训练一个「会管技能库」的 AI——SkillOS 让 agent 真正越用越强
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

训练一个「会管技能库」的 AI——SkillOS 让 agent 真正越用越强
原文:SkillOS: Learning Skill Curation for Self-Evolving Agents(Google Cloud AI Research + UIUC + MIT)
1. 前言
你有没有想过,你训练好的 LLM agent,跑了几百个任务之后,它变聪明了吗?
大概率没有。
现在大多数 agent 系统本质上是一次性的:每次来个新任务,就从头开始想,用完即走,上次踩过的坑下次照踩不误。这在 streaming setting 下简直是灾难——任务一个接一个到来,agent 却永远是个忘性大的新手。
要让 agent 真正”越用越强”,核心是 self-evolution:能从历史交互中提炼出可复用的知识,并在未来用上。这个东西叫 skill(技能)——把做过的经验抽象成结构化的 Markdown 文件,以后遇到类似任务直接检索用起来。
但问题来了:谁来管理这些技能?如何决定什么时候 insert 新技能、什么时候 update 旧技能、什么时候把没用的技能 delete 掉?这个过程叫 skill curation,而且这才是整个 self-evolving agent 系统最难的部分。
今天这篇来自 Google Cloud AI Research 的工作 SkillOS,专门解决这个问题,思路很清晰,实验也很扎实,值得聊聊。
2. 现有方法为什么不够用?
大致有三类现有做法:
- 人工维护技能库(比如 Anthropic 官方搞的 skills repository):太贵,无法 scale,凡人哪有那么多时间;
- 基于 prompt/规则的自动 curation(比如 aMem、Alita 等):靠固定规则,缺乏对 executor 实际表现的反馈,不能自适应;
- 短期 RL 训练:有人开始用 RL 来优化 skill 操作,但局限在 short task stream 上,信号太稀疏,很难学到复杂的长期 curation 策略(比如什么时候该删一个旧技能)。
核心矛盾:skill curation 的好坏,要等到未来好几个任务之后才能看出来——feedback 是 indirect 且 delayed 的。传统 RL 方法很难高效利用这种信号。
这就是 SkillOS 要搞定的问题。
3. SkillOS 怎么做的?
3.1 系统架构:解耦 Executor 和 Curator
SkillOS 的核心思路是解耦:
- Agent Executor(冻结):负责执行任务,从 SkillRepo 里检索相关技能(用 BM25),然后用 ReAct 或 CoT 来解题;
- Skill Curator(可训练):负责在每个任务完成后,根据 executor 的 trajectory,更新 SkillRepo——可以
insert_skill、update_skill、delete_skill;
如下图,整个系统跑在 streaming setting 下,任务一个接一个来,executor 拿技能解题,curator 看完再更新技能库:
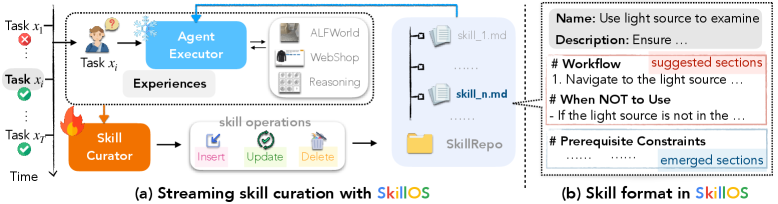
技能格式跟 Anthropic 的 SKILL.md 一样:一个 Markdown 文件,YAML frontmatter 存名字和描述,正文写可复用的 workflow、约束、注意事项。随着训练推进,这些技能文件还会自动长出新的结构(比如 Failure Handling、Conditional Branches),越来越细。
3.2 训练配方:Grouped Task Streams + Composite Rewards
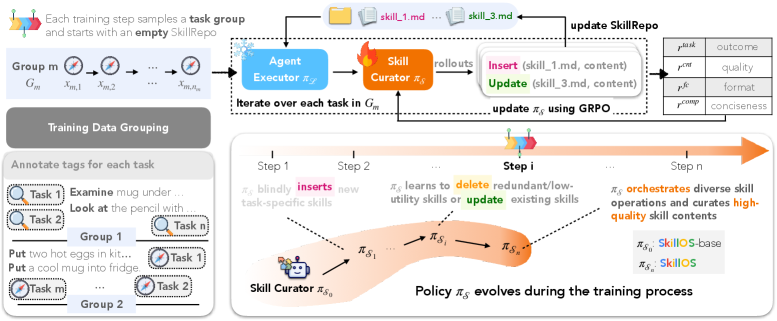
SkillOS 的核心贡献是一套 RL 训练 recipe,两个关键设计:
设计一:Grouped Task Streams
不是拿单个任务来训练,而是把相关任务打成一组(group)——基于任务的 skill-relevant attributes(主题、required skills、常见坑等)来聚类。训练时,每组任务顺序执行,前面任务更新 SkillRepo,后面任务来评估这些技能到底有没有用。
这就把 delayed feedback 转化成了可用的学习信号:curator 操作的好坏,由后续相关任务的成败来评判。
设计二:Composite Rewards
四个信号合在一起:
\[r = r_{\text{task}} + \lambda_f r_{\text{fc}} + \lambda_u r_{\text{cnt}} + \lambda_c r_{\text{comp}}\]- $r_{\text{task}}$:后续任务的平均成功率(最核心的信号)
- $r_{\text{fc}}$:function call 是否有效执行
- $r_{\text{cnt}}$:技能内容质量(用 Qwen3-32B 作为外部 judge)
- $r_{\text{comp}}$:压缩率,鼓励 curator 提炼精华而不是复制粘贴 trajectory
用 GRPO(Grouped Reward Policy Optimization)来优化,base model 是 Qwen3-8B,16 张 H100 训练约 3-5 天。整个训练流程如下图:
4. 实验结果
4.1 主实验
在 ALFWorld(家居任务 agent)、WebShop(购物 agent)和数学推理(AIME24/25、GPQA)上测试。
几个关键结论(以 Qwen3-8B 作为 executor 为例):
1. SkillOS 全面碾压 baseline
- ALFWorld 平均成功率 61.2%,比最强 baseline ReasoningBank 的 55.7% 高 +5.5 个点,比无记忆 baseline 的 47.9% 高 +13.3 个点;
- Gemini-2.5-Pro 作为 executor:从 66.4% 提升到 80.2%,同样大幅领先;
2. 8B 训练过的 curator 打赢 Gemini-2.5-Pro 直接做 curator
这是最有意思的结论之一。SkillOS-gemini 用 Gemini-2.5-Pro 直接做 skill curator(不经 RL 训练),在 Qwen3-8B executor 下只有 50.7%;而 RL 训练过的 Qwen3-8B curator 达到 61.2%。
单纯模型强不等于 skill curation 做得好——frontier model 生成的技能可能和 executor 的使用习惯对不上,而 RL 训练让 curator 学会了”为 executor 量身定制”。
3. 效率也提升了
interaction steps 从 21.1 降到 18.9,技能帮 agent 走了捷径,不用重复摸索。
4.2 跨任务泛化
如下图,SkillOS 在跨 task domain 迁移上也表现不错:
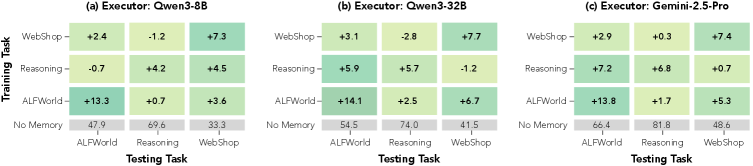
从 reasoning 任务上学出来的 curator,迁移到 ALFWorld 和 WebShop 上,提升幅度甚至比在原任务上训练的 baseline 还强(+13.3、+7.3)。原因很直觉:reasoning 学到的是更抽象、更 meta 的策略(分解、验证、规划),天然可以复用到其他任务类型里。
5. 为什么有效?几个有意思的分析
5.1 Ablation:grouped task stream 最关键
如下图的消融实验:
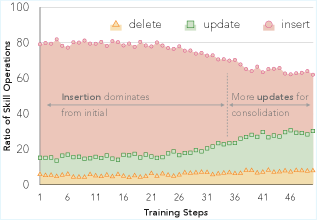
- 去掉 content quality reward:SR 从 61.2 跌到 58.6;
- 去掉 compression reward:SR 从 61.2 跌到 60.0;
- 去掉 grouping,改成随机序列:SR 直接跌到 57.3——这是最大的单点损失;
Grouped task stream 是整个设计的基石,没有它,RL 信号就变稀疏了,curator 很难学到长期 curation 策略。
5.2 Curator 行为演化
训练开始时,curator 大量 insert(建库),随着训练推进,update 比例不断上升,insert 下降——模型从”疯狂存技能”变成了”精炼、迭代技能”(见图 4)。delete 始终很少但在增长,说明 compression reward 在慢慢起作用。
5.3 技能内容本身也在进化
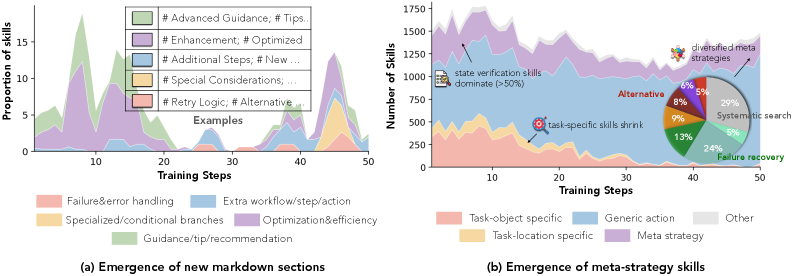
- 早期 SkillRepo:skill 文件里充斥着 “# Additional Guidance”、”# Tips” 这类泛泛而谈的章节;
- 训练后期:涌现出 “# Failure Handling”、”# Conditional Branches” 这类针对具体执行场景的章节;
- 技能类型分布也从 task-specific 向 meta-strategy 偏移:包括 failure recovery、systematic search、state verification 等更通用的高层策略。
SkillRepo 不只是在积累技能,它在演化出认知架构。
5.4 Skill 使用情况
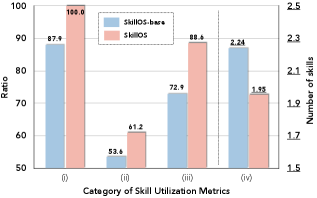
SkillOS 让 agent 在所有测试样本上都至少使用了一个技能,成功率更高,技能覆盖率更大,但每个样本用到的技能数反而更少——靠更精准的技能选择,不靠堆更多 context。
6. 几点个人 take
首先,这篇工作的思路很正,把 skill curation 单独抽出来训练,是非常 modular 的做法。解耦 executor 和 curator 的好处是显而易见的:executor 可以换(Qwen3-8B、Qwen3-32B、Gemini-2.5-Pro 都能用),curator 只训练一次。
不过有几点值得细想:
-
检索机制还是 BM25——作者自己也在 limitation 里提了,dense retrieval 或 learned retriever 可能更好。技能库大了之后,BM25 的匹配质量会成为瓶颈;
-
技能是 flat Markdown,不支持层次结构和可执行 script。Anthropic 原版 SKILL.md 是支持子技能引用和代码附件的,现在这个简化版能学到的上限有限;
-
Curator 和 Executor 没有联合训练。目前 executor 是冻结的,curator 只能通过写好技能来间接影响 executor。如果两个一起优化,理论上能更好地对齐,但训练代价会大很多;
-
Multi-agent shared memory 是个很有趣的方向:多个 agent 共享一个 SkillRepo,curation 决策要怎么协调?这个问题还没有好答案。
总体来说,SkillOS 是一个方向很对、工程扎实的工作,把 self-evolving agent 从”每次从头开始”推进到了”能从经验中持续提炼”。感兴趣的可以去读一读原文,实验细节很丰富。
欢迎评论区交流,有问题或者不同看法随时说~
本文基于 arXiv:2605.06614 写成。