延迟降47%!FineMoE如何用「细粒度」打破MoE推理的显存-延迟死局
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

延迟降47%!FineMoE如何用「细粒度」打破MoE推理的显存-延迟死局
原文:Taming Latency-Memory Trade-Off in MoE-Based LLM Serving via Fine-Grained Expert Offloading
1. 前言
今天想和大家聊聊这篇刚被 EuroSys ‘26 接收的工作——FineMoE。
研究方向是 MoE 推理优化的同学应该都知道,这个领域有一个结结实实的大坑:MoE 模型的参数很多,但推理时真正用到的 expert 只是少数,绝大多数 expert 参数全程闲着。以 Mixtral-8×7B 为例,每次推理激活的 expert 比例只有 28%,也就是说有 72% 的参数在 GPU 显存里白占着位置,换算下来是 67 GB 的显存在”陪跑”。
一个自然的思路是:把不用的 expert 卸载到 CPU 内存,用的时候再加载回来。但问题来了——怎么知道下一步要用哪个 expert?预测准了就能提前 prefetch,预测错了就得临时从 CPU 搬运,这个搬运延迟可能高达数百毫秒,直接拖垮推理速度。
这就是 显存-延迟 trade-off 的核心矛盾:要么全部放在 GPU 里(不卸载,显存爆炸),要么卸载到 CPU(显存省了,但 hit miss 时延迟暴增)。
现有方案在这个 trade-off 上踩了坑——它们要么低延迟但显存占用大,要么显存小但延迟高。FineMoE 的切入点很简单:现有方案太”粗粒度”了,预测准确率不够高,所以才陷入两难。
2. 背景:LLM Serving 和 MoE 的基本逻辑
先交代下背景。
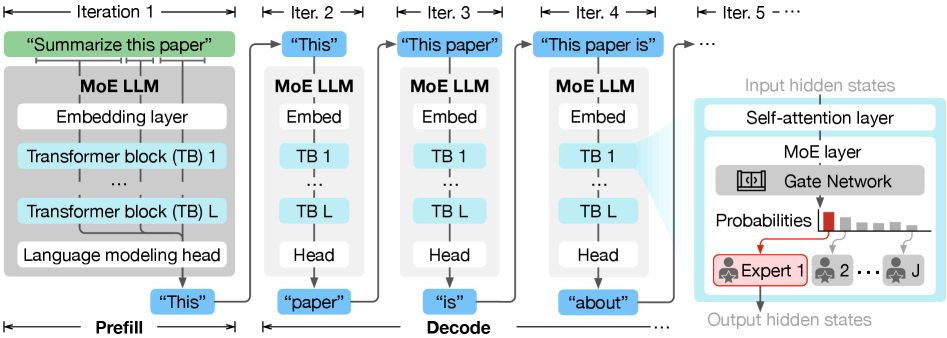
LLM serving 分两个阶段:prefill 和 decode。
- Prefill:一次性处理所有输入 token,生成第一个输出 token,只跑一次,是 compute-bound 的,用 TTFT(Time-To-First-Token)衡量。
- Decode:自回归逐 token 生成,每次用之前的输出预测下一个 token,是 memory-bound 的,用 TPOT(Time-Per-Output-Token)衡量。
MoE 层的结构是:每个 Transformer block 里,把原来的 FFN 替换成一组 expert 网络 + 一个 gate 网络。gate 网络决定当前 token 激活哪 Top-K 个 expert。比如 Mixtral-8×7B 每层有 8 个 expert,每次只激活 2 个(Top-2)。
如下图,Mixtral、Qwen1.5-MoE、Phi-3.5-MoE 三个典型 MoE 模型的参数统计:
| 模型 | 激活参数 / 总参数 | Top-K / 专家数 | MoE层数 |
|---|---|---|---|
| Mixtral-8×7B | 12.9B / 46.7B | 2 / 8 | 32 |
| Qwen1.5-MoE | 2.7B / 14.3B | 4 / 60 | 24 |
| Phi-3.5-MoE | 6.6B / 42B | 2 / 16 | 32 |
72%、81%、84% 的参数在推理中从不被激活,分别对应 67 GB、23 GB、70 GB 的显存浪费。
3. 现有方案为什么不够好
3.1 设计空间概览
如下图,MoE serving 的设计空间分两大类:
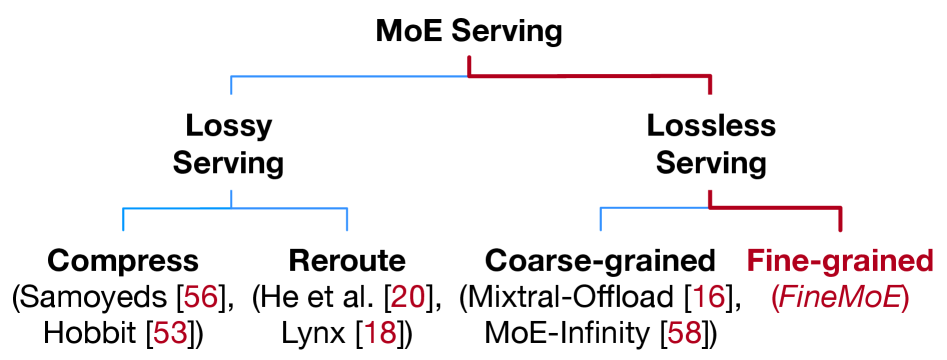
- Lossy serving:压缩、剪枝、量化——省显存,但损精度
- Lossless serving:卸载权重,保精度——这是 FineMoE 的赛道
Lossless offloading 里,有几个代表性方案:
- DeepSpeed-Inference:按层卸载,没有 expert 预取,每次都需要 on-demand 加载,延迟最差
- Mixtral-Offloading:用 LRU 缓存 + 投机式预取,同步预取会拖慢推理
- MoE-Infinity:追踪 request 级别的 expert 激活矩阵,异步预取,但预测粒度太粗
- ProMoE:训练预测器来预测 expert,准确率高但需要训练,开销大
这些方案的问题,一句话总结:它们都在 request 级别(粗粒度)追踪 expert 激活模式,而不是 iteration 级别(细粒度)。
3.2 粗粒度 vs 细粒度:信息熵说明一切
为什么粗粒度不好用?论文用 Shannon 熵量化了这个问题。
如下图,分别展示了粗粒度(request 级别)和细粒度(iteration 级别)的 expert 激活热图:
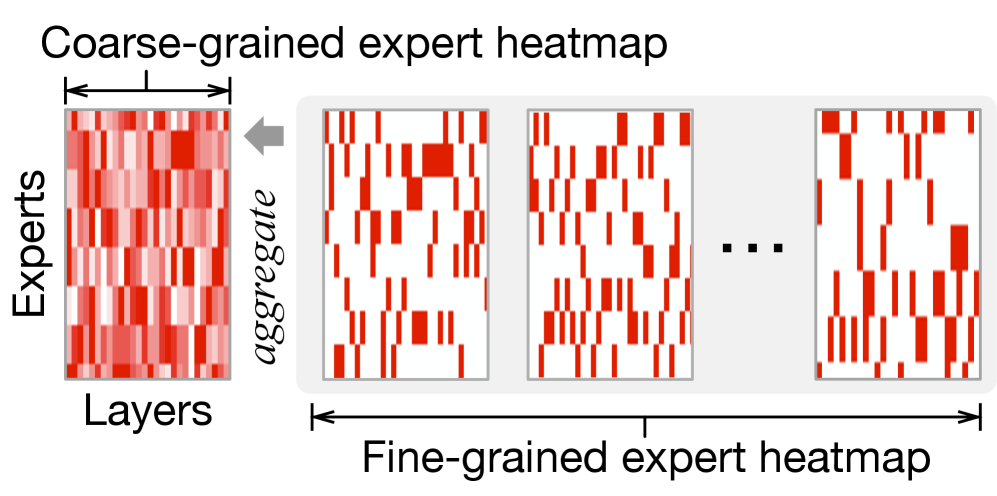
核心结论:粗粒度的 expert 激活熵显著高于细粒度,也就是说粗粒度的模式更难预测。更致命的是,随着 decode 迭代次数增加,request 级别的熵还会持续上升——因为越来越多的 expert 激活信息被聚合进去,模式越来越”平均化”,越来越难以区分。
如下图,细粒度 offloading 的 expert hit rate 在不同 prefetch distance 下都显著高于粗粒度:
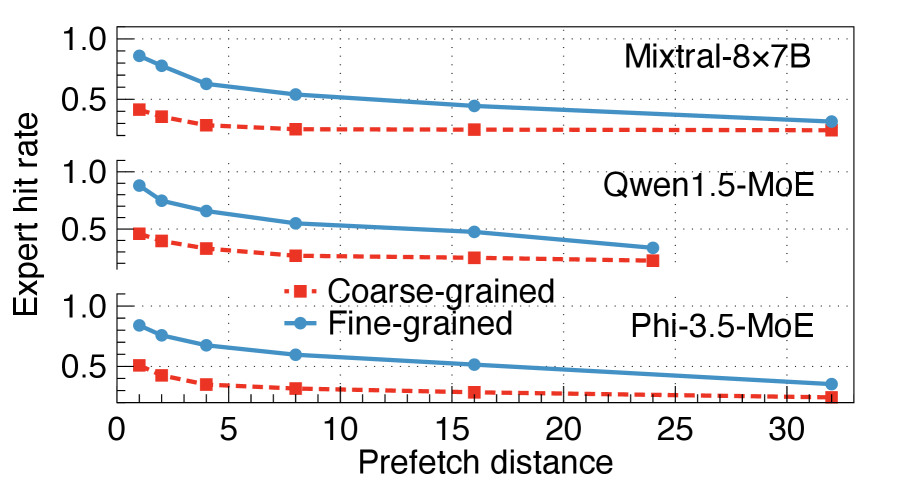
这个分析直接支撑了 FineMoE 的核心论点:要想准确预测 expert 激活,必须做细粒度的 iteration 级别分析,而不是 request 级别。
4. FineMoE 的方案
FineMoE 的设计围绕三个目标展开:
- 低显存占用 + 低推理延迟(打破 trade-off)
- 最小化 expert miss(减少 on-demand 加载)
- 自适应不同 MoE 模型和不同 prompt(不搞 one-fits-all)
4.1 整体架构
如下图,FineMoE 由三个核心组件构成:
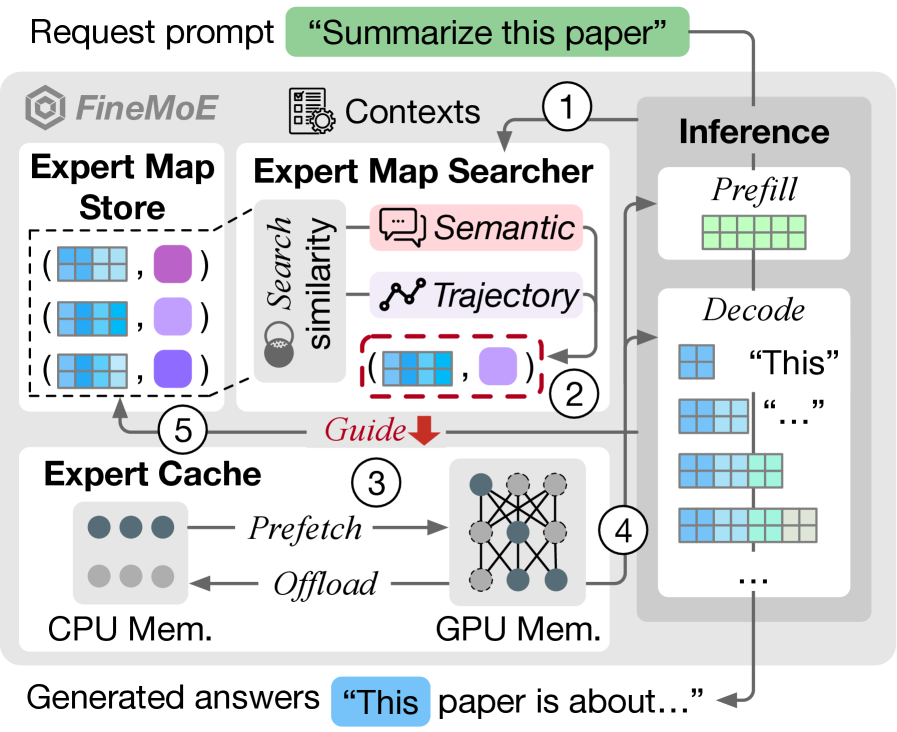
- Expert Map Store:存储历史 expert 激活模式(以 expert map 为单位)
- Expert Map Searcher:收到新 prompt 时,搜索最相似的历史 expert map
- Expert Cache:GPU 上缓存 expert 权重,管理 prefetch 和 eviction
五步工作流:
- 收集推理上下文(语义 embedding + 历史 expert 激活轨迹)
- 搜索最匹配的 expert map
- 根据搜索结果决定 prefetch 哪些 expert
- 推理执行(hit → 直接用;miss → on-demand 加载)
- 更新 Expert Map Store
4.2 Expert Map:细粒度的核心数据结构
Expert Map 是 FineMoE 的核心创新。
传统方案(如 MoE-Infinity)只记录 expert 的 hit count(某个 expert 在 request 里被激活了多少次)。FineMoE 不一样——它记录每个 iteration 里,gate 网络输出的完整概率分布。
如下图,expert map 记录了每一层 gate 输出的概率分布:
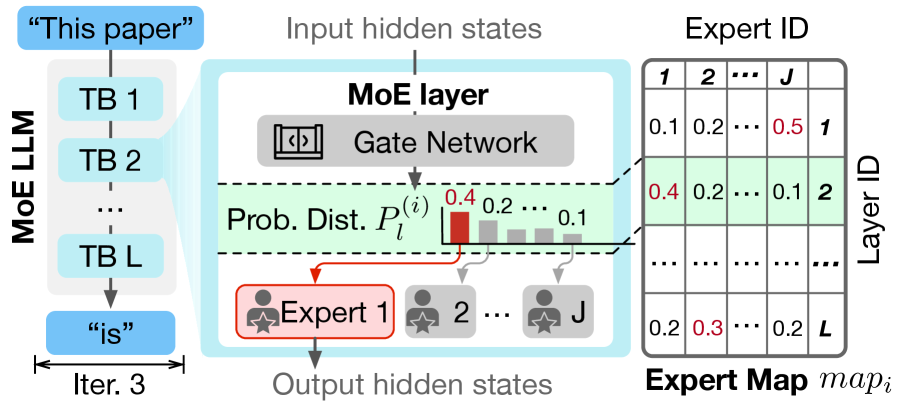
具体来说,第 i 次 iteration 的 expert map 定义为:
\[\text{map}_i = \{\mathbf{P}_1^{(i)}, \mathbf{P}_2^{(i)}, \ldots, \mathbf{P}_L^{(i)}\}\]其中 $\mathbf{P}_l^{(i)} \in \mathbb{R}^J$ 是第 l 层 gate 网络在第 i 次 iteration 的输出概率分布,$J$ 是 expert 总数。
和只记录 hit count 相比,expert map 有两个优势:
- 粒度更细:iteration 级别,不是 request 级别
- 信息更丰富:完整概率分布,不只是 0/1 的 hit/miss
4.3 双路搜索:语义 + 轨迹
知道了 expert map 长什么样,下一个问题是:给定一个新 prompt,怎么找到最相似的历史 expert map?
FineMoE 设计了两路搜索,分别对应推理的不同阶段:
如下图,两路搜索的工作流:
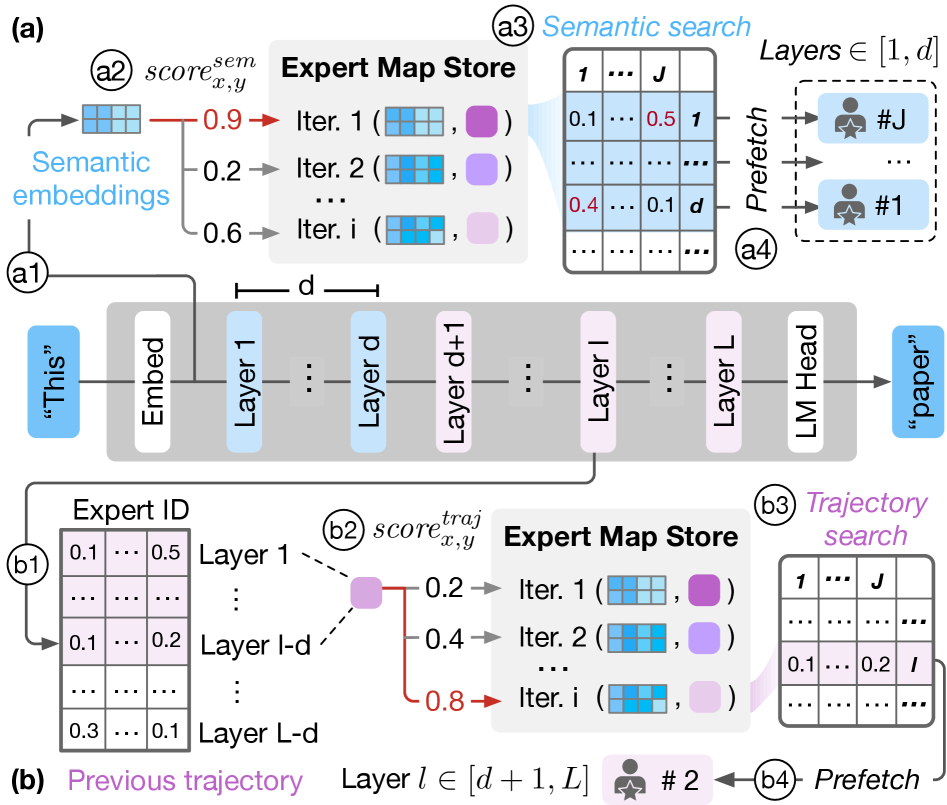
语义搜索(用于前 d 层)
在 prefill 阶段开始时,还没有任何 expert 激活历史,没法用轨迹。此时用 embedding 层的输出(语义 embedding)来查找相似的历史 prompt,找到对应的 expert map,指导前 d 层(d 是 prefetch distance)的 expert prefetch。
相似度用 cosine similarity 计算:
\[\text{score}_{x,y}^{\text{sem}} = \frac{\text{sem}_x^{\text{new}} \cdot \text{sem}_y^{\text{old}}}{\|\text{sem}_x^{\text{new}}\| \cdot \|\text{sem}_y^{\text{old}}\|}\]轨迹搜索(用于第 d+1 层之后)
从第 d+1 层开始,已经有了前面若干层的 expert 激活概率轨迹。这时用当前轨迹去匹配历史的 expert map,预测后续层的 expert 激活。同样是 cosine similarity:
\[\text{score}_{x,y}^{\text{traj}} = \frac{\text{map}_x^{\text{new}} \cdot \text{map}_y^{\text{old}}}{\|\text{map}_x^{\text{new}}\| \cdot \|\text{map}_y^{\text{old}}\|}\]如下图,两路搜索的 Pearson 相关系数分析证明,不管是语义相似度还是轨迹相似度,与 expert hit rate 都有显著的正相关:

这个分析很关键——它从理论上说明了”用相似 prompt 的历史 expert map 来指导当前的 expert prefetch”这个思路是站得住脚的。
4.4 自适应 prefetch:相似度越高,prefetch 越少
找到最相似的历史 expert map 后,怎么决定 prefetch 哪些 expert?
FineMoE 根据相似度分数动态调整预取数量,设计了一个动态阈值 $\delta_l$:
\[\delta_l = \text{Clip}(1 - \text{score}, 0, 1)\]逻辑很直观:
- 相似度高 → score 接近 1 → $\delta$ 接近 0 → 按概率选少量高把握的 expert prefetch
- 相似度低 → score 接近 0 → $\delta$ 接近 1 → 多 prefetch 一些以对冲不确定性
然后按概率从高到低累加,直到超过 $\delta$ 为止,这些 expert 就是要 prefetch 的集合。
4.5 异步架构:搜索不阻塞推理
现有方案(如 MoE-Infinity)的一个大问题是同步预取——要等 expert 预测和 prefetch 完成后才能继续 forward,等待时间直接加进延迟里。
FineMoE 用 Publisher-Subscriber 异步架构解决了这个问题:
- 推理进程负责向 Expert Map Store 发布上下文数据(语义 embedding、expert 概率分布)
- Expert Map Searcher 订阅数据,异步进行相似度计算和 expert prefetch
- 两个过程并行,互不阻塞
系统测量结果:异步操作引入的额外延迟不超过 50ms(约占单次 iteration 总延迟的 1%),基本可以忽略不计。
4.6 Expert Map Store 去重:保持多样性
Expert Map Store 有容量限制,不能无限存。当新的 iteration 数据进来时,FineMoE 计算它与历史数据的”冗余度”,用两路相似度的加权组合:
\[\text{RDY}_{x,y} = \frac{d}{L} \cdot \text{score}_{x,y}^{\text{sem}} + \frac{L-d}{L} \cdot \text{score}_{x,y}^{\text{traj}}\]冗余度高的旧 map 会被新 map 替换,保证 store 里的 expert map 尽量多样、有代表性。
论文还做了理论分析:保持至少 $\frac{1}{2}LJ \ln(LJ)$ 个 expert map,可以保证 98% 的相似度下界(即对于任意新 prompt,都能找到至少 98% 相似的历史 map)。实测下来,1K 大小的 store 足够,对应不到 200 MB CPU 内存。
5. 实验设置和结果
5.1 实验设置
- 硬件:6 × NVIDIA RTX 3090(24GB 显存),PCIe 4.0 互联,AMD Ryzen Threadripper PRO 3955WX + 480 GB CPU 内存
- 模型:Mixtral-8×7B、Qwen1.5-MoE、Phi-3.5-MoE
- 数据集:LMSYS-Chat-1M(真实用户对话)、ShareGPT
- Baseline:DeepSpeed-Inference、Mixtral-Offloading、ProMoE、MoE-Infinity
- 指标:TTFT(prefill 阶段)、TPOT(decode 阶段)、expert hit rate
5.2 整体性能(Offline Serving)
如下图,FineMoE 在三个模型、两个数据集上全面领先:
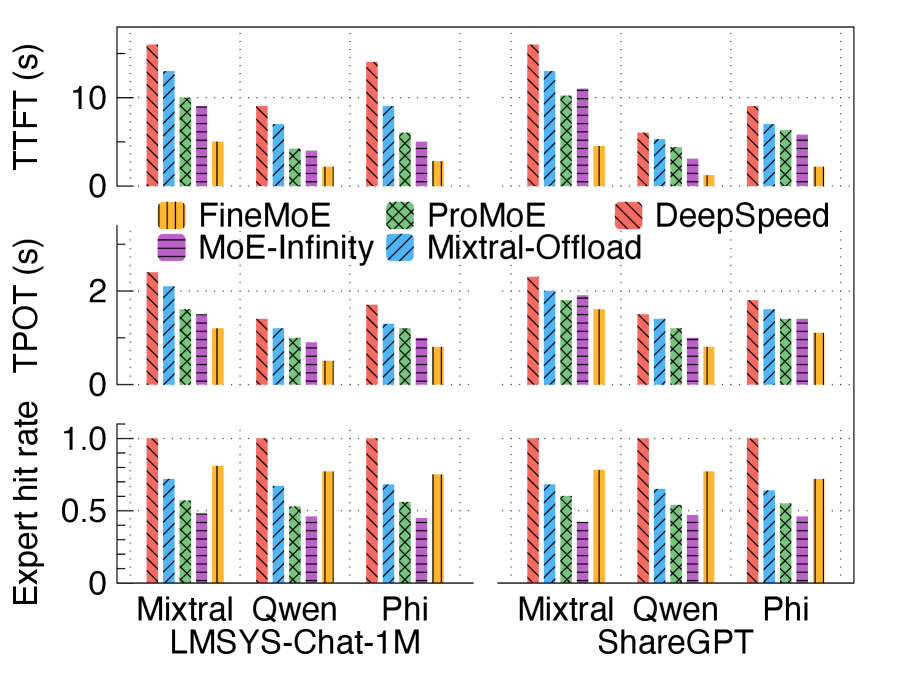
核心数字:
- 相比 DeepSpeed-Inference:TTFT 平均降低 74%,TPOT 平均降低 46%
- 相比 MoE-Infinity(最强 baseline):TTFT 平均降低 53%,TPOT 平均降低 22%
- Expert hit rate 相比 Mixtral-Offloading/ProMoE/MoE-Infinity 分别提升 14%/37%/68%
离谱的是,即使和”完全不卸载(No-offload)”的全量 GPU 方案相比,FineMoE 在显存大幅节省的同时,延迟也没有显著恶化。
5.3 在线服务(Online Serving)
如下图,在模拟真实在线流量(Azure LLM 推理 trace,256 个请求,2.91 req/s)下,FineMoE 的端到端请求延迟 CDF 曲线明显优于所有 baseline:

特别是 P90/P99 尾延迟,FineMoE 的优势更明显。这对实际线上服务来说非常关键——SLA 通常是看尾延迟的。
5.4 不同显存限制下的表现
如下图,在不同 GPU 显存 cache 限制(6 GB 到 96 GB)下,FineMoE 始终保持领先:

在显存极度受限(6 GB cache)时,FineMoE 相比 MoE-Infinity 的 TPOT 降低 29%。随着显存增大,各方案差距缩小(因为大家都能缓存更多 expert),但 FineMoE 始终在帕累托前沿。
5.5 高端 GPU(A100)上的表现
如下图,在 80 GB HBM2e A100 上测试,FineMoE 的相对优势有所收窄(因为高端 GPU 的 expert on-demand 加载速度更快),但仍然全面优于所有 baseline:
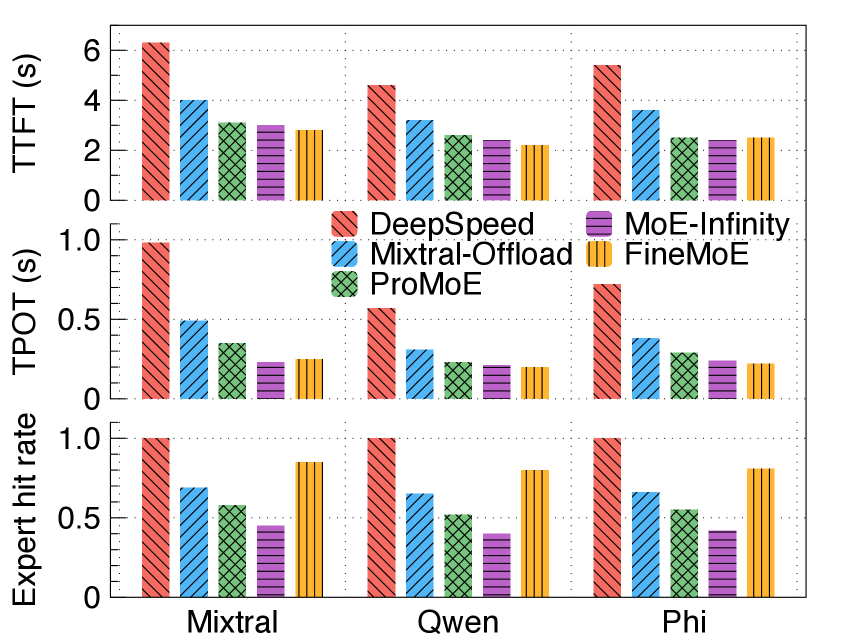
这也说明 FineMoE 的优势主要来自”更准的预测”(expert hit rate),而不是依赖特定硬件。
5.6 消融实验
如下图,逐步开启 FineMoE 各个设计组件后,expert hit rate 的变化:
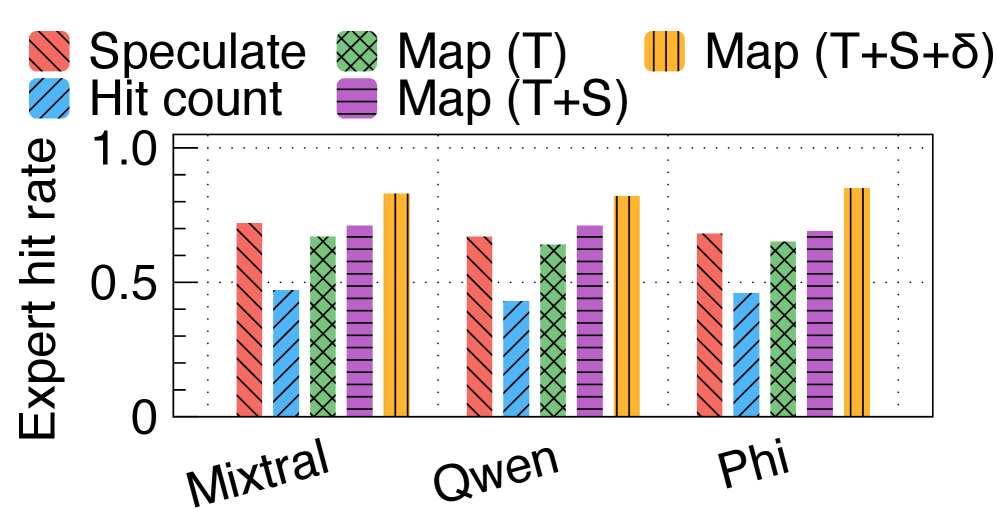
从 Speculate → Hit count → Map(T) → Map(T+S) → Map(T+S+δ),hit rate 逐级提升:
- 投机预测(Mixtral-Offloading 的方式)在 prefetch distance 小时效果不错,但 distance 增大后急剧退化
- request 级别 hit count(MoE-Infinity 的方式)最差
- 加上轨迹搜索(T)→ 加上语义搜索(T+S)→ 加上动态阈值(T+S+δ),每一步都有提升
每个设计决策都是有贡献的,没有凑数的模块。
6. 一些值得关注的设计细节
为什么不用 NN-based 预测器?
ProMoE 用了训练好的 predictor 来预测每层的 expert。论文给出了不用 NN 的理由:
- 推理延迟高,predictor 本身的延迟有时和 MoE 推理延迟本身差不多
- 需要 per-layer 训练,每次换模型或 workload 都要重新训
- 参数量大,占用额外 GPU 显存
- 和细粒度设计不兼容:在细粒度数据上训练 NN 收敛困难
FineMoE 的 heuristic 方案(相似度搜索)不需要训练,开箱即用。
prefetch distance 怎么选?
三个模型的最优 prefetch distance 分别设为:
- Mixtral-8×7B:d = 3
- Qwen1.5-MoE:d = 6
- Phi-3.5-MoE:d = 4
distance 太小,异步操作来不及完成,还是会引入等待延迟;distance 太大,预测依据不足,hit rate 下降。需要 profile 一下找到最优点。
7. 总结与个人感受
FineMoE 这篇工作的思路很清晰:
- 发现了一个被忽视的问题:现有 MoE offloading 方案都在用粗粒度(request 级别)的 expert 激活模式,而 iteration 级别的细粒度模式预测准确率更高
- 设计了一个轻量的数据结构(expert map)来追踪细粒度模式,不需要额外训练
- 双路搜索(语义 + 轨迹)覆盖了 prefill 初期没有历史轨迹的盲区
- 异步架构让搜索和 prefetch 不阻塞推理
- 动态阈值让 prefetch 数量自适应搜索置信度
实验结果很扎实,47% 的延迟降低、39% 的 hit rate 提升,而且 Expert Map Store 只需要不到 200 MB 的 CPU 内存,系统 overhead 也控制在 1% 以内。
这类工作的价值在于:不改模型权重,不需要训练,直接插入现有 serving 框架(HuggingFace Transformers),落地成本低,工程可行性强。
对我们做 MoE 推理优化的人来说,FineMoE 提供了一个很好的视角:粒度是关键。很多时候系统设计在”粗粒度够用了”的假设下偷懒,但 FineMoE 用数据证明了细粒度确实有用,而且代价并不大。
感兴趣的同学可以去看一下原文,目前代码似乎还没有开源(至少文中没有提到代码仓库),期待后续放出。
欢迎评论区交流~
作者:Hanfei Yu, Xingqi Cui, Hong Zhang, Hao Wang, Hao Wang(Stevens Institute of Technology / Rice University / University of Waterloo / Rutgers University) 发表于:EuroSys ‘26(2026年4月)