2025 | SSD for dLLMs:扩散语言模型也能用推测解码,最高 3.46×
2025 | SSD for dLLMs:扩散语言模型也能用推测解码,最高 3.46×
原文:Self Speculative Decoding for Diffusion Large Language Models Yifeng Gao, Ziang Ji, Yuxuan Wang, Biqing Qi, Hanlin Xu, Linfeng Zhang(2025)
这是 Self-Speculative Decoding 系列第五篇。前四篇讲的都是自回归 LLM 上的 SSD,这一篇换了个完全不同的场景:扩散语言模型(Diffusion LLM,dLLM)。
1. dLLM 是什么,为什么要给它加速
dLLM 近年受到越来越多的关注,代表模型有 LLaDA 和 Dream。生成范式和 GPT 系列完全不同:
- 从全 mask 的序列出发,迭代去噪,每步同时更新序列中多个位置
- 用双向注意力(不是 causal attention),生成时能看到全局上下文
- 天然并行:每次前向传播可以同时确定多个 token
听起来应该很快。但实际跑下来,dLLM 依然慢——即使每步并行更新多个位置,迭代的去噪步数依然不少,每步都要跑完整的双向 attention。
下图说明了问题所在:有 cache 时 TPS 随 batch size 增长,但受限于去噪步数,天花板摆在那里:
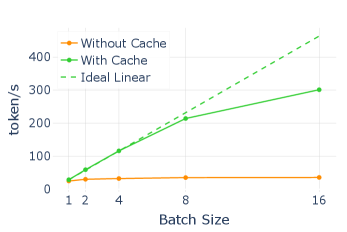
能不能把 Self-Speculative Decoding 移植到 dLLM 上,减少所需的去噪步数?
这篇工作(2025年10月)给出了肯定的答案,是第一个针对 dLLM 的无损自推测加速框架。
2. 先搞清楚:dLLM 的一步去噪在做什么
在讲 SSD 怎么做之前,先说清楚 dLLM 的标准推理流程,不然后面的方法会很难理解。
dLLM 的初始状态:输入序列中,生成位置全部用 [MASK] 占位,条件位置(prompt)保持原 token:
输入:[prompt tokens...] [MASK] [MASK] [MASK] [MASK] [MASK]
↑要生成的 5 个位置
一步去噪:把含 mask 的序列喂进双向 Transformer,输出每个 mask 位置的 token 概率分布,然后按某种策略决定哪些位置在这一步”揭开”(unmask):
def one_denoising_step(x_masked, model, n_unmask=2):
"""
x_masked: 当前序列(含若干 MASK)
n_unmask: 这一步决定揭开多少个位置
"""
# 双向 attention,所有位置同时计算
logits = model(x_masked) # [seq_len, vocab_size]
# 对每个 MASK 位置,计算置信度(softmax 最大值)
mask_positions = [i for i, t in enumerate(x_masked) if t == MASK]
confidences = [logits[i].softmax().max() for i in mask_positions]
# 选置信度最高的 n_unmask 个位置揭开
top_positions = topk(confidences, n_unmask)
# 对选中位置采样(或 greedy)得到新 token
new_tokens = [sample(logits[p]) for p in top_positions]
# 更新序列
x_new = x_masked.copy()
for pos, tok in zip(top_positions, new_tokens):
x_new[pos] = tok
return x_new
标准推理:重复 T 步,每步揭开若干位置,直到所有 MASK 都被填上:
Step 0: [MASK] [MASK] [MASK] [MASK] [MASK]
Step 1: [tok1] [MASK] [MASK] [tok4] [MASK] ← 揭开位置1,4
Step 2: [tok1] [tok2] [MASK] [tok4] [MASK] ← 揭开位置2,5
Step 3: [tok1] [tok2] [tok3] [tok4] [tok5] ← 揭开位置3,最后一步
SSD 的目标:把 T 步压缩成更少的步数,同时保证最终输出一样。
3. 关键挑战:dLLM 的生成不是线性的
在自回归 LLM 里,SSD 很直觉:draft K 个 token,verify,从第一个拒绝的地方截断。
但 dLLM 有两个根本性的不同,让这个逻辑没法直接套用:
挑战一:Semi-Autoregressive 结构
dLLM 每步可能揭开多个位置,而且揭开的位置是不连续的(哪里置信度高就揭哪里)。这不像自回归那样是严格左到右的线性链,”截断”的概念需要重新定义。
挑战二:顺序不一致(Out-of-Order Unmasking)
这是 dLLM SSD 的核心难题。看个例子:
当前状态:[MASK] [MASK] [MASK] [MASK] [MASK]
Draft 模型(一步揭开 2 个位置):
Step 1: 揭开位置3、位置5 → [MASK] [MASK] [tok3] [MASK] [tok5]
Step 2: 揭开位置1、位置4 → [tok1] [MASK] [tok3] [tok4] [tok5]
最终: [tok1] [tok2] [tok3] [tok4] [tok5]
Stepwise 验证(标准一步一步验证):
Step 1 验证:完整模型在初始状态下,最高置信度的 2 个位置是位置1、位置2
→ 标准答案是揭开 [tok1] 和 [tok2]
→ 但 draft 揭开的是位置3、位置5 ← 顺序不一致!即使最终 token 对,顺序不同也判拒绝
问题的本质:dLLM 的输出不只是”最终 token 是什么”,还包括”以什么顺序揭开”。同一组最终 token,不同的揭开顺序在 stepwise 验证框架下是不同的”路径”,其中大部分会被判为不一致。
4. 方法:层次化验证树
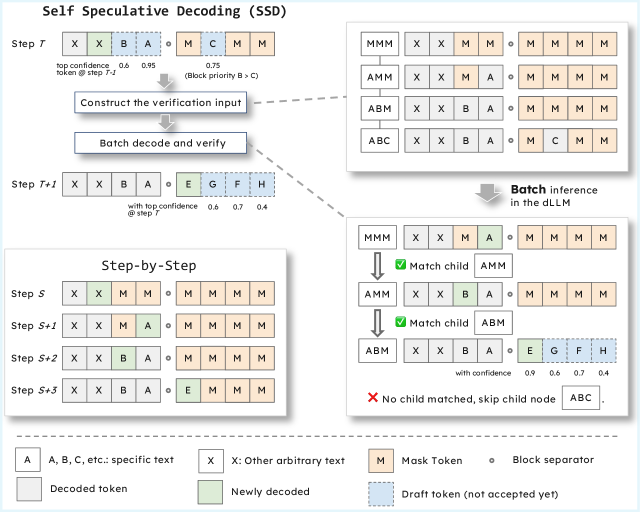
SSD for dLLM 的核心机制是层次化验证树(Hierarchical Verification Tree)。
下图展示了整体框架,左边是 step-by-step 的标准推理,右边是 SSD 的验证树推理:
4.1 线性验证链:基础版本
先理解最简单的情况——线性链(每次 draft 揭开 1 个位置):
Draft 阶段:从当前状态 x(有 M 个 MASK),用草稿模型(跳过部分去噪步骤或用简化版模型)一次前向,按置信度选出 N 个位置,提议 token [d₁, d₂, ..., d_N]:
def draft_phase(x_current, draft_model, N):
logits = draft_model(x_current) # 一次前向
mask_positions = get_mask_positions(x_current)
confidences = [logits[p].softmax().max() for p in mask_positions]
# 选置信度最高的 N 个位置
top_N_positions = topk(confidences, N)
top_N_tokens = [logits[p].argmax() for p in top_N_positions]
# 构建 N+1 个候选状态(验证树的节点)
nodes = [x_current] # 根节点:当前状态
for i in range(N):
x_i = apply_tokens(nodes[0], top_N_positions[:i+1], top_N_tokens[:i+1])
nodes.append(x_i) # 子节点 i:接受前 i 个 draft token 后的状态
return nodes, top_N_positions, top_N_tokens
验证树的 N+1 个节点:
根节点 x₀: [MASK] [MASK] [MASK] [MASK] [MASK] ← 当前状态
子节点 x₁: [d₁] [MASK] [MASK] [MASK] [MASK] ← 接受第1个 draft
子节点 x₂: [d₁] [d₂] [MASK] [MASK] [MASK] ← 接受前2个 draft
子节点 x₃: [d₁] [d₂] [d₃] [MASK] [MASK] ← 接受前3个 draft
...
子节点 x_N: [d₁] [d₂] [d₃] ... [d_N] ← 接受全部 draft
Verify 阶段(关键:一次 batch forward 处理所有节点):
def verify_phase(nodes, full_model):
"""
将 N+1 个节点打包成一个 batch,一次前向传播处理所有
等价于原来的 N+1 次独立前向,但只占用一次的时间(利用 GPU 并行)
"""
# 所有节点组成一个 batch
batch = torch.stack(nodes) # [N+1, seq_len]
# 一次 batch forward(双向 attention)
batch_logits = full_model(batch) # [N+1, seq_len, vocab_size]
return batch_logits
接受判断:
def accept_check(batch_logits, nodes, top_N_positions, top_N_tokens):
accepted = 0
for i in range(len(top_N_tokens)):
# 完整模型对节点 x_i 的输出
# 它在接下来应该揭开哪个位置、填什么 token?
node_logits = batch_logits[i] # 节点 x_i 对应的 logits
mask_positions = get_mask_positions(nodes[i])
confidences = [node_logits[p].softmax().max() for p in mask_positions]
predicted_pos = topk(confidences, 1)[0] # 完整模型最想揭开哪里
predicted_tok = node_logits[predicted_pos].argmax()
# 检查是否和 draft 的第 i+1 个提议一致
if predicted_pos == top_N_positions[i] and predicted_tok == top_N_tokens[i]:
accepted += 1 # 接受,继续检查下一个
else:
# 拒绝:使用完整模型的预测(predicted_pos, predicted_tok),截断
break
return accepted
加速的来源:标准推理需要 T 次独立前向(每次处理 1 个状态),SSD 每轮只需要 1 次 batch forward(处理 N+1 个状态),但通过验证至少接受 1 个、最多接受 N 个去噪步骤的等价结果。即使接受率只有 50%,平均每次 batch forward 能推进 ~N/2 步,比 1 步快得多。
4.2 Mix-Order 扩展:应对顺序不一致
对于顺序不一致的失败,SSD-dLLM 引入了 grandchild 节点:
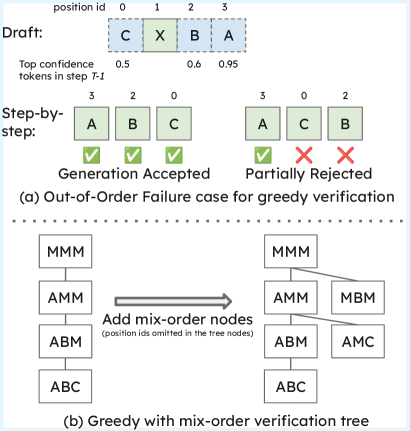
问题重现:节点 x₀(全 MASK),draft 提议揭开位置3。但完整模型对 x₀ 的 stepwise 输出是揭开位置1——顺序不一致,拒绝。
解法:在每个父节点下,同时保留”按 draft 顺序”(子节点)和”按完整模型预测顺序”(grandchild 节点)两条路径:
验证树(mix-order 版本,draft N=3):
x₀(根:全 MASK)
/ \
子节点 x₁ grandchild x₁'
(draft 位置3) (完整模型预测位置1)
/ \
x₂ x₂' ...
(draft+3) (完整模型+)
树的总节点数从 N+1 扩展到 2N-1,多出的节点处理了 draft 顺序和 stepwise 顺序不一致的情况。实验表明 mix-order 带来约 2.5%-3.1% 的额外步数减少,代价是 batch size 增大约 50%-67%。
5. 实验结果
实验在 LLaDA 和 Dream 系列上跑,任务覆盖数学(GSM8K、MATH)、代码(HumanEval、MBPP),单张 A100 80GB。
主要结果:
| 模型 | Draft 长度 | TPS | Speedup | 步数减少 |
|---|---|---|---|---|
| LLaDA-Base | — | 13.84 | 1× | — |
| LLaDA-Base + SSD | 4 | 28.10 | 2.03× | 58.6% |
| LLaDA-Instruct + SSD | 4 | 51.37 | 2.11× | 60.6% |
| Dream-Instruct | — | 16.26 | 1× | — |
| Dream-Instruct + SSD | 5 | 39.58 | 2.43× | 67.6% |
| Dream-Instruct(MBPP) | 5 | 22.07 | 3.46× | 77.4% |
最高的 3.46× 在 Dream-Instruct + MBPP 代码生成任务上,步数减少了 77.4%。所有实验质量指标与 stepwise 解码完全一致——无损。
Speedup 对 sequence length 和 prompt 长度的敏感性:
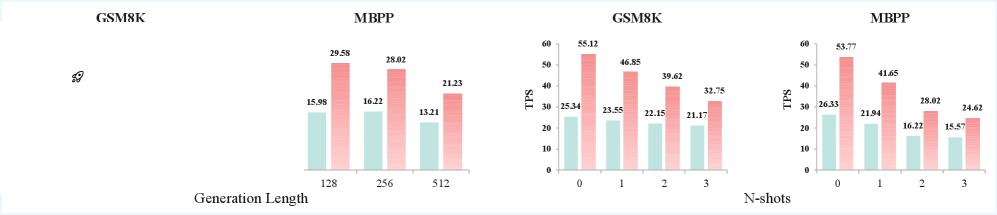
左边两图:生成长度从 128 到 512,SSD(橙色)始终比 baseline(绿色)快。右边两图:随着 N-shots 增加(prompt 变长),speedup 有所下降——因为更长 prompt 让 prefill 开销占比增大,SSD 对 decode 阶段的优化被稀释了。
6. 局限性
顺序不一致问题仍未完全解决:即使加了 Mix-Order 扩展,也只处理了部分情况,这是 dLLM SSD 和自回归 SSD 相比的根本性障碍。
最优 draft 长度模型相关:LLaDA 在 N=4 时最优,Dream 在 N=5 时最优,没有通用值,需要调参。
长 prompt 场景加速比下降:3-shot 下从 ~2.4× 降到 ~1.5×。
7. 小结
dLLM SSD 是 Self-Speculative Decoding 第一次走出自回归 LLM 的范围。2×-3.46× 的加速、完全无损——对于一类本来就”天然并行”却还是跑不快的模型来说,这个结果相当漂亮。
关键创新点值得记住:
- 验证树 = 用一次 batch forward 处理 N+1 种”假设状态”,避免了 N+1 次独立推理
- Mix-Order 节点处理了 dLLM 特有的顺序不一致失败模式
- 无损保证来自严格的 stepwise 一致性检查
下一篇,SSD 去到了离经典 NLP 更远的地方:自动语音识别(ASR),用 CTC encoder 做草稿,LLM decoder 做验证。
如果这篇文章涉及的 LLM 推理效率优化你想系统深入,可以看看我们团队出版的《动手学 AutoML:从 NAS 到大语言模型优化实战》,书里虽然不直接讲 diffusion LLM,但 LLM 效率优化的加速思路和本文有一定关联。
