KBS'21 | 我写的 AutoML 综述被引 2700+ 次,今天来聊聊这篇文章的来龙去脉
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

KBS’21 | 我写的 AutoML 综述被引 2700+ 次,今天来聊聊这篇文章的来龙去脉
1. 一个不太谦虚的开场
这篇综述是我读博早期(2019年)写的,发表在 Knowledge-Based Systems(KBS),现在谷歌学术上显示引用量已经超过 2700 次。每次看到这个数字都有点不真实的感觉——一篇综述能有这种引用量,说明当时确实踩在了一个节点上:整个 AutoML/NAS 领域刚刚爆发,大家都急需一个系统性的梳理。
今天想和大家聊聊这篇文章在写什么、当时的研究背景是什么,以及五年多过去了,这个领域发生了什么变化。
(不排除穿插一些个人感受和私货,哈哈)
2. 为什么要写 AutoML 综述?
2019 年前后,深度学习已经在图像分类、目标检测、语言模型等方向都取得了突破性进展。但有一个问题一直存在:
搭一个好的深度学习系统,高度依赖人类专家。
从数据预处理到特征工程,从超参数调整到网络结构设计,每一步都需要领域知识和大量试错。这是深度学习大规模落地的最大障碍之一。
而”自动化机器学习”(AutoML)就是为了解决这个问题的一系列方法的总称。问题是,当时 AutoML 领域的综述要么只覆盖 NAS,要么只覆盖 HPO(超参数优化),没有一个完整覆盖整个 ML pipeline 的综述。
如下图,我们的综述覆盖了完整的 AutoML 流程:
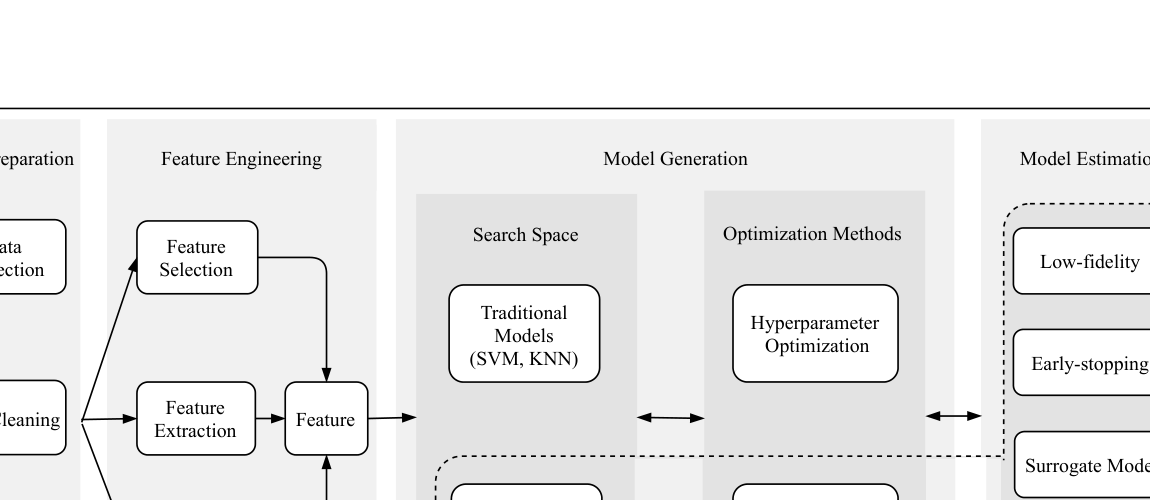
对比当时已有的综述:
我们是第一个同时覆盖 Data Preparation、Feature Engineering、HPO 和 NAS 的综述。
3. 综述内容速览
3.1 数据准备
数据是 ML 的基础,AutoML 在数据层面的自动化主要包括三块:
数据收集:如何自动爬取、众包标注、主动学习标注等。
数据清洗:从简单的缺失值填充到 AlphaClean(把清洗操作建模成超参数优化问题)。
数据增强:这是 2019 年的热点话题,AutoAugment(Google)用 RL 搜索最优增强策略轰动一时。如下图,我们系统整理了图像、音频、NLP 三个模态的增强方法:
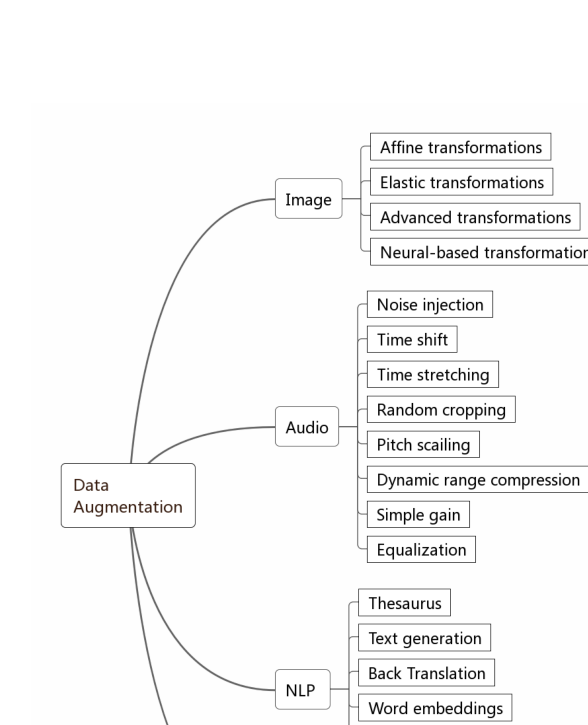
3.2 特征工程
特征选择和特征构造的自动化。这一块在 NAS 出现后关注度有所下降,但在表格数据(非深度学习场景)里仍然很重要,AutoFeat、Featuretools 等工具就在做这件事。
3.3 超参数优化(HPO)
HPO 是 AutoML 里最”经典”的部分,方法分几类:
- Grid Search / Random Search:简单粗暴,但高维效率极差
- 贝叶斯优化(BO):用代理模型(Gaussian Process、Tree Parzen Estimator)建模 f(超参)→性能 的关系,再用 acquisition function 决定下一个采样点。Hyperopt、SMAC3 都是这个方向的代表。
- 进化算法:把每组超参数当成一个”个体”,交叉变异选优。
- Hyperband / BOHB:在资源分配上做了创新,用 early stopping 快速淘汰差的配置。
3.4 神经架构搜索(NAS)——重头戏
这也是综述最重头的部分(40%+ 的篇幅都在讲 NAS),因为 2019 年 NAS 正在爆炸。
搜索空间
NAS 的搜索空间定义了”可以搜索哪些架构”,主要分三种:
Entire-structured:整个网络从头搜——最灵活但搜索代价极大。如下图,节点是 layer,边是操作(conv 3×3、max pool 等):
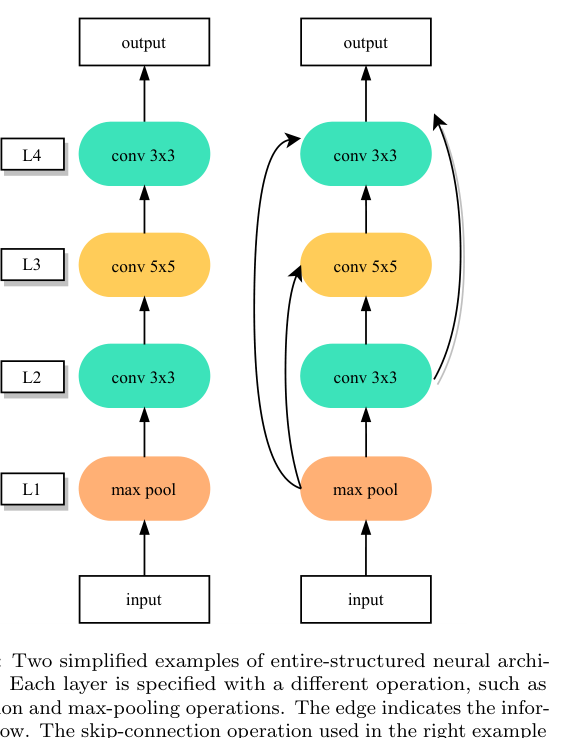
Cell-based:把网络分成可重复的 cell(block),只搜 cell 的结构再堆叠——大幅降低搜索空间,且天然可迁移。NASNet、DARTS、AmoebaNet 都在这个范式下。
Hierarchical:多级 cell 嵌套——cell 里面还有 cell。
架构优化方法
- 强化学习(RL):用 controller RNN 生成架构,用验证集精度作为 reward。NASNet 是代表,但当时需要 450 块 GPU 跑 4 天,离谱的消耗。
- 进化算法(EA):把架构当成基因,交叉变异。AmoebaNet 系列走这条路。
- 梯度下降(Gradient-based):最划时代的突破来自 DARTS(2018)——把离散的架构搜索松弛成连续的,用梯度优化,一块 GPU 跑几小时就搞定。如下图,DARTS 和 P-DARTS 的搜索阶段对比:
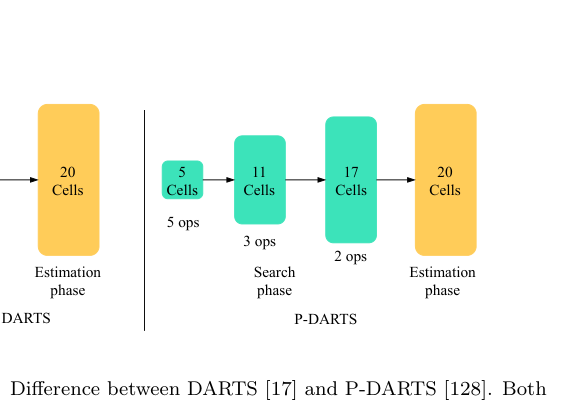
P-DARTS 是对 DARTS 的改进——把搜索分成多阶段,逐步增加 cell 数、减少候选操作数,桥接了搜索和评估阶段的 gap。
- 代理模型(Surrogate)/ 权重共享(One-shot NAS):ENAS 用参数共享让所有子网络共享权重,搜索效率又上了一个台阶。
4. 写这篇综述的感受
说实话,当时写这篇综述的时候,我刚开始读博不久,主要动机是搞清楚这个领域到底在干嘛。
那时候 NAS 论文每周都在刷 SOTA,看不过来。写综述迫使我把几十篇论文系统读了一遍,整理出一个有逻辑的 taxonomy。这个过程对自己后续做 NAS 研究(比如我们后来的 EAGAN、NAS-LID 等工作)有很大帮助。
引用量高的原因大概是:
- 时机好——NAS 正在从小众变大众,需要入门材料
- 覆盖面广——唯一覆盖完整 pipeline 的综述
- 持续更新——从 2019 发到 2021 年更新了 6 个版本,保持了一定的时效性
5. 现在来看,哪些判断对了,哪些没预测到?
说对了的:
- One-shot NAS(权重共享)会成为主流 ✓ —— NASBench、DARTS-PT、β-DARTS、BossNAS 等大量工作涌现
- NAS 会往更实用方向走(移动端、医疗等垂直场景)✓
- 数据增强自动化(AutoAugment 方向)会持续发展 ✓
没预测到的:
- LLM 的爆发让 NAS 在 NLP 侧几乎”消失”了——BERT/GPT 的出现让 Transformer 一统江湖,NLP 里的架构设计问题不再是搜索问题
- Foundation model 时代,”训一个大模型+微调”的范式让 AutoML 的部分工作(数据增强、架构搜索)在 NLP 里变得不再那么重要
- 但 MoE 架构兴起之后,路由机制的设计又带来了新的 NAS-like 问题——这也是我现在做 ExpertFlow 这类工作的动机之一
一个感悟: AutoML 的核心精神(用自动化方法替代人工试错)没有过时,只是形态变了——现在更多是 prompt optimization、agent workflow 自动化、MoE 路由优化。
6. 写在最后
如果你现在才入门 ML/深度学习,这篇 2021 年的综述作为了解 AutoML 历史背景的读物还是有用的,但 NAS 那部分的很多具体工作现在已经是”历史”了(在 LLM 时代)。
如果你对 NAS / AutoML 这个方向有兴趣,欢迎私信聊聊,或者看我们后续更新的工作。
论文地址:https://arxiv.org/abs/1908.00709 代码/工具:hyperbox(我们组开发的 AutoML 框架)