MoE 变 Dense:剪枝+蒸馏能救内存瓶颈吗?
MoE 变 Dense:剪枝+蒸馏能救内存瓶颈吗?
📖 新书推荐:如果你对 MoE 部署优化、模型压缩、自动搜索这类话题感兴趣,欢迎看看我们刚出版的《动手学 AutoML:从 NAS 到大语言模型优化实战》——系统讲透搜索空间设计、效率评估、LLM 压缩与微调等核心方法,配有完整可运行代码。京东搜索「动手学 AutoML」即可。
原文:Pruning and Distilling Mixture-of-Experts into Dense Language Models
1. 前言
你是否想过这个问题:
Qwen3-30B-A3B 推理起来爽,但你得先把 30B 参数全部塞进显存——哪怕每个 token 只激活 3B。
这就是整个 MoE 时代最核心的矛盾:稀疏激活带来了计算上的高效,但内存瓶颈根本没有解决。MoE 能让你省算力,却没法省显存。
所以自然就有人问:能不能把训练好的 MoE 直接”变成”一个 dense 模型? 不是从头训 dense,也不是压缩成小 MoE,而是把 expert 的知识直接浓缩到一个标准的 FFN 里?
今天想和大家聊聊这篇来自 KRAFTON 的工作——据我所知,这是第一个系统性研究 MoE-to-dense 转换的框架,而且结论相当有意思。
2. 背景:MoE 的内存困境
先交代下背景。
现在主流的大模型基本都是 MoE 架构:DeepSeek-V3/V4、Qwen3、Llama 4、GLM-5……这些模型的共同设计思路是:有很多 expert,但每个 token 只路由到其中少数几个。
以 Qwen3-30B-A3B 为例:
- 总参数:30B
- 每个 MoE 层有 128 个 expert
- 每个 token 激活其中 8 个
- 实际参与计算的参数:~3B
从计算量看,30B 的 MoE 用起来接近 3B dense 的成本。但从内存来看——你得把 30B 全部加载进来,不然 router 不知道往哪路由。
这就结结实实踩了个大坑:你买单卡 A100 跑不了,买多卡又觉得没必要,因为大多数参数在推理时根本用不上,就是坐在那里吃显存。
3. 现有方案的痛点
面对这个问题,学术界已经有不少工作了:
3.1 Expert 剪枝(把 MoE 压缩成小 MoE)
REAP、MC-SMoE、HC-SMoE、Sub-MoE、MergeMoE……这些工作的思路是减少 expert 数量,把 128 个 expert 压缩成更少。但有一个本质问题没有解决:
输出还是 MoE 模型。你还是需要 router,还是需要把所有保留的 expert 全部加载进显存。内存瓶颈的根本矛盾没有消失。
如下图,Table 1 对现有方法做了梳理——所有 prior work 都只能产出更小的 MoE,而这篇工作第一个把目标定在了完全的 dense 模型上:
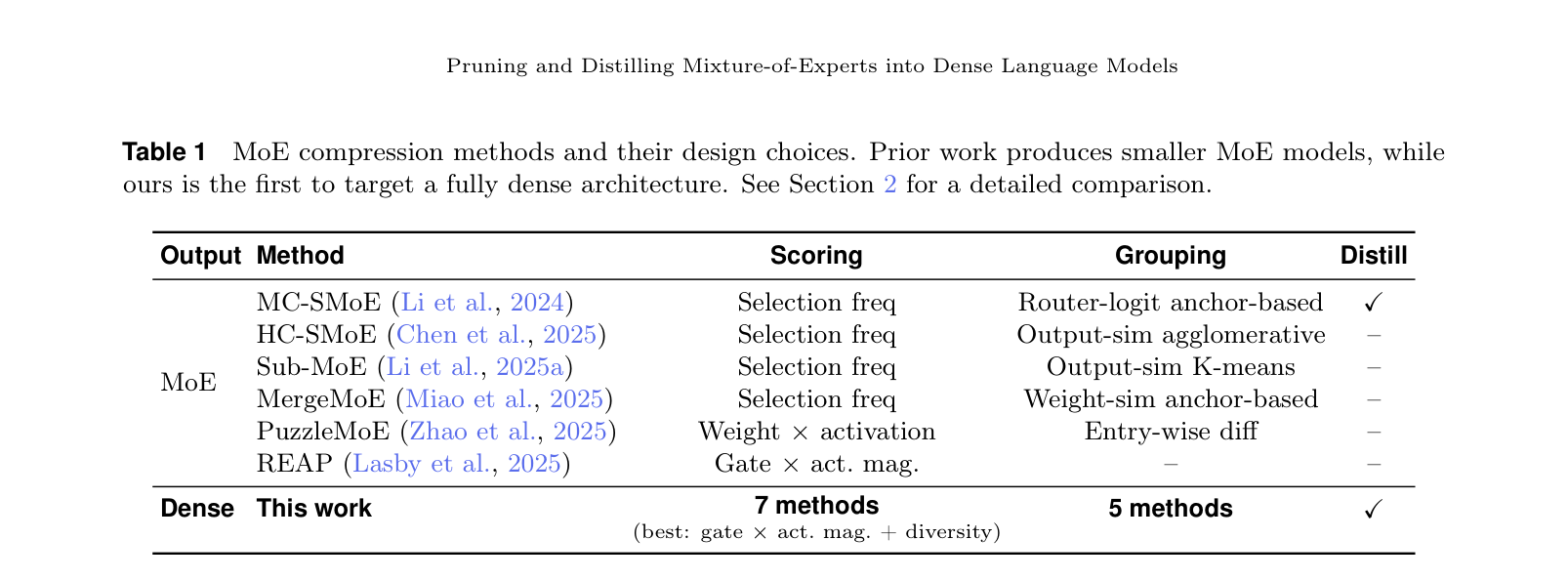
3.2 Dense 模型剪枝(Dense-to-Dense)
另一条路是先训一个大 dense 模型(比如 Qwen3-32B),再剪枝蒸馏到小 dense 模型。Minitron 就是走这条路。
问题是:
- 你得先有个大 dense teacher,训练成本本身就不低
- 大 dense teacher(32B)在推理时每个 token 全量激活,给学生做蒸馏时计算效率低
- dense 剪枝在高压缩比下效果很差(后面实验数据会说明)
4. 这篇工作的核心思路
这篇论文提出了一个三步走的框架,把 MoE 直接转成 dense:
第一步:对 MoE 层里的所有 expert 打分,选出最重要的 K 个。
第二步:把 K 个 expert 分成 k 组(k 是原来 MoE 的 top-k 数),每组内做 score-weighted 平均得到一个代表性 FFN 块,再把 k 个 FFN 块拼接成一个完整的 dense FFN。
第三步:用原始 MoE 作为 teacher,对 dense 学生做知识蒸馏,把蒸馏过程中的精度损失补回来。
如下图是完整的 pipeline 和与其他方法的对比:
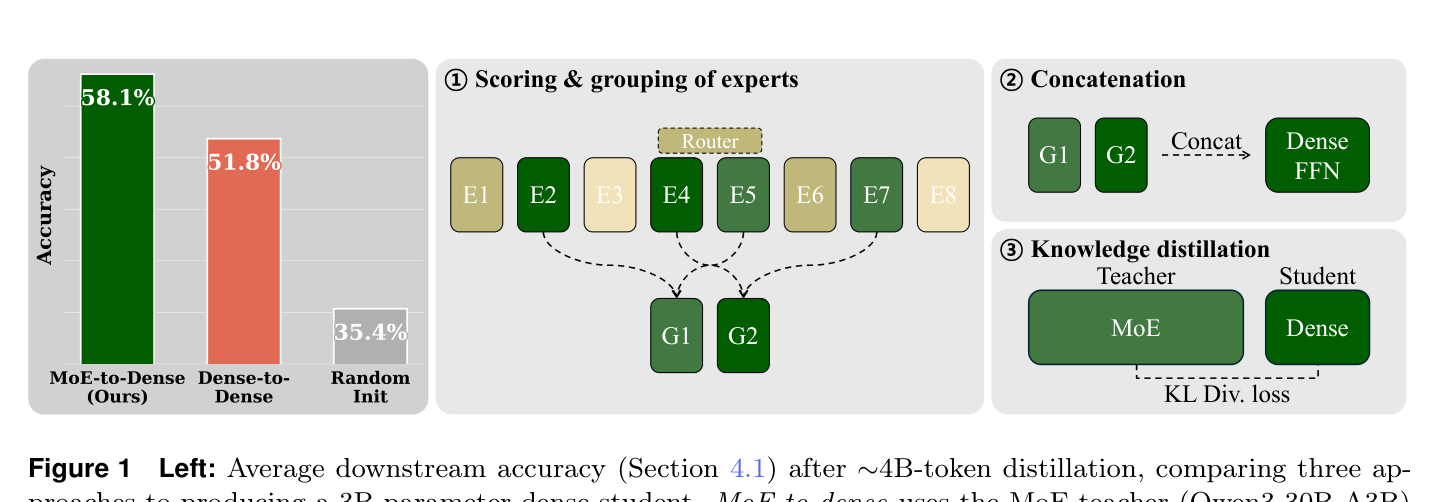
这张图非常关键——左边对比了三种产出 3B dense 模型的方式(MoE-to-dense、Dense-to-dense pruning、Random Init),MoE-to-dense 大幅领先;右边是 pipeline 示意图,三步转换一目了然。
5. 方法细节:打分才是关键
5.1 Expert 打分:七种方法的对决
这篇工作花了大量篇幅研究如何给 expert 打分——这是整个 pipeline 中最关键的决策,比怎么分组更重要。
论文一共评测了 7 种打分方法,大致分三类:
频率类(SF/PP/PS):看 expert 被选中了多少次、路由概率多高。这类方法偏爱”generalist”expert——服务的 token 多,但选的 expert 高度重叠,没什么多样性。
条件概率类(CP/ACP):CP 只统计被路由到时的平均概率,过滤掉频率信息,专注于 router 真正”有把握”时的分数;ACP 在 CP 基础上再乘以输出范数,把 expert 的实际输出贡献也算进去。
D-Optimal 类(DO-CP/DO-ACP):这是这篇论文自己提出的方法。核心思想是:独立给每个 expert 打分会选出很多”同质”的 expert,浪费了 dense FFN 的表示能力。D-Optimal 准则用 Gram 矩阵的 log-determinant 来同时衡量每个 expert 的重要性和 expert 之间的多样性,保证选出来的 k 个 expert 尽可能”各司其职”。
如下图展示了不同打分方法选出的 top-8 expert 之间的重叠度:
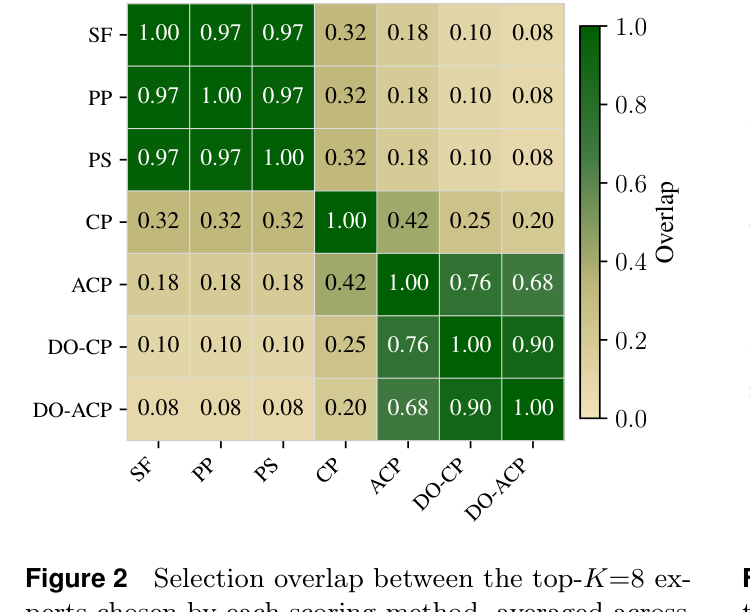
频率类方法(SF/PP/PS)选出来的 expert 几乎完全重叠——本质上它们在选同一批”万金油”expert。DO-ACP 和其他方法的重叠度只有 ≤0.08,选出的 expert 要多样得多。
下图则是 effective rank(有效秩,衡量多样性的指标,满分 8)的对比:
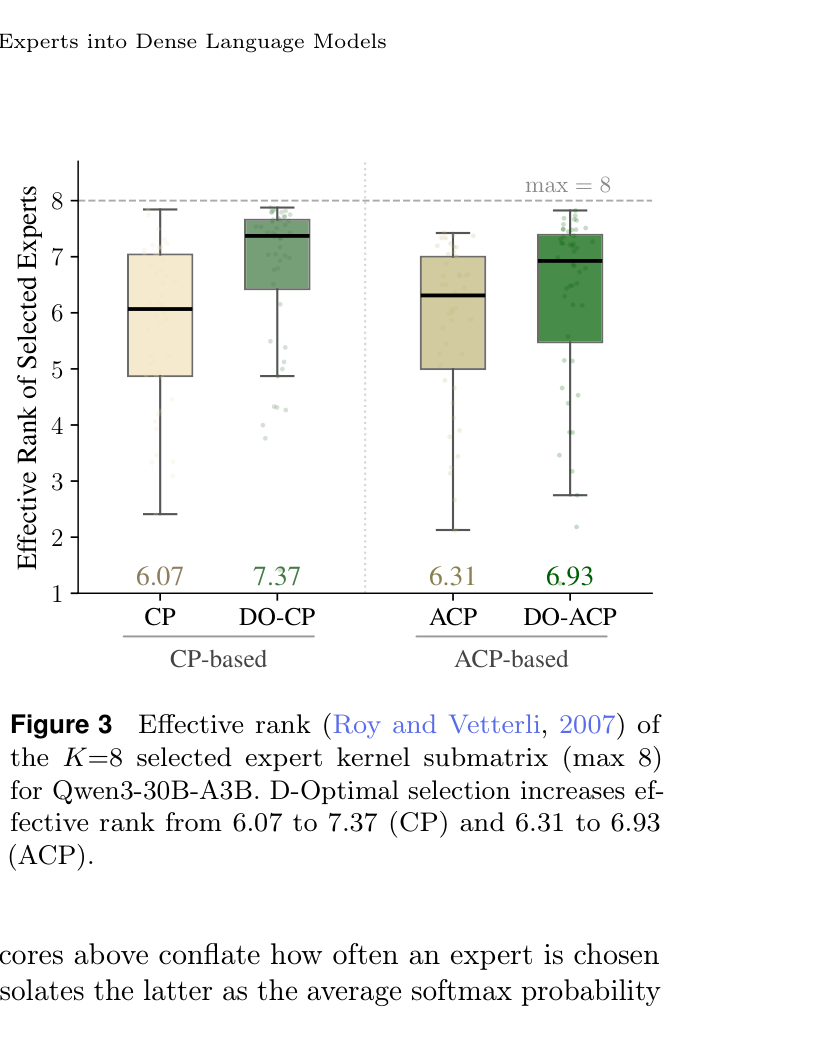
DO-Optimal 选出的 expert 集合有效秩从 6.07 提升到 7.37(基于 CP),或从 6.31 提升到 6.93(基于 ACP)。换句话说,它真的让 dense FFN 的每个”槽位”都发挥了不同的作用。
5.2 分组策略:五种方法,差距不大
把 K 个 expert 分成 k 组,每组合并为一个 FFN 块,共有五种策略:轮询(RR)、权重聚类(WC)、router 聚类(RC)、Anchor-based(AB)、输出聚类(OC)。
实验结论很干脆:分组策略对最终结果的影响远小于打分方法,只贡献约 1 pp 的差距。而且当 K=k 时(纯剪枝,不做合并),分组根本不重要——因为每组只有一个 expert,没有”组内平均”这回事。
5.3 Down-projection 缩放:弥合静态权重和动态路由的差距
MoE 里 router 是 token-dependent 的,而 dense FFN 的权重是静态的。怎么弥合?
论文用了两种简单的静态缩放方案:均匀缩放(每组权重 ×1/k)和比例缩放(按 expert 重要性分配权重)。实验发现差距很小,但打分越极端(比如 CP 选的 expert 概率差异大),比例缩放更好。
6. 实验结果:350 种配置的大扫描
这篇工作一口气跑了 350 种组合(7 打分 × 5 分组 × 2 缩放 × 5 个 K 值),主要在 Qwen3-30B-A3B 上做评测,然后在 DeepSeek-V2-Lite 和 GPT-OSS-20B 上做验证。
6.1 打分策略决定上限
如下图展示了各配置的下游任务平均准确率(0.3B token 蒸馏后):
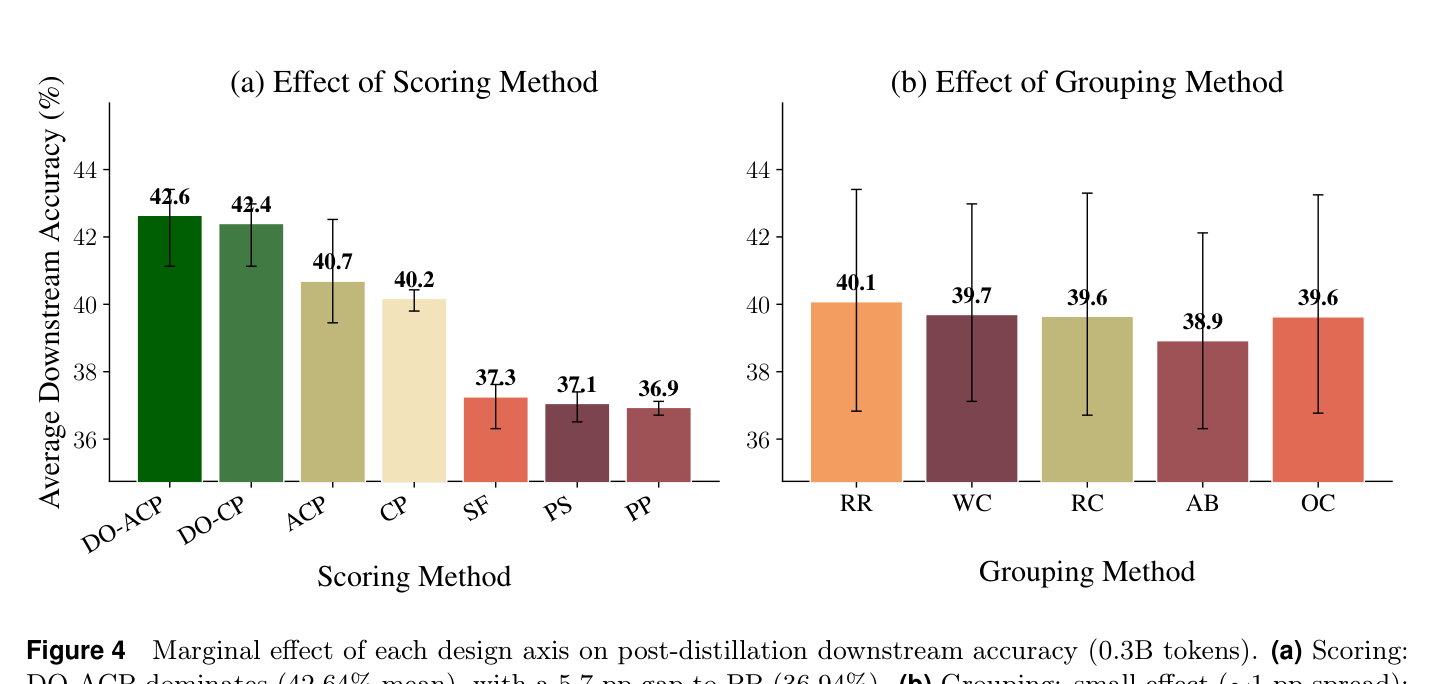
结论非常清晰:
- 最好的打分(DO-ACP)vs 最差的打分(PP),差距 5.7 pp
- 最好的分组(RR)vs 最差的分组(AB),差距只有 1.2 pp
打分是核心。
6.2 纯剪枝(K=k)胜过合并
最好的 7 个配置全部使用 K=8 的纯剪枝——就是选出最好的 8 个 expert,直接拼接,完全不做组内平均。虽然合并(K>k)在蒸馏前 PPL 更低,但蒸馏之后排名逆转:DO-ACP 在 K=8 下达到 43.41% 平均准确率,而 ACP×OC K=16 只有 40.50%。
为什么?直觉上,DO-ACP 选出的 expert 本来就已经足够多样,强行合并反而把有用的个性化信息抹掉了;而频率类方法选出一堆同质 expert,合并反而有助于去冗余。
6.3 和其他方法的对比
如下表,跟各种 baseline 的硬碰硬对比:
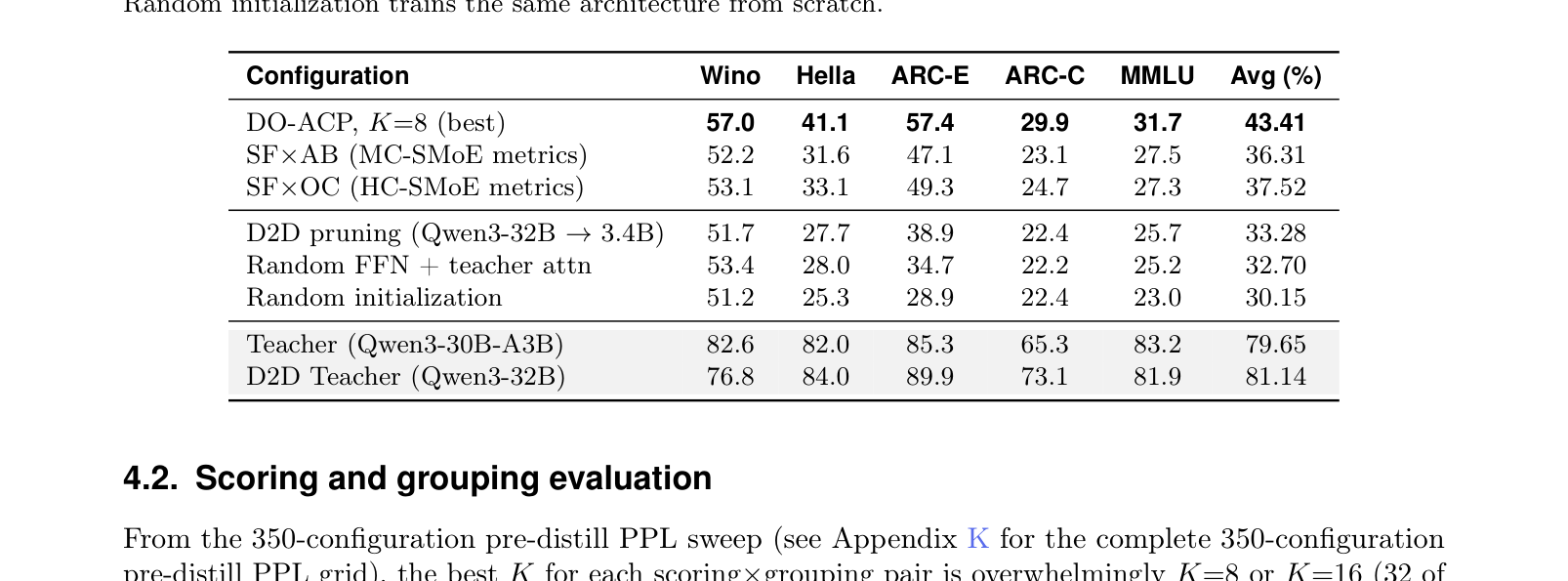
- DO-ACP(43.41%)vs MC-SMoE 打分方式(36.31%):+7.1 pp
- DO-ACP vs Dense-to-Dense 剪枝(33.28%):+10.1 pp
- DO-ACP vs Random FFN(32.70%):+10.7 pp
Dense-to-Dense 剪枝在这个压缩比(30B→3B)下几乎和随机初始化一样,只比 random 好 0.6 pp。这说明 dense 剪枝在极高压缩比下结构优势很弱,而 MoE expert 提供了一个强得多的初始化。
6.4 扩展训练:4B token 后效果
蒸馏量放大到 4B token,结论依然稳定:
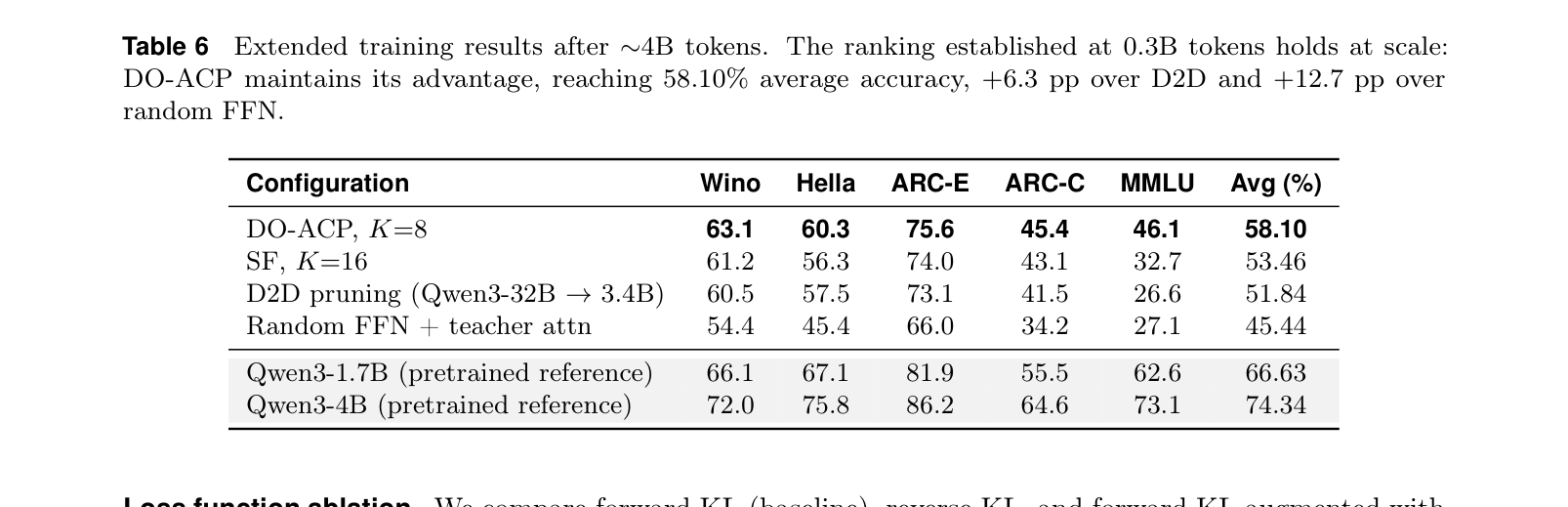
DO-ACP 达到 58.10% 平均准确率,比 D2D 剪枝(51.84%)高 +6.3 pp,而且训练速度还快 1.6 倍。
速度快这件事很重要:MoE teacher(Qwen3-30B-A3B)每个 token 只激活 3B 参数,而 Dense teacher(Qwen3-32B)需要跑全量 32B——MoE teacher 蒸馏更省算力。
验证损失曲线如下:
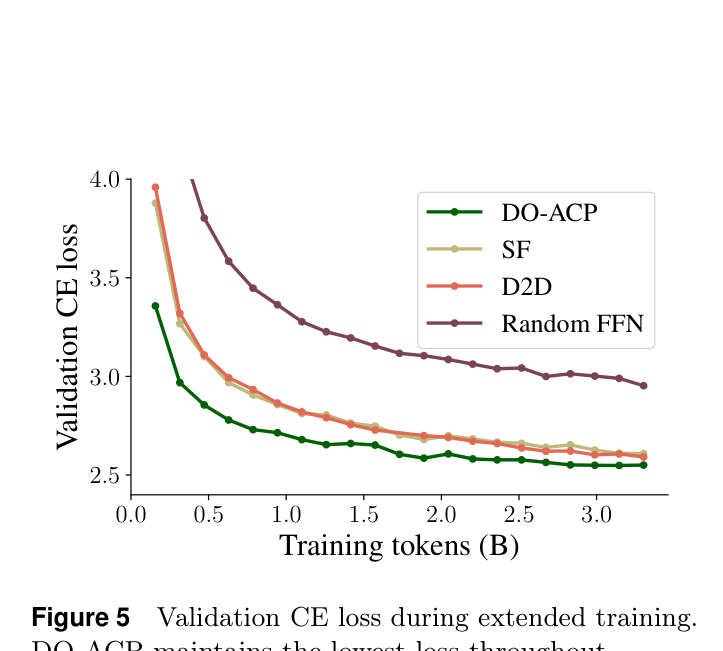
DO-ACP 在整个训练过程中始终保持最低的验证损失,优势没有随训练量扩大而消失。
6.5 定性分析:错误模式对比
论文还做了 MMLU chain-of-thought 的定性分析,用 Claude Opus 4.6 作为 judge 对 567 道题的回答做分类。
如下图展示了各模型的错误分布:
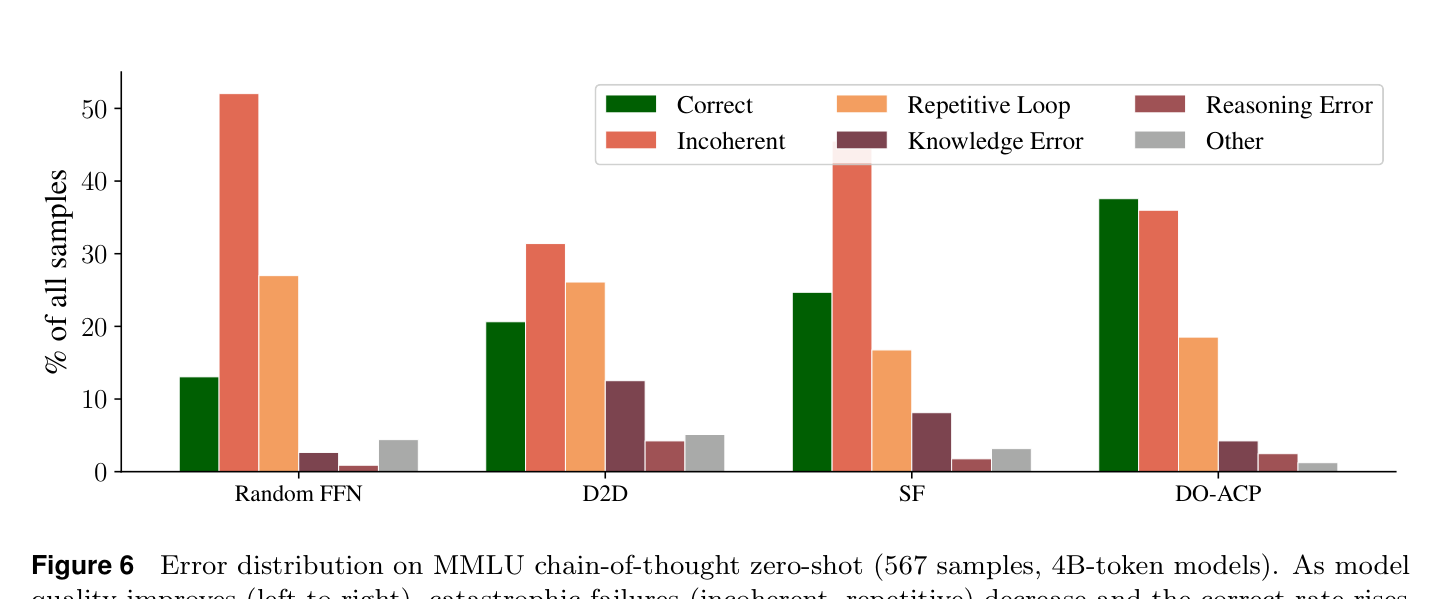
从左到右模型质量提升,灾难性失败(语无伦次、重复循环)比例下降。DO-ACP 的灾难失败率(54.5%)是所有方法中最低的,同时知识错误率也最低(4.2% vs D2D 的 12.5%)。
MMLU 人文类题目上差距最大:DO-ACP 达到 49.2%,SF 只有 25.4%,D2D 只有 19.2%。知识密集型任务下多样性打分的优势更明显——选出多样的 expert 确实更好地保留了世界知识。
6.6 跨模型验证
在 DeepSeek-V2-Lite 和 GPT-OSS-20B 上的验证结果:
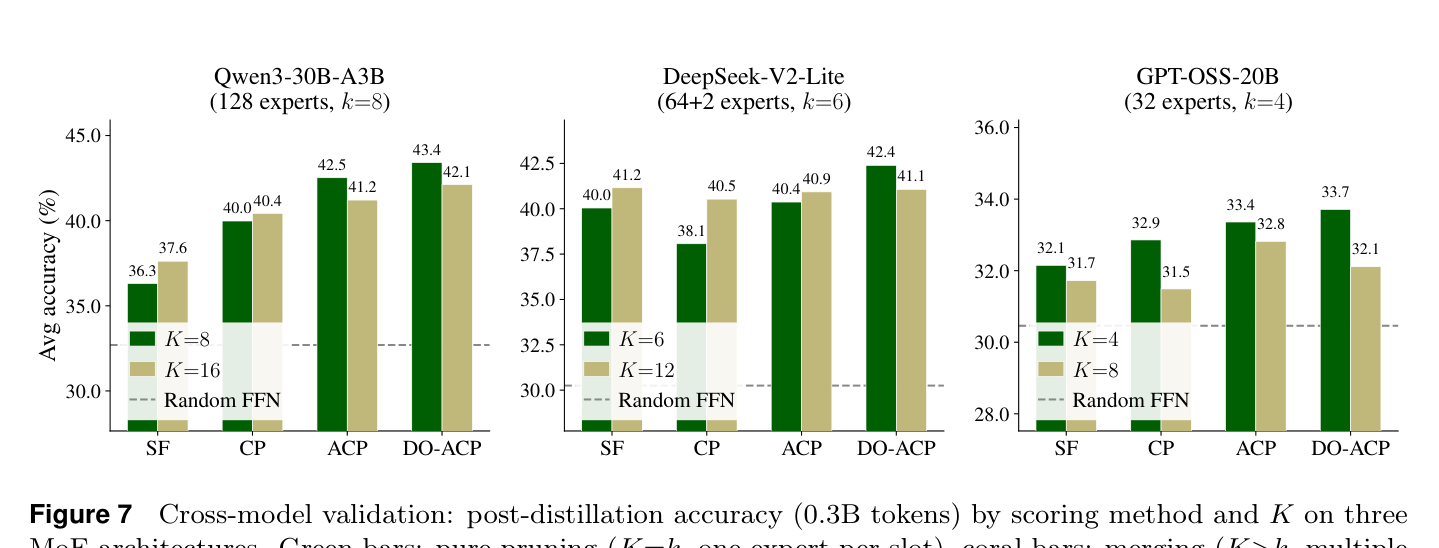
核心结论在三个模型上都成立:DO-ACP 最好,纯剪枝(K=k)最好。但有一个有趣的规律:expert 池越大,多样性打分的优势越明显。
- Qwen3(128 experts):最好 vs 最差打分差 7.1 pp
- DeepSeek-V2-Lite(64 experts):差距 4.3 pp
- GPT-OSS-20B(32 experts):差距 1.6 pp
直觉上也说得通:expert 越多,高质量 expert 之间冗余越严重,多样性筛选的价值越大;expert 数少时每个 expert 覆盖的 token 模式更不一样,独立打分也能选出比较多样的集合。
7. 这个工作值不值得?前景如何?
说几点个人判断。
7.1 内存问题确实是真问题
这不是为了发论文而造的问题。MoE 在实际部署中内存占用确实是卡脖子的点——尤其是单卡 serving、边缘设备、on-device 推理。把 30B MoE 变成等效 3B dense,这个需求非常真实。
7.2 MoE 是更好的起点
这篇论文最重要的发现不是某个具体方法,而是MoE-to-dense 比 Dense-to-dense 剪枝强得多这个事实。
在相同参数量下,MoE 的 expert 天然提供了更好的初始化:每个 expert 虽然参数少,但它们捕捉了不同的 token 模式,把它们拼在一起就已经构成了一个质量不错的 dense FFN,蒸馏只是锦上添花。而 dense 剪枝从一个”大而全”的网络暴力剪到小,在极高压缩比下结构信息丢失严重。
7.3 D-Optimal 的思路有普适性
把 D-optimality(实验设计里的经典准则)用到 expert 选择上,是个挺优雅的迁移。它本质上是在问”我用有限的 budget,怎么选一个信息量最大的子集”——这个问题在 active learning、coreset 选取、模型压缩里都有对应。
这篇工作的理论部分也是认真的——证明了 greedy 选择的 (1-1/e) 近似比,有冗余时独立打分会失败的反例,以及有限样本下的稳定性保证。不是随便套了个公式。
7.4 局限和还没解决的问题
说实话,这篇工作还有几个明显的限制:
压缩比很高:Qwen3-30B-A3B → 3.3B,压缩了近 10 倍。4B token 蒸馏之后 58.10% 的均分,而同规模 Qwen3-1.7B(比这个学生还小)预训练后能到 66.63%。差距还有 8.5 pp。如果目标是部署,还需要更多的蒸馏数据。
蒸馏量有限:4B token 对于 LLM 来说仍然是很少的量。论文自己也承认,需要扩到数十亿 token 级别才能真正评估质量天花板。
专家池大小影响收益:GPT-OSS-20B(32 experts)上 MoE-to-dense 相对 random baseline 只有 +3.7 pp,而 Qwen3 上有 +10.7 pp。如果 MoE 的 expert 数本来就不多,转换成 dense 的优势就没那么显著了。
合并策略还可以优化:当前方案把合并权重和打分权重绑定,论文承认解耦可能更好。
7.5 这个方向有没有前景?
我觉得是有的,但需要看清楚它解决的是哪个问题。
它不是想训练出一个最强的 3B 模型——从头预训练肯定能做得更好。它解决的是”我已经有了一个训练好的强 MoE,我不想重新训,但我需要一个能跑在内存受限环境里的 dense 版本“这个问题。
这个场景在 on-device、私有部署、边缘计算场景下非常常见。而且随着 MoE 成为旗舰模型的标配,MoE-to-dense 的”原材料”会越来越多——每一个 MoE 都是潜在的 dense 小模型工厂。
比较有意思的后续方向:
- 能不能在蒸馏时引入更多数据(domain-specific)来做领域适配?
- MoE-to-dense 和 LoRA 微调结合,能不能进一步弥合质量差距?
- expert 粒度更细时(如 DeepSeek 的 fine-grained MoE),转换策略需要怎么调整?
8. 总结
一句话:把 MoE 剪成 dense,打分方法是核心,多样性比频率更重要,最终产物比 Dense-to-Dense 剪枝强 +6.3 pp,还快 1.6 倍。
这篇工作做的事情很朴素——系统地扫了一遍所有可能的设计选择,找出哪个因素最关键,然后把结论在多个模型上验证了。没有花哨的创新,但结论实在,实验扎实。
MoE 的内存瓶颈是整个行业的核心矛盾之一,MoE-to-dense 提供了一个新的思路。值得关注。
欢迎评论区交流,如果有踩过类似坑的也欢迎分享。
不排除穿插了个人私货哈哈,有问题欢迎指出