MoE 训练通信瓶颈有救了?DySHARP 直接在交换机里做计算,干掉 50% 冗余流量
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

MoE 训练通信瓶颈有救了?DySHARP 直接在交换机里做计算,干掉 50% 冗余流量
原文:Accelerating MoE with Dynamic In-Switch Computing on Multi-GPUs(ISCA 2026)
1. 前言
今天想和大家聊聊一篇 ISCA 2026 的工作——DySHARP。
研究 MoE 的朋友应该都知道,MoE 最大的问题之一就是通信开销。每个 token 要 Dispatch 到对应 expert 的 GPU,算完再 Combine 回来,这两步 inter-GPU 通信在 DeepSeek-V3 的实测里占了 MoE layer 执行时间的 70.4%。GPU 算力越来越强,但通信带宽的增速跟不上,导致瓶颈越来越突出。
更有意思的是,NVIDIA 其实在 Hopper 时代就搞了 NVLink SHARP(NVLS),理论上可以在交换机内做计算来消掉通信冗余——但偏偏 MoE 的通信模式是”动态”的,NVLS 只支持”静态”的,直接 GG。
DySHARP 就是为了填这个坑来的。
2. MoE 通信里有多少冗余
先看问题有多严重。MoE 的 expert parallelism(EP)模式下,每个 token 需要经过 Dispatch 和 Combine 两轮 inter-GPU 通信:
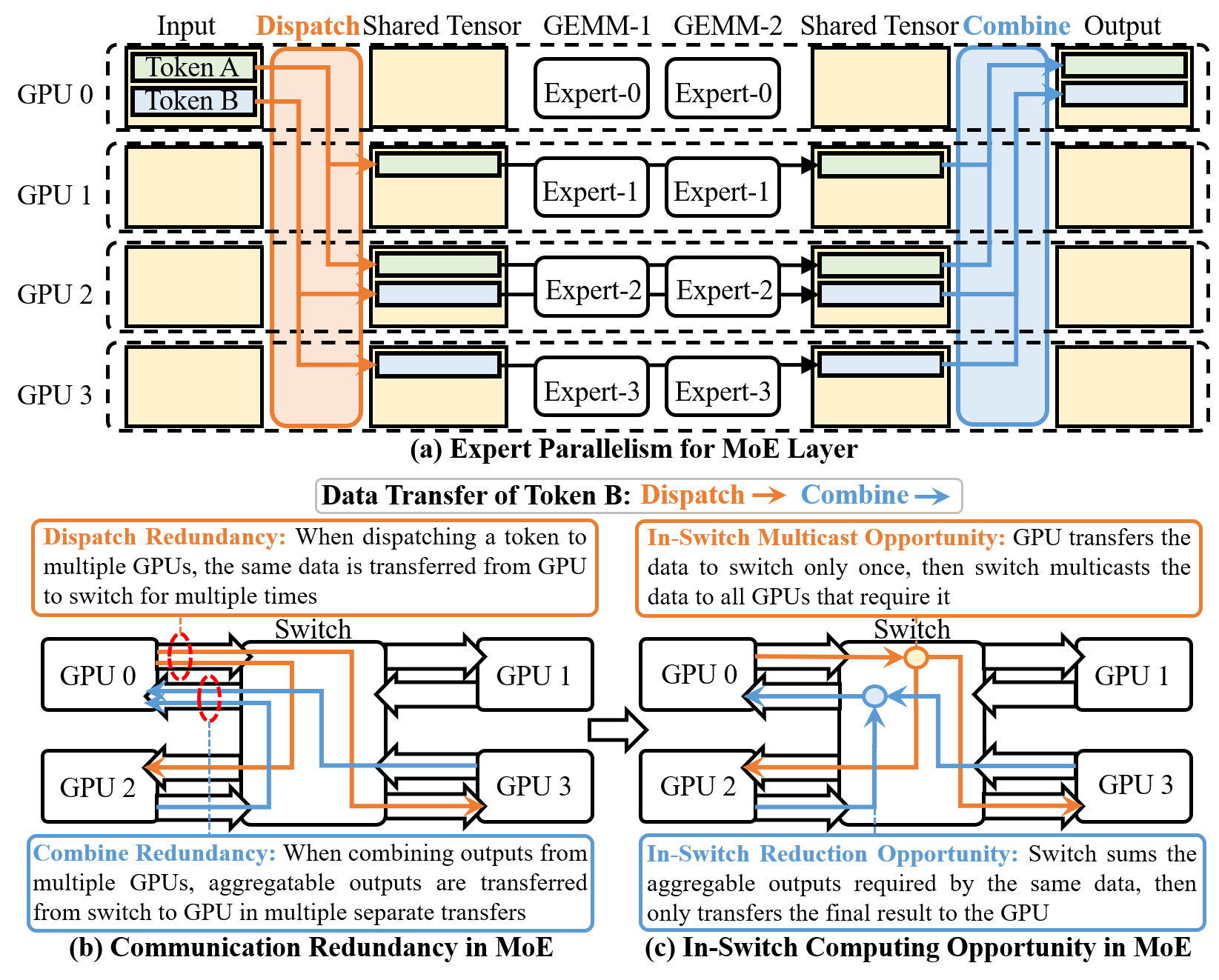
上图把问题说得很清楚。以图中的 Token B 为例:
- Dispatch 冗余:Token B 需要发给 GPU2 和 GPU3,GPU0 就得把同一份数据传两次,走两条链路——完全重复的数据传了两遍
- Combine 冗余:GPU2 和 GPU3 各自算出的中间结果,再分别传回 GPU0——这两份数据其实可以在交换机里直接加起来再传,没必要各发一份
NVLS 提出的 in-switch computing 恰好可以解决这两个问题:in-switch multicast 消掉 Dispatch 的重复传输,in-switch reduction 在交换机内聚合 Combine 的中间结果。图中 (c) 部分展示了这个理想方案。
下图定量衡量了这个冗余到底有多大:
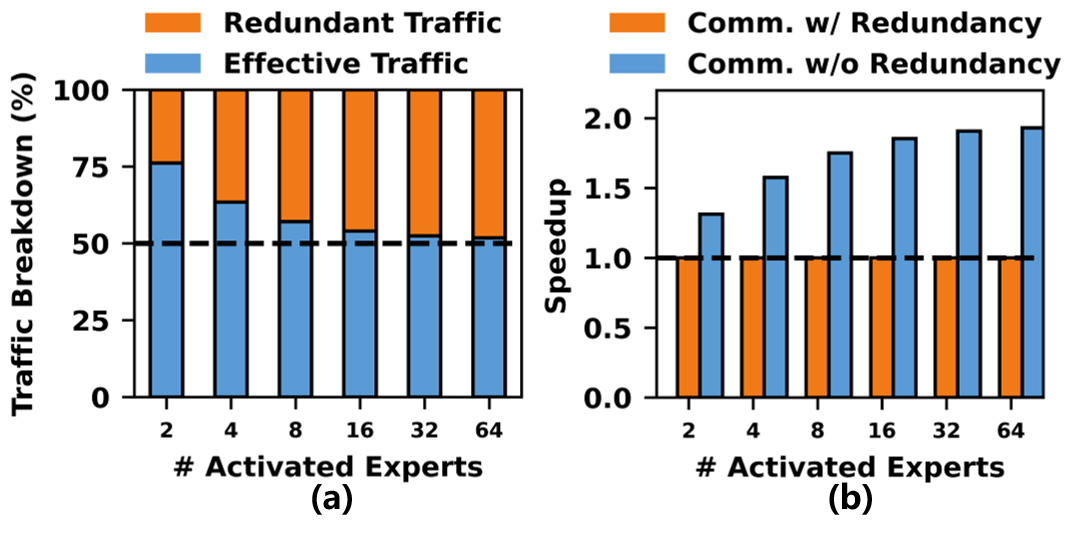
- 左图(a):当激活专家数 ≥ 8 时,冗余流量接近总流量的 50%,一半带宽在传重复数据
- 右图(b):如果把冗余消掉,理论通信加速接近 2×
3. 为什么 NVLS 搞不定
既然 NVLS 有 in-switch computing,为什么不直接用?
因为 NVLS 的设计是针对静态集合通信(AllGather / Reduce-Scatter)的,有两个硬约束:所有 token 都和固定的同一组 GPU 通信(Fixed target sets),且 token 在每个 GPU 上的内存偏移完全一样(Symmetric addressing)。
MoE 的 Dispatch/Combine 偏偏是动态的,下图对比得很直观:
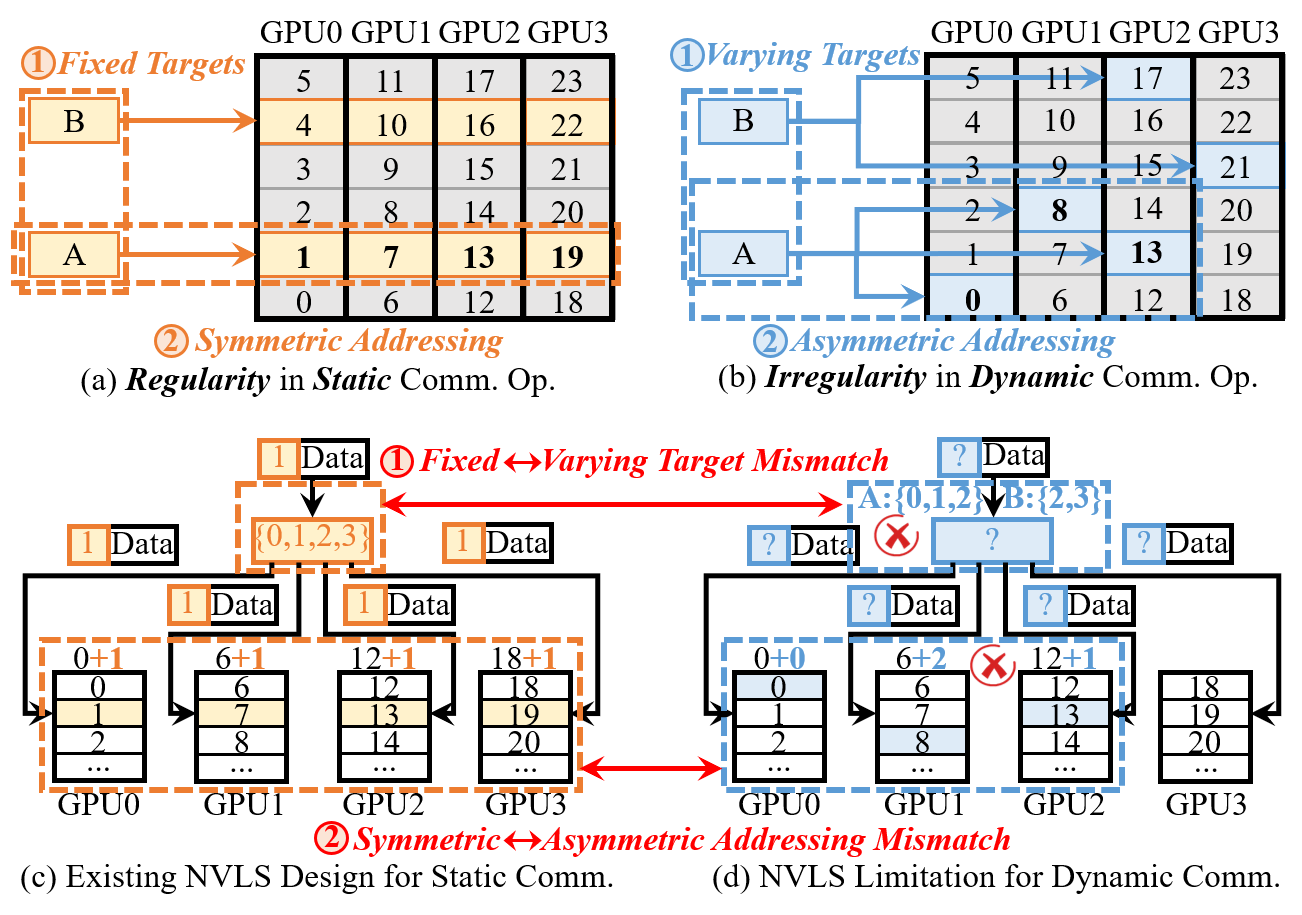
- 左边(a)静态:AllGather 的 token 发给所有 GPU,地址完全对称,NVLS 完美适配
- 右边(b)动态:Token A 发 GPU{0,1,2},Token B 发 GPU{2,3},目的地完全不同,内存 offset 各 GPU 本地管理,不对称
如果强行把 MoE 通信套进 NVLS,就要用 AllGather/Reduce-Scatter 来模拟 Dispatch/Combine,结果是不管 token 要不要,都给所有 GPU 发一遍。实测在 DeepSeek-V3 + GH200 NVL32 上,这个 workaround 产生了 340% 的无用流量,把 in-switch computing 省下的好处全冲掉了,比不用还糟。
4. DySHARP 的两把刷子,为什么缺一不可
DySHARP 提出了两个技术来配合解决这个问题:
- Dynamic Multimem Addressing:让交换机支持动态通信,把冗余流量削减掉
- Token-Centric Kernel Fusion:让 Dispatch 和 Combine 并发执行,把流量削减真正变成速度提升
为什么两个缺一不可?下图是最核心的一张图,一定要认真看:
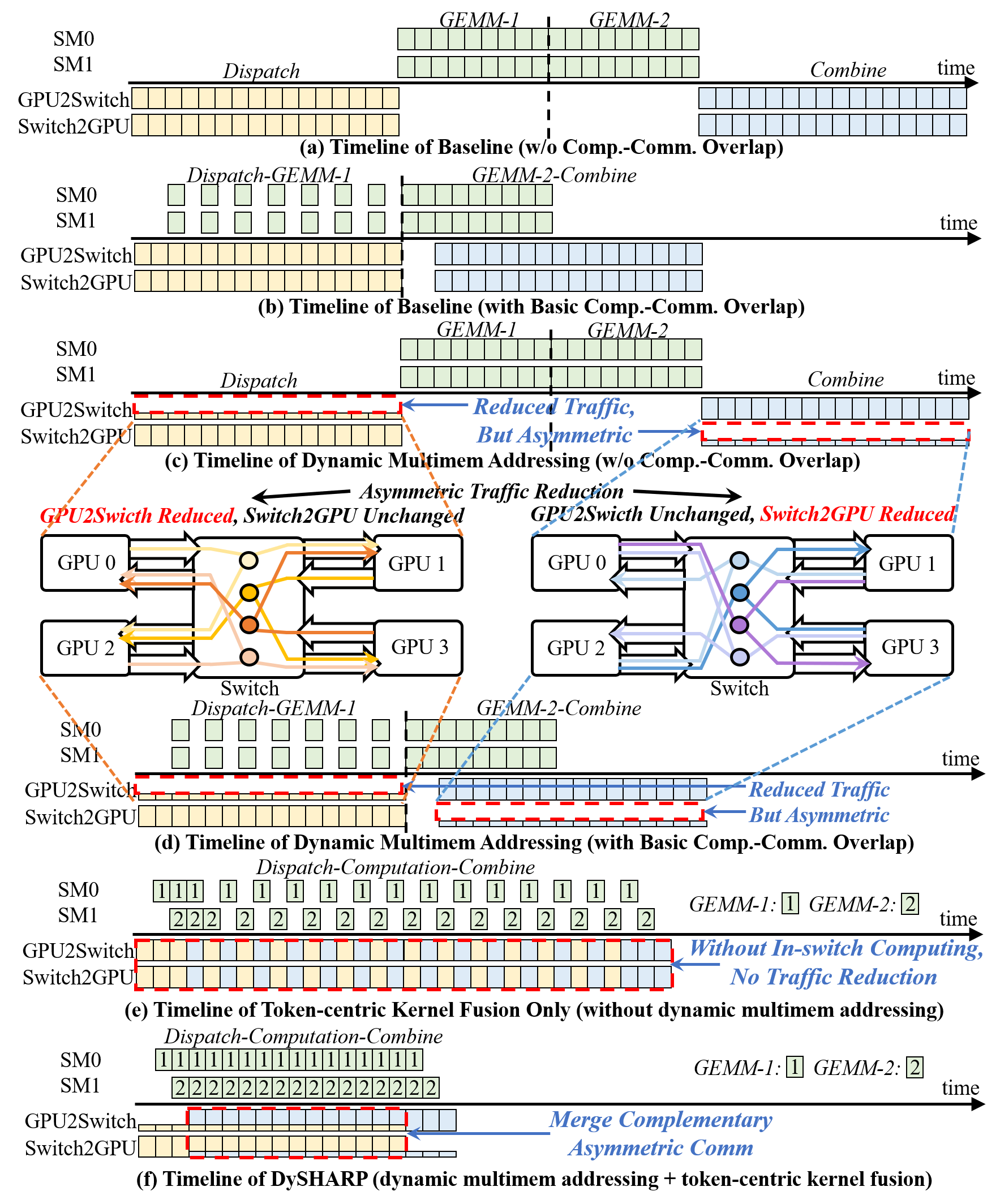
图中从上到下列出了 6 种配置:
- (a) DeepEP:基线,Dispatch → GEMM → Combine 串行,通信严重瓶颈
- (b) COMET:当前 SOTA,做了 Dispatch-GEMM-1 和 GEMM-2-Combine 的 overlap,但通信量没变
- (c) DySHARP-Basic:只加 dynamic multimem addressing,Dispatch 的 GPU→Switch 流量减少了,Combine 的 Switch→GPU 流量也减少了,但两个方向的削减是不对称的——单独执行 Dispatch 或 Combine 时,被未削减的那侧拖住,没法直接转化成加速
- (d) DySHARP-COMET:DySHARP-Basic + COMET 的 overlap,有所改善,但流量不对称问题仍在
- (e) Kernel Fusion Only:只做 Dispatch/Combine 并发而不减流量,相比 COMET 没有改善
- (f) DySHARP 完整版:两者结合——Dispatch(GPU→Switch 主导)和 Combine(Switch→GPU 主导)并发执行,两个方向的互补非对称流量叠加,双向带宽都被充分利用,才把 50% 的流量削减真正变成了加速 ✅
核心洞察:in-switch computing 减的是单向流量,天生不对称;kernel fusion 让两个方向并发,把互补的非对称流量叠加,才能真正转化成整体带宽利用率提升。
5. Dynamic Multimem Addressing 怎么设计
难点在于:multimem packet 里只携带一个地址,怎么表示”多个目标 GPU 上各自不同的内存位置”?
作者的洞察是:Dispatch 其实是 AllGather 的动态版本——两者的 token 都有一个跨 GPU 统一的逻辑位置(algebraic index),区别只是 Dispatch 只发给部分 GPU。所以 packet 里可以继续带 algebraic index,再加一个轻量的 target list,让目标 GPU 在本地做 algebraic→layout 的地址映射。
下图比较了”把所有目的地址直接塞进 packet”(explicit addressing)和 DySHARP 的方案:
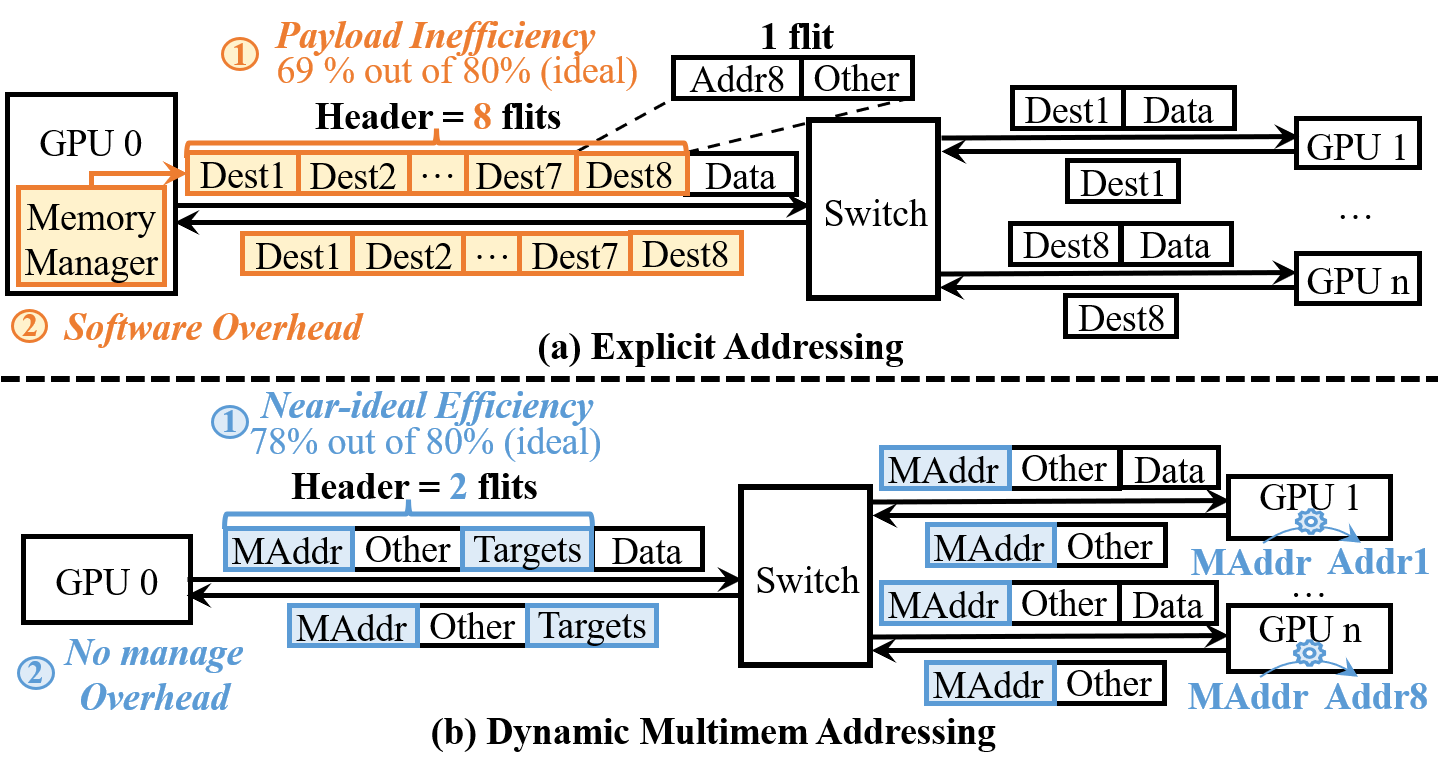
上半部分(a)是 explicit addressing:每个目标地址都要占 header flit,8 个目标时 payload efficiency 从理想的 80% 降到 69%,而且发送方还要预先计算每个目标 GPU 的 remote 内存地址,额外同步开销 5%+。
下半部分(b)是 dynamic multimem addressing:packet 只带一个 multimem address 和一个 target list,目标 GPU 自己管自己的内存映射,payload efficiency 达到 78%(接近理想的 80%),没有额外软件开销。
这套设计的完整硬件架构如下:
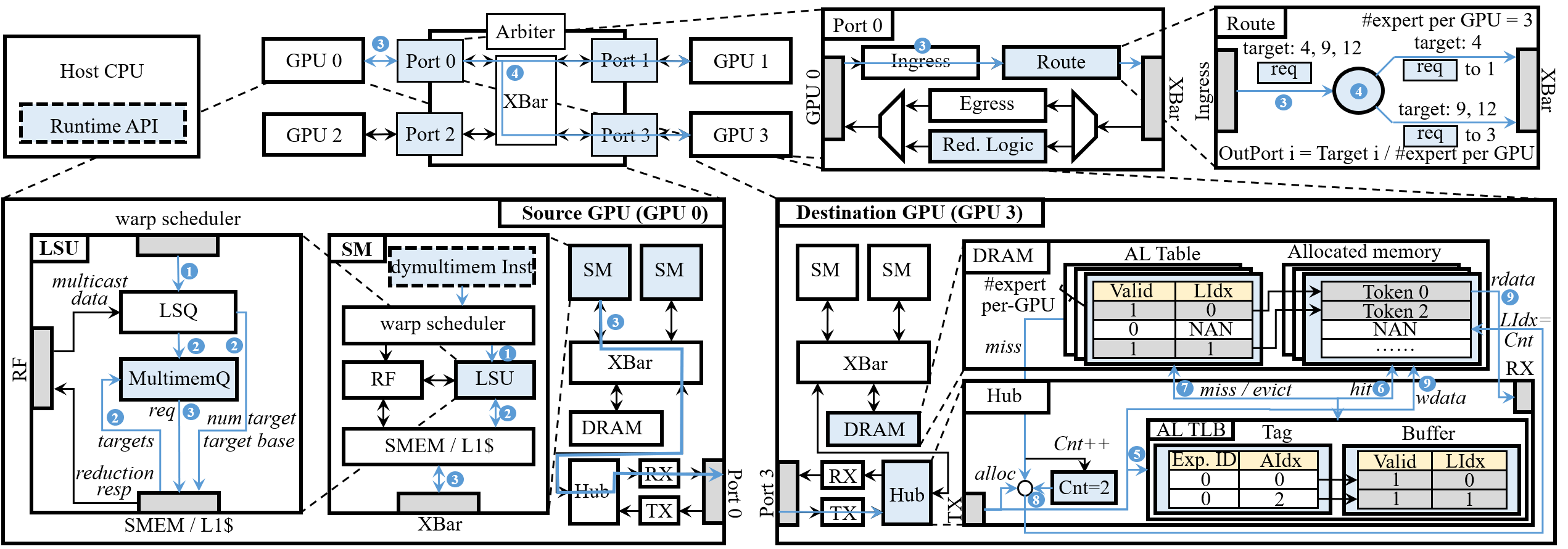
三个核心组件:
- Source GPU:SM 的 LSU 新增 MultimemQ,处理
dymultimem.*指令,先取 target list,再发 request packet - Switch:Route 模块按 target list 转发和复制;
dymultimem.ld_reduce(Combine)时等所有响应聚合后只发最终结果回来 - Destination GPU:Hub 里新增硬件 Memory Manager,维护 AL Table(Algebraic-Layout 映射表),把 algebraic index 翻译成本地 virtual address
6. Token-Centric Kernel Fusion 怎么做
即使流量削减了 50%,如果 Dispatch 和 Combine 依然串行执行,in-switch multicast 减的 GPU→Switch 流量和 in-switch reduction 减的 Switch→GPU 流量是不对称的——各自执行时都被”未减那侧”拖住,加速上不去。
解法是让 Dispatch 和 Combine 并发执行。而做到这一点,需要把 Dispatch→GEMM-1→GEMM-2→Combine 这条依赖链细化到 token/tile 粒度:
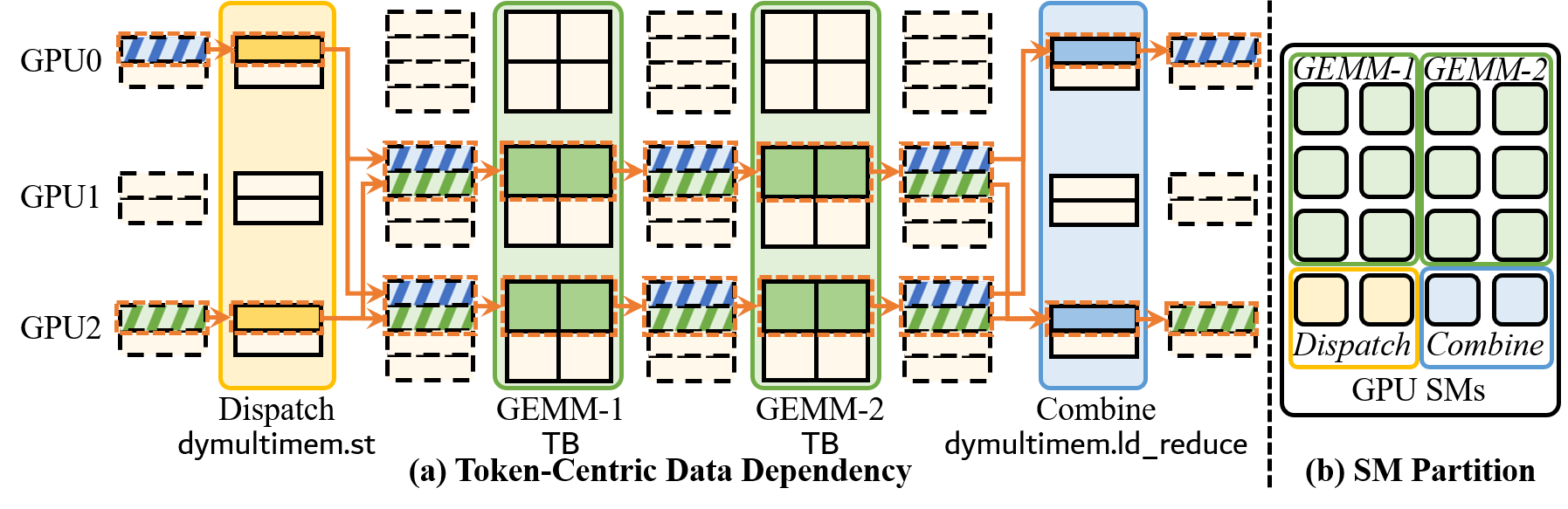
图中左边(a)展示了 token-centric 数据依赖:某个 token 的 Dispatch 完成了,对应的 GEMM-1 tile 就可以立刻开始;GEMM-2 输出后立刻触发 Combine,不需要等整个 operator 跑完。图中右边(b)展示了 SM 分区:SM 被分成 4 组分别负责 Dispatch、GEMM-1、GEMM-2、Combine,实现真正的流水并发。
7. 实验结果
实验在模拟的 GH200 NVL32(32 GPU)上跑,对标 DeepSeek-V3(Small/Medium/Large,topk=8/16/32)。
端到端加速
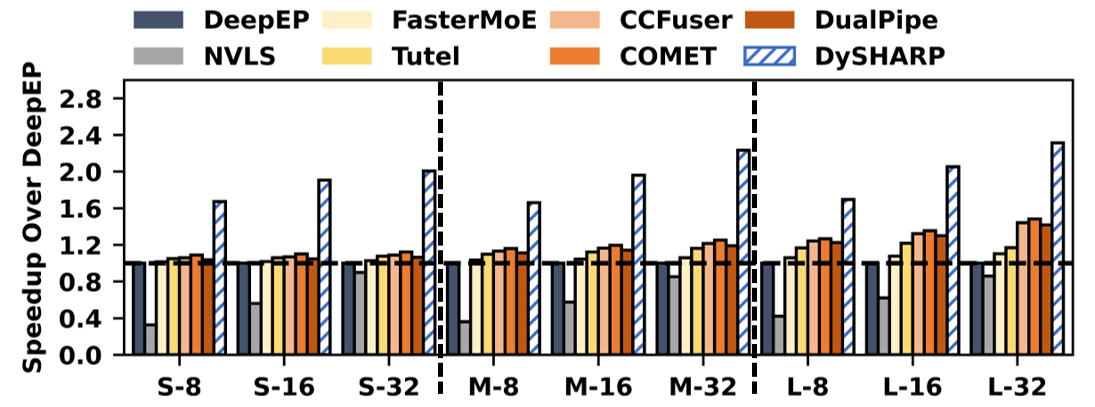
- vs DeepEP:最高 2.31×,几何均值 1.93×
- vs NVLS(静态 workaround):最高 5.12×——无用流量把它拖死了
- vs COMET(当前 SOTA):最高 1.79×,几何均值 1.59×
消融实验:每个技术贡献了什么
下图的消融实验把 6 种配置的时间 breakdown 都列出来了,和前面图 4 的分析完全对应:
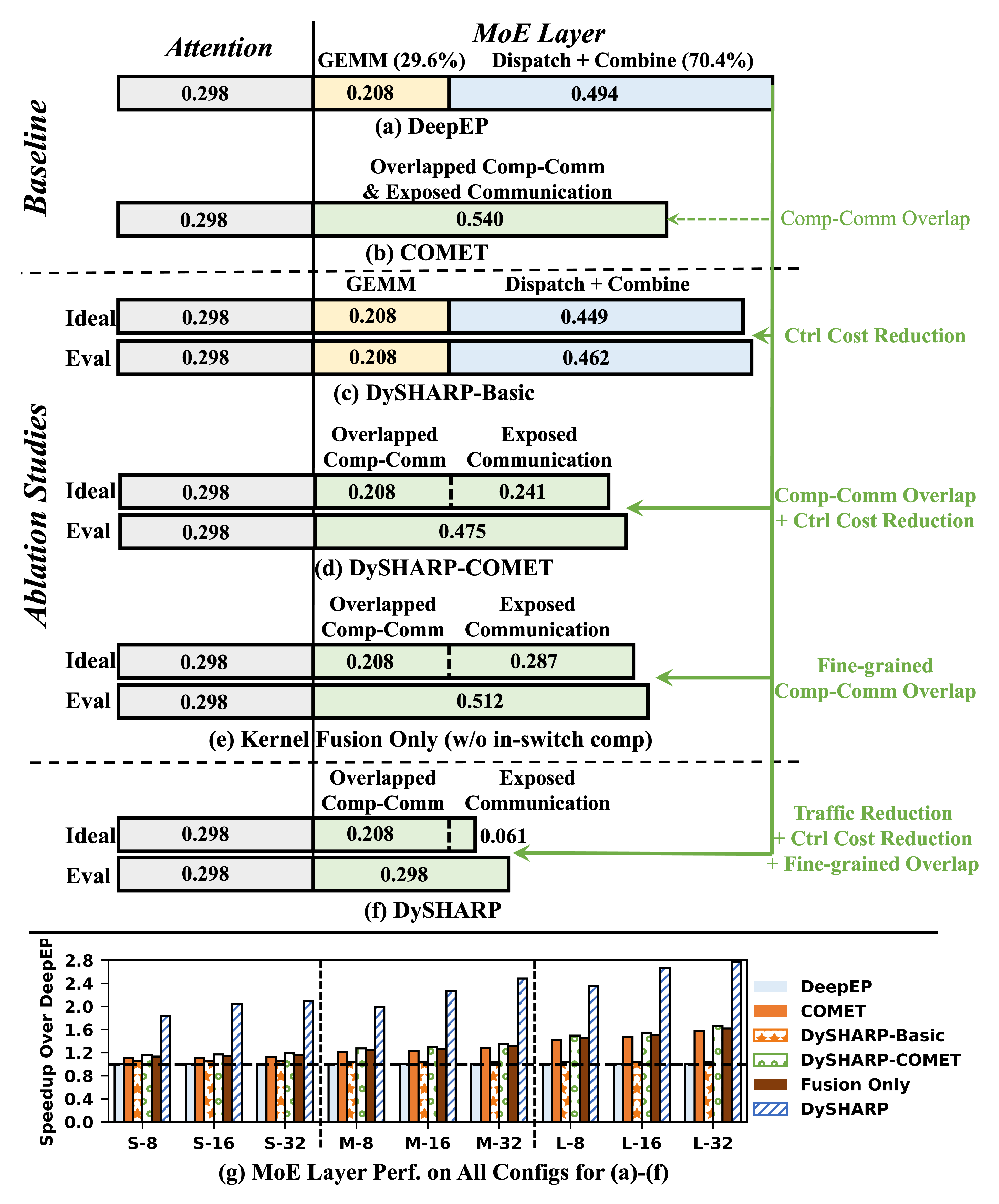
- (a) DeepEP:Dispatch+Combine 占 70.4%,通信严重瓶颈
- (c) DySHARP-Basic:流量减了,但不对称,没法直接加速
- (f) DySHARP 完整版:把两侧互补流量 merge,暴露的通信时间大幅缩短
对比 (e) Kernel Fusion Only 和 (b) COMET 几乎一样说明了:没有流量削减,光靠并发是没用的。
8. 我的看法
这篇工作有几个点值得细品:
问题切入点很准。MoE 通信优化的工作已经不少了,大家大多在 overlap 上卷。这篇从”根本上流量就多了”这个角度入手,切入点很有意思,而且给出了完整的全栈解法——从 packet format、ISA、微架构到 CUDA Runtime 都改了一遍。
图 4 那个六格对比是亮点。不是堆 feature,而是系统地证明了为什么 A 不行、B 不行、A+B 才行。这种设计逻辑比单点 trick 有意思得多,也更容易说服 reviewer。
硬件开销控制得好。GPU 侧 0.024%、Switch 侧 0.1% 的面积开销,基本可以说是在现有框架上最小侵入式地扩展,没有推倒重来。
当然也有值得注意的地方:实验全在模拟器(BookSim2 + Accel-Sim)上跑,不是真机;而且要落地,NVIDIA 需要在 ISA、微架构、Switch 多个层面同步改动,这个工程量不小。
- topk 越大收益越大,topk=1 这类极端稀疏场景效果有限
不管怎么说,把 in-switch computing 从静态 collective 扩展到动态 MoE 通信,这是整个行业面临的核心矛盾之一,这篇工作是个很有价值的 first step。
欢迎评论区交流,指出问题也欢迎🤝