 分布参数,保留 burst 特性同时适配系统规模
5. BurstGPT 告诉了我们什么?
5.1 BurstGPT vs MAF2:同 RPS 下,BurstGPT 更难伺候
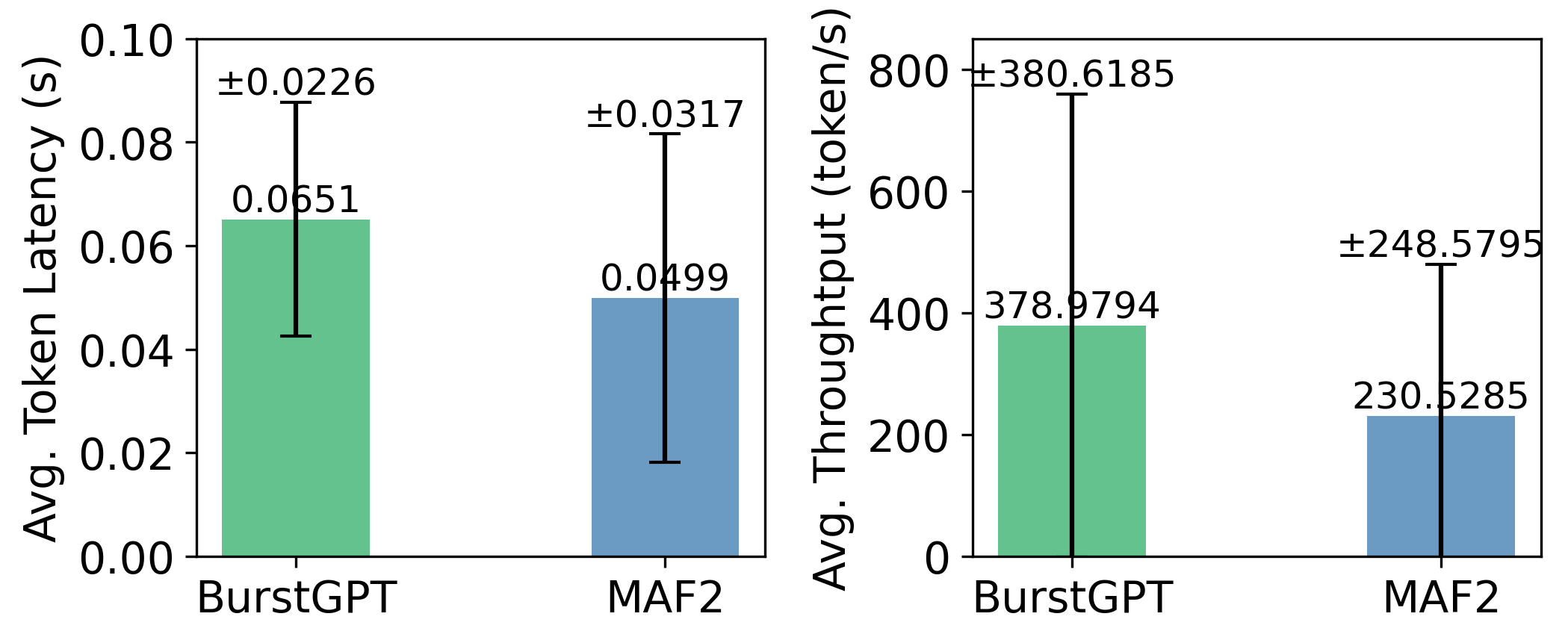
在同样 RPS(0.326)下,BurstGPT workload 下 vLLM 的平均 token latency(0.0651s)比 MAF2(0.0499s)高 30%,吞吐量也更高(因为实际处理了更多并发)。
结论:用 MAF2 测出来系统很稳,一换真实 workload 就原形毕露。合成数据评测的结论没法信。
5.2 同一优化,在对话服务和 API 服务上效果可能相反
我们用 BurstGPT 的对话 trace 和 API trace 分别评估三种调度策略(FCFS、SRF、LRF):
- 对话服务:LRF(Long Request First)在延迟上优于 FCFS
- API 服务:上面的结论完全不成立,LRF 变成了劣势
这说明:一个 workload 上调优的系统,未必能泛化到另一个 workload。现在很多论文只报一种 workload 的结果,结论可信度存疑。
5.3 Huawei PD 解耦系统的实际应用
BurstGPT 还被用于华为 Prefill-Decode(PD)解耦推理系统的原型开发:
- 用 BurstGPT 的 trace 在仿真平台模拟不同 PD ratio 下的 goodput
- 在工作日 6:00 时刻,随着 workload 从大量短请求(解码密集)切换到长请求(预填充密集),最优 PD ratio 从 2:6 切换到 6:2
- 动态 PD ratio + beam search 进一步提升 goodput
这个 case 说明 BurstGPT 不只是学术玩具,在工业系统设计中也有实际价值。
6. 为什么要做这个工作?
这是一篇偏向系统的数据论文。我们在 2024 年初就把数据集挂到 arXiv 上了,然后持续更新了一年多(5 个版本),最终发表在 KDD 2025。
这个工作的出发点其实很朴素:做 LLM serving 系统研究,需要真实 workload。但当时根本没有公开的 LLM trace 数据集。用合成数据做出来的结论,面对真实场景时经常失灵。
我们有机会从一个运行 ChatGPT 区域服务的合作伙伴那里采集到这些数据(当然做了隐私处理,只保留了统计特征),就把它开源了。
现在这个数据集在工业界用得比较多,vLLM、SGLang、Mooncake 等框架的测试中都看到过 BurstGPT 的影子。
7. 总结
| 特征 | BurstGPT |
|---|---|
| 数据量 | 1031 万条 trace |
| 时间跨度 | 213 天 |
| 来源 | Azure OpenAI GPT 区域服务 |
| 服务类型 | Conversation + API |
| 模型类型 | GPT-3.5、GPT-4、GPT-4v |
| 覆盖维度 | 并发模式、对话模式、响应长度、失败率 |
核心结论:用合成 workload 优化出来的 LLM 推理系统,在真实场景里大概率会让你踩坑。