让不同 LLM 之间共享 KV Cache?DroidSpeak 是怎么做到的
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

让不同 LLM 之间共享 KV Cache?DroidSpeak 是怎么做到的
原文:DroidSpeak: KV Cache Sharing for Cross-LLM Communication and Multi-LLM Serving
1. 前言:一个很自然但从没人解决过的问题
KV Cache 共享这件事,在单个模型的场景里已经做得很成熟了——vLLM 的 prefix caching、SGLang 的 RadixAttention,本质都是”同一个模型、不同请求共享相同前缀的 KV Cache”。
但有一个问题从来没人认真解决过:如果是两个不同的模型,能共享 KV Cache 吗?
听起来是个怪问题。为什么两个不同模型会需要共享 KV Cache?
在多 Agent 系统里,这其实很常见。比如一个 coding agentic workflow 里,有个 coding agent 和一个 testing agent,它们分别是从同一个基础模型 fine-tune 出来的不同版本。两个 agent 都要读同一套背景文档或对话历史,然后分别生成各自的输出。
按现在的做法,两个 agent 各自跑各自的 prefill,把同一段上下文算两遍——一遍都不能省。
这就是 DroidSpeak 要解决的核心问题:在分布式 LLM 推理系统里,让运行着不同模型的 GPU 节点之间,能够安全地共享 KV Cache,从而省掉重复的 prefill 计算。
来自芝加哥大学 + 微软的工作,今天聊聊它怎么做到的。
2. 背景:跨模型 KV Cache 共享的三个场景
如下图,论文给了三类典型场景:
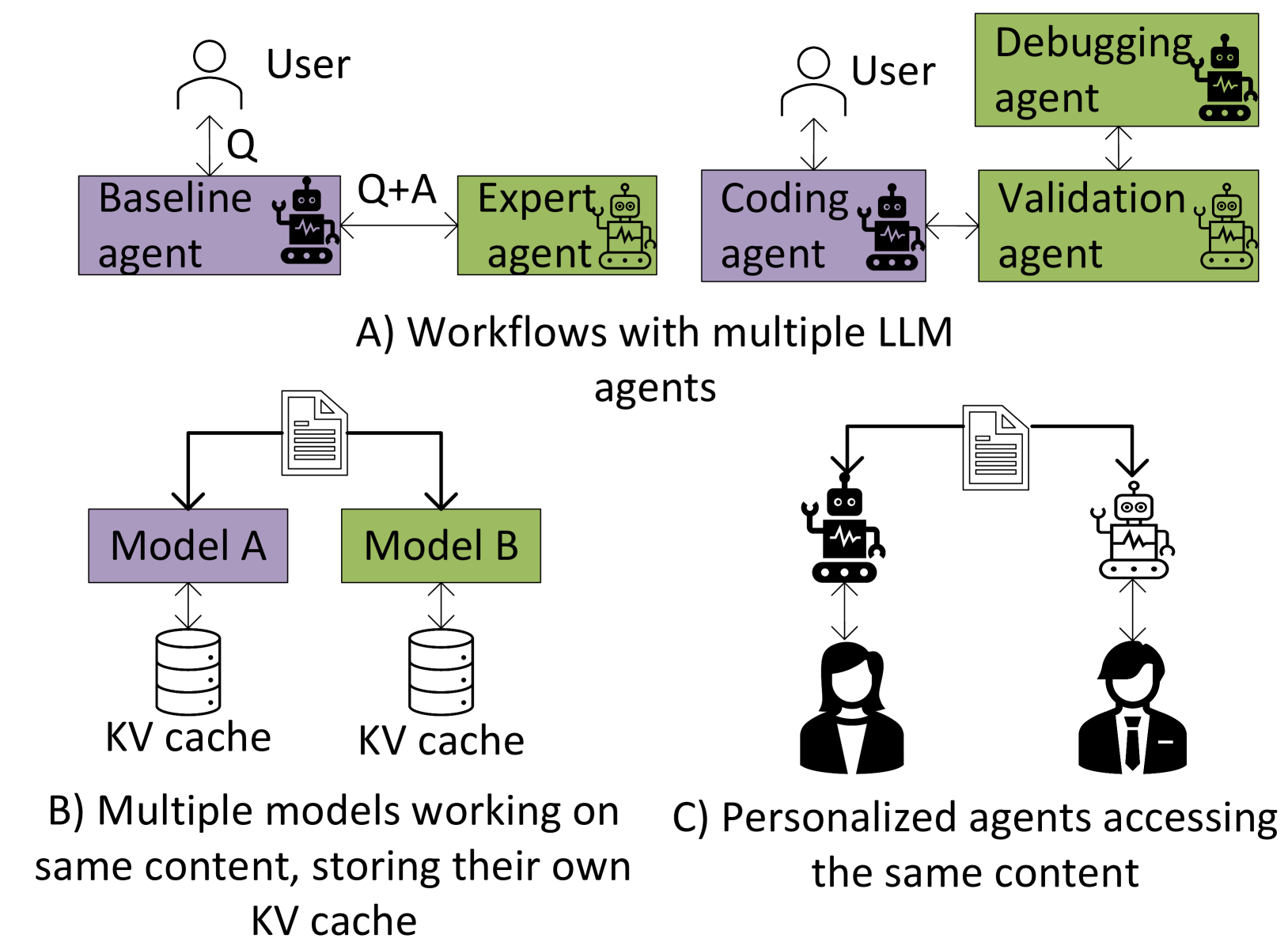
场景 A — Multi-agent workflow:baseline agent + expert agent 协作,两个模型处理同一条用户输入。
场景 B — 多模型服务同一内容:同样的文档或背景,被多个不同的专业化模型各自处理,各建各的 KV Cache,重复计算严重。
场景 C — 个性化 Agent:coding agent、validation agent、debugging agent,三者处理同一个代码问题,上下文高度重叠。
这三个场景有个共同点:多个 fine-tune 自同一基础模型的不同 LLM,重复处理相同的输入前缀。 如果能让一个模型算好 KV Cache 之后,另一个模型直接拿来用,prefill 成本就能大幅降低。
前人做的 prefix caching 能省掉同一个模型内部的重复计算,但跨模型的这层从来没人碰过。
3. 第一个问题:直接复用 KV Cache 行不行?
直觉上,两个 fine-tune 自同一基础模型的模型,权重差别不大,KV Cache 应该也差不多,直接拿来用应该没啥问题?
论文做了实测。结论一句话:直接复用另一个模型的 KV Cache,精度暴跌。
如下图,对 8 个 model pair 的测试结果:
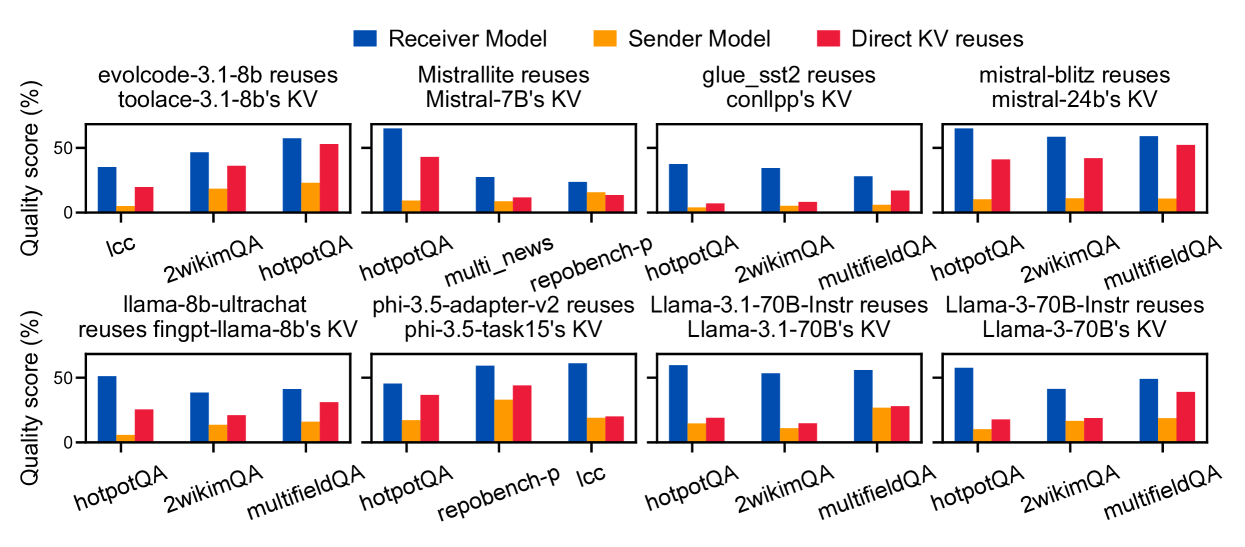
HotpotQA 上,大多数 model pair 直接复用后 F1 score 下降超过 50%。其他 dataset 情况各异,但基本上都是精度受损。
所以直接复用走不通。问题变成:有没有一部分 KV Cache 是可以安全复用的,只重算少数关键层?
4. 关键发现:只有 ~11% 的 layer 是敏感的
论文逐层测试了”只复用这一层的 KV Cache,其余层全部重算,精度会怎样”。结论非常清晰:
不同 layer 对 KV Cache 偏差的敏感度差异极大,平均只有约 11% 的 layer 是”critical layer”(精度敏感的)。
如下图(每个子图对应一个 model pair,红色 bar 表示 critical layer):
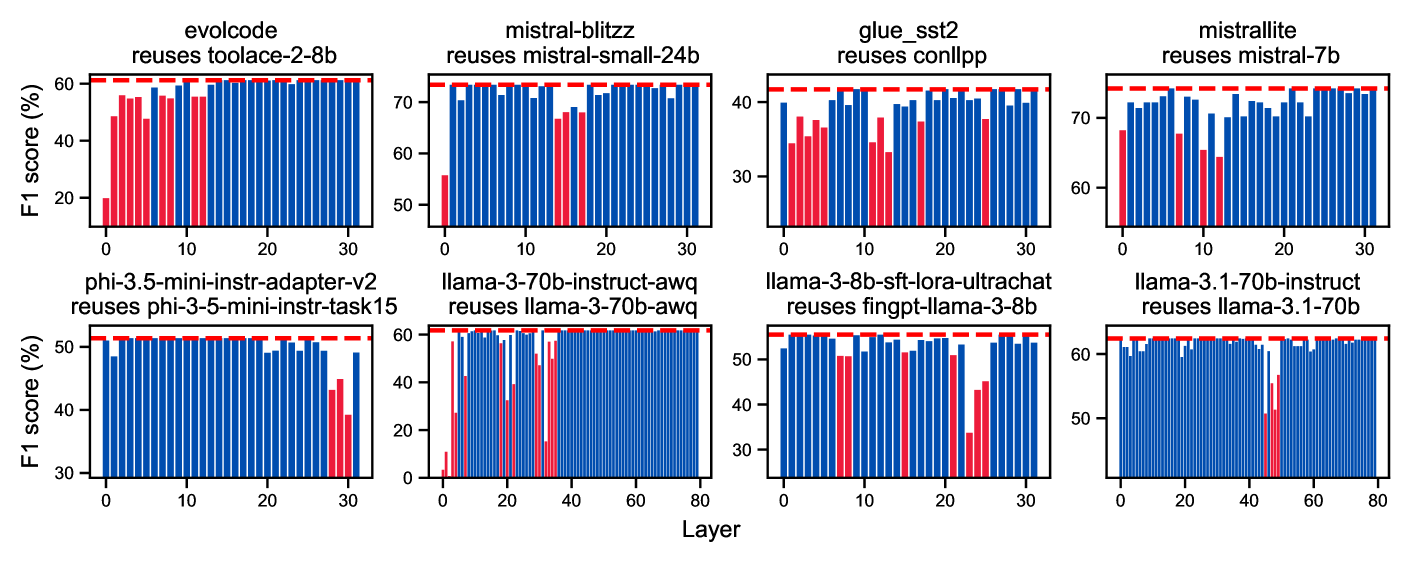
几个很有意思的观察:
-
critical layer 的位置因 model pair 而异——对于某个 pair,layer 23 最敏感;对另一个 pair,可能是 layer 5-7。没有通用规律,必须针对每个 pair 单独 profiling。
-
对于同一个 model pair,critical layer 的分布在不同输入上高度稳定。也就是说,用一个小的”训练集”测出来的 critical layer pattern,可以泛化到其他数据集上。这个性质非常关键——意味着 offline profiling 的结论是可信的。
如下图,同一 dataset 内不同输入的 F1 score 方差极小:

- non-critical layer 的误差在不同输入间方差极小。Critical layer 的误差波动很大,non-critical layer 几乎没有波动。这和直觉一致:critical layer 往往承担推理能力或任务适应能力,必须精确;non-critical layer 相对”平滑”,复用的代价很低。
5. DroidSpeak 的设计
5.1 为什么要用”连续层组”,而不是把所有 critical layer 都重算
有了上面的发现,直觉是:建个映射,把各散落在不同位置的 critical layer 全部重算,非 critical layer 全部复用。
但这行不通,原因是 E cache(embedding cache)的传输成本。
在 prefill 阶段,逐 layer 处理时,如果从”复用 KV”切换到”重算”,需要知道上一层的 E cache(该 layer 的输入 embedding)才能重算。如果非连续地重算多个 critical layer,每个切换点都要传一次 E cache——而 E cache 的大小是 KV cache 的 2-4 倍。多个切换点意味着多次大块数据传输,overhead 很快就超过复用带来的收益。
如下图,transition point 越多,误差越大,传输成本也越高:
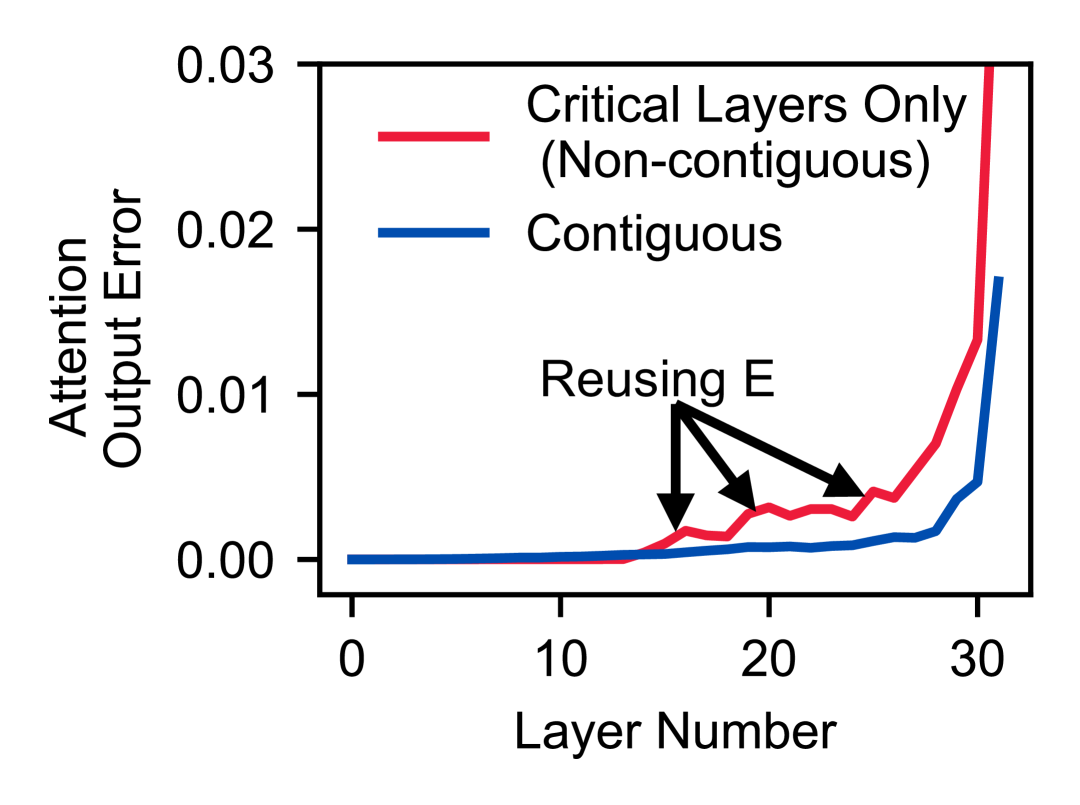
所以 DroidSpeak 的解法是:选择一个连续的 layer group 来重算,只有一个 transition point,只传一次 E cache,其余大量 layer 的 KV Cache 直接从 sender model 复用。
如下图,DroidSpeak 选出最优的连续层组(例如 layer 4-5)来重算:
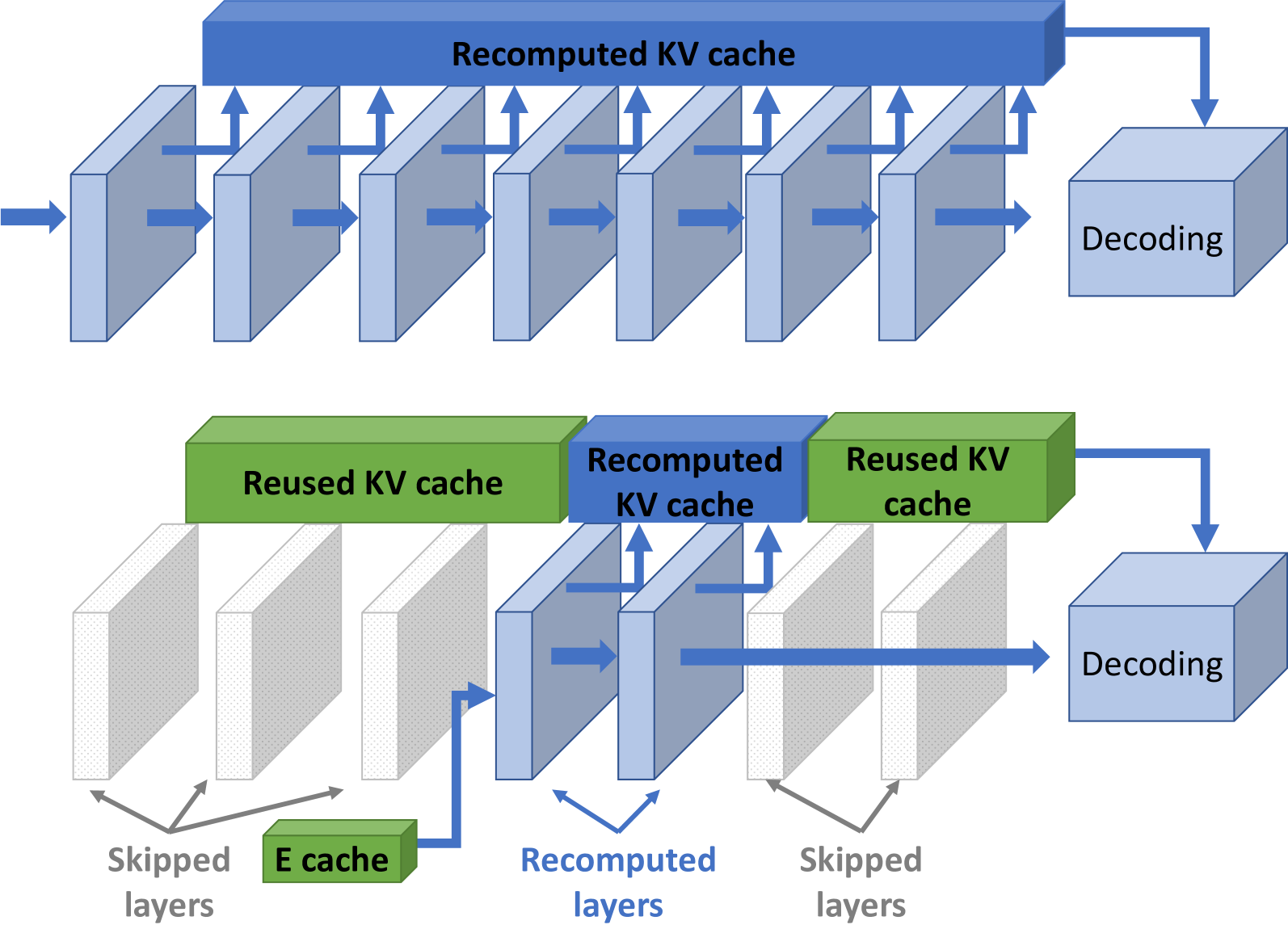
5.2 Offline Profiling:找到效率最优的 layer group
不同 layer group 的重算范围不同,产生的精度和延迟 tradeoff 也不同。DroidSpeak 通过 offline profiling 找到 Pareto frontier——在精度损失 ≤5% 的前提下,最小化需要重算的 layer 数量。
如下图是 profiling 结果的示例(scatter plot + Pareto frontier):
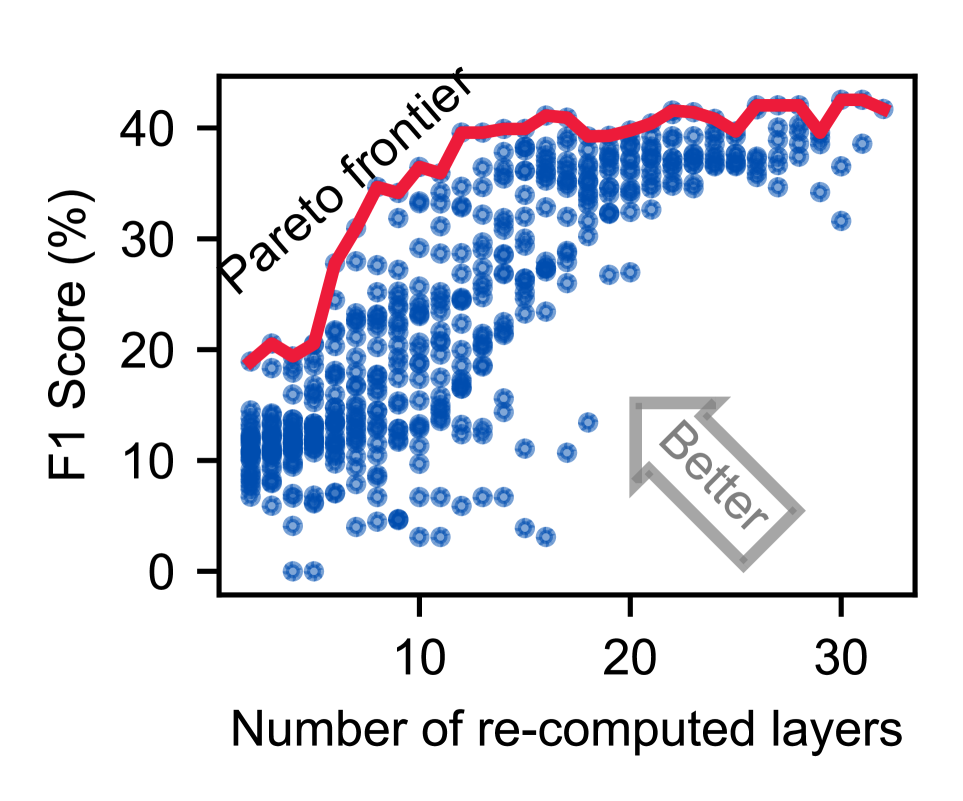
Profiling 的计算复杂度是 O(l²)(l = 模型层数),对于 32 层的 Llama-3-8B,在 A100 上大概需要 3 小时。但这是一次性成本——profile 完之后,这个 model pair 的最优配置就固定了,之后一直沿用。
实际部署时可以用 2-layer group 粒度做 profiling,计算量减少约 3x,精度损失可以忽略。
5.3 Online Stage:Pipeline 化加载,把延迟藏起来
即使确定了哪些 layer 要重算,从 sender model 加载 KV Cache 的网络延迟仍然可能成为瓶颈(跨节点走 InfiniBand)。
DroidSpeak 用 pipeline 化加载来解决这个问题:
如下图,对比了三种策略:
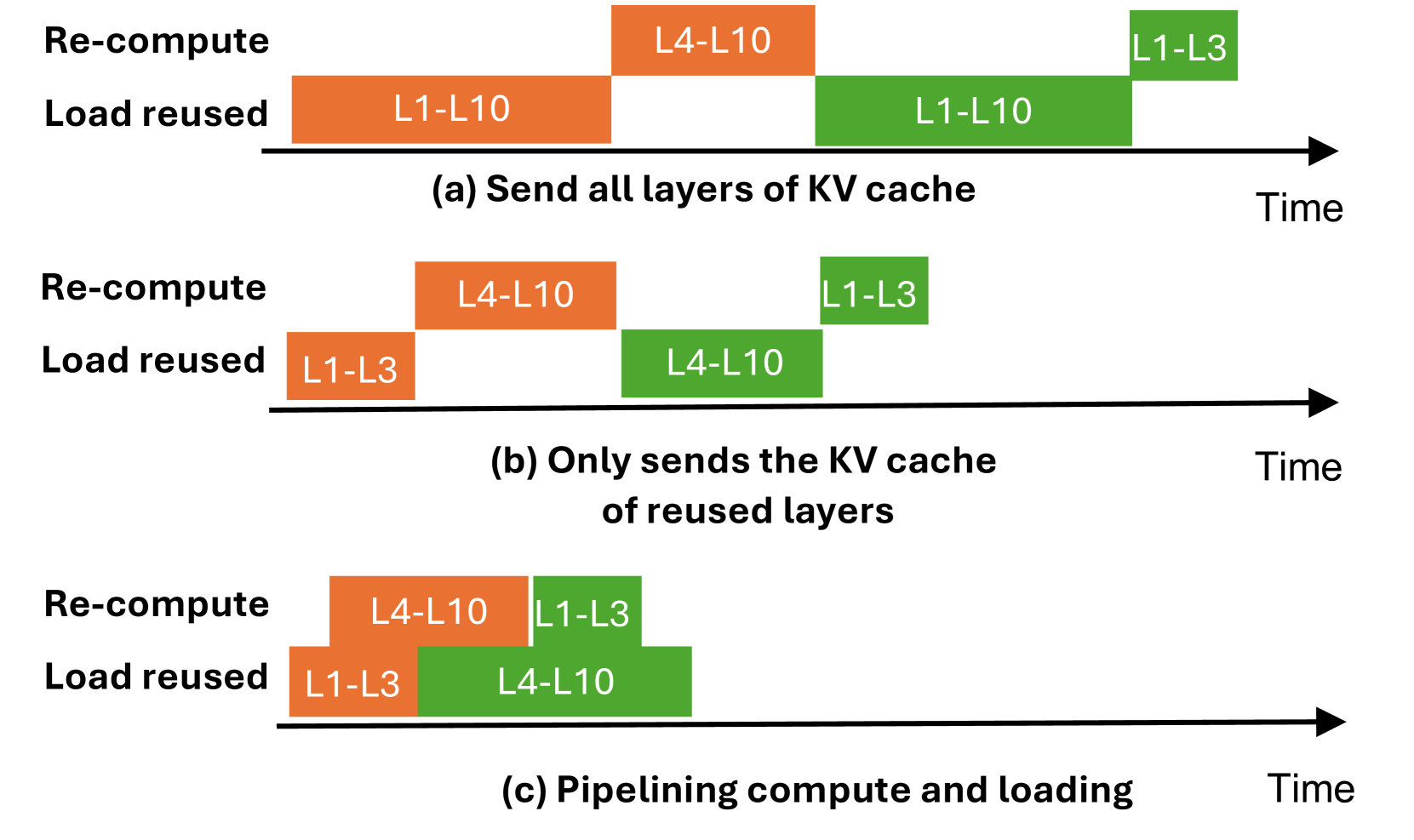
- 策略 (a):先把所有 layer 的 KV Cache 都传过来,再开始重算。最慢。
- 策略 (b):只传需要复用的 layer 的 KV Cache,然后重算。稍好。
- 策略 (c):先传 transition layer 的 E cache(体积小),立刻开始重算;同时在后台把复用 layer 的 KV Cache 加载进来。 加载和重算完全并行,TTFT 减少约 2x。
5.4 整体系统架构
系统分两阶段:
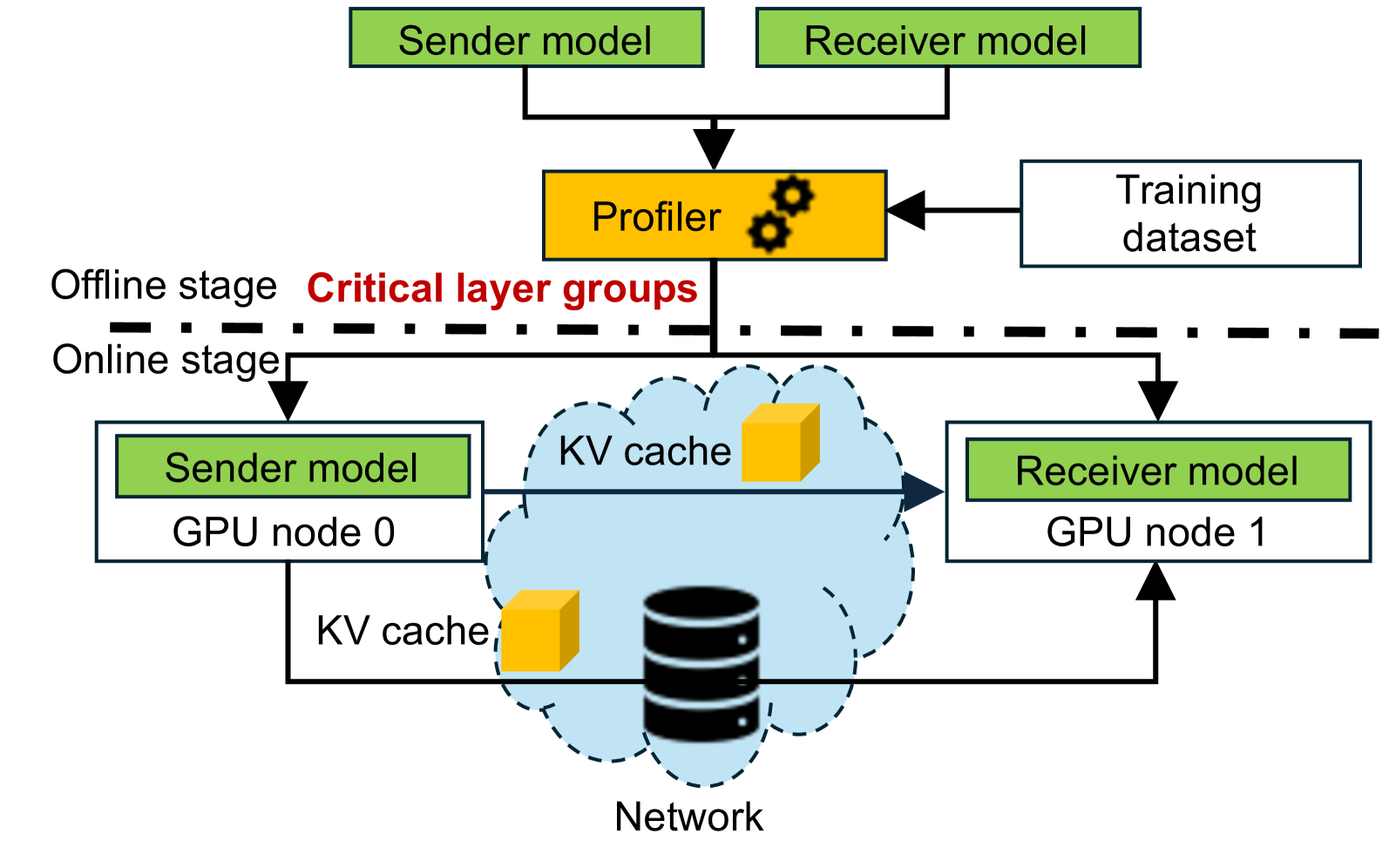
Offline stage:用 training dataset 对每个 model pair 做 profiling,得到最优重算配置(Pareto frontier 上的点)。
Online stage:根据当前可用资源,动态选择 Pareto frontier 上的配置,执行 partial prefill + pipeline 化 KV Cache 加载。
实现基于 vLLM + LMCache,约 3K 行 Python 代码,提供三个核心接口:store()、fetch()、partial_prefill()。
6. 实验结果
6.1 延迟和精度 tradeoff
如下图,8 个 model pair × 多个 dataset 的 prefill 延迟 vs 精度散点图:
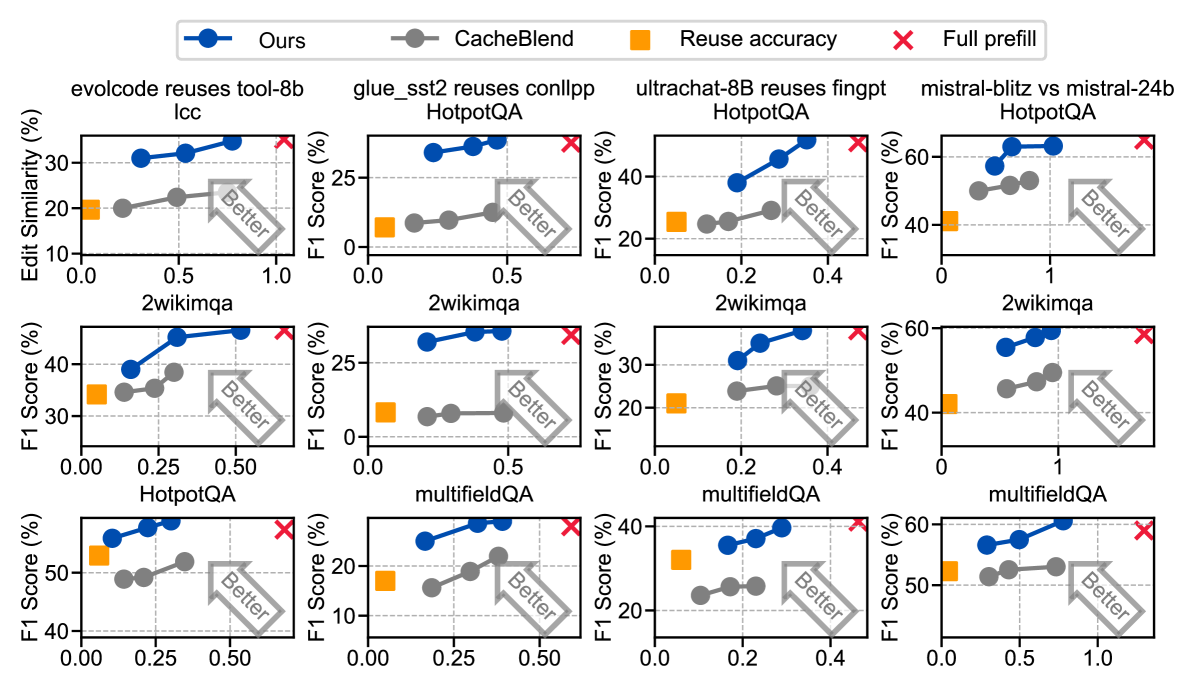
- vs full prefill:prefill 延迟降低 1.7-3.1x,精度持平
- vs full KV reuse:精度大幅优于直接复用(避免了前文提到的精度暴跌)
- vs CacheBlend:同等延迟下,精度高 5-33%(平均 16%)
6.2 吞吐量和 TTFT
在模拟在线请求(Poisson 分布到达率)的场景下:
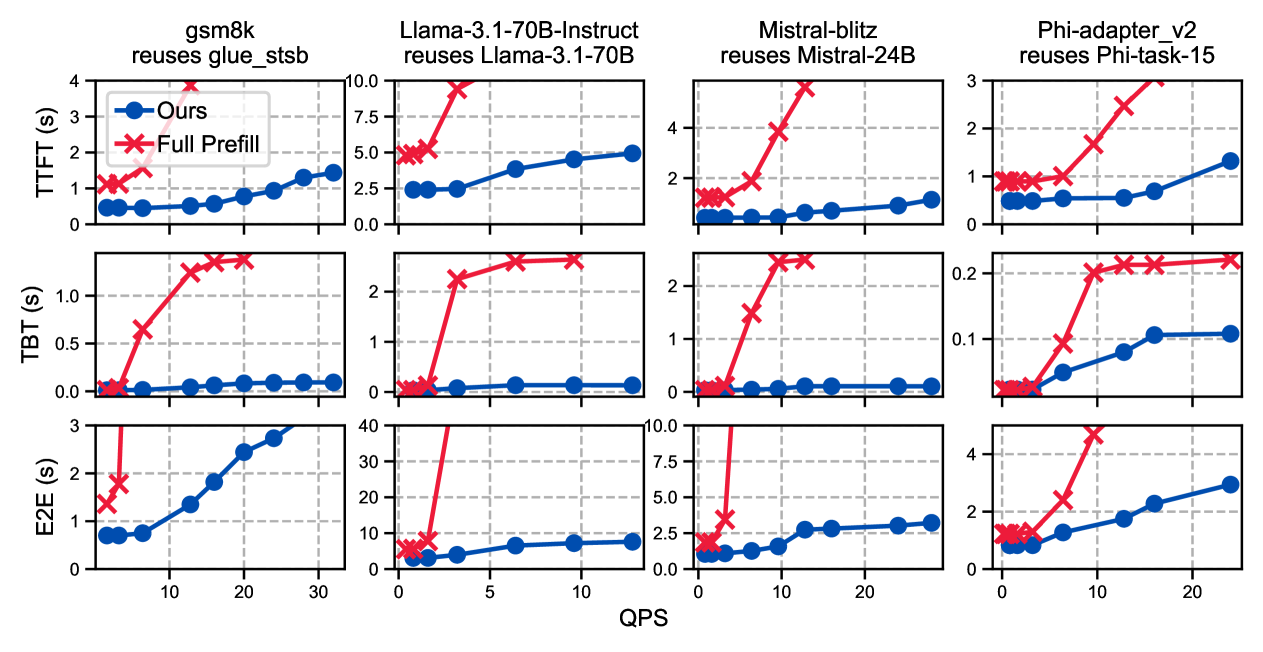
- 假设在 full prefill 开始出现队列积压(TTFT 膝点)之前的 SLO,DroidSpeak 能支持 2-4x 更高的吞吐。
- TBT(Token Between Tokens)和 E2E 也得到二阶改善——prefill 变快,减少了对 decode 阶段的干扰。
6.3 真实 Agentic Workflow 测试
在 MetaGPT 编排的 coding agentic workflow(coder + tester 两个 agent)上:
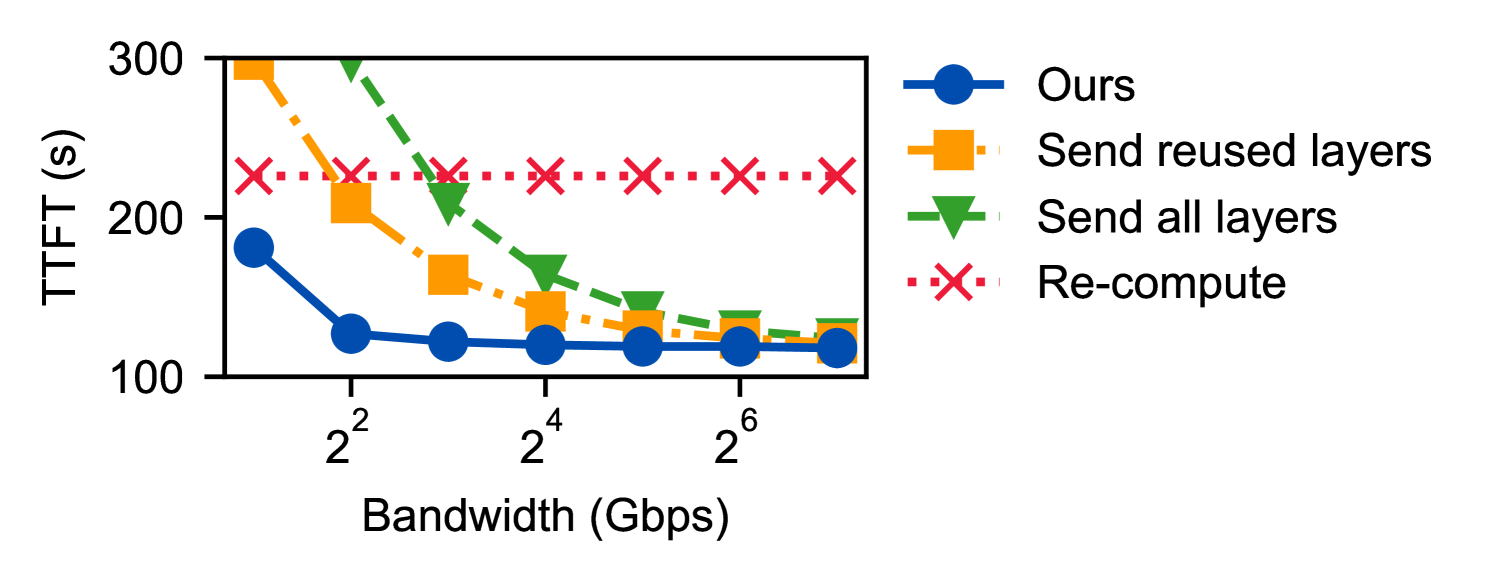
- TTFT 提升 2.7x
- E2E 延迟大幅降低
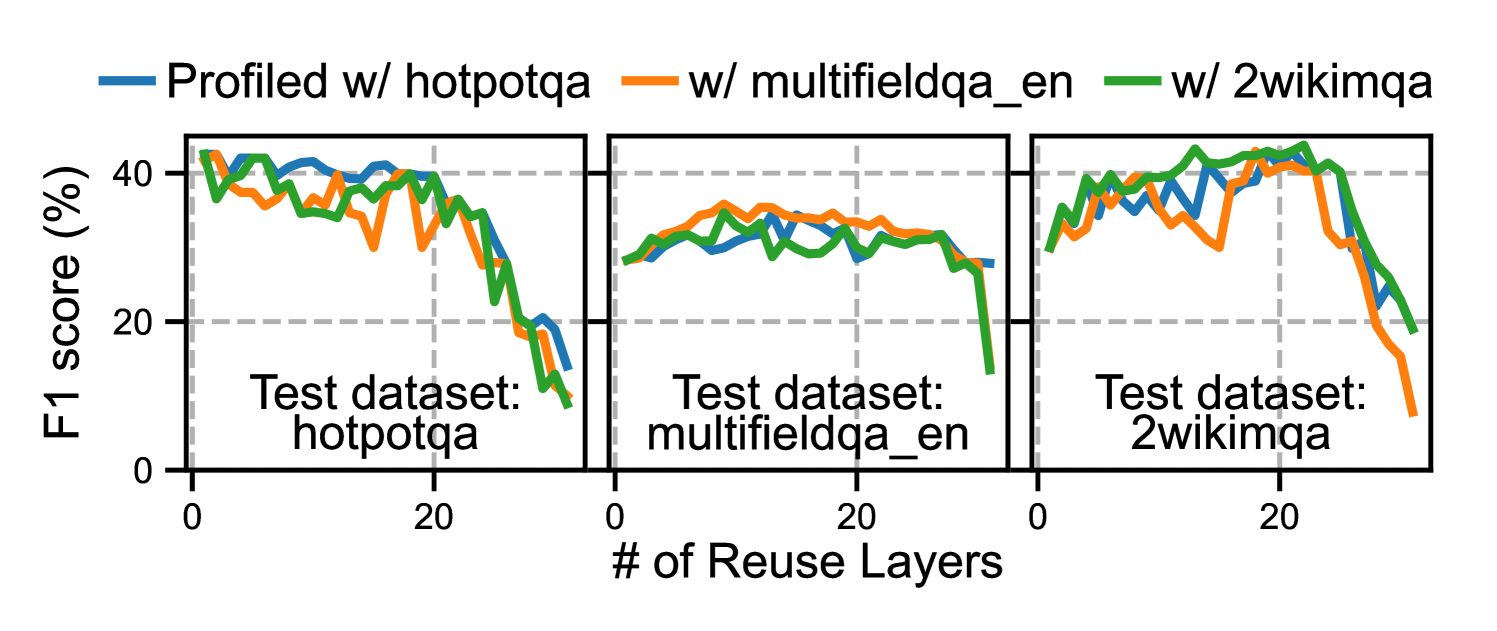
6.4 Profiling 结果泛化性
如下图,用 HotpotQA 训练集 profile 完的配置,拿去跑 multifieldQA、2wikimQA 等其他 dataset,最大精度差距 4 个百分点,平均差 2 个百分点。一次 profiling,多 dataset 通用。
6.5 MoE 模型也能用
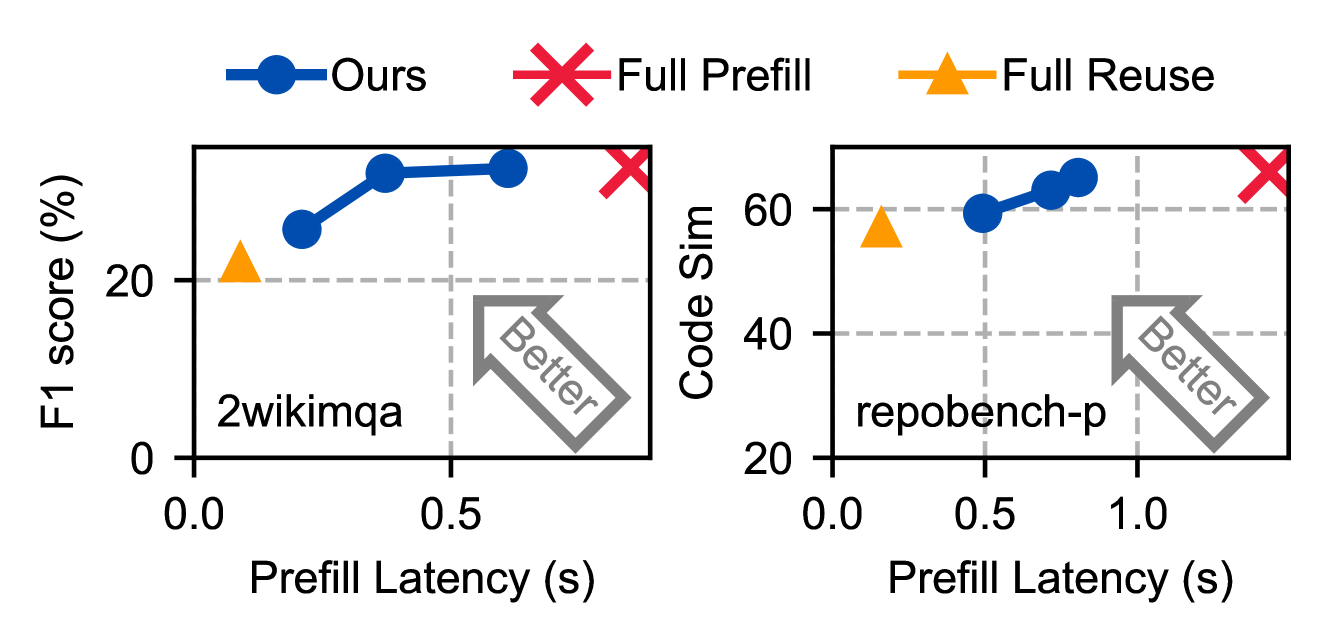
如下图,论文还测了 Mixtral-8x7B(MoE 模型),在 2wikimQA 和 repobench-p 上同样有效,说明 DroidSpeak 不局限于 dense 模型。
7. 个人评价
这篇工作切入点很好:“单模型内的 KV Cache 共享”已经做烂了,跨模型的这道门还没人破。 选了一个真实存在的系统级问题,然后用扎实的 empirical study 先把问题量化清楚(直接复用行不行、哪些 layer 敏感、是否跨输入稳定),再基于这三个 insight 设计系统。
几个细节值得学习:
-
E cache 的大小分析(是 KV cache 的 2-4x)直接决定了为什么要用连续层组而不是散点重算。这个约束如果没算清楚,设计就会走弯路。
-
Offline profiling 的 Pareto frontier 抽象很优雅——不是找一个固定的”最优配置”,而是给出整条 tradeoff 曲线,让 online stage 按资源情况动态选点。
-
Pipeline 化加载的 timeline 分析(三种传输策略对比)讲得非常清楚,从”为什么要 pipeline”到”省了多少”一气呵成。
一个没有完全解决的点是:profiling 开销是 O(l²),虽然是一次性成本,但对于每一个新的 model pair 都要重新 profile。随着生态里 fine-tuned 模型爆炸式增长,model pair 的数量会快速膨胀,这个 profiling 的扩展性值得后续工作继续探讨。
整体来说,这是一篇工程导向、insight 清晰的系统论文,做 multi-agent serving 或分布式 LLM 推理的同学可以重点关注。
如有错误欢迎评论区指出。