说人话理解 EPIC:KV Cache 复用的「编译-链接」范式(附可运行代码复现)
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

说人话理解 EPIC:KV Cache 复用的「编译-链接」范式(附可运行代码复现)
原文:EPIC: Efficient Position-Independent Caching for Serving Large Language Models
1. 前言
你有没有想过,当你用 RAG 系统给 LLM 塞了 5 篇文档 + 一个问题时,这 5 篇文档的 KV cache 其实在不同请求之间是可以复用的?
毕竟文档内容没变,变的只是用户的问题。但现实是,绝大多数系统只支持前缀匹配的 KV cache 复用——也就是说,只有当两个请求的开头完全一致时,缓存才能命中。这就很尴尬了:你 RAG 检索出来的文档顺序稍微变一下,或者 system prompt 改了一个字,前面缓存的 KV 全部失效,得重算。
这也是整个行业在 KV cache 复用上的核心矛盾:你想复用的 chunk(文档/few-shot 示例)在不同请求里出现的位置不一样,但 KV 向量里偏偏编码了位置信息(RoPE),导致”位置一变,缓存作废”。
今天想和大家聊聊这篇 EPIC,它把这个问题用一个非常漂亮的类比讲明白了——位置无关代码(PIC)。学过操作系统的同学应该不陌生:动态链接库之所以能被加载到内存的任意地址,靠的就是位置无关代码。EPIC 要做的,是让 KV cache 也能实现”位置无关”。
2. 核心问题:为什么 KV Cache 不能随便拼?
先交代下背景。LLM 的 prefill 阶段要给所有 prompt token 算 KV 向量,这一步是 compute-bound 的,也是 TTFT(Time-To-First-Token)的主要瓶颈。Context caching(也叫 prompt caching)的思路很简单:重复出现的 token 序列,把它们的 KV 向量缓存下来,下次直接用。
vLLM、SGLang 这些推理框架都实现了 prefix caching——但问题是,它只能复用公共前缀。
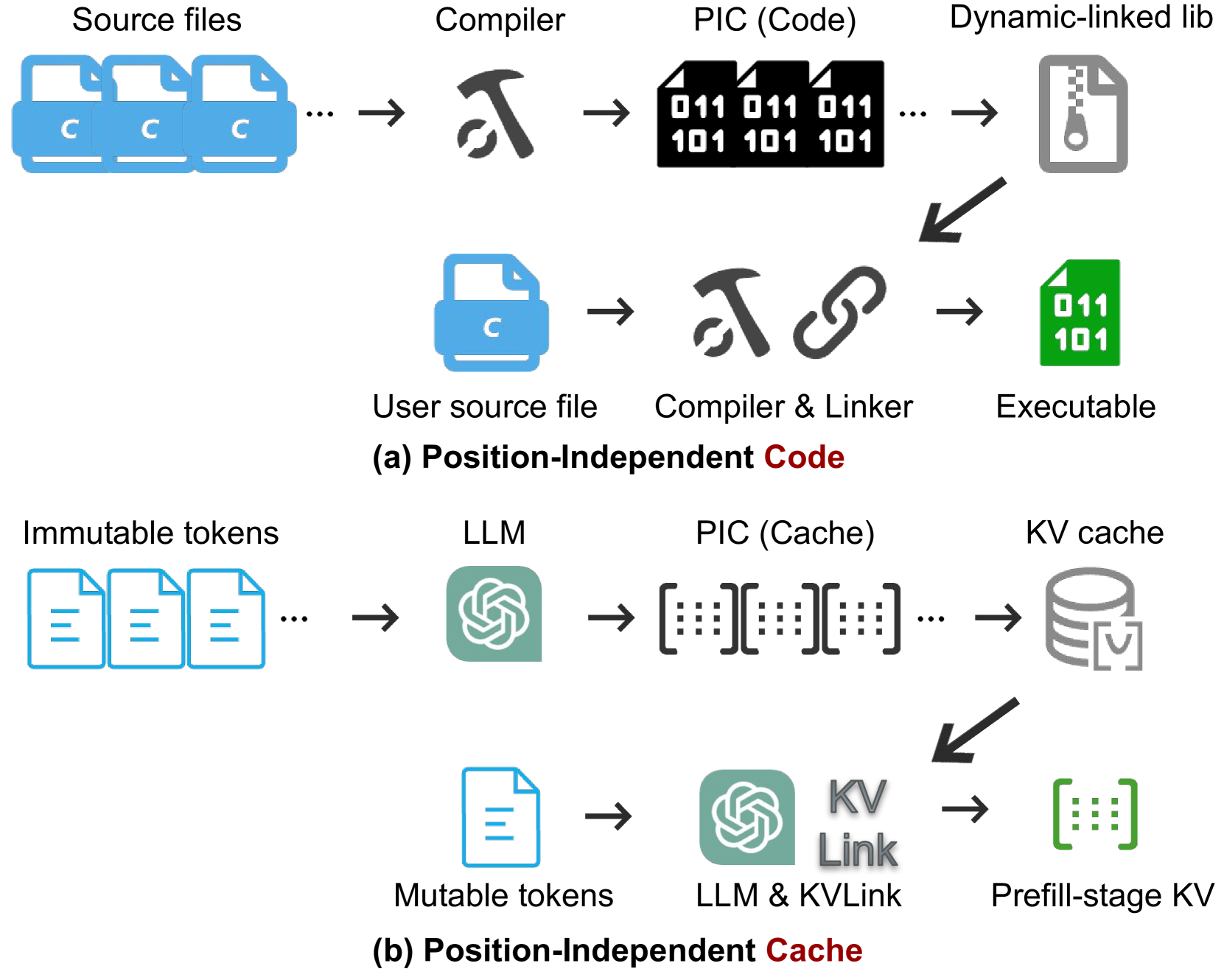
如上图,EPIC 把 KV cache 的复用类比成编译和链接:
- Compile 步骤:每个文档 chunk 被独立送进 LLM,生成 KV 向量并缓存(类比把 C 源文件编译成 .o 文件)
- Link 步骤:使用时把多个 chunk 的 KV 缓存拼起来,加上用户 query,重算一部分 KV 来保证精度(类比链接 .o 文件生成可执行程序)
但这里有个关键问题:每个 chunk 独立编译时,position ID 都是从 0 开始的。这意味着拼接后,第二个 chunk 的第一个 token 的位置信息是”0”,但它在完整 prompt 里的实际位置可能是 1024。
RoPE 位置编码直接编进了 K 和 Q 向量,位置信息的错位导致注意力计算出错。更具体地说,每个 chunk 开头的 token 会产生”attention sink”效应——它们会过度吸引注意力,让后面的 token 无法有效关注到真正重要的内容。
3. 现有方案的痛点
在 EPIC 之前,CacheBlend 是第一个尝试解决 Position-Independent Caching (PIC) 的工作。但它有两个硬伤:
第一,复杂度太高。 CacheBlend 需要先在第一层完整重算所有 KV,通过对比 attention map 选出”变化最大”的 15% token,然后在剩余层只重算这 15%。但别忘了,第一层的完整重算就已经是 O(N²) 了——当 N 到达 35000 token 时,CacheBlend 直接 OOM。
第二,动态选择 token 的开销巨大。 CacheBlend 用的是 dynamic sparsity,需要运行时计算 attention map 来选 token,这个”选 token”本身就占了 TTFT 的 16% - 64%。
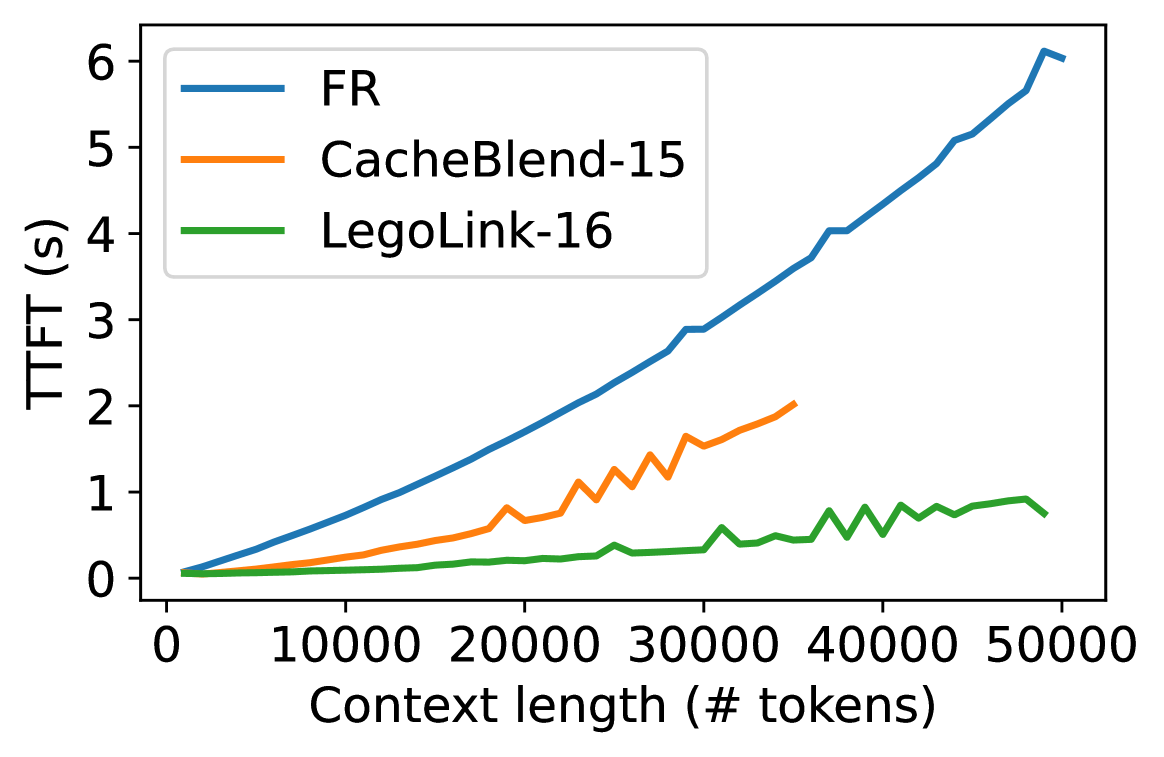
如上图,随着 context 变长,CacheBlend-15 的 TTFT 以二次方增长,在约 35000 token 时 OOM;而 LegoLink-16 几乎是线性增长,50000 token 也没问题。
4. LegoLink:简单到离谱的核心算法
EPIC 提出的 LegoLink 算法,核心思想简单到让人拍大腿:
只重算每个 chunk 开头的 k 个 token(第一个 chunk 除外),让它们”意识到”自己不在序列起始位置。
就这么简单。k 通常设为 2~16,在论文实验中 k=2 就足以把精度损失控制在 7% 以内。
但光这一句话可能还是抽象,下面我用一个具体例子把整个流程拆开讲。
4.1 举个例子:一步步走完 LegoLink
假设一个 RAG 场景,用户问”Chrysan Company 的创始人是谁?”,系统检索出了 3 篇文档:
Chunk 0 (系统指令, 4 tokens): "你 是 一个 助手" → position [0,1,2,3]
Chunk 1 (文档A, 5 tokens): "苹果 公司 由 乔布斯 创立" → position [0,1,2,3,4]
Chunk 2 (文档B, 5 tokens): "Chrysan 公司 由 张三 创立" → position [0,1,2,3,4]
Query (用户问题, 3 tokens): "谁 创立 Chrysan"
⚠️ 注意看 position:每个 chunk 编译时都是从 0 开始的! 这就是 PIC 的关键——chunk 独立编码,不知道自己在完整 prompt 里的位置。
Step 1: Compile — 独立编码每个 chunk
每个 chunk 被独立送进模型,position 从 0 开始:
Chunk 0: tokens=["你","是","一个","助手"], positions=[0,1,2,3] → 生成 KV_0 (4个KV向量)
Chunk 1: tokens=["苹果","公司","由","乔布斯","创立"], positions=[0,1,2,3,4] → 生成 KV_1 (5个KV向量)
Chunk 2: tokens=["Chrysan","公司","由","张三","创立"], positions=[0,1,2,3,4] → 生成 KV_2 (5个KV向量)
每个 chunk 的 KV 向量都被缓存下来。
Step 2: Link — 拼接 + 选择性重算
现在用户发来 query,我们要把 3 个 chunk 的 KV 拼起来。拼接后的完整序列长这样:
全局位置: [0 1 2 3 | 4 5 6 7 8 | 9 10 11 12 13 | 14 15 16]
Token: [你 是 一个 助手| 苹果 公司 由 乔布斯 创立 | Chrysan 公司 由 张三 创立 | 谁 创立 Chrysan]
chunk 0 chunk 1 chunk 2 query
问题来了:chunk 1 的”苹果”这个 token 的 KV 向量里,RoPE 编码的位置是 0(编译时的位置),但它在完整 prompt 里的正确位置应该是 4。”Chrysan” 的 KV 里位置是 0,正确应该是 9。
这导致了什么?每个 chunk 开头的 token 都以为自己是”位置 0”——序列的起点。在 causal attention 中,位置 0 的 token 会被后续所有 token 关注(因为它”最老”),吸收了大量注意力。这就是 attention sink。
LegoLink (k=2) 的做法:
需要重算的 token(★ 标记):
位置: [0 1 2 3 | ★4 ★5 6 7 8 | ★9 ★10 11 12 13 | ★14 ★15 ★16]
Token: [你 是 一个 助手| 苹果 公司 由 乔布斯 创立 | Chrysan 公司 由 张三 创立 | 谁 创立 Chrysan]
↑ chunk1开头2个 ↑ chunk2开头2个 ↑ query全部
具体重算了哪些?
- Chunk 0:不重算(它是第一个 chunk,位置本来就从 0 开始,没有错位)
- Chunk 1 的前 2 个 token:”苹果”(pos 4)、”公司”(pos 5) — 用正确的全局位置重新算 KV
- Chunk 2 的前 2 个 token:”Chrysan”(pos 9)、”公司”(pos 10) — 用正确的全局位置重新算 KV
- Query 的所有 token:”谁”(pos 14)、”创立”(pos 15)、”Chrysan”(pos 16) — query 本来就要算
一共只重算了 7 个 token(2+2+3),而不是全部 17 个。
Step 3: 重算时的 Attention 计算
重算这 7 个 token 时,每个 token 的 Q 向量用正确的全局位置编码 RoPE,然后 attend to 所有 17 个位置的 KV(其中 7 个是刚重算的,10 个是缓存的)。
以 “Chrysan”(位置 9) 为例:
- 编译时:它的 K 向量用了 RoPE(pos=0),所有后续 token 都觉得它是”起点”,疯狂给它注意力 → attention sink
- LegoLink 重算后:它的 K 向量用了 RoPE(pos=9),后续 token 能正确判断与它的相对距离,不再过度关注 → sink 消失
这就是为什么重算 chunk 开头的少数几个 token 就能解决问题:只有这几个 token 有严重的 attention sink,后面的 token 虽然位置也有偏差,但它们不在”位置 0”上,不会成为 sink。
直观对比
Naive(不重算):
query "Chrysan" 的注意力 → 80% 被 chunk 1/2 开头 token 吸走 → 找不到"张三"
LegoLink-2(重算 k=2):
query "Chrysan" 的注意力 → 正确分配到"张三 创立"处 → 输出"张三"✓
Full Recompute(全重算):
query "Chrysan" 的注意力 → 和 LegoLink 几乎一样 → 输出"张三"✓
但代价是重算了全部 17 个 token 而不是 7 个
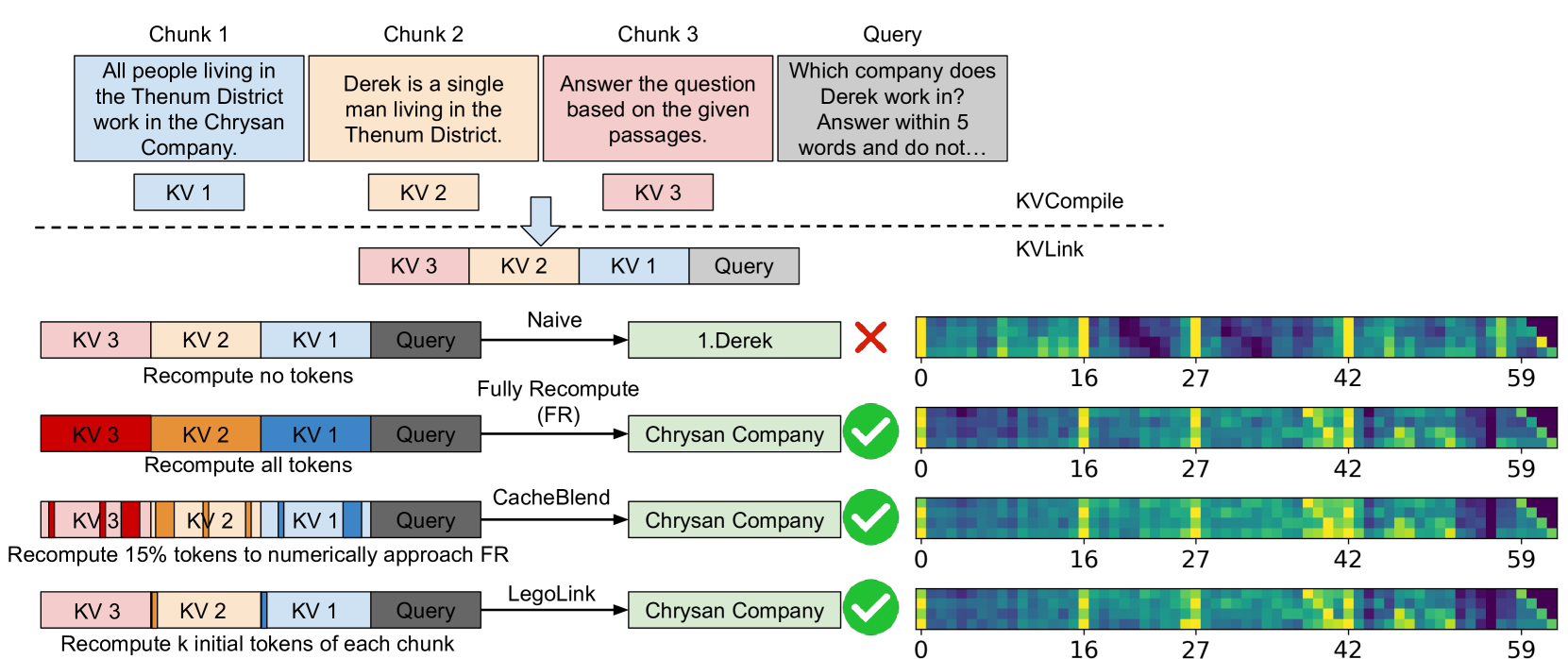
如上图对比了 Naive(不重算)、FR(全重算)、CacheBlend(重算 15% token)和 LegoLink(只重算每个 chunk 开头 k 个 token)。右边的 attention map 非常直观:
- Naive:每个 chunk 开头有明显的亮色竖线(attention sink),注意力被这些 token 吸走了
- FR:attention 分布正常,chunk 开头 token 虽然仍有一定 attention(因为 BOS token 的特殊性),但不再过度集中
- LegoLink:通过只重算开头 k 个 token,attention map 几乎和 FR 一致
4.2 为什么只重算开头 k 个 token 就够了?
回到上面的例子。chunk 1 里的”由”(编译 pos=2, 正确 pos=6) 和 “乔布斯”(编译 pos=3, 正确 pos=7) 的位置也是错的,为什么不需要重算?
原因有二:
-
Attention sink 是位置 0 的专利。在 causal attention 中,位置 0 的 token 是唯一被所有后续 token 都能看到的,自然成为注意力的”垃圾桶”。位置 2、3 虽然也有偏差,但偏差不会导致极端的 attention 集中。
-
Query 和 decode token 才是信息聚合者。最终回答问题的是 query 和后续生成的 token,它们的 Q 向量是用正确全局位置算的,能正确 attend to 所有 KV(包括那些位置稍有偏差但内容正确的 token)。
4.3 复杂度对比
| 方法 | 重算 token 数 | 时间复杂度 | 说明 |
|---|---|---|---|
| FR | N=17 | O(N²) | 全重算,最准但最慢 |
| CacheBlend-15 | 15%×N≈3 | O(15%·N²) | 还是 O(N²),因为第一层要全算 |
| LegoLink-k | (chunks-1)×k+q=7 | O(k·N) ≈ O(N) | k 是常数,近线性 |
| LegoLink-0 | 0 | O(q·N) | 编译时处理 sink,link 零开销 |
5. 系统架构
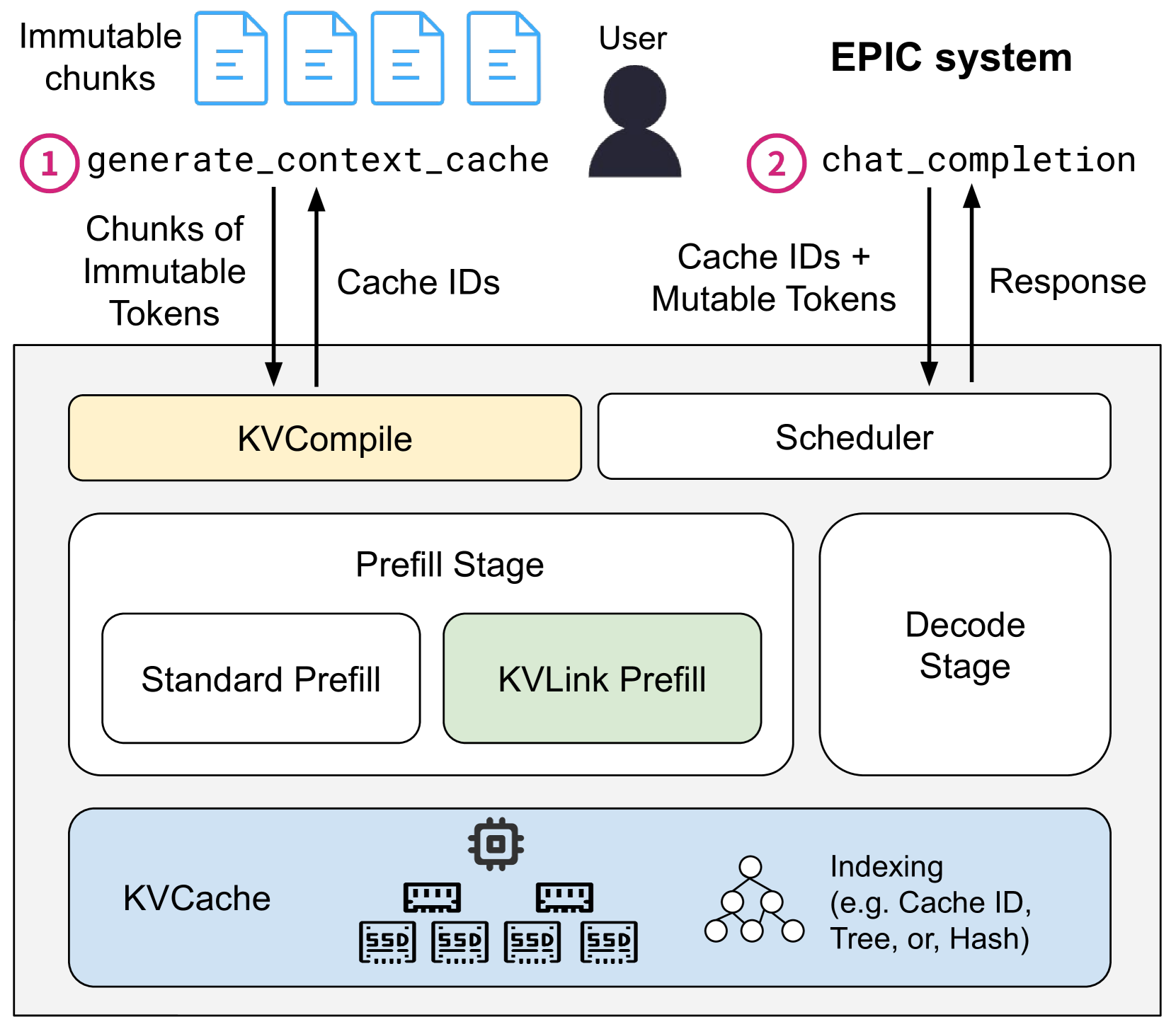
EPIC 的系统架构很清晰:
- KVCompile:接收用户提交的 immutable chunk,执行标准 prefill 生成 KV 向量,存入 KVCache,返回 cache ID
- KVLink:收到请求时,根据 cache ID 取出 KV 缓存,执行 LegoLink 重算,然后正常 decode
- KVCache:支持 HBM / DRAM / SSD 多级存储
用户通过两个 API 交互:
-
generate_context_cache(chunks)→ 获得 cache IDs -
chat_completion(cache_ids, query)→ 获得回复
这种 explicit caching 的设计跟 Google Gemini 和 Mooncake 类似,用户自己管理缓存的生命周期。
6. 实验结果
6.1 精度-延迟 Pareto 前沿
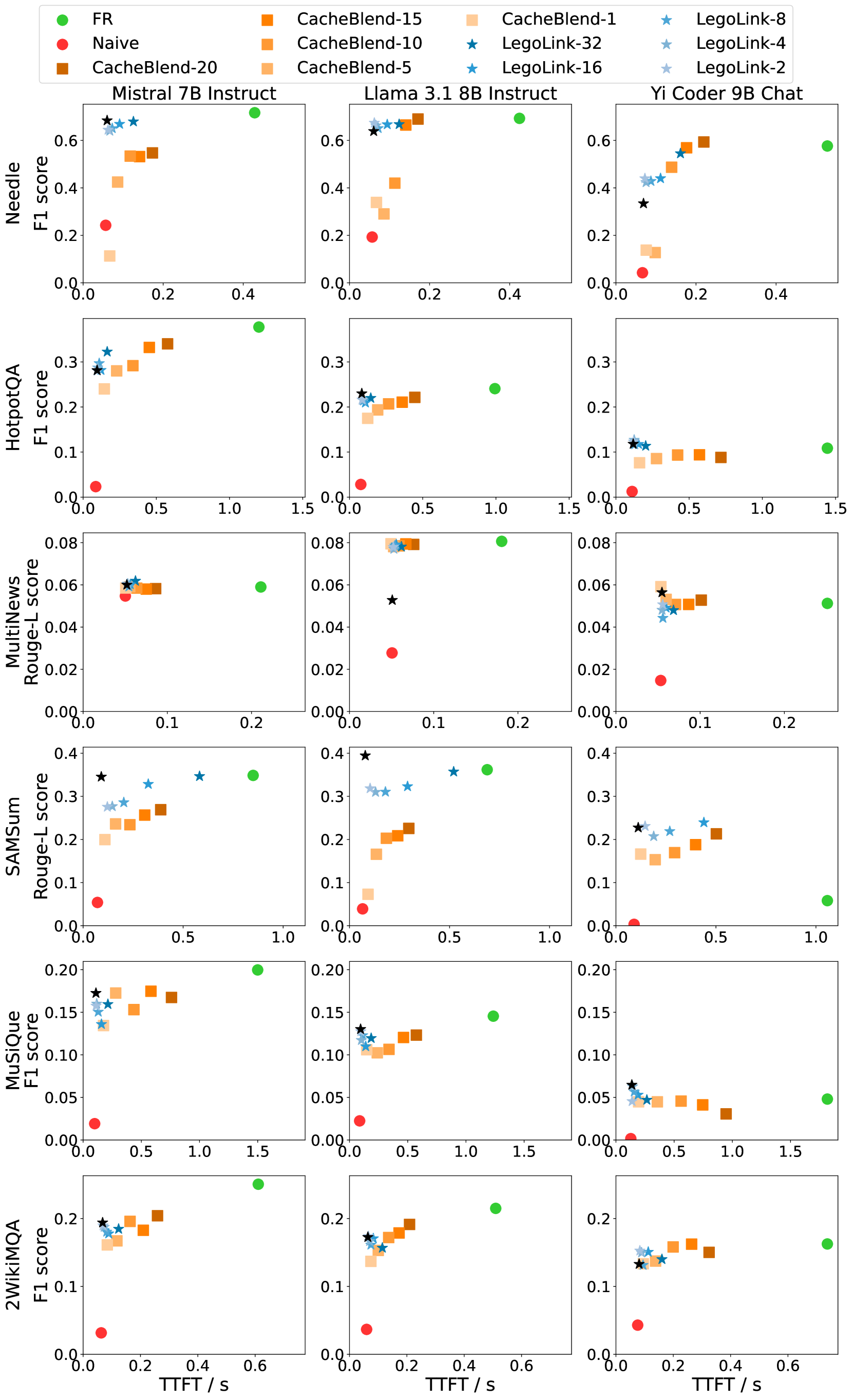
如上图(6 个数据集 × 3 个模型),LegoLink(蓝色星星系列)在大多数场景下建立了新的 Pareto 前沿。核心发现:
- LegoLink-2 就能把精度损失控制在 0-7%,同时 TTFT 比 CacheBlend-15 减少最多 3×
- CacheBlend-1 或 CacheBlend-5(重算类似数量的 token)精度会崩——因为它选错了要重算的 token
- 增大 k 带来的精度增益递减:重算几个开头 token 就够了
6.2 系统级性能
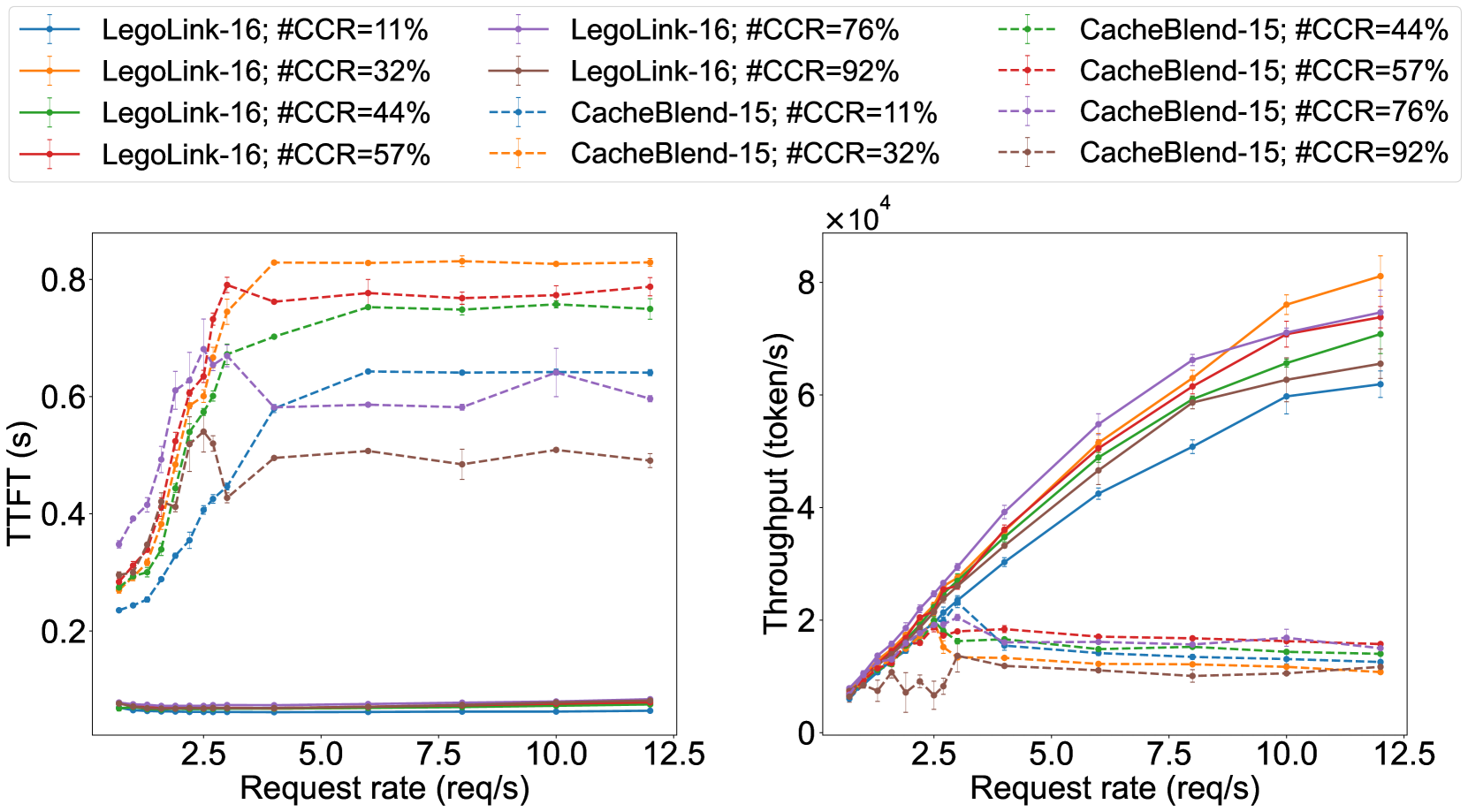
在异步工作负载下:
- LegoLink-16 相比 CacheBlend-15 实现 最高 8× TTFT 降低
- 吞吐提升 最高 7×
- 随着 CCR(Context Cache Ratio)增加,LegoLink 的 TTFT 保持稳定,而 CacheBlend 持续波动
6.3 LegoLink-0:零开销变体
论文还提出了一个骚操作:LegoLink-0。在 compile 阶段给每个 chunk 前面加 4 个 dummy token(如 BOS token),编译完后把这些 dummy 的 KV 丢掉。这样 attention sink 在编译时就被”预消费”了,link 阶段完全不需要重算!虽然精度比 LegoLink-2 略差一点,但 link 开销为零。
7. 代码复现
光说不练假把式。我用一个最简的 Transformer 模型复现了 LegoLink 的核心逻辑,不依赖 vLLM,只需要 PyTorch,CPU 就能跑。
代码在这里:https://github.com/marsggbo/easy-kvcache
git clone https://github.com/marsggbo/easy-kvcache.git
cd easy-kvcache
python epic/epic_legolink.py
核心实现大概 400 行,把 compile/link 两步和四种算法(Naive / FR / LegoLink / LegoLink-0)都实现了。这里挑几个关键部分讲一下。
7.1 Compile 步骤:独立编码 chunk
def compile_chunk(self, token_ids: torch.Tensor) -> CompiledChunk:
"""Compile:独立编码一个 chunk,position 从 0 开始"""
chunk_len = token_ids.shape[1]
# ⚠️ 关键:position IDs 从 0 开始
positions = torch.arange(chunk_len, device=token_ids.device)
_, kv_caches, _ = self.model(token_ids, positions)
return CompiledChunk(token_ids=token_ids, kv_caches=kv_caches, chunk_len=chunk_len)
继续沿用上面 4.1 节的例子。假设我们有 3 个 chunk,每个 chunk 被独立编译:
输入 token_ids: 含义:
chunk 0: tensor([[10, 20, 30, 40]]) → "你 是 一个 助手" (shape: [1, 4])
chunk 1: tensor([[50, 60, 70, 80, 90]]) → "苹果 公司 由 乔布斯 创立" (shape: [1, 5])
chunk 2: tensor([[100,110,120,130,140]]) → "Chrysan 公司 由 张三 创立" (shape: [1, 5])
对于 chunk 1,调用 compile_chunk(tensor([[50,60,70,80,90]])) 时内部变量:
chunk_len = 5
positions = tensor([0, 1, 2, 3, 4]) ← 关键:从 0 开始!不管 chunk 1 在 prompt 里实际从位置 4 开始
模型前向传播后,返回的 kv_caches 是一个 list,每个元素是一个 (K, V) tuple:
kv_caches = [
(K_layer0, V_layer0), # 每个 shape: [1, n_heads, 5, head_dim] 即 [batch, heads, chunk_len, dim]
(K_layer1, V_layer1),
(K_layer2, V_layer2),
(K_layer3, V_layer3),
]
这些 KV 向量被存进 CompiledChunk,后续 link 时复用。注意 K 向量里已经编进了 RoPE(pos=0,1,2,3,4) 的位置信息——而正确的全局位置应该是 4,5,6,7,8。这个错位就是后续需要重算的根源。
7.2 LegoLink:只重算开头 k 个 token
def link_legolink(self, query_ids, k=4):
"""LegoLink:只重算每个 chunk(除第一个)开头的 k 个 token"""
# Step 1: 确定重算位置
recompute_indices = []
offset = 0
for i, chunk in enumerate(self.compiled_chunks):
if i > 0: # 第一个 chunk 不需要重算
for j in range(min(k, chunk.chunk_len)):
recompute_indices.append(offset + j)
offset += chunk.chunk_len
# 加上 query tokens
query_indices = list(range(total_ctx_len, total_ctx_len + query_len))
all_recompute_indices = recompute_indices + query_indices
# Step 2: 用 **正确的全局位置** 重算这些 token
recompute_positions = torch.tensor(all_recompute_indices) # 全局位置!
# Step 3: 逐层执行——新算的 KV 替换缓存中对应位置
for layer_idx, layer in enumerate(self.model.layers):
# 计算新的 Q, K, V(用正确位置的 RoPE)
Q, K_new, V_new = compute_qkv(x, recompute_positions)
# 在缓存 KV 的对应位置覆盖
K_exp[:, :, recompute_indices] = K_new
V_exp[:, :, recompute_indices] = V_new
# Q (k' tokens) attends to all N tokens
attn = softmax(Q @ K_exp.T / sqrt(d)) @ V_exp
还是用上面的 3 chunk + query 例子,设 k=2,一步步看每个变量:
Step 1:确定重算位置
遍历 3 个 chunk:
i=0, chunk 0 (len=4): 跳过(第一个 chunk 不重算), offset=0 → 0+4=4
i=1, chunk 1 (len=5): 重算前 2 个 → recompute_indices=[4, 5], offset=4 → 4+5=9
i=2, chunk 2 (len=5): 重算前 2 个 → recompute_indices=[4, 5, 9, 10], offset=9 → 9+5=14
total_ctx_len = 4+5+5 = 14
query_len = 3
query_indices = [14, 15, 16]
all_recompute_indices = [4, 5, 9, 10, 14, 15, 16] ← 一共 7 个 token 需要重算
对应到完整序列中的位置:
位置: [0 1 2 3 | 4 5 6 7 8 | 9 10 11 12 13 | 14 15 16 ]
[你 是 一个 助手|苹果 公司 由 乔布斯 创立|Chrysan 公司 由 张三 创立 | 谁 创立 Chrysan]
★ ★ ★ ★ ★ ★ ★
重算chunk1前2个 重算chunk2前2个 重算query全部
Step 2:构造正确位置的重算输入
# 从完整 token 序列中取出需要重算的 token
all_token_ids = [10,20,30,40, 50,60,70,80,90, 100,110,120,130,140, 150,160,170]
↑ query tokens
recompute_ids = tensor([[50, 60, 100, 110, 150, 160, 170]]) # shape [1, 7]
# pos4 pos5 pos9 pos10 pos14 pos15 pos16
recompute_positions = tensor([4, 5, 9, 10, 14, 15, 16]) # ← 全局位置!不是从 0 开始
关键区别:编译时 “苹果”(token 50) 用的 positions=0,现在重算用的 positions=4。RoPE 编码不同,生成的 K 向量也不同,attention sink 效应就会消失。
Step 3:逐层重算并替换缓存
# 拿到缓存的 KV(3 个 chunk 拼接后)
K_cached shape: [1, n_heads, 14, head_dim] # 14 = 4+5+5,三个 chunk 的 KV 拼一起
V_cached shape: [1, n_heads, 14, head_dim]
# 扩展为完整序列长度(加上 query 的位置)
K_exp shape: [1, n_heads, 17, head_dim] # 17 = 14 + 3 (query)
V_exp shape: [1, n_heads, 17, head_dim]
# 复制缓存到前 14 个位置
K_exp[:, :, :14, :] = K_cached
# 用重算的 KV 覆盖对应位置
K_exp[:, :, [4,5,9,10,14,15,16], :] = K_new # 7 个新 K 向量替换原来的
V_exp[:, :, [4,5,9,10,14,15,16], :] = V_new
# 现在 K_exp 中:
# 位置 0-3: chunk 0 的原始缓存 KV(没动,因为第一个 chunk 不需要重算)
# 位置 4,5: chunk 1 开头 2 个 token 的 **新** KV(用正确位置 4,5 重算的)
# 位置 6-8: chunk 1 剩余 3 个 token 的原始缓存 KV(没动)
# 位置 9,10: chunk 2 开头 2 个 token 的 **新** KV(用正确位置 9,10 重算的)
# 位置 11-13:chunk 2 剩余 3 个 token 的原始缓存 KV(没动)
# 位置 14-16:query 的 KV(首次计算)
# Attention: Q (7个重算token) × K_exp^T (17个位置) → [1, heads, 7, 17]
attn_scores = Q @ K_exp.transpose(-2, -1) / sqrt(head_dim)
# 加 causal mask(每个 token 只能看到自己及之前的位置)
# 最终只取 query 部分(最后 3 个)的输出 → logits
7.3 LegoLink-0:编译时预处理
def link_legolink_zero(self, query_ids, n_dummy=4):
"""LegoLink-0:compile 时加 dummy prefix,link 时零开销"""
for chunk in self.compiled_chunks:
# 在 chunk 前面加 n_dummy 个 dummy token(如 BOS)
dummy_ids = torch.full((1, n_dummy), BOS_TOKEN_ID)
padded_ids = torch.cat([dummy_ids, chunk.token_ids], dim=1)
# 编译带 dummy 的版本
_, kv_caches, _ = self.model(padded_ids, positions)
# 丢掉 dummy 的 KV,只保留原始 chunk 的 KV
kv_caches = [(K[:,:,n_dummy:,:], V[:,:,n_dummy:,:]) for K, V in kv_caches]
这个变体的思路很巧妙,还是用 chunk 1 举例:
原始编译(标准 compile):
输入: ["苹果","公司","由","乔布斯","创立"]
positions: [0, 1, 2, 3, 4]
→ "苹果"在 pos=0,成为 attention sink
LegoLink-0 编译(加 dummy prefix):
输入: ["<BOS>","<BOS>","<BOS>","<BOS>", "苹果","公司","由","乔布斯","创立"]
positions: [0, 1, 2, 3, 4, 5, 6, 7, 8]
→ 4 个 dummy 占据了 pos 0-3,"苹果"在 pos=4
→ dummy token "吃掉"了 attention sink
然后丢弃前 4 个 dummy 的 KV:
KV 原始 shape: [1, heads, 9, dim]
丢弃后 shape: [1, heads, 5, dim] ← 只保留 "苹果" 到 "创立" 的 KV
这样 chunk 1 的 “苹果” 的 KV 向量里编码的是 pos=4(不再是 0),attention sink 在编译时就被消除了。link 阶段直接 naive 拼接就行,零重算开销。
代价是 compile 阶段要多算 4 个 dummy token,但 compile 只做一次、link 做很多次,所以总体上是划算的。
7.4 运行结果
跑一下就能看到效果:
Step 5: 不同 k 值对 LegoLink 精度的影响
k Cosine Sim Recompute Tokens % of Total
-------------------------------------------------------
0 0.9975 0 0.0%
1 0.9995 10 9.6%
2 0.9996 12 11.5%
4 0.9996 16 15.4%
32 1.0000 72 69.2%
和论文结论完全一致:k=2 就够了,继续加大 k 收益递减。
8. 一些个人 Take
-
类比很精髓。用编译/链接来类比 PIC 的 compile/link,这个抽象做得很漂亮。看完论文你会觉得”这也太自然了”,但自然的东西往往是最难想到的。
-
Attention sink 是个被低估的问题。之前 StreamingLLM 那篇讲 attention sink 更多是在 decode 阶段(evict 过程中保留 sink token),EPIC 把它放到了 PIC 的场景下,而且给出了比 StreamingLLM 更细粒度的解决方案。
-
Static sparsity > Dynamic sparsity(在这个场景下)。CacheBlend 用 dynamic sparsity 去选 token 重算,看起来更”智能”,但实际上选 token 的开销本身就很大。LegoLink 预先知道该重算谁(每个 chunk 开头),反而又快又准。这给了我们一个启发:不是所有问题都需要”动态”方案,如果你对问题结构足够了解,静态方案往往更优。
-
这篇工作对 RAG 场景特别有价值。目前 RAG 系统的瓶颈之一就是长 context 的 prefill 开销。如果 document chunk 的 KV cache 可以跨请求复用,而且不需要 prefix 完全匹配,那 TTFT 可以大幅降低。可以预见未来的推理框架会原生支持 PIC。
-
代码质量。官方代码基于 vLLM 实现,改动了约 2K 行 Python,主要在 attention backend 和 scheduler 两处。代码结构还是比较清晰的,感兴趣的可以 diff 一下和 vLLM 0.7.0 的差异。
欢迎评论区交流,如果觉得有帮助也欢迎 star 一下 easy-kvcache 项目,后续会继续加入更多 KV cache 优化算法的简化复现。