ICLR'25 | SWIFT:不训练不搜索,Self-Speculative Decoding 的即插即用版
ICLR’25 | SWIFT:不训练不搜索,Self-Speculative Decoding 的即插即用版
原文:SWIFT: On-the-Fly Self-Speculative Decoding for LLM Inference Acceleration Heming Xia, Yongqi Li, Jun Zhang, Cunxiao Du, Wenjie Li,ICLR 2025
这是 Self-Speculative Decoding 系列第三篇。前两篇的进展:
- Draft & Verify(2023):提出范式,层配置靠贝叶斯优化离线搜 6-7 小时,task-specific,换任务就得重搜
- LayerSkip(ACL’24):从训练端解决跨任务问题,效果更好,但必须用特定配方重训模型
两篇工作放在一起,依然是个两难:要么接受高昂的离线搜索代价,要么接受重新训练的门槛。
SWIFT(ICLR 2025)说:都不用。
它的核心主张是:LLM 的层稀疏性是内在属性,可以在推理过程中即时发现,不需要任何预训练改动,优化开销只占总推理时间的 0.8%。
1. 先看两个关键观察
在讲方法之前,先看 SWIFT 给出的两个实验发现,这是整个设计的出发点。
观察一:均匀跳层效果比你想象的好
很多人会觉得,不做任何优化直接跳层,draft token 质量会很差。SWIFT 做了个实验:对 LLaMA-2 均匀跳掉一半的层(就是 every other layer),再用 top-k(k=5)候选而非贪婪输出 draft token。
结果:acceptance rate 高达 90% 以上,平均 speedup 1.22×。
这说明层稀疏性比大家以为的强得多。
观察二:层稀疏性强烈 task-specific
但均匀跳层只能到 1.22×,离实用还有差距。问题在哪?SWIFT 发现,不同任务的最优层配置差异极大——在 storytelling 任务上搜出的最优配置,拿到 reasoning 任务上用,speedup 从 1.47× 直接跌到 1.01×。
如下图,(a) 是跳层数量 vs. acceptance rate 的关系,(b) 是跨任务迁移后 speedup 的崩跌:
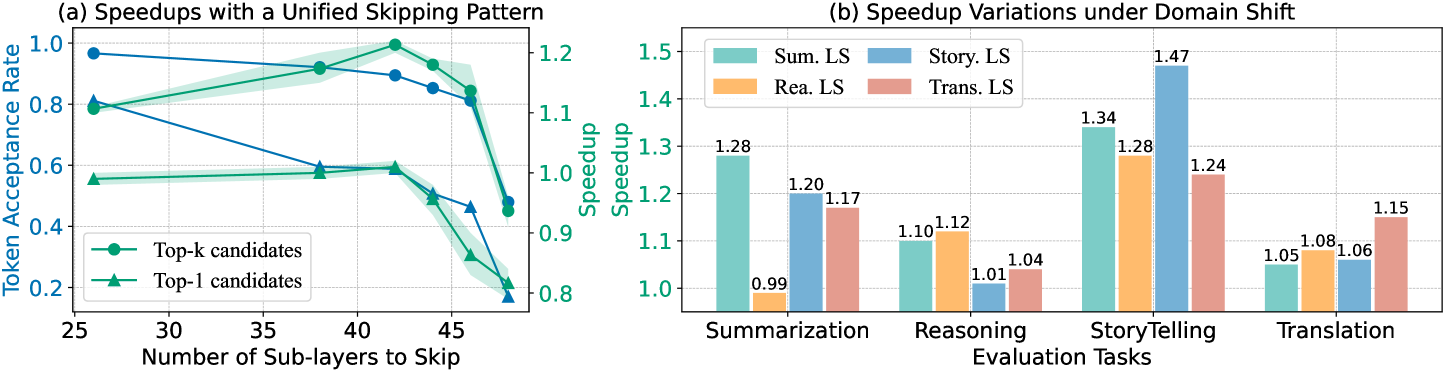
右边柱状图里,Sum. LS(摘要任务搜出的配置)放到 Reasoning 任务上,直接掉到 0.99×——比不加速还差一点点。这正是 Draft & Verify 的根本痛点。
SWIFT 的结论:与其离线为每个任务搜一次,不如在推理时在线自适应地找当前任务的最优配置。
2. 方法:两阶段在线自适应
SWIFT 的推理流程如下图,分两个阶段:

生成序列的前 mN 个 token 用于在线优化层配置(图中黄/红色区域),之后切换到置信度感知加速模式(绿色区域)。
2.1 搜索空间:层配置是个二进制向量
首先明确 SWIFT 在优化什么。
对于一个 L 层的 LLM,层配置用一个二进制向量 z ∈ {0,1}^L 表示:z_l = 1 表示跳过第 l 层,z_l = 0 表示保留。搜索空间是 2^L 种组合——LLaMA-2-13B 有 40 层,搜索空间就是 2^40 ≈ 1 万亿。显然不能穷举。
Draft & Verify 用离线贝叶斯优化搜 7.5 小时来处理这个规模。SWIFT 说:不需要,因为你不需要找全局最优,只需要找当前任务上”足够好”的局部最优,而且可以在推理过程中边跑边找。
2.2 阶段一:在线层配置优化
关键问题:怎么评估一个层配置 z 的好坏,而不引入额外的推理开销?
SWIFT 的核心洞察是:用已经生成的上下文 token 来评估,不需要预测未来。
具体做法:
取最近生成的 γ 个 token 组成一个上下文窗口 [x_{t-γ}, ..., x_{t-1}],对这段已知序列,用当前层配置 z 运行草稿模型:
对窗口内每个位置 i:
draft_logits = forward(x_{i-γ:i}, skip_layers=z)
draft_pred[i] = argmax(draft_logits)
matchness(z) = mean(draft_pred[i] == x_i for all i in window)
也就是说,matchness 衡量的是:如果你用配置 z 来预测这段已知文本,能猜对多少个 token。这段文本已经生成了,对比是瞬间的,不需要额外运行任何新 token 的推理。
这就是为什么 SWIFT 的优化开销只有 0.8%——matchness 的计算几乎零额外代价。
动态搜索策略
有了 matchness 评分,SWIFT 用以下流程在线搜索最优 z:
# 阶段一:上下文积累 + 在线优化
collected_configs = [] # 收集的 (z, matchness) 样本
best_z = uniform_skip_z # 初始:均匀跳层
for t in range(1, optimization_steps):
if t % β == 0: # β=25
# 贝叶斯优化:用已收集样本更新 GP,推荐下一个候选 z
gp.fit(collected_configs, collected_scores)
z_candidate = ucb_acquisition(gp) # UCB 采集函数
else:
# 随机探索:在 best_z 附近随机翻转若干位
z_candidate = random_neighbor(best_z)
# 在当前上下文窗口评估候选 z
score = compute_matchness(z_candidate, context_window[-γ:])
collected_configs.append((z_candidate, score))
if score > best_score:
best_z = z_candidate
best_score = score
# 用 best_z 生成一个新 token(正常推理)
new_token = generate_one_token(context, skip_layers=best_z)
context.append(new_token)
贝叶斯优化的 GP 维护一个从层配置向量到 matchness 分数的映射,每 β 步用 UCB 采集函数选出”预期最优 + 不确定性高”的下一个候选点。随机探索则在 GP 不确定的区域撒网,避免 BO 局部最优。
延迟开销:
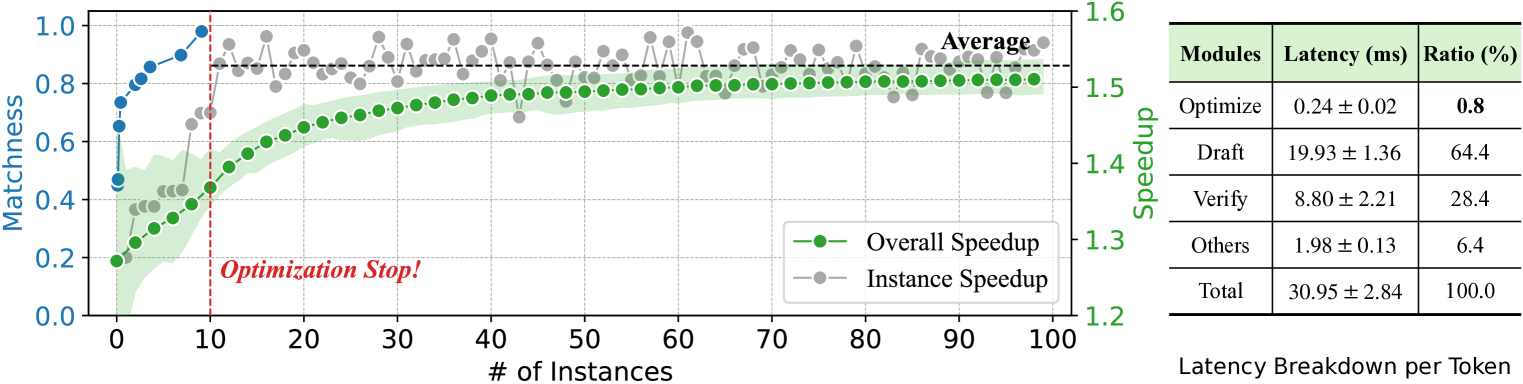
图右边的 latency breakdown:Optimize 只有 0.24ms,占总延迟的 0.8%,Draft 占 64.4%,Verify 占 28.4%。相比 Draft & Verify 的 7.5 小时离线搜索,优化时间缩短了约 180 倍。
2.3 阶段二:置信度感知的推理加速
找到最优 z 之后,进入加速生成阶段。SWIFT 没有直接用跳层模型做 greedy draft,而是加入了两个置信度感知机制。
① 早停(Early-Stopping Drafting)
每生成一个 draft token,计算当前置信度 p_j = max(softmax(logits)):
draft_tokens = []
draft_candidates = []
for j in range(max_draft_len):
logits = forward(context + draft_tokens, skip_layers=best_z)
p_j = logits.softmax().max()
if p_j < ε: # 置信度低于阈值
break # 提前停止,后续 draft 大概率被拒绝
k = confidence_to_topk(p_j) # 见下表
candidates = topk(logits, k)
draft_tokens.append(candidates[0]) # argmax 作为草稿
draft_candidates.append(candidates) # 保存前 k 个候选
② 动态 top-k 候选验证
根据置信度选不同数量的候选,而非固定用 greedy:
| 置信度区间 | top-k |
|---|---|
| (0, 0.5] | k=10 |
| (0.5, 0.8] | k=5 |
| (0.8, 0.95] | k=3 |
| (0.95, 1] | k=1 |
直觉很清楚:置信度高说明草稿模型很确定,k=1 就够(等同于 greedy),验证快;置信度低说明不确定,给更多候选兜底,提高 acceptance rate。
验证与接受逻辑:
# Verify 阶段:一次 batch forward 过完整模型
# 输入:原始 context + 所有 draft_tokens(并行)
verify_logits = full_model_batch_forward(context, draft_tokens)
accepted = 0
for j in range(len(draft_tokens)):
# 完整模型在位置 j 输出的 token
full_token = sample_from(verify_logits[j]) # 无损:按完整模型分布采样
if full_token in draft_candidates[j]:
# 完整模型选的 token 在草稿的 top-k 候选里 → 接受
accepted += 1
else:
# 不在候选里 → 拒绝,用完整模型的 token,截断后续草稿
context.append(full_token)
break
# 接受的那些 draft token 加入输出
context.extend(draft_tokens[:accepted])
无损保证:虽然用了 top-k 而不是严格的 min(1, p/q) 接受条件,但 SWIFT 证明,只要在拒绝时从修正分布 norm(max(0, p_full - p_draft_topk)) 重新采样,最终输出分布仍等价于完整模型的自回归分布。acceptance rate 的数学期望约等于完整模型预测 token 落在 top-k 候选集内的概率之和。
3. 实验:在线 vs. 离线的差距有多大
和 Self-SD(Draft & Verify)对比,这是最关键的一张图:
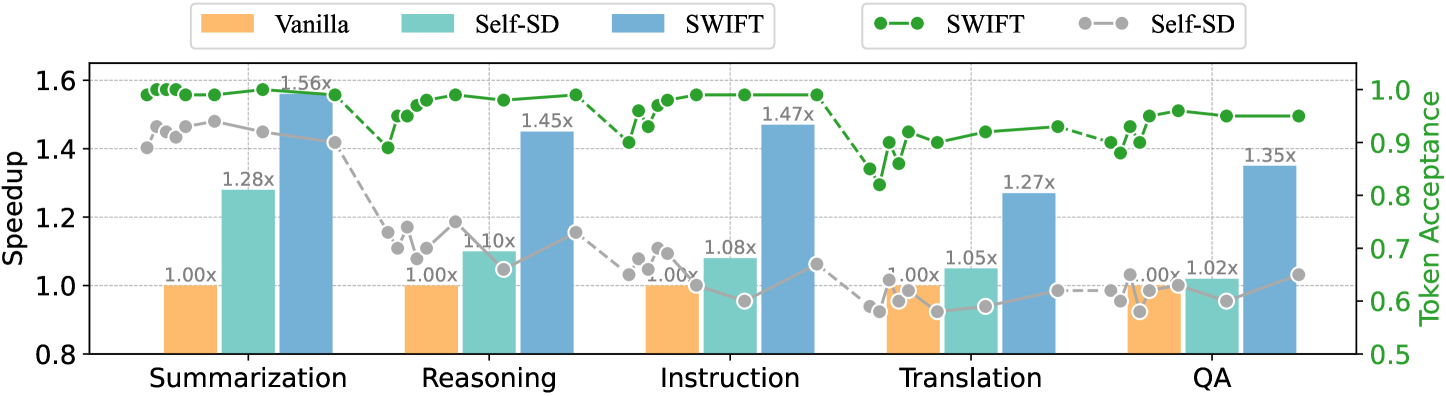
横轴是输入实例序号,绿线(SWIFT)的 speedup 一直稳在 1.4×-1.6×,acceptance rate 稳在 ~95%。灰线(Self-SD)在任务切换时 speedup 和 acceptance rate 同时崩跌——正是 task-specific 层配置的问题。
在 LLaMA-2 系列和 CodeLLaMA 上的主要结果:
- LLaMA-2-13B,CNN/DM:1.37×;GSM8K:1.31×;TinyStories:1.53×
- LLaMA-2-70B 平均:1.48×
- CodeLLaMA-13B,HumanEval:1.40×,acceptance rate 0.98,pass@1 完全一致
在 Yi-34B 和 DeepSeek-Coder-33B 上:
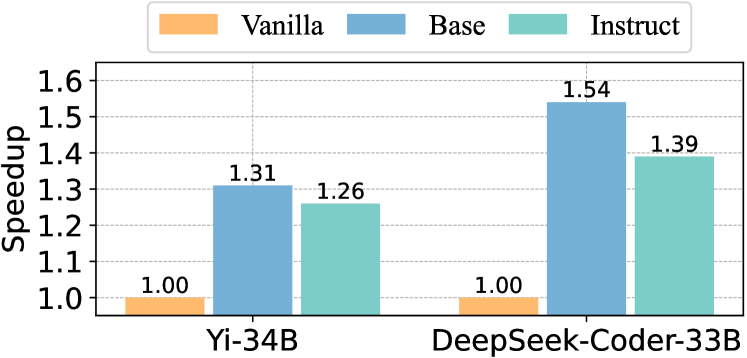
Yi-34B 1.31×,DeepSeek-Coder-33B Base 直接到 1.54×。说明方法对不同架构和规模有良好的泛化性。
规模效应:更大的模型层稀疏性更强,70B 可以以更高的跳层比例(0.45-0.5)运行,最终 speedup 比 13B 更高——大模型越大越”冗余”,SSD 越有搞头。
4. 和前两篇工作的横向对比
| Draft & Verify | LayerSkip | SWIFT | |
|---|---|---|---|
| 需要训练 | 否 | 是(重新预训练) | 否 |
| 离线搜索代价 | ~7.5 小时 | 无需搜索 | ~0(0.8% overhead) |
| 任务切换时 | AR 92%→68% | 稳定 | 稳定(~96%) |
| 最大 Speedup | 1.99×(70B) | 2.16×(8B) | 1.62×(70B) |
| 适用范围 | 任何模型 | 需重训 | 任何模型 |
SWIFT 的绝对 speedup 上限比 LayerSkip 稍低(LayerSkip 因为训练时做了准备,可以更激进地选 exit 层),但适用范围最广——任何现成模型直接插上就能用。
这也是 Self-SD 技术路线走到这里的一个重要节点:不改模型、不预搜索、即插即用的 1.3×-1.6× 加速,已经具备工程落地的条件。
后续的工作开始把 SSD 往新场景推:MoE 架构、扩散语言模型、语音识别……下一篇聊 MoE 上的 SSD,那个场景的问题和动机更刺激一点。
如果这篇文章涉及的 LLM 推理效率优化你想系统深入,可以看看我们团队出版的《动手学 AutoML:从 NAS 到大语言模型优化实战》,书里讲到了 NAS 在推理优化中的应用思路,和 SWIFT 的在线自适应搜索设计有些呼应。
