layout: post title: “MoE 推理的 KV Cache 问题,PiKV 是怎么解的” date: 2026-05-12 tags: [LLM, MoE, KV Cache, 推理系统, 论文解读] —
原文:PiKV: KV Cache Management System for Mixture of Experts
代码:NoakLiu/PiKV
你用过 DeepSeek、Mixtral 这类 MoE 模型的人,可能听说过它们的卖点:稀疏激活。
什么叫稀疏激活?普通 Transformer 每一层都要跑完整个 FFN(前馈网络)。MoE 的做法是把这个 FFN 拆成 N 个”专家”(expert),每次只让其中 k 个专家干活。比如有 16 个 expert,每个 token 只激活 2 个,那理论上计算量就压缩到了 1/8。
这是 MoE 能撑得住更大参数规模的根本原因——参数很多,但每次推理真正用到的只是一小部分。
听起来很美。但我们自己跑 MoE 模型的时候,结结实实踩了一个坑:
显存怎么还是这么大?latency 怎么没降多少?
问题出在 KV Cache 上。
先简单解释一下 KV Cache 是干嘛的,不熟悉的同学看这段,熟悉的可以跳过。
自回归生成时,每生成一个新 token,模型需要对它和前面所有 token 做 attention。这意味着:第 100 个 token 生成时,要对前 99 个 token 的 Key(K)和 Value(V)做一次 attention 计算。
如果每次都重新算前面所有 token 的 K 和 V,计算量太大。所以实际工程里,我们把每一步生成的 K、V 存下来,下次直接读取,这就是 KV Cache。
问题是:随着上下文越长,KV Cache 越大。一个 7B 规模的 MoE 模型,128K context、16 个 expert,全量 KV Cache 超过 24GB。
而且注意:KV Cache 是 dense 的。
MoE 把 FFN 变稀疏了,但 attention 还是全量的。每个 token 的 K、V 不管它被哪个 expert 处理,都要全部存下来,还要在多 GPU 之间全量同步。
这就是问题的根源:
MoE 的计算稀疏了,但内存访问模式还是 dense 的。
稀疏 expert 带来的计算收益,被 dense KV Cache 的存储和通信开销给吃掉了。
PiKV 这篇工作就是直接冲这个矛盾来的——既然 expert 的计算可以稀疏,KV Cache 的管理也应该感知 expert 的稀疏性。
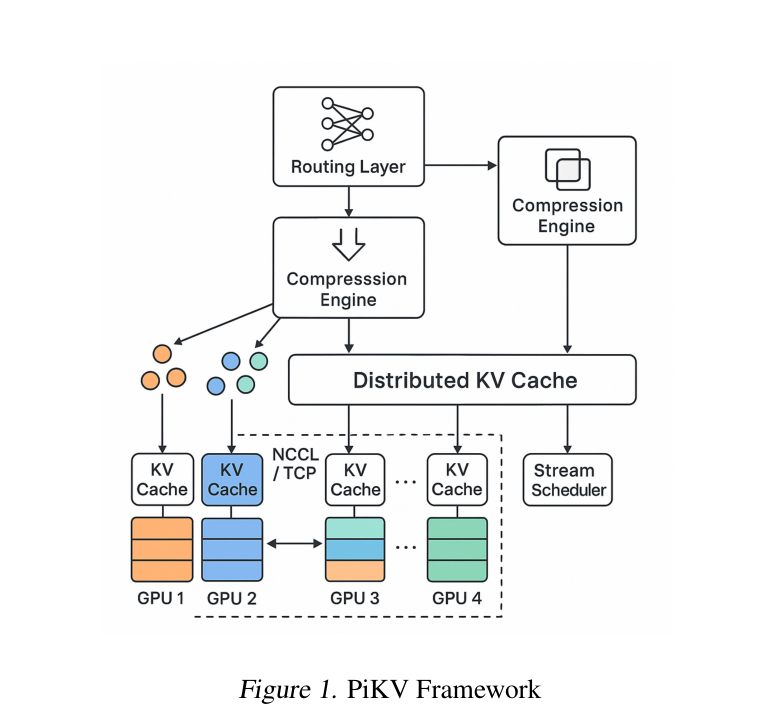
先看下整体框架:
如上图,PiKV 分为四个模块,从上到下:
这四个模块不是孤立的——routing 的决策参考了 cache 命中率,compression 的参数影响 scheduling 的内存预算,scheduler 的元数据又反馈给 routing。
下面逐一拆解。
问题: 传统做法是每个 GPU 都存一份完整的 KV Cache,多 GPU 部署时相当于做了冗余复制。16 个 expert、每个 expert 都有对应的 KV,每台 GPU 全量存,显存占用 = $O(E \cdot L)$,$E$ 是 expert 数,$L$ 是序列长度。
PiKV 的做法: 按 token 和 expert 的组合做哈希,把不同 token 的 KV 分散到不同 GPU 上:
\[s(t, e) = (t \bmod N_{\text{tok}}) \oplus (e \bmod N_{\text{exp}})\]这里 $s$ 是 shard id,$t$ 是 token 位置,$e$ 是 expert id。每个 GPU 只存 $O(L/G + L/E)$ 的 KV,$G$ 是 GPU 数量。
举个具体例子:16 个 expert、8 个 GPU、序列长度 L=128K:
理论上节省了约 83%。
每个 shard 内部用环形 buffer(circular buffer)管理,插入代价 $O(1)$,不需要动态 reallocation。
路由这件事,普通 MoE 只问一个问题:这个 token 应该发给哪些 expert?
PiKV 额外问了一个问题:发给哪些 expert 的 cache 命中代价最低?
如下表,PiKV 支持 7 种路由策略,从简单到复杂:
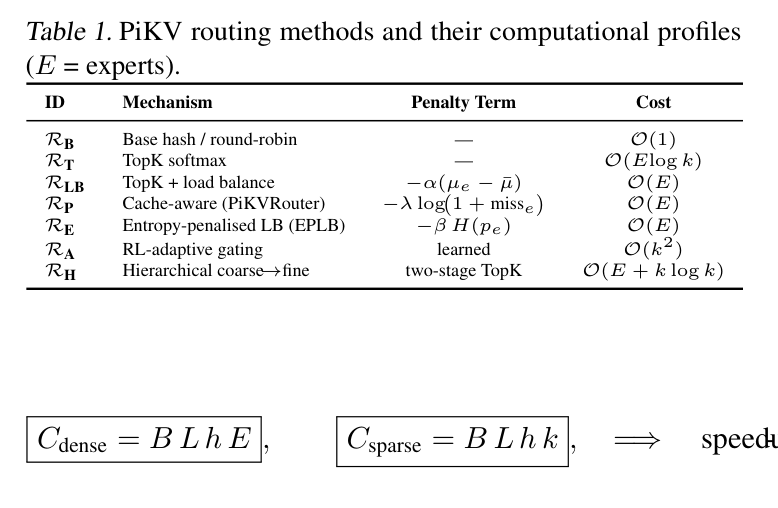
逐个解释:
$\mathcal{R}_B$(base hash/round-robin): 最简单,直接哈希分配,代价 $O(1)$,完全不考虑 cache 状态和负载均衡。
$\mathcal{R}_T$(TopK softmax): 标准 MoE 做法。计算每个 expert 的 softmax 分数,取前 k 个,代价 $O(E \log k)$。不考虑 cache。
$\mathcal{R}_{LB}$(TopK + load balance): 在 TopK softmax 基础上加了负载均衡惩罚项 $-\alpha(\mu_e - \bar{\mu})$,让负载分布更均匀,防止某些 expert 过热。
$\mathcal{R}_P$(PiKVRouter,cache-aware): 这是核心创新。在 TopK softmax 的基础上,加了 cache miss 惩罚项:$-\lambda \log(1 + \text{miss}_e)$。cache miss 率越高的 expert,被选中的代价越大,从而让路由倾向于选 cache 热的 expert。
$\mathcal{R}_E$(EPLB,entropy-penalised): 用 entropy $-\beta H(p_e)$ 做惩罚,鼓励路由分布更确定(低熵),减少负载的随机性。
$\mathcal{R}_A$(RL-adaptive): 用强化学习训练路由策略,overhead 最大($O(k^2)$),但最自适应。
$\mathcal{R}_H$(Hierarchical): 两阶段,先粗粒度选出候选 expert,再细粒度 TopK,代价 $O(E + k\log k)$。
最有工程意义的是 $\mathcal{R}_P$。传统路由完全不知道系统状态,PiKV 把 cache miss 率这个运行时信息反馈进来,本质上是在做 locality-aware scheduling——和 CPU 缓存调度的思想是一致的,只是搬到了 LLM serving 场景。
路由稀疏化带来的理论收益:
\[\text{speed-up} = \frac{E}{k}, \quad \text{memory relief} = \frac{E}{k}\]16 个 expert、每 token 激活 2 个:计算量和 KV fetch 都压到 $1/8$。
KV 存下来之前还要压缩,进一步省显存。PiKV 支持一套完整的压缩方法:
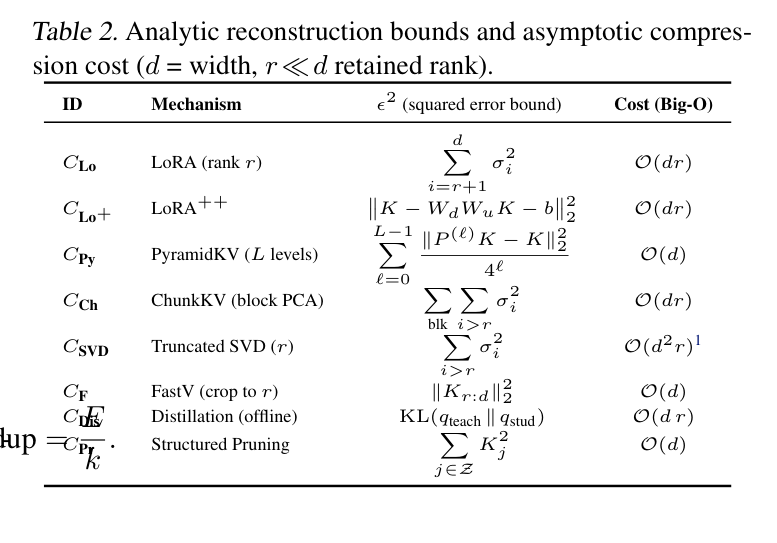
表里的 ID 对应的是不同压缩方法,比如:
$C_{Lo}$(LoRA,rank $r$): 把 K/V 用低秩矩阵近似,误差上界 $\sum_{i=r+1}^{d} \sigma_i^2$(丢掉后 $d-r$ 个奇异值对应的分量),代价 $O(dr)$。
$C_{Py}$(PyramidKV,$L$ levels): 层级化压缩,浅层保留更多 token,深层保留更少,利用 attention pattern 的层次结构。
$C_{SVD}$(Truncated SVD,$r$): 直接做 SVD,保留前 $r$ 个奇异值,是最精确的低秩近似之一,但代价 $O(d^2 r)$ 偏高。
$C_{F}$(FastV): 直接把 K 截到前 $r$ 个维度,误差 $|K_{r:d}|_2^2$,最粗暴但也最快。
设压缩比 $\rho = d/d’$($d$ 是原始维度,$d’$ 是压缩后维度),一次 step 的延迟:
\[T_{\text{step}} = \frac{dk B}{\rho} \left(\frac{2}{\beta} + \frac{\eta}{\gamma}\right)\]$\beta$ 是 HBM 带宽,$\gamma$ 是计算吞吐,$k$ 是激活的 expert 数,$B$ 是 batch size。
说人话:$\rho$ 越大,读 cache 的数据越少,decode 时间越短,基本线性关系,直到 decode 本身变成新的瓶颈。
显存总有上限。Scheduling 解决的是:在有限内存下,哪些 KV cache 页值得留,哪些该踢?
如下表,PiKV 支持 8 种调度策略:

每种策略都对应一个 utility score $u_i$,根据 $u_i$ 的大小决定 eviction 顺序:
这里有个值得关注的设计细节:adaptive threshold vs. fixed threshold。
固定门限(如 H2O、SL)对内存预算固定、workload 稳定的场景够用,但如果 batch 里来了长短差异很大的请求,固定门限容易过激或过保守。自适应门限(如 QUEST、AdaKV)会根据实际 hit rate 动态调整,更稳健。
内存分析上,论文给出了一个设计规则。给定压缩比 $\rho$、token 数 $L$、GPU 数 $G$、保留页数 $K$,最优 buffer size 是:
\[S^* = \sqrt{\frac{L}{K \cdot G}}\]代入后总显存:$\mathcal{M}_{\text{total}}^* = \frac{4d}{\rho}\sqrt{\frac{KL}{G}}$
这是一个明确的工程公式:给定预算,直接算出该设多大的 buffer。
如下是 PiKV 的整体执行逻辑(Algorithm 1):

流程很清晰:
关键在于:各模块通过 metadata 传递信息。compression 写入时记录压缩比、大小、时间戳;scheduling 读取这些 metadata 更新 utility score;routing 读取 cache miss 率,调整下一步的 expert 选择。这四个模块形成了一个闭环——每一步都在影响下一步的决策。
这篇论文(v2)把完整实验放在了 GitHub README 而不是 PDF 正文。直接说结论:
在不同模型和配置组合下,PiKV 相比 Standard MoE baseline:
值得注意的是,不同模块组合带来的收益差异很大,具体选哪种 router + compressor + scheduler 的组合,需要根据 workload 调整。
PiKV 做的事情,用一句话概括:
把 MoE 的稀疏性从”计算层”传导到”存储层”。
普通 MoE 推理框架只把稀疏性用在了 expert 的计算选择上,KV Cache 这一块还是 dense 的遗留逻辑。PiKV 说:storage 也该感知 expert 的稀疏结构,routing 的选择要考虑 cache cost,cache 的管理要按 expert 分片。
这个方向是对的,而且会越来越重要。随着 DeepSeek、Qwen MoE 这类模型在生产中的规模越来越大,serving 的瓶颈必然从计算转向 memory 和 communication。到那个时候,只让计算稀疏是不够的。
当然也有几个保留意见:
不过作为一个系统框架,思路清晰,代码也开源了,有做 MoE serving 的同学可以跑起来看看。
有问题或者发现描述有误欢迎评论区交流。