LoRA fine-tune吞吐量提升1.96倍!LoRAFusion如何把内存带宽浪费和pipeline bubble一起干掉
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

LoRA fine-tune吞吐量提升1.96倍!LoRAFusion如何把内存带宽浪费和pipeline bubble一起干掉
1. 前言
做过 LLM fine-tune 的同学应该都知道,LoRA 是当前 PEFT 方法里最主流的选择。只引入少量低秩参数,显存省下来了,效果也不差。
但你有没有想过:LoRA 参数只有全参数的 0.3% 不到,为什么加上 LoRA 之后训练速度反而掉了 40%?
这个数字是真实测出来的,不是理论估算。Fine-tune LLaMa-3.1-70B,加上 LoRA(rank=16)之后,训练 throughput 直接下降 40%。本质上是一个让人有些细思极恐的问题:参数只加了 0.3%,计算量也没增加多少,但速度掉了这么多,钱花在哪了?
今天这篇 EuroSys ‘26 的工作 LoRAFusion 把这个问题剖析得很清楚,顺带还解决了另一个在多任务 fine-tune 场景里被严重忽视的问题:多个 LoRA job 并行时的 pipeline bubble 和 GPU 负载不均衡。
代码已开源:github.com/CentML/lorafusion
2. 背景:LoRA 的参数结构和 fine-tune 痛点
先简单回顾一下 LoRA 的公式。对于一个预训练权重矩阵 $W \in \mathbb{R}^{k \times n}$,LoRA 注入两个低秩矩阵 $A \in \mathbb{R}^{k \times r}$ 和 $B \in \mathbb{R}^{r \times n}$($r \ll k, n$):
\[Y = XW + \alpha \cdot (XA)B = XW + \alpha \cdot SB\]其中 $S = XA$ 是中间结果(维度小),$\alpha$ 是缩放系数。fine-tune 过程中 $W$ 冻结不更新,只更新 $A$ 和 $B$。
以 LLaMa-3.1-70B 为例:
- 全参数 fine-tune:仅模型状态就需要约 1120 GB 显存(参数、梯度、优化器状态)
- LoRA(rank=16)fine-tune:只需约 142 GB 显存,额外参数量仅占 0.29%
显存省了将近 8 倍,但训练速度呢?
如下图,LoRA linear 层和普通 frozen linear 层的吞吐量对比:
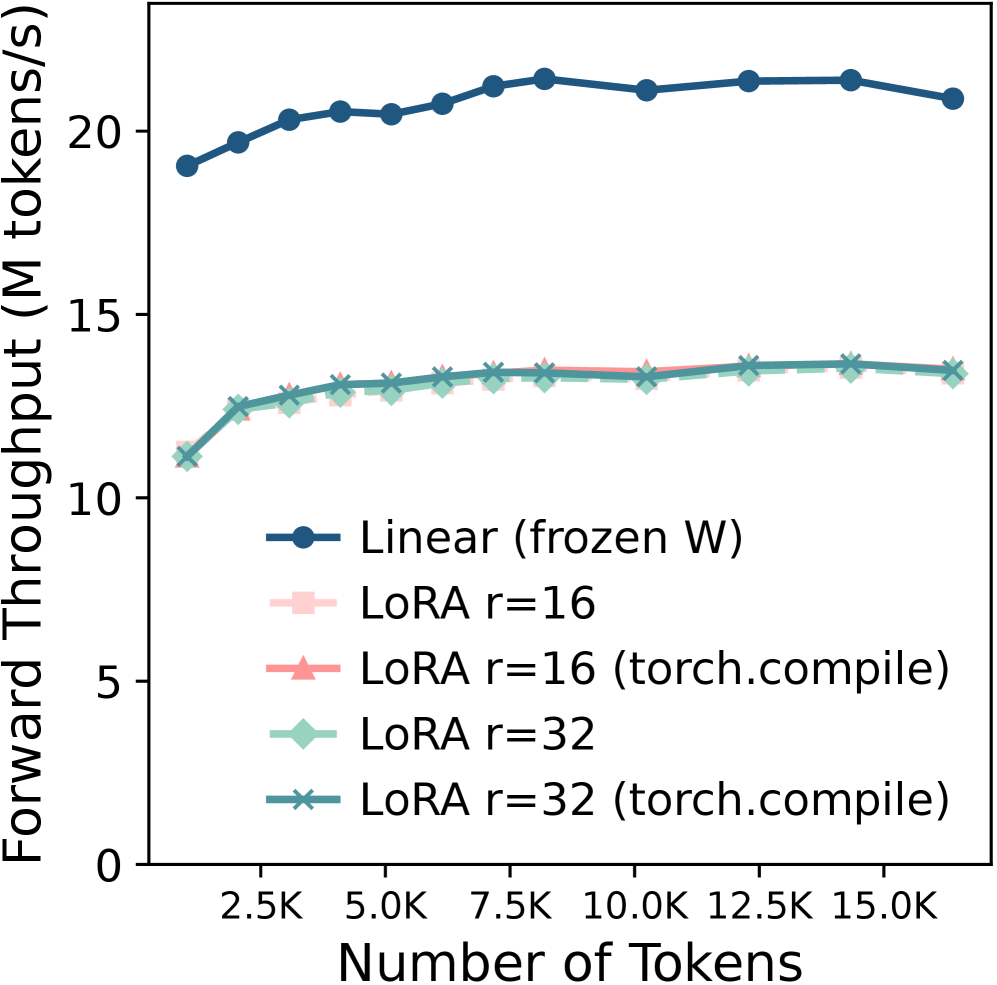
不管 token 数和 rank 是多少,LoRA linear 比 frozen linear 慢了约 40%(forward)和 36%(backward)。torch.compile 几乎没有帮助。这是为什么?
3. 问题分析:罪魁祸首是内存带宽,不是计算量
3.1 内存访问是瓶颈
如下图,一个 LoRA linear 层的运行时细分:
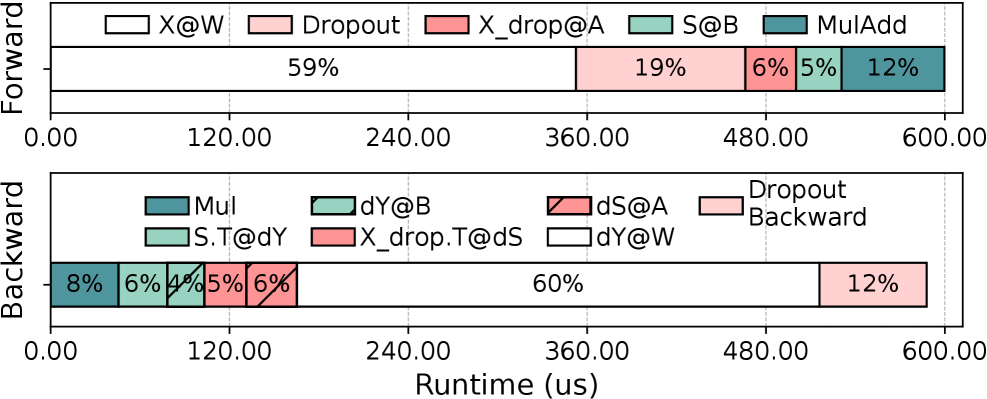
运行时主要分三类:
- Frozen GEMM($XW$):compute-bound,占 59%/60%(前向/反向)
- LoRA GEMM($XA$ 和 $SB$):memory-bound,前向占 10.76%,反向占 20.37%
- Element-wise 操作(dropout、乘法、加法):memory-bound,前向占 30.46%,反向占 17.49%
LoRA 的下投影 $S = XA$ 的算术强度 $\mathbb{I}$ 是:
\[\mathbb{I} = \frac{1}{\frac{1}{r} + \frac{1}{n} + \frac{1}{m}} \ll \mathbb{B}\]由于 $r$ 很小(比如 16),这个算术强度远低于 H100 的硬件 balance 点(FP16 约 295),确认是 memory-bandwidth-bound。
更直接的数据:用 NVIDIA Nsight Compute 测量,LoRA 模块的 GPU global memory 读写流量比 frozen linear 增加了 2.64 倍。
结论很明确:LoRA 的 runtime overhead 根本原因是大 activation tensor 的重复内存访问,不是 FLOPs 增加。
3.2 Multi-LoRA 的机会被忽视了
现实中的 fine-tune 场景经常同时跑多个 LoRA job——超参搜索、多任务适配、多租户服务。这些 job 共用同一个 base model,显存开销很小,完全可以放在同一批 GPU 上跑。
但现有系统(比如 mLoRA)基本是各跑各的,错过了两个重要的优化机会:
如下图,随 global batch size 增大,理想吞吐量的提升幅度:
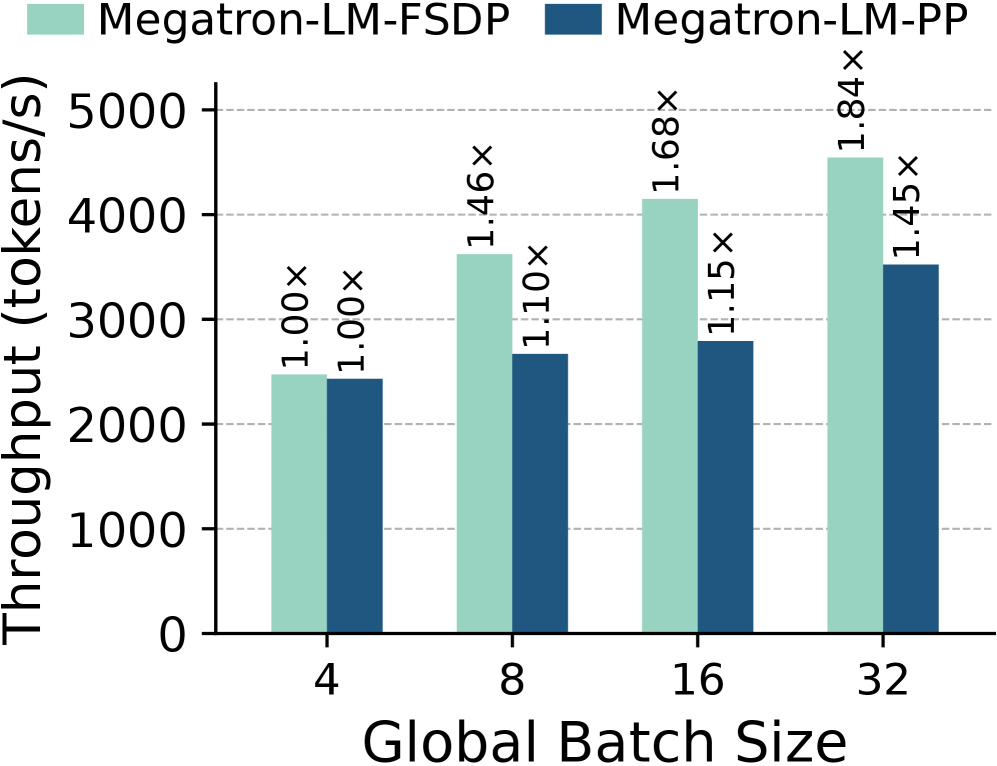
机会 1:增大 global batch size,降低分布式并行 overhead
把多个 job 的 sample 合并,global batch size 从 4 增到 32,FSDP 的理想吞吐量提升 84%,Pipeline Parallelism 提升 45%。原因是更大的 batch 能更好地 overlap 通信和计算(FSDP),以及填满 pipeline stages 减少 bubble(PP)。
机会 2:跨 job 打包样本,缓解 GPU 负载不均衡
实际数据集的 sequence length 分布差异很大(XSum/CNN/WikiSum 各不相同),导致每个 microbatch 的 token 数波动剧烈。如下图,同一 microbatch_size=4 下,token 数在不同样本间差异悬殊:
这种不均衡在 FSDP 下导致各 rank 等待最慢的那个,在 PP 下形成更多 bubble。如果把多个 job 的样本混合打包,可以有效平衡每个 microbatch 的 token 数,理论上可以带来最高 2.28 倍的吞吐量提升。
如下图,实际测量到的 LoRA fine-tune 相比理想固定长度场景的性能下降(最高约 30%):
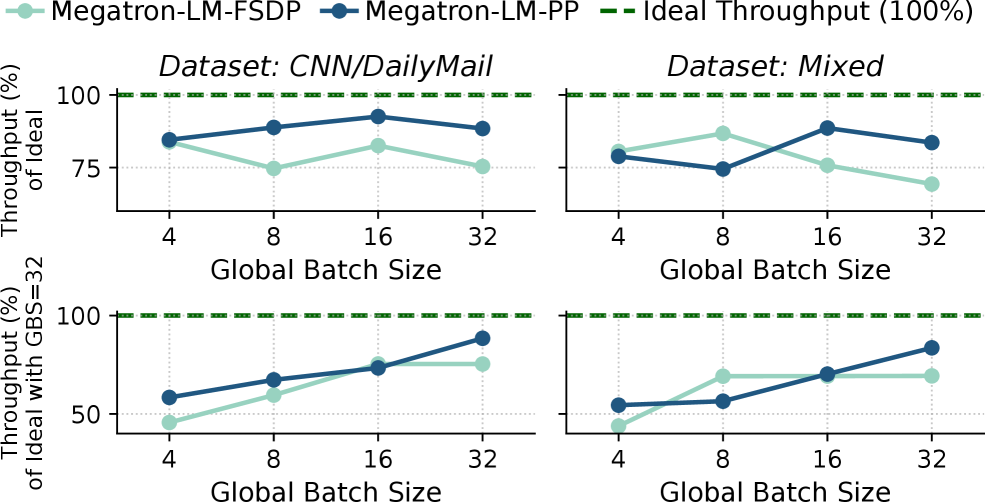
这是整个 multi-LoRA fine-tune 领域的核心矛盾:现有系统要么不支持多 job 并行,要么支持了但忽略了 load balance 和 kernel 层面的 redundant memory access。
4. LoRAFusion 的方案
两个层面的优化,对应两个问题:
如下图,LoRAFusion 整体系统架构:
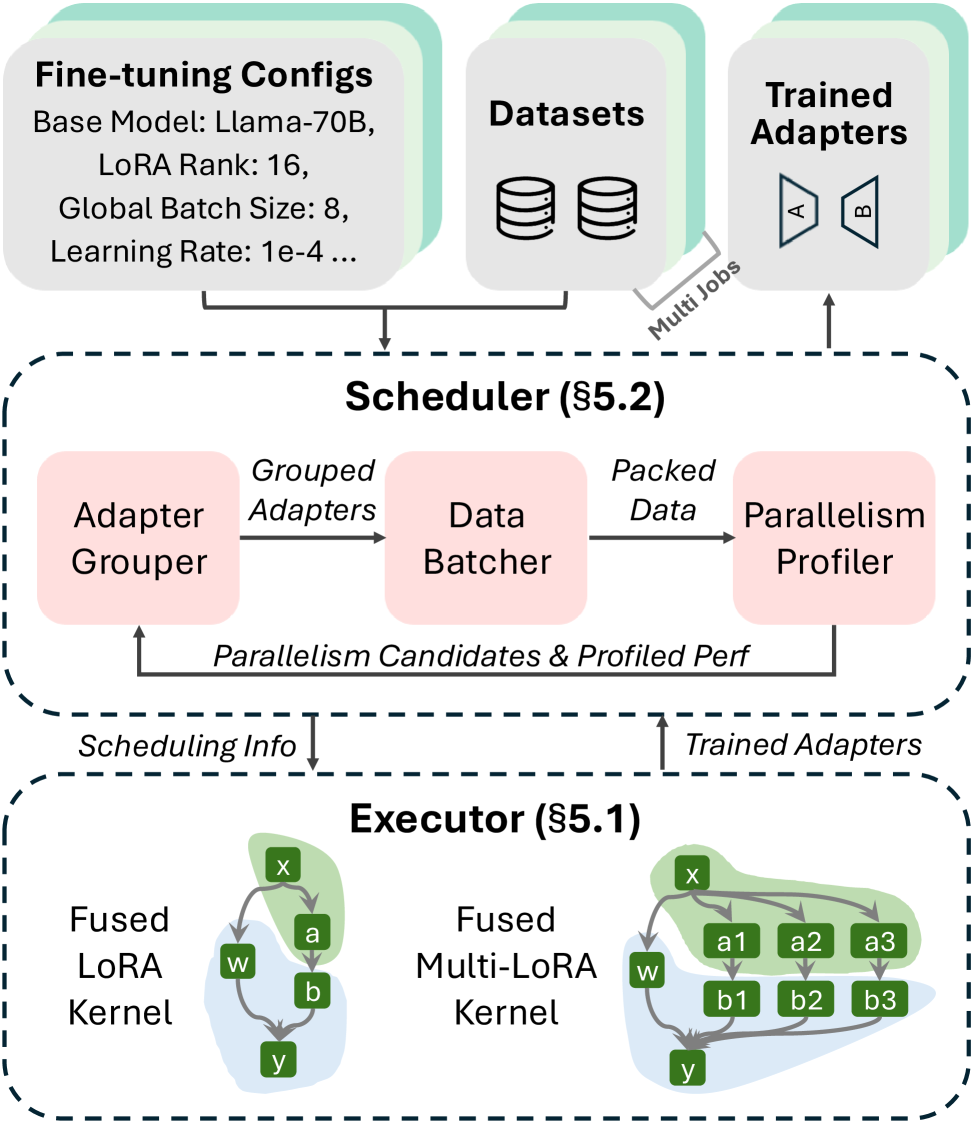
4.1 Kernel 层面:FusedLoRA 和 FusedMultiLoRA
核心思路:图分裂(Graph Splitting)+ 横向融合
一个直觉上的做法是把整个 LoRA 计算图 fuse 成一个 kernel。但这有两个问题:
- Frozen GEMM($XW$)是 compute-bound,需要精心 tiling,如果和其他操作混在一起,共享的寄存器/shared memory 会破坏最优 tiling
- $XA$ 和 $(XA)B$ 之间有 producer-consumer 依赖,naive fusion 要么 recompute,要么跨 thread block 同步,都会引入额外开销
LoRAFusion 的解法是在中间张量 $S = XA$(维度小,rank 维度)处分裂计算图:
如下图,三种融合策略的对比(recompute / synchronization / graph-split):
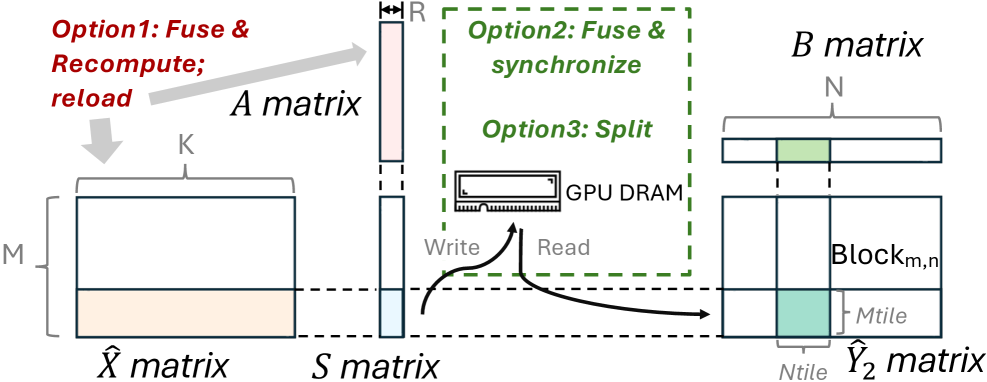
$S$ 的大小是 $m \times r$($r$ 很小),读写它代价很低。在 $S$ 处分裂后:
- $S$ 之前的操作(dropout + $XA$)fuse 成一个 kernel,消除大 activation tensor 的重复加载
- $S$ 之后的操作($XW$ 和 $\alpha \cdot SB$)fuse 成另一个 kernel,避免 frozen GEMM 被干扰
如下图,FusedLoRA 的 kernel 设计(前向和反向):
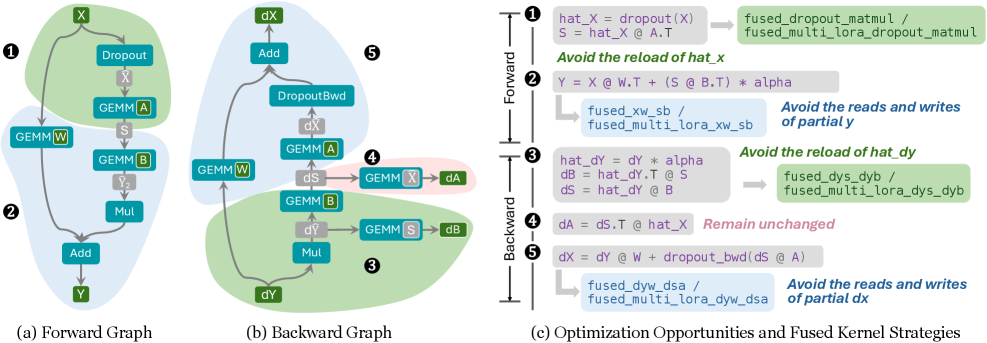
具体实现:
- Forward 前向:① dropout + 下投影($X \to S$)fuse 成一个 kernel;② frozen GEMM($XW$)和 LoRA 上投影($\alpha SB$)fuse 成一个 kernel,直接累加输出,消除一次大张量的读写
- Backward 反向:③ fuse $dS$ 和 $dB$ 的计算,消除 $dY$ 的重复加载;⑤ fuse base model 的梯度计算和 LoRA path 操作,消除 partial output 梯度的重复读写
内存流量实测减少 34%~37%,不需要 recompute,不需要 synchronization。
接下来,扩展到 FusedMultiLoRA,支持同时处理来自不同 job 的 adapter:
如下图,FusedMultiLoRA 的 tile 级 routing 机制:
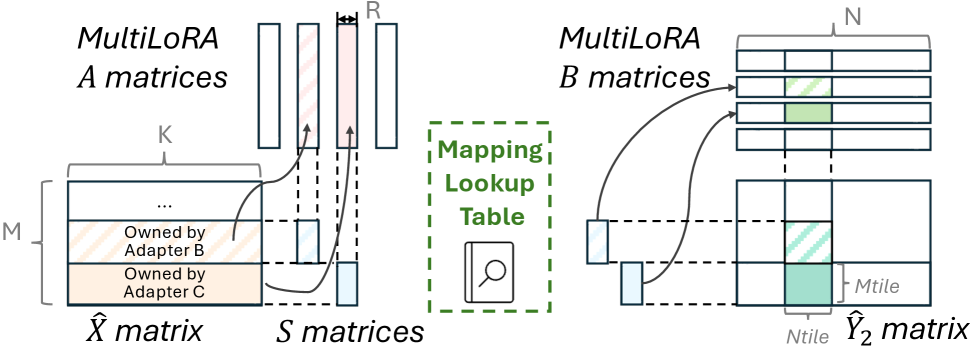
每个 input tile 带一个 adapter ID,kernel 执行时动态查表,加载对应的 $A$ 和 $B$ 矩阵并应用正确的 dropout 和 scaling。Base model 的计算在所有 token 间共享,adapter-specific 逻辑按 tile 独立处理。反向传播时,梯度同样按 adapter ID 路由回各自的 adapter,互不干扰。
4.2 Scheduling 层面:Multi-LoRA 自适应调度
这是 LoRAFusion 的另一个核心贡献,解决的是如何把多个 job 的样本打包成均衡的 microbatch。
如下图,Multi-LoRA 调度器的三步工作流:
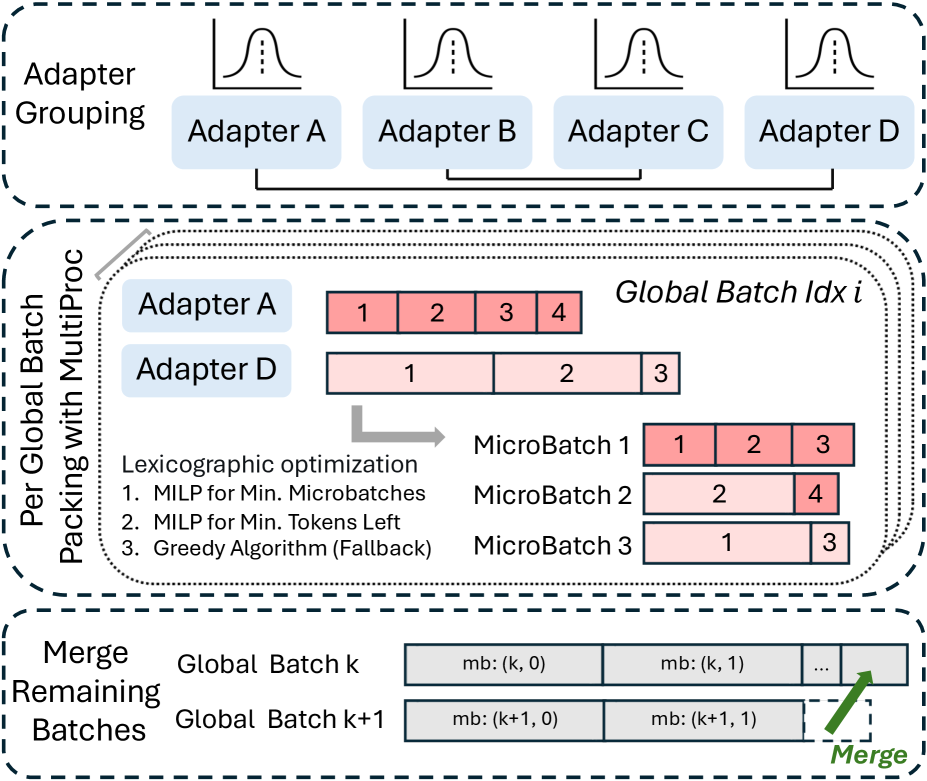
整个调度分三步:
Step 1:Adapter 分组(Bubble Lemma)
Pipeline 并行下有一个依赖约束:adapter $i$ 的 global batch $j$ 的 sample,在它的 backward 完成之前,同一 adapter 的 global batch $j+1$ 的 sample 不能开始 backward。简单说就是:同一个 adapter 的相邻两个 global batch,在时间线上必须间隔至少 $S-1$ 个 microbatch($S$ 是 pipeline stages 数)。
LoRAFusion 通过把 adapter 按 sequence length 分布分组,并在相邻组之间保持这个间隔,来满足 Bubble Lemma。组内采用”头尾配对”——长 sequence 和短 sequence 的 adapter 配对,提升负载均衡。
Step 2:两阶段 MILP bin-packing
组内的样本需要被打包到 microbatch 里(每个 microbatch 有 token 容量上限)。目标是:①最小化 microbatch 数;②让最空的 microbatch 尽量空(为后续合并留空间)。
这是一个 bin-packing 问题,用两阶段 MILP 求解:
- Stage 1:最小化 bin(microbatch)数 $B^*$
- Stage 2:固定 $B = B^*$,最大化最空的 bin 的空闲空间
MILP 设置超时,超时则 fallback 到贪心算法。多个 global batch 的打包并行用 multiprocessing 执行。
Step 3:跨 batch 合并
每个 global batch 的最后一个 microbatch 往往是欠填充的(last microbatch 问题)。LoRAFusion 在满足 Bubble Lemma 的前提下,把下一个 global batch 的开头 token 挪进来填充,减少 pipeline bubble。
系统异步性保障:调度时间线性增长(每个样本约 4ms CPU 时间),但调度本身和 GPU 训练并行执行,overhead 被隐藏在 GPU 计算时间内。
5. 实验设置和结果
5.1 实验设置
- GPU:NVIDIA H100(80GB,NVLink)和 L40S(48GB,PCIe)
- 模型:LLaMa-3.1-8B、Qwen-2.5-32B、LLaMa-3.1-70B
- 数据集:XSum、CNN/DailyMail、WikiSum(摘要任务)
- 实验配置:同时 fine-tune 4 个 LoRA adapter
- Baseline:Megatron-LM(FSDP 和 PP)、mLoRA
5.2 端到端结果
如下图,在 H100 上训练 4 个 LoRA adapter 的端到端 throughput 对比:
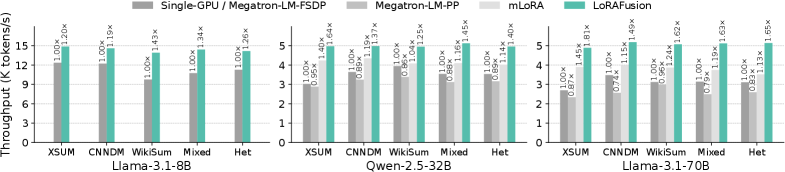
核心数字:
- 相比 Megatron-LM:最高 1.96×,平均 1.47× 提升
- 相比 mLoRA(SOTA multi-LoRA):最高 1.46×,平均 1.29× 提升
不同模型的收益规律:
- LLaMa-3.1-8B(单卡):平均 1.26×,主要来自 FusedLoRA kernel,因为单卡不存在 pipeline bubble
- Qwen-2.5-32B / LLaMa-3.1-70B(多卡分布式):平均 1.42×/1.64×,调度层面的优化贡献更大
- WikiSum 数据集(sequence length 方差极大):LoRAFusion 在 baseline 出现 OOM 的情况下仍能稳定运行
如下图,在 L40S 上的对比结果:
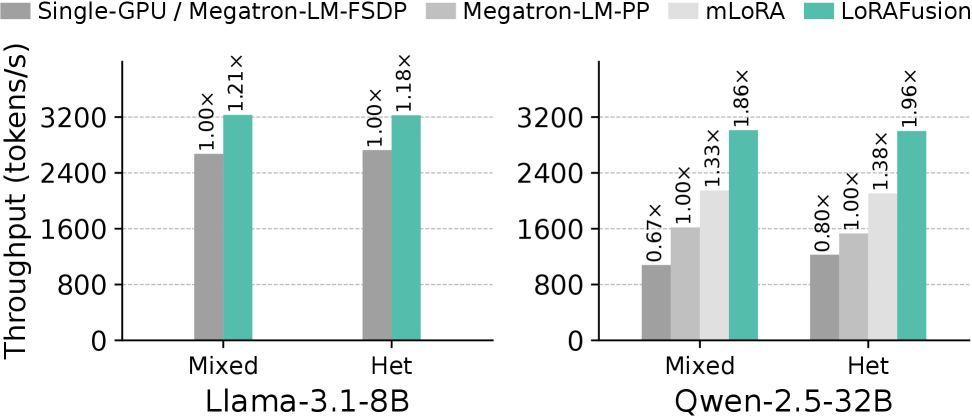
L40S 的绝对提升略小(单卡显存有限,限制了 batch size),但 LoRAFusion 依然保持领先。
5.3 扩展性
如下图,在 4、8、16 卡 H100 上的扩展性对比(DP scaling vs Job scaling):
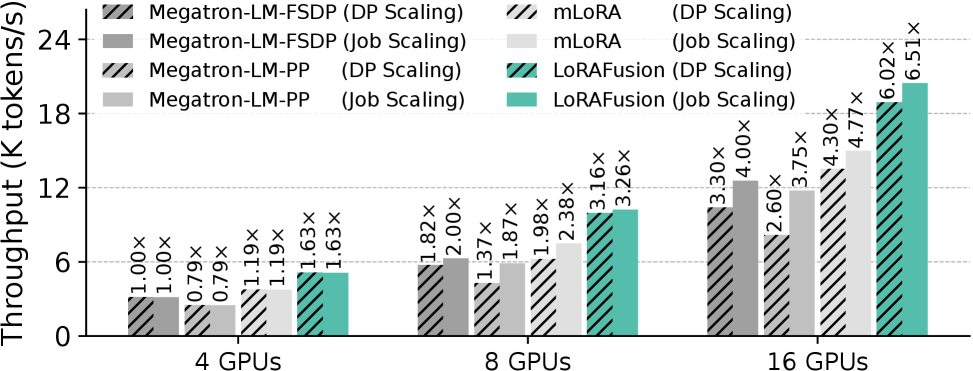
关键发现:Job-level scaling(用更多 GPU 跑更多并行 job)优于 DP scaling(用更多 GPU 扩展同一 job),在 8 和 16 卡时分别高出 1.18× 和 1.25×。
原因很直接:更多的 job 提供了更大的 global batch,调度灵活性更高,pipeline bubble 更少。LoRAFusion 同时兼容 DP scaling,在 DP scaling 场景下也比 Megatron-LM 快 1.78×,比 mLoRA 快 1.50×。
5.4 Kernel 性能
如下图,FusedLoRA 和 FusedMultiLoRA kernel 的吞吐量对比:
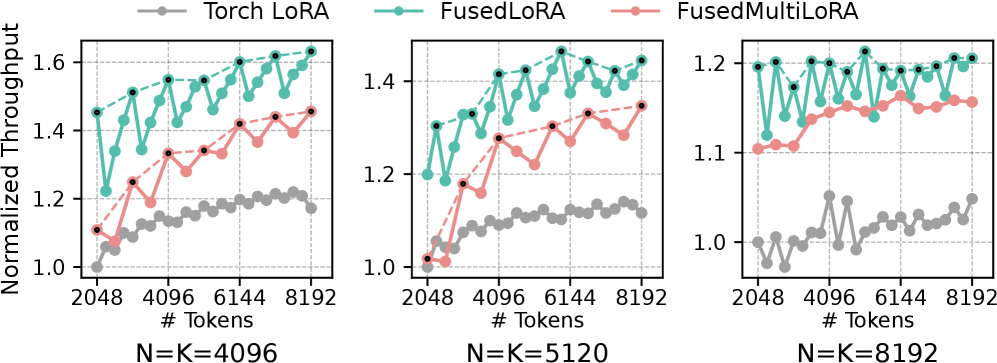
- FusedLoRA:平均 1.27×(最高 1.39×)
- FusedMultiLoRA:平均 1.17×(最高 1.24×)
FusedMultiLoRA 在反向传播时需要额外累加多个 adapter 的梯度,有轻微 overhead,但整体依然显著优于 baseline。
如下图,内存流量实测(Nsight Compute):
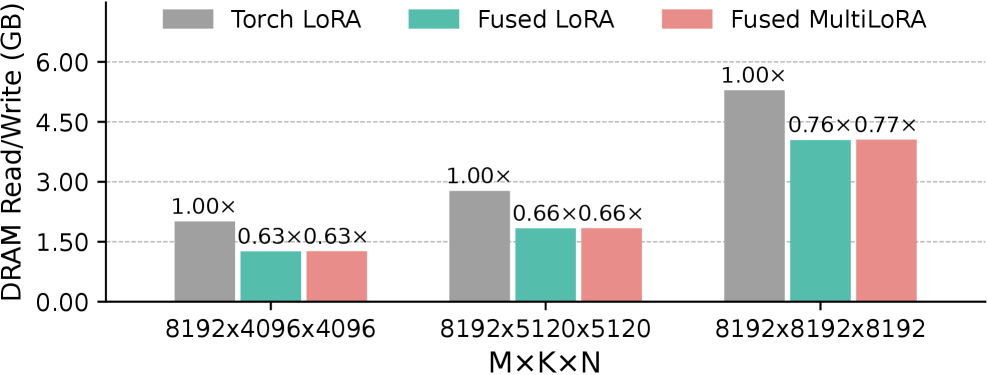
DRAM 总流量减少 34%~37%,和理论分析完全对应。
5.5 Pipeline Bubble 消减
如下图,不同 adapter 数量下 LoRAFusion 的 pipeline bubble 比率:
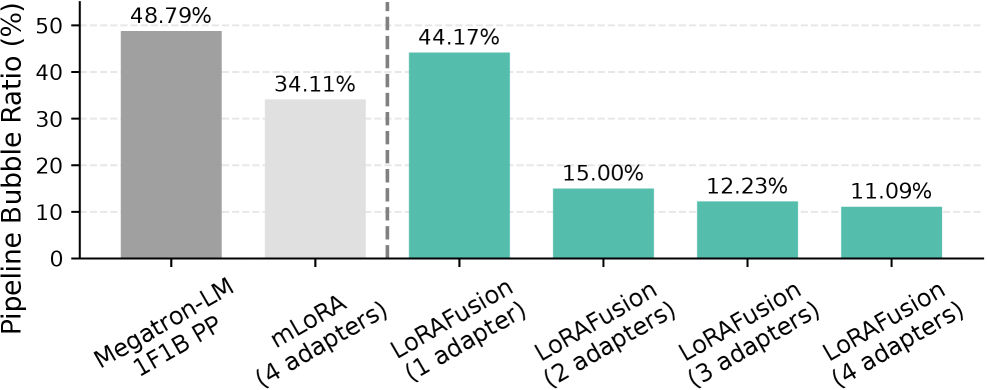
- Megatron-LM(单 adapter):48.79%
- mLoRA(4 adapter):34.11%
- LoRAFusion(4 adapter):11.09%
bubble 从将近一半降到一成,调度的效果非常明显。
5.6 Speedup 分解
如下图,LoRAFusion 在 LLaMa-3.1-70B(4 H100)上的加速分解:

从 Megatron-LM baseline 开始,各组件的贡献:
| 累加组件 | 相对 Megatron-LM 加速 |
|---|---|
| + FusedLoRA | 1.13× |
| + Multi-LoRA Zero-Bubble PP | 1.50× |
| + FusedMultiLoRA | 1.72× |
| + Adaptive Scheduling | 2.05× |
kernel fusion + pipeline 调度 + 负载均衡,三个维度缺一不可,组合起来才是最终的 2× 提升。
6. 一些延伸思考
为什么 torch.compile 解决不了这个问题?
torch.compile 有 compiler-based fusion,但测试结果是对 forward pass 几乎零收益,backward 只有可以忽略的微小改善。原因是 LoRA 的计算图结构对 torch.compile 的 fusion 规则来说不够”友好”——大 activation tensor 在多个分支之间共享,编译器难以自动找到减少内存 traffic 的最优分裂点。LoRAFusion 的 graph-splitting 策略本质上是一个领域特定的 kernel 设计,需要对 LoRA 结构有深入理解。
Kernel 可以直接插入现有系统?
是的,FusedLoRA kernel 可以作为 plug-and-play 替换,直接接到 PEFT Library、LLaMa-Factory 等现有系统上。论文中验证了数值精度等价,不影响模型质量。这个”即插即用”的设计思路值得借鉴——优化和算法分离,降低落地门槛。
LoRA 变体怎么办(DoRA/VeRA)?
论文讨论了可扩展性:这些变体的核心 LoRA 计算结构不变,只是在外面套了 prologue/epilogue 函数,LoRAFusion 的 kernel 可以通过添加这些函数来扩展。更通用的方案是集成进 torch.compile 的 compiler 框架,未来工作。
7. 总结
LoRAFusion 找到了两个被现有系统忽视的问题,并给出了系统性的解法:
- 内存带宽浪费:LoRA 参数只有 0.3%,但大 activation tensor 的重复加载导致 40% 吞吐量下降。LoRAFusion 用 graph-splitting + 横向 kernel fusion 把内存流量减少 34%~37%
- Multi-LoRA 机会未被利用:多 job 并行时的 pipeline bubble 和 load imbalance。LoRAFusion 用 Bubble Lemma 约束的 adapter 分组 + 两阶段 MILP bin-packing,把 bubble 从 48% 压到 11%
两者结合,端到端吞吐量最高提升 1.96×(平均 1.47×),而且代码已经开源,kernel 部分可以直接插到现有系统里。
对做 LLM fine-tune 的工程师来说,这篇工作的实用价值很直接。感兴趣的可以去试一下:github.com/CentML/lorafusion
欢迎评论区交流~
作者:Zhanda Zhu, Qidong Su, Yaoyao Ding, Kevin Song, Shang Wang, Gennady Pekhimenko(University of Toronto / Vector Institute / NVIDIA) 发表于:EuroSys ‘26(2026年4月)