说人话:一文搞懂现在火热的 LLM agent 自进化原理
说人话:一文搞懂现在火热的 LLM agent 自进化原理
插播:以下内容节选自我们团队最近出版的书籍《动手学 AutoML:从 NAS 到大模型优化实战》,感兴趣的朋友可以前往 jd 搜索购买,感谢支持 https://item.jd.com/15384990.html

最近 LLM agent「自进化」(self-evolving agent)这个词特别火。
逻辑大概是这样:让 agent 自己生成一堆变体(改改 prompt、换换工具组合、调调 workflow),在任务上跑一遍(rollout),谁的表现好就留下谁,再在好的那批身上继续改——这么一轮一轮迭代下去,agent 就「越进化越强」。
我第一次刷到这类工作的时候,第一反应不是「哇好新」,而是——
这不就是 进化算法(Evolutionary Algorithm) 吗?
生成变体 = 变异 / 交叉,跑任务打分 = 适应度评估,留下好的 = 选择。这套「选择—变异—保留」的循环,在 AutoML、尤其是神经架构搜索(NAS)领域,已经被反复打磨了快十年。换的只是搜索对象:以前搜的是网络结构,现在搜的是 agent 的 prompt 和工具链。
所以这篇我想把这套「自进化」的机器从头拆开,用最朴素的方式讲清楚它到底怎么跑——配代码、配图,让你看完之后,再去刷那些 self-evolving agent 的 paper 会有种「哦原来你也是这套」的通透感。
不背公式,从问题出发。
1. 说人话:什么是「进化」
进化算法这个名字唬人,其实核心就一句话:学生物进化,让一群解自己卷,卷出最好的那个。
它和我们熟悉的梯度下降是两条完全不同的路。梯度下降需要目标函数可微,顺着导数往下滑;进化算法完全不要求可微,它就是「生成一堆候选 → 打分 → 淘汰差的 → 在好的身上做变异 → 再来一轮」。所以哪怕你的优化目标是「推理延迟」「显存占用」这种没法求导的东西,它照样能搜。
这也是为什么它在 NAS、在今天的 agent 自进化里都吃得开——因为这些场景的「好坏」根本写不出一个可微的 loss。
理解这件事的第一步,是把进化算法那套生物学黑话,翻译成 NAS 的语言。下面这张对照表,我个人觉得是理解整件事的钥匙:
 (节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 4 章 表 4-1)
(节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 4 章 表 4-1)
你把右边那一列从「神经网络架构」换成「一个 agent」,整张表对 LLM agent 自进化照样成立:
- 个体(Individual) → 一个 agent 配置(一套 prompt + 工具 + workflow)
- 种群(Population) → 一批不同的 agent
- 适应度(Fitness) → agent 在任务集上的成功率 / 得分
- 变异(Mutation) → 随机改一改它的 prompt 或工具
- 选择(Selection) → 保留表现好的那几个
是不是一下就通了。「自进化」不是什么新范式,它本质上是进化算法换了个搜索空间。
2. 一轮「进化」到底在干什么
光有对照表还不够,得看它一轮循环里具体跑了哪几步。进化搜索可以拆成六步,流程如下图:
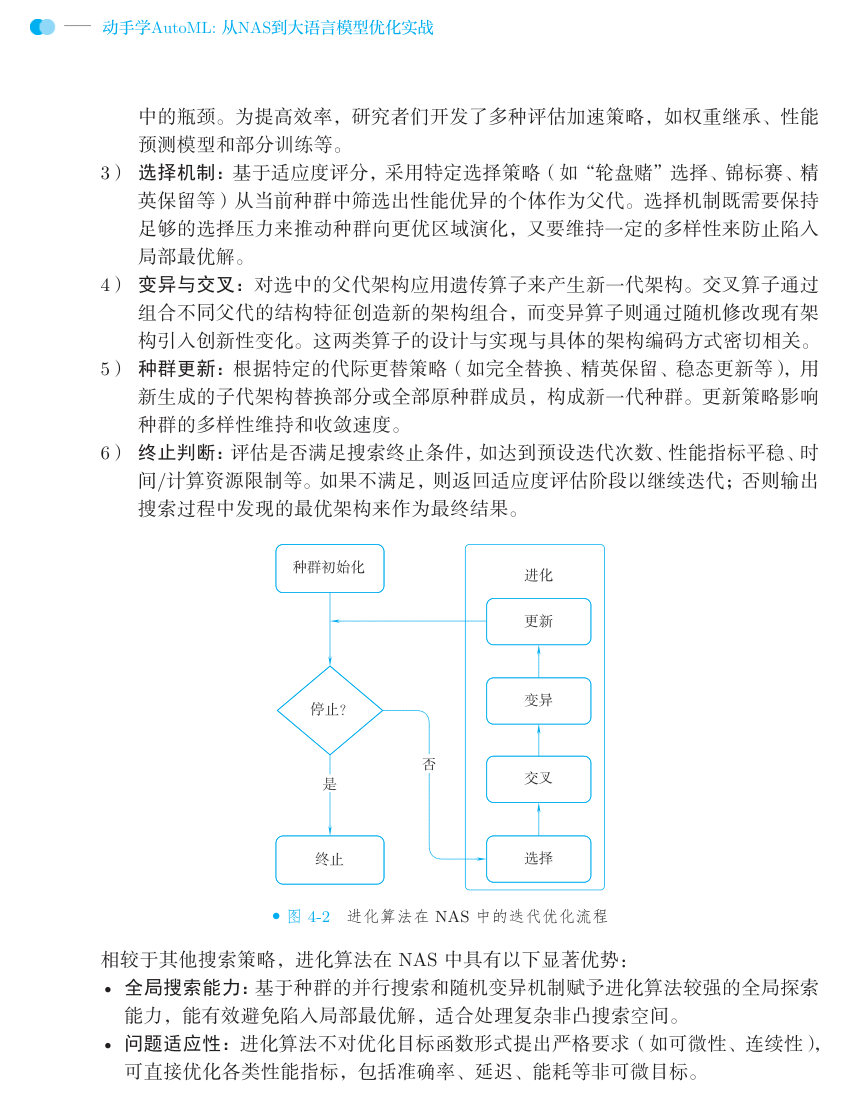 (节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 4 章 图 4-2)
(节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 4 章 图 4-2)
我用大白话过一遍:
- 种群初始化:随机生成一批候选解(架构 / agent),作为起跑线。这一步多样性很关键,太单一容易早早收敛到一个局部最优就出不来了。
- 适应度评估:每个候选都跑一遍打分。这一步是整个流程的瓶颈——对 NAS 来说是训练评估一个网络巨贵,对 agent 自进化来说是每跑一遍 rollout 都在烧 token。后面所有的加速 trick,本质上都是在跟这一步的开销作斗争。
- 选择:按分数挑出表现好的当父代。
- 交叉 + 变异:在父代身上做改动,生成下一代。这是产生「新东西」的唯一来源。
- 种群更新:用新一代替换掉老种群的一部分。
- 终止判断:到点了(迭代次数 / 资源耗尽 / 性能不再涨)就停,输出最优解;没到就回到第 2 步。
你拿这张图去对最近那些 self-evolving agent 的 paper,会发现它们的 pipeline 几乎是一比一的对应。区别只在第 4 步「怎么变异」和第 2 步「怎么评估」,剩下的骨架都一样。
所以接下来我重点讲这两步——它们才是真正有技术含量、也是最容易踩坑的地方。
3. 难点一:怎么「变异」一个结构而不把它搞坏
先说变异和交叉。
道理听起来很简单:随机改个基因嘛。但 「怎么编码」直接决定了你能怎么改。这里我挑最朴素的二进制编码举例。
比如搜一个三层卷积网络,每层有「卷积核大小」和「激活函数」两个选择,各用一个比特表示。那么 00 01 10 就完整编码了一个网络。这时候交叉和变异就特别直观——交叉就是两个父代各切一半拼起来,变异就是随机翻转某几个比特:
 (节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 4 章 图 4-3)
(节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 4 章 图 4-3)
代码也短得不像话,实现就这么几行:
def gene_crossover(parent_a, parent_b):
"""单点交叉生成子代"""
crossover_pos = len(parent_a) // 2
child_a = parent_a[:crossover_pos] + parent_b[crossover_pos:]
child_b = parent_b[:crossover_pos] + parent_a[crossover_pos:]
return child_a, child_b
def gene_mutation(arch_code, mutation_prob=0.1):
"""随机变异操作"""
return [
random.choice(architecture_params[param])
if random.random() < mutation_prob else val
for param, val in zip(architecture_params.keys(), arch_code)
]
但这里有个结结实实的坑,也是我想强调的重点:
简单粗暴地按比特交叉,很可能把网络搞坏。
举个例子,两个父代网络要交换的位置,一个是卷积、一个是 ReLU,它俩的输入输出通道数根本对不上。你硬交换,生成的子网会因为通道数不匹配,前向传播直接挂掉。
这个坑在 LLM agent 自进化里有一模一样的版本:你把 agent A 的一段 prompt 和 agent B 的工具调用逻辑随机拼一起,很可能拼出一个语义矛盾、根本跑不通的怪胎。
常见的解法是:别在最细的粒度上交叉。NAS 里的做法是把「卷积 + BN + ReLU」打包成一个「阶段(stage)」作为交叉的最小单元,保证交换后结构依然合法。换到 agent 上,就是按「功能模块」而不是「单个 token」去变异。
变异这件事的精髓,是在「探索新结构」和「不破坏现有结构」之间找平衡——变异太猛,种群全废;变异太弱,又跳不出当前的局部最优。这个权衡,是所有搞自进化的人都绕不过去的。
4. 难点二:又要准又要小,单目标根本不够
第二个难点在评估和选择。
前面为了讲清楚,我都假设「适应度」就是一个数(比如准确率)。但真实场景里你要的从来不止一个目标:
- 搞 NAS 压缩:又要准确率高,又要模型小
- 搞 agent 自进化:又要任务成功率高,又要 token 省
这俩目标天生打架——模型越大通常越准,agent 想得越多通常越对,但代价就是更贵。这时候「最优解」根本不是一个点,而是一条帕累托前沿(Pareto Front):在这条线上的每个解,你想让它在某个目标上更好,就必然得牺牲另一个目标。
处理这种多目标问题,业界最经典的算法叫 NSGA-II。它的核心是把种群按「非支配排序」分层,再用「拥挤度距离」保证留下来的解足够多样,流程如下图:
 (节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 11 章 图 11-6)
(节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 11 章 图 11-6)
我贴一段核心的「支配关系判断」,你感受一下其实没那么玄:
def dominates(a: np.array, b: np.array):
# 若 a 支配 b,返回 True(a 在所有目标上都不差,且至少一个目标更好)
return np.all(a <= b) and not np.all(a == b)
就这么一行判断,配上非支配排序,你就能把一大堆「准确率 / 模型大小」各异的候选,自动分成一层一层的帕累托前沿。第一层就是当前最优的那一组互不支配的解——它们各有各的取舍,没有谁能完全碾压谁。
这套多目标的思路,恰恰是现在 agent 自进化里最缺的一环。我看很多自进化的工作还停留在「单目标卷成功率」,卷到最后 agent 是变强了,但每跑一次贵得离谱。NSGA-II 这种东西迁移过去,是能直接派上用场的。
5. 来真的:手撸一个进化压缩,把 ResNet 砍掉 75%
讲了这么多原理,最后一定要落到一个能跑起来的真实项目上——光说不练那是 PPT。
下面用我自己开源的 hyperbox 框架,把 ResNet18 在 CIFAR10 上做一次进化压缩。整个流程就是前面讲的那套机器,只不过搜索对象变成了「每一层的通道数压缩比例」:
- 训练超网(supernet):把所有候选子网的权重共享在一张超网里一起训。这就是 one-shot NAS 的核心 trick,省掉了「每个候选都从头训」的天价开销。
- 进化搜索:超网权重固定,用上面那套 NSGA-II 选择 + 交叉 + 变异去搜。每采样一个子网,直接从超网继承权重就能评估,不用重训、不用微调。
- 微调:对搜出来的帕累托模型做最后的微调,定稿。
跑完之后,搜索结果长这样——横轴是模型大小,纵轴是验证准确率,每个点都是一个搜出来的子网:
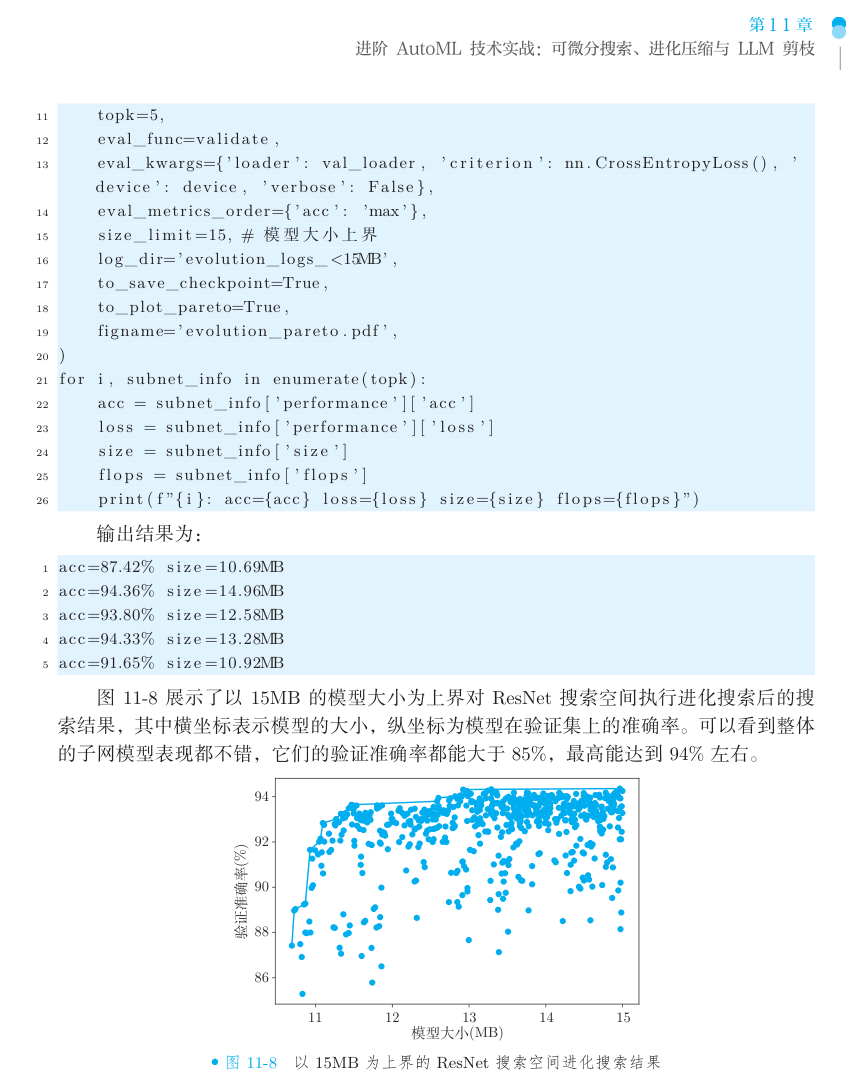 (节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 11 章 图 11-8)
(节选自《动手学 AutoML:从 NAS 到大语言模型优化实战》第 11 章 图 11-8)
可以看到整条帕累托前沿上的子网表现都不错,准确率基本都在 85% 以上,最高能到 94% 左右。挑第一个帕累托模型做微调,最终的结果是:
模型大小 10.69MB,相比原始超网压缩了约 74.95%,测试集准确率 91.39%。
砍掉四分之三的参数量,准确率只掉一点点。这个过程里没有一处是手工调的——通道数怎么配、哪层该瘦、哪层该留,全是进化算法自己搜出来的。这就是 AutoML 想干的事:把「试错」这件苦力活,从你手上接过去自动化掉。
6. 写在最后
绕了一圈,其实我想说的就一句话:
LLM agent「自进化」不是凭空冒出来的新魔法,它的底层骨架,就是进化搜索那套被打磨了快十年的东西。 选择、变异、交叉、多目标权衡、超网共享——这些 NAS 里反复验证过的工具,正在被原样搬到 agent 上。区别只是搜索空间从「网络结构」换成了「prompt 和工具链」。
所以如果你是冲着 agent 自进化、或者 LLM 时代的模型优化来的,我反而建议你回头把进化算法这套基础吃透。新热点跑得快,但底层的优化逻辑稳得很——吃透了它,再看那些新 paper 会轻松很多。
以上内容(术语对照、进化流程、交叉变异、NSGA-II 非支配排序与拥挤度距离、以及 hyperbox 上的 ResNet 压缩实战)节选自我写的《动手学 AutoML:从 NAS 到大语言模型优化实战》(机械工业出版社)。书里还有 NAS 各大范式、超参优化、以及 LLM 时代量化剪枝的内容,每个概念都尽量配了可运行的代码而不是 toy demo。有需要的同学可以前往京东搜索书名,或复制下方完整链接购买,感谢支持:
https://item.jd.com/15384990.html
照例,欢迎评论区聊——包括书里写得不清楚的地方,都可以直接来问。

- 作者:marsggbo,新加坡 A*STAR CFAR 研究员
- 小红书 / 知乎 / GitHub: marsggbo