MoE 推理的内存墙,被一块多芯粒芯片打穿了?
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

MoE 推理的内存墙,被一块多芯粒芯片打穿了?
今天想和大家聊聊这篇来自港科大的工作 —— Expert Streaming,最近在 arXiv 上出现,是少见的从芯片架构角度直接解决 MoE 推理内存瓶颈的硬核工作。
先交代下背景:MoE 火是真的火,DeepSeek、Qwen3 都在往 MoE 走,但我们自己跑的时候,却结结实实踩了个大坑 —— 显存根本不够用。稀疏激活的好处(计算量小)在 edge 设备上被”要把所有 expert 权重全量加载进来”这一条给彻底抵消了。
1. 问题到底出在哪里
MoE 的逻辑是:每次 forward,一个 token 只激活 top-K 个 expert,90% 以上的 expert 权重全程闲着。理论上很省计算,但现实是:
你得把所有 expert 的权重都放进 on-chip memory,才能在激活时立刻取用。
Qwen3-30B-A3B 有 128 个 expert,全量加载就是海量的 on-chip 存储需求。在 edge 多芯粒(multi-chiplet)加速器上,每块芯粒的 SRAM 是有限的,放不下。
大家的常见做法是 Expert Parallelism(EP)—— 把不同的 expert 分到不同芯粒上,每个芯粒只存一部分 expert。但这带来两个问题:
- all-to-all 通信开销:token 要跨芯粒路由到对应 expert 所在的芯粒,通信量随 batch size 下降而急剧放大
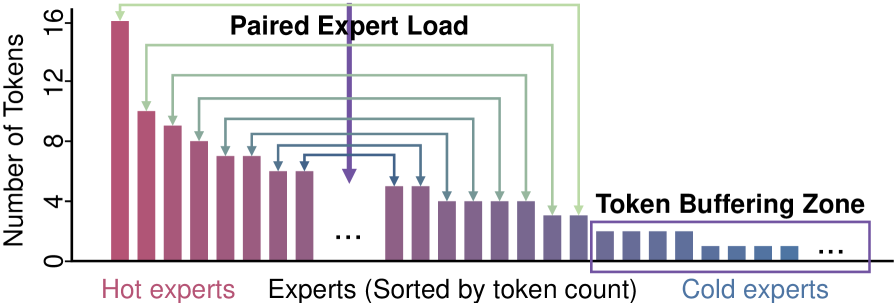
- 负载不均衡:MoE 有个很典型的”长尾效应”——
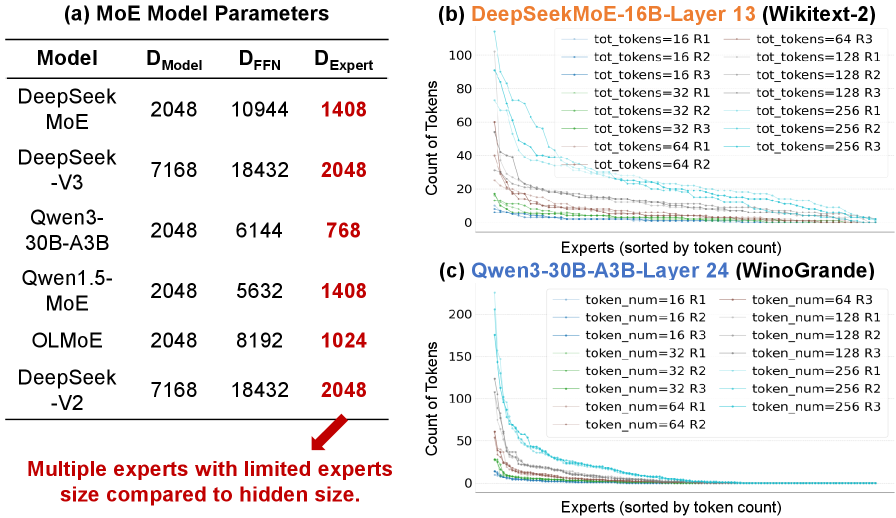
如上图,小 batch 下这个长尾效应更严重:少数 hot expert 处理大量 token,大量 cold expert 几乎空转,芯粒利用率极不均匀。
还有个 state-of-the-art 的方案叫 Hydra,思路是利用 cross-layer expert popularity 来提前预测哪些 expert 会被激活,减少跨片通信。但本质还是基于 EP 的思路,没有从根上解决 on-chip memory 压力。
这也是整个行业 MoE edge 部署面临的核心矛盾:稀疏激活带来的计算收益,被全量权重加载的内存代价完全吃掉了。
2. Expert Streaming 的核心思路
这篇工作的出发点很有意思 —— 既然 D2D(die-to-die)高带宽互联(比如 UCIe)越来越成熟,为什么不把它当成一种计算资源,而不是单纯的通信开销来对待?
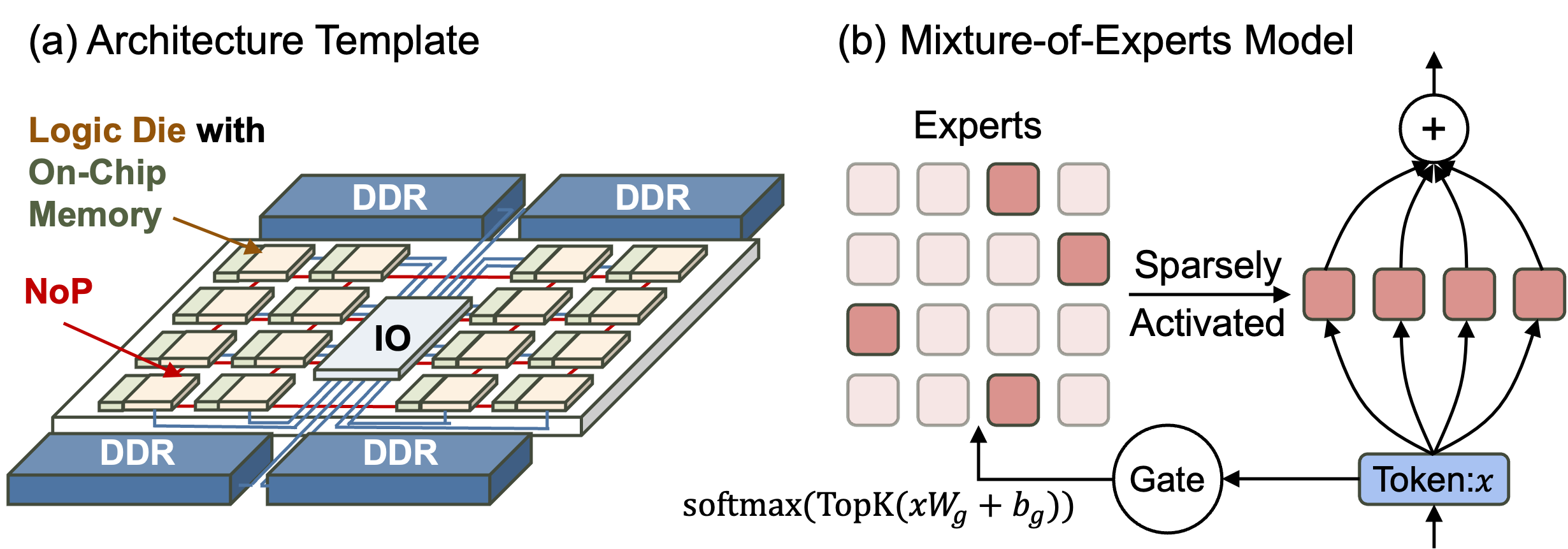
核心方案叫 FSE-DP(Fully Sharded Expert Data Parallelism),可以拆成三个互相咬合的设计:
2.1 Micro-slice Streaming
把每个 expert 的权重切成小块(micro-slice),在芯粒之间像流水线一样循环传输。
每个芯粒同时做三件事:
- 计算当前 micro-slice 对应的矩阵乘
- 接收下一块从邻居芯粒传来的 micro-slice
- 转发刚算完的 micro-slice 给下一个芯粒
这样,D2D 通信和计算完全 overlap,expert 权重不需要全量驻留在任何一个芯粒上。
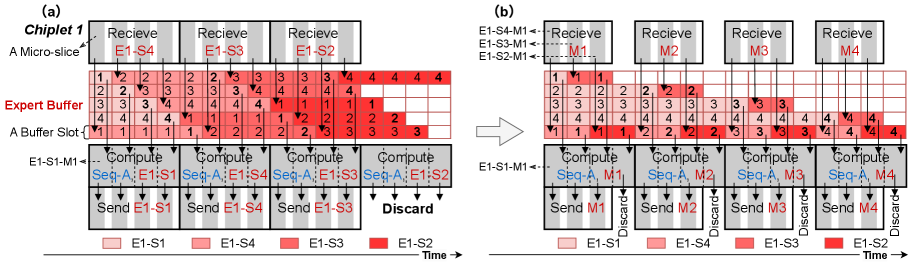
关键效果:on-chip memory 只需要存若干个 micro-slice 大小的 buffer,而不是整个 expert 的权重。
更进一步,他们做了”eager micro-slice usage”的优化 —— 芯粒收到 micro-slice 后立刻转发,不等计算完,这样每块 micro-slice 在 ring 上停留时间更短,buffer 占用更低。
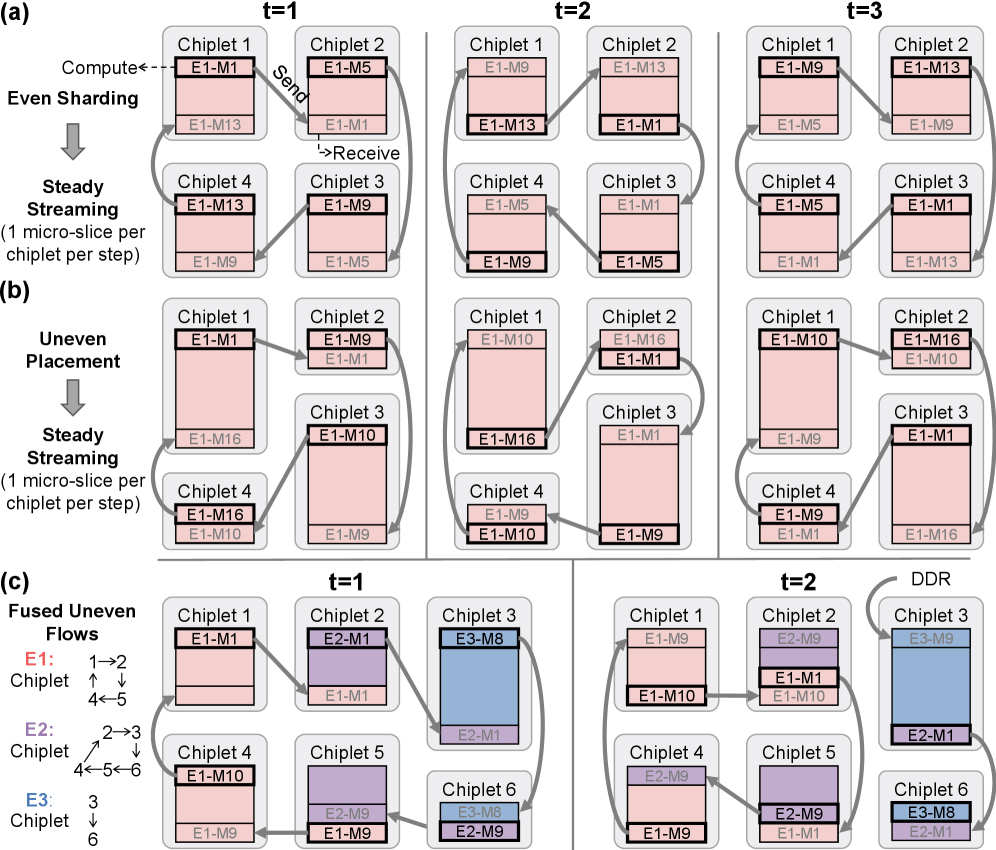
2.2 多芯粒下的全分片并行(FSE-DP)
一个 expert 不再绑定在某一个芯粒上,而是均匀切分到所有芯粒上。每个芯粒持有这个 expert 的一个 slice,token 在芯粒间做 redispatch 以均衡负载。
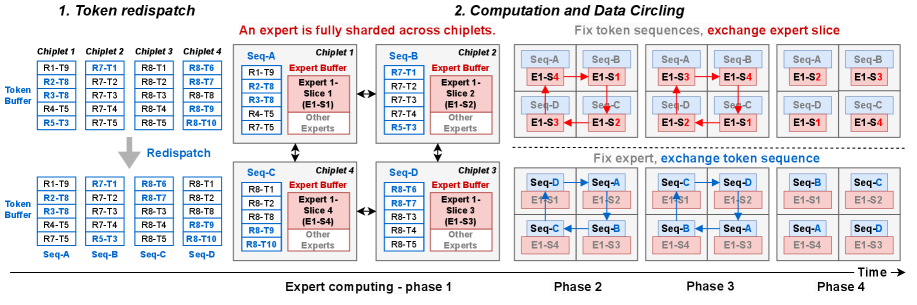
两种等价的执行方式:
- (a) token sequence 不动,expert slice 在芯粒间流动
- (b) expert slice 不动,token sequence 在芯粒间流动
本质是一样的,调度器统一抽象为”trajectory”来管理。
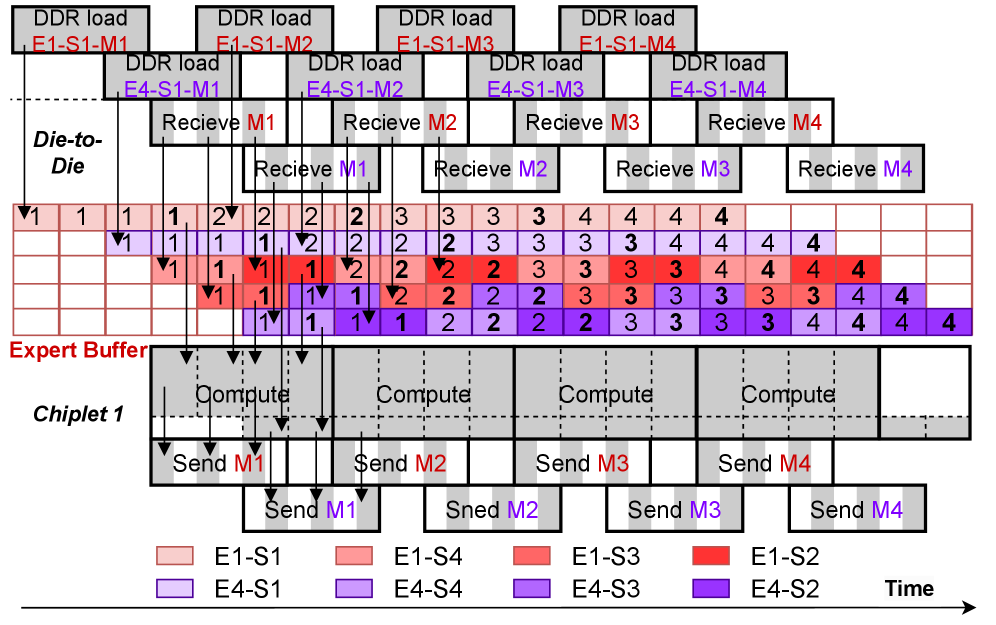
2.3 Paired-load + Token Buffering
光有 micro-slice streaming 还不够,还有个利用率问题:DDR 加载 expert 权重的延迟(off-chip)比 D2D 通信慢得多。
Paired-load:把 hot expert(处理 token 多,compute-bound)和 cold expert(处理 token 少,memory-bound)配对,在同一个时间窗口内交错执行,让计算和 DDR 加载互相掩盖对方的 idle 时间。
Token Buffering:遇到 cold expert 时,不急着立刻处理这个 request,而是在 MoE 层边界暂停,等积累到一定数量的 token 之后再一起处理,提升 expert 利用率。
这两个策略把 DDR 加载的 overhead 和 D2D 的 micro-slice 流完全融合进了一个统一的 pipeline:
3. 调度器设计
上面这套方案能运转,有个前提:需要一个硬件调度器来实时决定”哪些 expert 的 micro-slice 走哪条 trajectory”。
他们把这个调度器实现在 IO die 上,面积仅 0.43 mm²(28nm 工艺),调度延迟在亚微秒级别,不会成为 bottleneck。
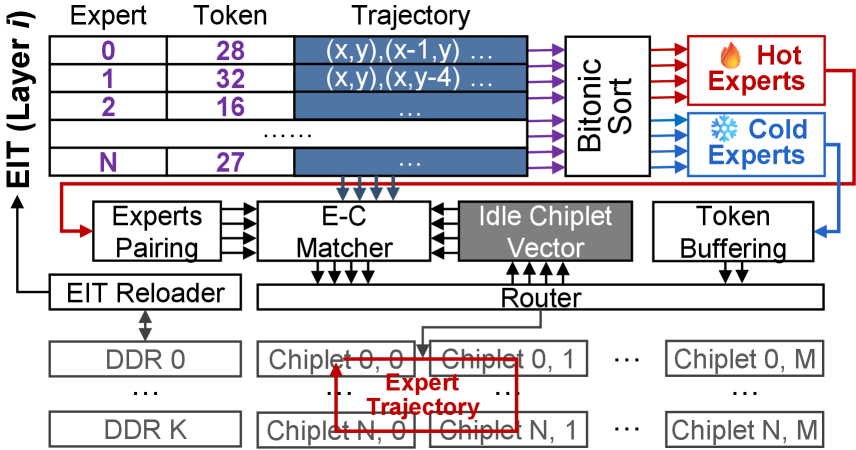
“Virtualization”是调度器抽象层的关键概念 —— 无论 expert 在各芯粒上如何不均匀分布,调度器只需要保证 micro-slice 按规定的 trajectory 流动,底层实现细节对上层完全透明。
4. 实验效果
测试了 4 个模型:Phi-3.5-MoE(16 experts)、Yuan2.0-M32(32 experts)、DeepSeek-MoE-16B(64 experts)、Qwen3-30B-A3B(128 experts),数据集覆盖 Wikitext-2、C4、WinoGrande。
单层 latency

FSE-DP 在 16–1024 token 的 low-batch 范围内,单层 latency 均优于 EP 和 Hydra。
端到端 throughput
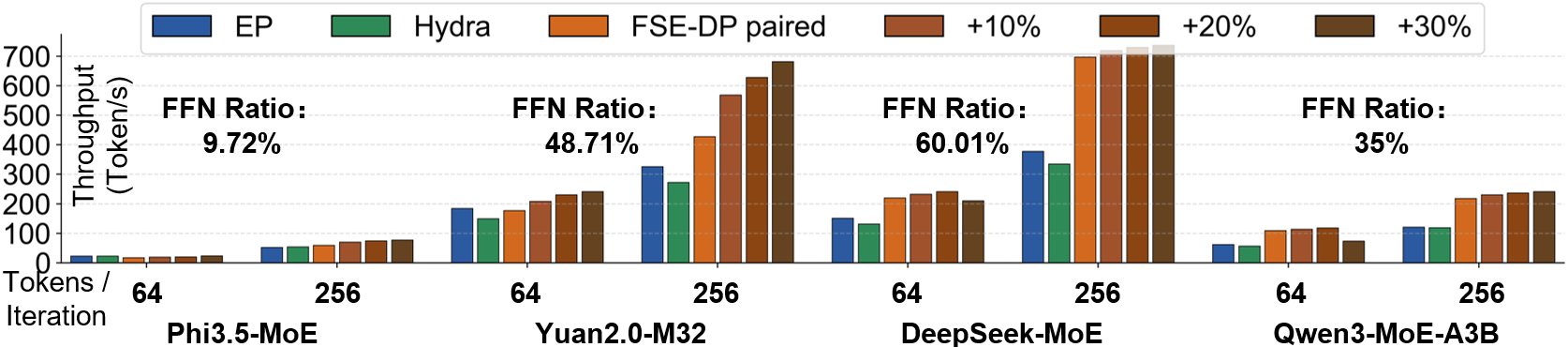
端到端 throughput 相比 state-of-the-art 基线,实现了 1.22×–2.00× 的提升。
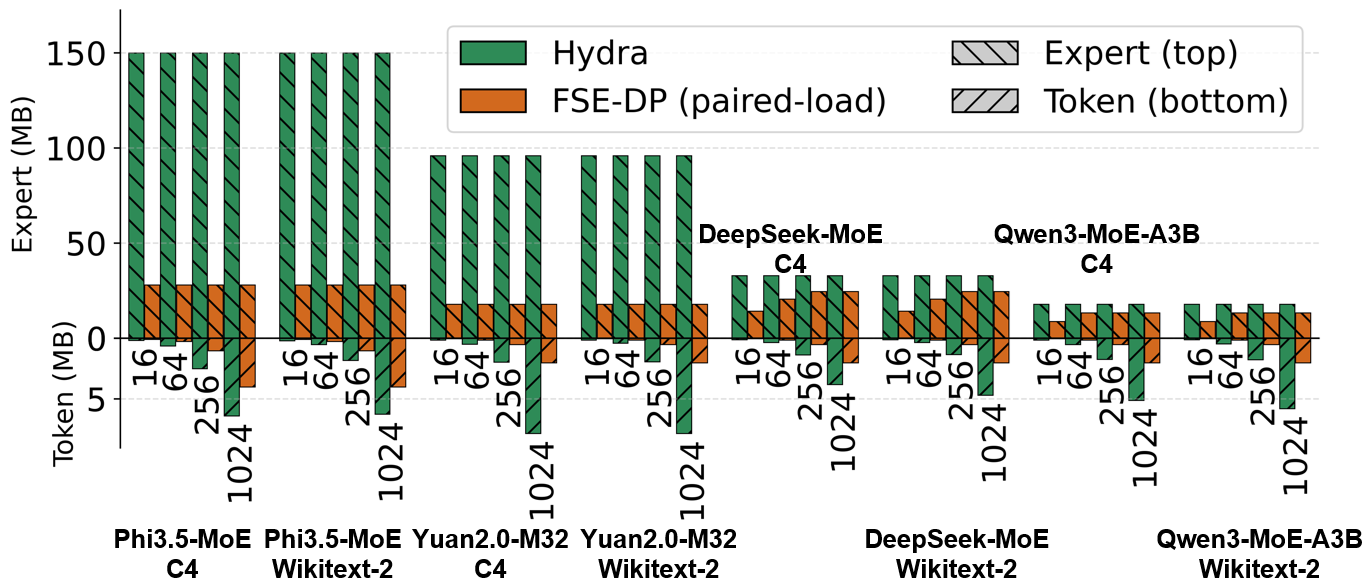
On-chip memory savings
与 Expert Parallelism 相比,节省了高达 78.8% 的 on-chip memory。
Ablation study
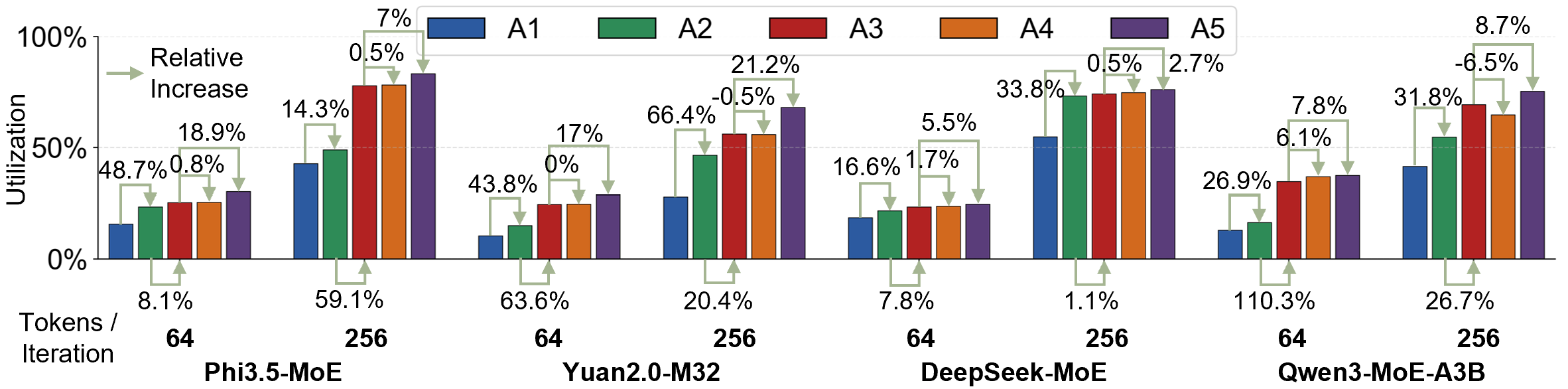
micro-slice streaming、paired-load、token buffering 三个模块各自都有贡献,叠加后达到最优。
5. 我的 take
这篇工作有几个地方让我觉得很有意思:
1. 视角的转换很关键。 之前大家把 D2D 通信当成 MoE 并行的”代价”来优化,这篇工作直接把它当成”流水线资源”来利用,思路上有个质的跳转。
2. 真正的硬件协同设计。 光有算法不够,他们实际流片了(Figure 10 有芯片照片),在真实芯片上验证了整套方案,这在学术界还是比较稀缺的。

3. 对 edge MoE 的意义。 2.00× throughput + 78.8% memory savings,在资源受限的 edge 场景下,这个 combo 是实质性的提升,不是那种”提了 3%,但只在特定条件下”的 benchmark 游戏。
当然,也有局限性:token buffering 会引入额外的 latency(在 request 层面),这对 latency-sensitive 的场景有影响;另外这套方案对 D2D 带宽有一定要求,不同代际芯片的迁移成本还不清楚。
总体来说,这是一篇把系统架构、调度算法、硬件实现做得比较扎实的 MoE 推理优化工作,推荐做 LLM 系统和 edge 部署方向的同学认真看看。
欢迎评论区交流,有问题也欢迎指出。