ReMoE:只动 Router 就让 MoE 推理快 2 倍?这才是端侧 MoE 部署该有的姿势
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

ReMoE:只动 Router 就让 MoE 推理快 2 倍?这才是端侧 MoE 部署该有的姿势
原文:ReMoE: Boosting Expert Reuse through Router Fine-Tuning in Memory-Constrained MoE LLM Inference
1. 前言
你有没有想过一个问题:MoE 模型的”稀疏激活”理论上是推理效率的银弹——每个 token 只用 Top-K 个 expert,计算量小得很。但当你把 MoE 模型塞到手机/边缘设备上的时候,为什么体验反而比同等计算量的 dense 模型还卡?
答案是内存瓶颈。
以 DeepSeek-V2-Lite 为例,它有 64 个 routed expert,每个 token 选 6 个。但如果你设备的快速内存只能装下 6 个 expert 的权重,那每生成一个 token,只要选中的 expert 集合跟上一步不一样,就得从慢速存储(UFS/NVMe SSD)把新 expert 搬进来。搬一次就是几百 MB 的权重 I/O。
这也是整个 MoE 端侧部署的核心矛盾:模型的稀疏激活降低了计算量,但 expert 的频繁切换导致 I/O 成了新的瓶颈。
今天想和大家聊聊这篇被 ICML 2026 接收的工作——ReMoE。它的思路非常优雅:不改模型结构、不改推理引擎、不加运行时策略,只 fine-tune router(gate 参数),就让 MoE 在边缘设备上的推理速度提升 1.77–1.99×。
2. 问题定义:MoE Offloading 的 Locality Gap
2.1 端侧 MoE 推理的困境
先交代下背景。在内存受限的设备上跑 MoE 模型,通常只有少量 expert 能常驻快速内存(比如 GPU 显存、DRAM),剩下的 expert 要从慢速存储(UFS 4.0、NVMe SSD)按需加载。这种模式叫 expert offloading。
问题是:标准 MoE 训练时用了 load-balancing loss,目的是让 token 尽量均匀分配给所有 expert,防止训练时 expert parallelism 出问题。这个优化目标在训练时很合理,但到了内存受限的单请求推理场景,就变成了灾难——router 被训练得尽可能”散”地选 expert,导致相邻 token 几乎不复用同一批 expert。
如下图,对比了 Baseline 和 ReMoE 的 expert 访问模式:
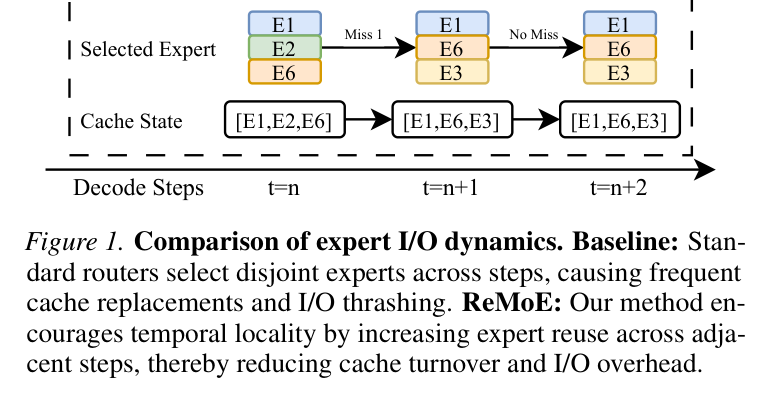
左边是标准 router 的行为:每一步选的 expert 集合和上一步差异很大,cache 被频繁淘汰替换,产生大量 I/O thrashing。右边是 ReMoE:相邻步之间 expert 复用率大幅提高,cache 替换频率下降,I/O overhead 显著减少。
2.2 量化指标:EOR
为了量化这个”缓存友好度”,论文定义了两个指标:
Instantaneous Reuse (IR):相邻两步 expert 集合的重叠比例:
\[IR_t = \frac{|E_t \cap E_{t-1}|}{K}\]Expert Overlap Ratio (EOR):整个序列的平均 IR:
\[EOR = \frac{1}{T-1}\sum_{t=2}^{T} IR_t\]EOR 越高,意味着 cache miss 越少。论文还给出了一个关键命题:在标准 LRU cache(容量 $C \geq K$)下,平均 expert fetch 次数的上界是 $K(1 - EOR)$。所以提高 EOR,就是直接减少 I/O。
2.3 训练-推理的 Mismatch
如下图,可以清楚看到 baseline router 的 routing trajectory:

这是 DeepSeek-V2-Lite 第 21 层在 teacher forcing 下的 expert 选择轨迹。Baseline(左)可以看到短暂的复用,但频繁切换。ReMoE(右)通过 gate-only fine-tuning 把这些短暂的复用”拉长”了,形成明显的水平条纹——同一个 expert 被连续多步选中。
重点:输入是固定的(teacher forcing),所以差异完全来自 routing policy 的改变,不是生成内容不同。
3. ReMoE 方法详解
3.1 总览:冻结一切,只调 Gate
ReMoE 的核心思路极其简洁:冻结所有非 router 参数(embedding、attention、expert FFN 全部不动),只 fine-tune gate 参数 $\theta_{\text{gate}}$。
如下图展示了 ReMoE 在单个 MoE 层内的工作流程:
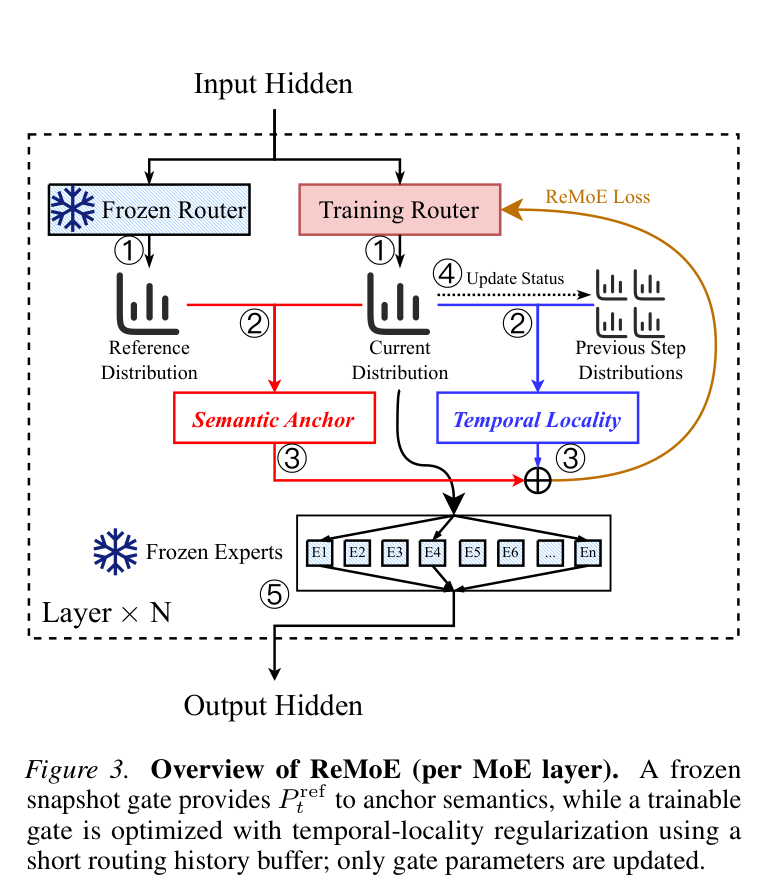
具体步骤:
-
Step 1:给定当前 hidden state $h_t$,同时跑两个 router——一个是冻结的 reference router(用预训练权重 $\theta^0_{\text{gate}}$ 的 FP32 快照),产出 $P^{\text{ref}}_t$;一个是可训练的 router,产出 $P_t$。
- Step 2:用两个信号优化可训练 router:
- Semantic Anchor(Trust-KL):让 $P_t$ 不要偏离 $P^{\text{ref}}_t$ 太远
- Temporal Locality Signal:让 $P_t$ 倾向于复用最近几步选过的 expert
-
Step 3-4:记录当前选择的 Top-K expert 到历史 buffer,供后续步骤使用
- Step 5:正常执行 Top-K expert,和 baseline 完全一致
关键洞察:训练时多了 reference router 的前向计算,但部署时完全没有任何额外开销——用的就是标准 MoE 推理图,只是 gate 权重被替换成了 fine-tune 后的版本。
3.2 训练目标
总目标函数:
\[\mathcal{L} = L_{\text{CE}} + \lambda_{\text{KL}} L_{\text{Trust}} + \alpha_t L_{\text{Loc}}\]其中 $L_{\text{CE}}$ 是标准 next-token cross entropy,$L_{\text{Trust}}$ 是语义锚点,$L_{\text{Loc}}$ 是时域局部性正则,$\alpha_t$ 是 warmup 系数。
注意一个细节:训练时把标准 MoE load-balancing loss 关掉了($L_{\text{aux}} = 0$),因为 load-balancing 的目标是让 expert 使用尽可能均匀——这和 cache locality 的目标直接冲突。
3.3 Semantic Anchor:Trust-KL Loss
说人话就是:不能让 router 为了提高复用率就乱飘,得”锚住”预训练学到的路由语义。
具体做法是用 KL 散度约束当前 $P_t$ 和冻结参考分布 $P^{\text{ref}}_t$ 的距离:
\[L_{\text{Trust}} = \frac{1}{T}\sum_{t=1}^{T} D_{\text{KL}}(P_t \| \text{stop\_gradient}(P^{\text{ref}}_t))\]这里用 stop_gradient 是因为 $P^{\text{ref}}_t$ 来自冻结分支,不需要梯度回传。
为什么选 KL 而不是 L2 之类的?因为 routing 本身就是概率分布,KL 散度天然适合衡量分布偏移,而且对高概率 expert(实际会被 Top-K 选中的)赋予更大权重。
3.4 Temporal Locality Regularization
这是 ReMoE 的核心技术贡献,由四个子项组成:
\[L_{\text{Loc}} = \lambda_{\text{Reuse}} L_{\text{Reuse}} + \lambda_{\text{Smooth}} L_{\text{Smooth}} + \lambda_{\text{Lag}} L_{\text{Lag}} + \lambda_{\text{WS}} L_{\text{WS}}\]逐一解释:
① Reuse Loss $L_{\text{Reuse}}$——直接提高短期复用
先定义”reuse mass”:当前步分配给上一步选中 expert 的概率质量:
\[m_t = \frac{1}{K}\sum_{k \in \tilde{E}_{t-1}} P_t(k)\]其中 $\tilde{E}{t-1} = \text{stop_gradient}(E{t-1})$,即上一步的 Top-K 集合作为固定目标。然后对整个序列取平均并取负对数:
\[\rho = \frac{1}{T-1}\sum_{t=2}^{T} m_t, \quad L_{\text{Reuse}} = -\log(\rho + 10^{-8})\]直觉上就是:鼓励当前步把更多概率分配给上一步用过的 expert,增加复用的可能性。
② Smoothness Loss $L_{\text{Smooth}}$——抑制高频抖动
用对称 KL 散度惩罚相邻步分布的突变:
\[L_{\text{Smooth}} = \frac{1}{T-1}\sum_{t=2}^{T} \text{SymKL}(P_t, P_{t-1})\]如果 $P_t$ 相邻步变化越小,Top-K 边界被跨越的可能性就越低。注意这里没有 stop_gradient,因为希望双向约束:$P_t$ 要靠近 $P_{t-1}$,反过来也一样。
③ Lagged Inertia Loss $L_{\text{Lag}}$——抑制慢漂移
只看相邻步可能忽略”温水煮青蛙”的漂移——每步变化很小但累积起来 expert 集合完全不同了。用一个 lag set $\mathcal{D} = {1, 2, 4, 8, 16}$ 对齐多个历史步:
\[L_{\text{Lag}} = \frac{1}{T-1}\sum_{t=2}^{T} \frac{1}{|\mathcal{D}|}\sum_{d \in \mathcal{D}, t-d \geq 1} \text{SymKL}(P_t, P_{t-d})\]④ Working-Set Compression Loss $L_{\text{WS}}$——压缩局部工作集
前三个都不能防止 router 在一个稍大的窗口内访问太多不同 expert。这个 loss 对窗口内平均分布做熵最小化:
\[\bar{P}_b = \frac{1}{W}\sum_{j=1}^{W} P_{(b-1)W+j}, \quad L_{\text{WS}} = \frac{1}{n}\sum_{b=1}^{n} H(\bar{P}_b)\]鼓励局部窗口内只依赖少量 expert,让 routing 适配小 cache 容量。
4. 实验设置
- 模型:DeepSeek-V2-Lite(15.7B 总参数,2.4B 激活参数,64 routed expert + 2 shared expert,Top-6 routing)
- 数据:OpenHermes-2.5,100K 样本训练,1K 验证
- 训练:2000 步,AdamW,lr=5e-5,序列长度 2048,micro-batch=1 + grad_accum=8
- 超参:$\lambda_{\text{KL}}=0.45$,$\lambda_{\text{reuse}}=0.2$,$\lambda_{\text{smooth}}=0.05$,$\lambda_{\text{lag}}=0.05$,$\lambda_{\text{ws}}=0.01$
- 训练成本:单张 80GB GPU 约 7.9 小时。一次性成本,推理时零开销。
5. 实验结果
5.1 Routing Locality 提升
如下图展示了定量结果:
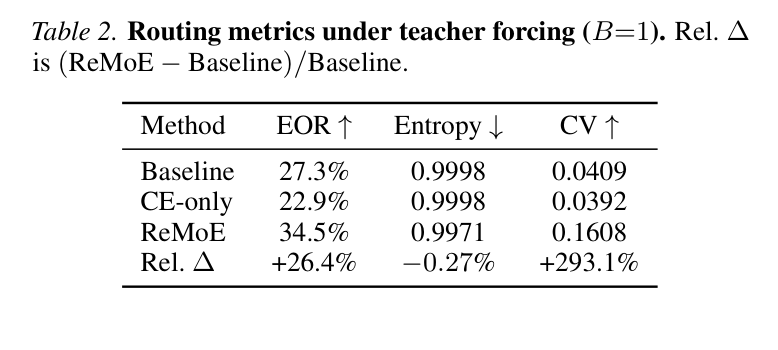
核心数字:
- EOR 从 27.3% 提升到 34.5%,相对提升 +26.4%
- 作为对照,CE-only(用相同数据和设置只优化交叉熵,不加 locality loss)的 EOR 反而降到了 22.9%——说明单纯 continued fine-tuning 不仅没用,反而有害
- Routing entropy 从 0.9998 降到 0.9971(微降),负载均衡 CV 从 0.04 升到 0.16(可接受,因为 B=1 场景没有 expert parallelism)
- 序列级 expert 多样性几乎不变(64.000 → 63.997),说明 concentration 是 step-level 的局部集中,而不是全局 routing collapse
5.2 Cache 效率提升

在 LRU cache 下,不同容量 $C$ 的结果:
- $C=6$(和 Top-K 匹配):uHR 从 0.3187 提升到 0.3687(+15.7%),#uMiss 从 0.87M 降到 0.81M(-7.3%)
- $C=12$:uHR 从 0.4519 提升到 0.5035(+11.4%),#uMiss 从 0.70M 降到 0.63M(-9.4%)
- 在 LFU、FIFO、甚至 Belady 最优策略下都有类似提升
5.3 真实系统评测
vLLM Expert Offloading(RTX 3090)
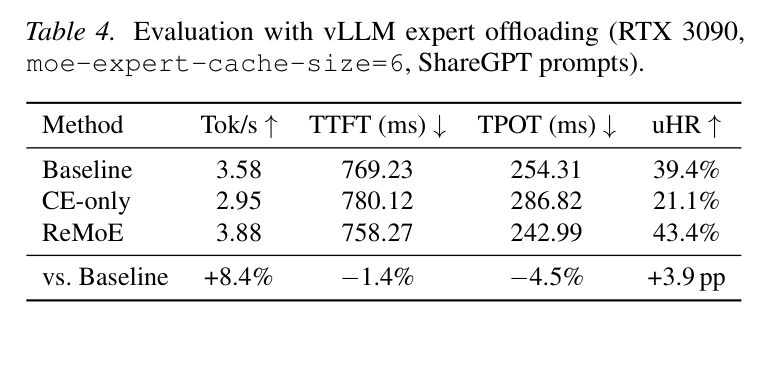
- 输出吞吐从 3.58 提升到 3.88 tok/s(+8.4%)
- TPOT 从 254.31ms 降到 242.99ms(-4.5%)
- uHR 从 39.4% 提升到 43.4%
- CE-only 反而比 baseline 还差(2.95 tok/s),再次证明 locality loss 的必要性
Jetson Orin NX 16GB 边缘设备(llama.cpp + NVMe SSD)
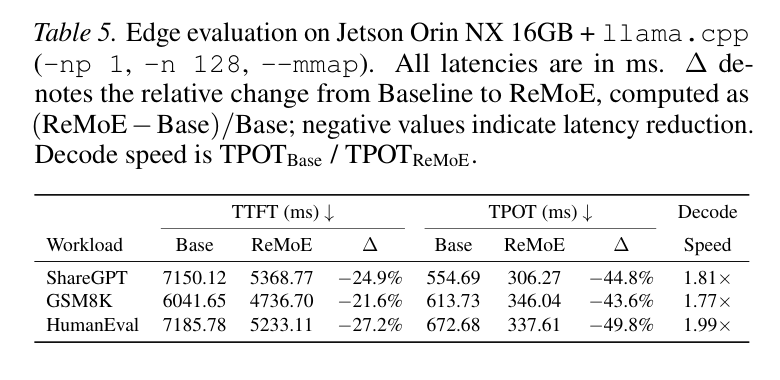
这才是 ReMoE 真正大显身手的场景——SSD 后端的 expert miss 代价更高:
- ShareGPT:TPOT 从 554.69ms 降到 306.27ms,减少 44.8%,decode speedup 1.81×
- GSM8K:TPOT 从 613.73ms 降到 346.04ms,减少 43.6%,decode speedup 1.77×
- HumanEval:TPOT 从 672.68ms 降到 337.61ms,减少 49.8%,decode speedup 1.99×
细思极恐:只改了 router 的权重,没动任何其他东西,推理速度翻倍。
5.4 模型能力保持
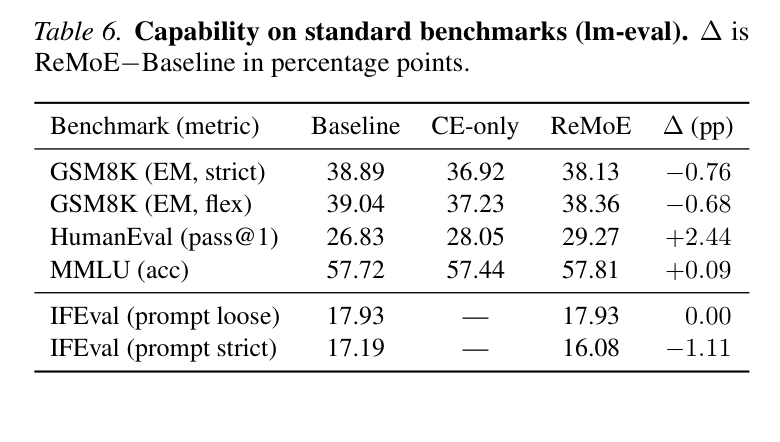
- MMLU:57.72 → 57.81(+0.09 pp),几乎不变
- HumanEval:26.83 → 29.27(+2.44 pp),反而提升了
- GSM8K(strict):38.89 → 38.13(-0.76 pp),在误差范围内
- IFEval:基本持平
结论:locality gain 不以牺牲模型能力为代价。
6. 消融实验
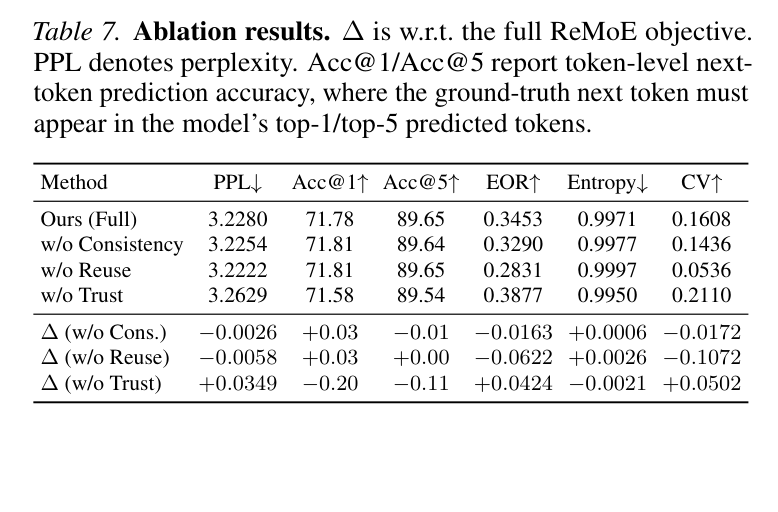
消融研究逐一移除各组件,结论清晰:
| 变体 | EOR | PPL | 解读 |
|---|---|---|---|
| Full ReMoE | 0.3453 | 3.2280 | 完整方法 |
| w/o Reuse | 0.2831 | 3.2222 | EOR 暴跌 -0.062,Reuse 是核心驱动力 |
| w/o Consistency | 0.3290 | 3.2254 | EOR 小降 -0.016,辅助稳定作用 |
| w/o Trust | 0.3877 | 3.2629 | EOR 最高但 PPL 劣化,Trust 防止过度集中 |
三个关键发现:
- Reuse loss 是 locality 提升的主力:去掉它 EOR 直接回到接近 baseline 水平
- Consistency terms(Smooth + Lag + WS)起辅助稳定作用:主要抑制 routing 抖动和慢漂移
- Trust-KL 是质量守门员:没有它 EOR 能更高(0.3877),但 PPL 开始劣化(3.2280 → 3.2629),routing 过度集中(CV: 0.16 → 0.21)
7. 超参敏感性

论文做了 $\lambda_{\text{reuse}}$ 和 $\lambda_{\text{KL}}$ 的 sweep:
-
增大 $\lambda_{\text{reuse}}$:reuse score 从 0.283 线性增长到 0.370,同时 trust deviation 也增大(0.0098 → 0.0667)。但 PPL 和 Acc@1 在整个范围内保持稳定(PPL ≈ 3.22-3.24),说明在合理范围内提高复用不影响能力。
-
增大 $\lambda_{\text{KL}}$:trust deviation 从 0.308($\lambda_{\text{KL}}=0$)降到 0.016($\lambda_{\text{KL}}=0.7$),但 reuse 也从 0.386 降到 0.321。$\lambda_{\text{KL}}=0.45$ 是一个甜点:既有强复用增益,drift 也可控。
8. 泛化性验证
论文不只在 DeepSeek 上做了验证:
-
Qwen1.5-MoE-A2.7B:同样的 recipe,EOR 从 0.1695 提升到 0.2156(+27.2%),下游 benchmark 保持(MMLU 61.10 → 61.20,HumanEval 35.37 → 35.98)
-
Iluvatar BI-V150 GPU(国产卡):EOR +25.0%,prefill 吞吐 2.47×,decode 吞吐 1.54×
-
华为昇腾 910B3 NPU + 鲲鹏 920:EOR +30.2%,生成吞吐从 4.3 提升到 4.8 tok/s(+11.6%)
跨模型、跨硬件平台都能 work,这说明方法的 generalization 不错。
9. 与推理时 Cache-Aware Rerouting 的比较
一个自然的问题:为什么不在推理时直接给 cache 里已有的 expert 加分?
论文做了对比实验:在推理时给 cached expert 的 router score 加一个 bonus $\beta$:
- $\beta=1.0$:uHR 41.66%,但 PPL 从 6.35 飙到 10.60
- $\beta=4.0$:uHR 63.88%,但 PPL 炸到 3607.92——模型直接废了
而 ReMoE 的 learned router 不加任何推理时干预,uHR 23.74%,PPL 6.35——在一个更安全的 quality-locality trade-off 点上。
更有趣的是,两者可以叠加:ReMoE + mild rerouting($\beta=0.5$)比 Baseline + 同等 rerouting 效果更好(uHR 34.07% vs 32.07%,PPL 6.51 vs 6.97)。
10. 个人 Take
这篇论文让我印象深刻的几点:
-
问题定义精准:把 MoE 训练时的 load-balancing 和部署时的 cache locality 之间的 mismatch 抽出来,定义为一个可优化的问题。这个 insight 本身就很有价值。
-
方法极其轻量:只动 gate 参数,2000 步,7.9 小时,一张卡。推理时零开销。这种”训练-部署”分离的思路非常工程友好。
-
效果惊人:在 Jetson 上接近 2× 的 decode speedup,而且没有牺牲模型能力。这在 MoE efficiency 方向是很少见的”白捡”收益。
-
与现有系统正交:ReMoE 改的是上游 routing trace,和下游的 cache 策略(LRU/LFU)、prefetch 策略、推理时 rerouting 都是互补的,可以叠加。
如果你在做 MoE 模型的端侧部署,或者对 expert offloading 系统感兴趣,这篇值得仔细读。代码和 checkpoint 已开源:https://github.com/BUAA-OSCAR/ReMoE。
欢迎评论区交流 / 指出问题。