arXiv'26 | SSD for ASR:用 CTC 编码器打草稿,LLM 验证,语音识别也能推测解码
arXiv’26 | SSD for ASR:用 CTC 编码器打草稿,LLM 验证,语音识别也能推测解码
原文:Self-Speculative Decoding for LLM-based ASR with CTC Encoder Drafts George Saon, Samuel Thomas, Takashi Fukuda, Tohru Nagano, Avihu Dekel, Luis Lastras(IBM Research,2026)
这是 Self-Speculative Decoding 系列第六篇,也是目前时间线上最新的一篇。前五篇的 SSD 都在文本生成领域——不管是 Dense 模型、MoE 模型还是扩散模型,解码的对象都是文本 token。
这篇工作把 SSD 带到了一个完全不同的场景:基于 LLM 的自动语音识别(ASR)。
1. LLM-based ASR 的推理瓶颈
先交代下背景。
现代高性能 ASR 系统越来越多地采用 LLM 作为解码器:Conformer encoder 提取声学特征,LLM decoder 自回归生成文本。代表系统是 IBM 的 granite-speech 系列。
这类系统的质量比传统 CTC/attention hybrid 强不少,但自回归解码的老问题依然存在——每生成一个 token 就得跑一遍完整 LLM,推理速度受限。
但 LLM-ASR 里有一个天然的”草稿生成器”一直没被充分利用:CTC(Connectionist Temporal Classification)encoder head。
CTC 是 Conformer encoder 上的一个附属头,它不需要 LLM 就能独立地对整段语音做一遍快速转录——一次前向传播,直接输出完整的文字假设(hypothesis)。质量比 LLM 差一些,但速度快得多。
这就是 SSD for ASR 的出发点:用 CTC 的输出作为草稿,让 LLM 来验证。
2. 方法:三步走的自推测解码
方法设计如下图:
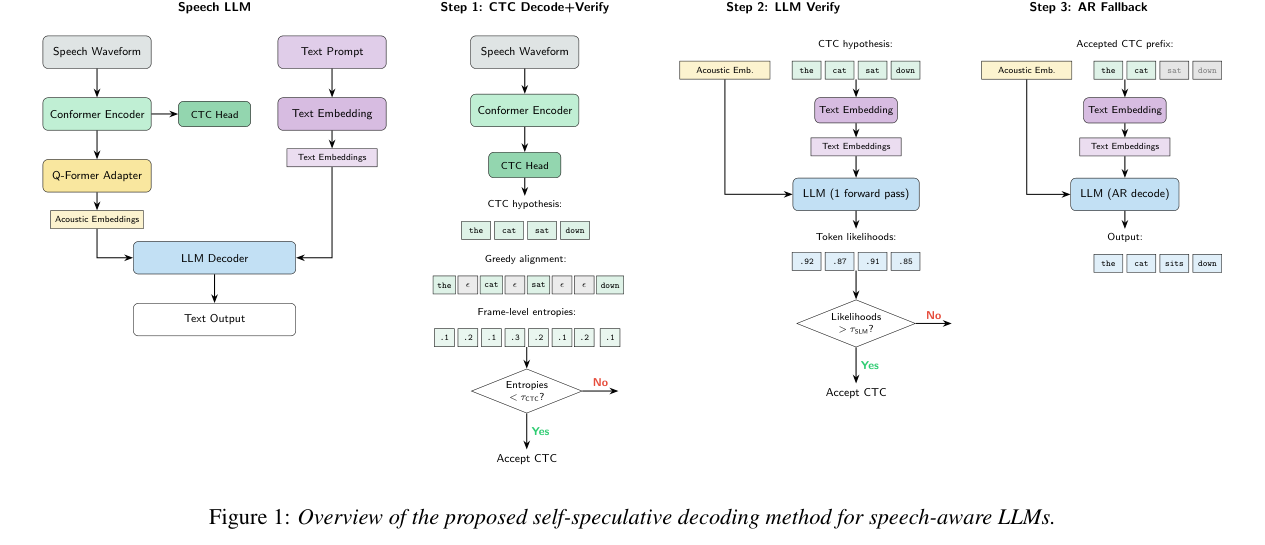
整个推理分三步:
Step 1:CTC Decode + Verify
先跑 Conformer encoder + CTC head,得到一条完整的 CTC hypothesis(如”the cat sat down”)。
然后做第一道验证:计算每个 token 对应的 CTC 帧级熵(frame-level entropy)。如果所有帧的熵都低于阈值 τ_CTC(说明 CTC 非常确定),就直接接受 CTC 结果,跳过 LLM,大幅节省推理时间。
这一步直接接受的比例越高,整体 RTFx 越大。
CTC 帧级熵的具体计算:CTC head 对语音的每一帧 t 输出一个概率分布 p(t)(包含所有词表 token + blank)。帧级信息熵:
\[H(t) = -\sum_{k} p_k(t) \log p_k(t)\]熵越低说明 CTC 在这一帧越”笃定”。接受条件:对 CTC hypothesis 里每个 token x_j,找到与之对齐的所有帧 F_j,如果 max_{t ∈ F_j} H(t) < τ_CTC 对所有 j 成立,则接受整条 hypothesis,跳过 LLM。
Step 2:LLM Verify
对 Step 1 没被直接接受的 CTC hypothesis,把 acoustic embedding + text prompt 一起喂给 LLM,做一次完整前向传播(非自回归),计算每个 CTC token 的 LLM 似然度。
如果所有 token 的 LLM likelihood 都超过阈值 τ_SLM,接受 CTC 结果——这是第二道 filter,用 LLM 的语言理解能力来 double-check CTC 的可信度。
LLM likelihood 的具体含义:把 acoustic embedding(声学特征)和 CTC hypothesis 的所有 token 一起送进 LLM,做一次并行前向传播(类似 teacher forcing,不是自回归):
# 一次并行 forward,不逐 token 解码
all_logits = llm.forward(acoustic_embed, ctc_tokens)
# all_logits[j] 是 LLM 对位置 j 的输出分布
log_likelihoods = [log_softmax(all_logits[j])[ctc_tokens[j]]
for j in range(len(ctc_tokens))]
# 接受条件:所有位置的 log likelihood 都超过 τ_SLM
accept = all(ll > τ_SLM for ll in log_likelihoods)
关键:这是一次 O(1) 的并行 forward,而不是 O(n) 的逐 token 自回归,速度接近 prefill 而非 decode,远快于完整 AR 解码。
Step 3:AR Fallback
Step 2 不通过的部分(LLM 认为 CTC 某些 token 不可信),回退到完整的 LLM 自回归解码,以已接受的 CTC token 为前缀,继续生成剩余文本。
这个三步框架很有意思:CTC 和 LLM 各司其职。CTC 快但不精,LLM 精但慢;SSD 让 CTC 先跑,LLM 只在必要时介入,整体开销大幅降低。
完整决策流程伪代码:
def ssd_asr_inference(audio, conformer, ctc_head, llm, τ_CTC, τ_SLM):
# CTC: 一次前向,得到帧级分布
acoustic_embed, frame_logits = conformer(audio)
ctc_tokens = ctc_decode(frame_logits) # beam search 或 greedy
# ── Step 1: CTC Verify ──────────────────────────────
frame_entropies = compute_entropy(frame_logits) # H(t) for all t
if all_tokens_low_entropy(ctc_tokens, frame_entropies, τ_CTC):
return ctc_tokens # 直接接受,跳过 LLM
# ── Step 2: LLM Verify ──────────────────────────────
all_logits = llm.parallel_forward(acoustic_embed, ctc_tokens)
log_likelihoods = [log_p(all_logits[j], ctc_tokens[j])
for j in range(len(ctc_tokens))]
accepted_prefix = []
for j, ll in enumerate(log_likelihoods):
if ll > τ_SLM:
accepted_prefix.append(ctc_tokens[j])
else:
break # 第一个不满足的位置截断
if len(accepted_prefix) == len(ctc_tokens):
return ctc_tokens # 全部接受
# ── Step 3: AR Fallback ─────────────────────────────
# 以 accepted_prefix 为前缀,从截断位置开始自回归
remaining = llm.autoregressive_decode(
acoustic_embed,
prefix=accepted_prefix,
start_pos=len(accepted_prefix)
)
return accepted_prefix + remaining
这个流程的美妙之处:绝大多数请求在 Step 1 或 Step 2 就结束了(图2数据显示,简单数据集上 AR fallback 占比趋近于零),LLM 的自回归计算只在确实需要时才介入。
3. 关键参数:两个阈值的权衡
方法的核心超参是两个阈值:τ_CTC(CTC 熵阈值)和 τ_SLM(LLM 似然阈值)。
下图展示了两个阈值在 Earnings22 数据集上对 WER 和 RTFx 的影响:
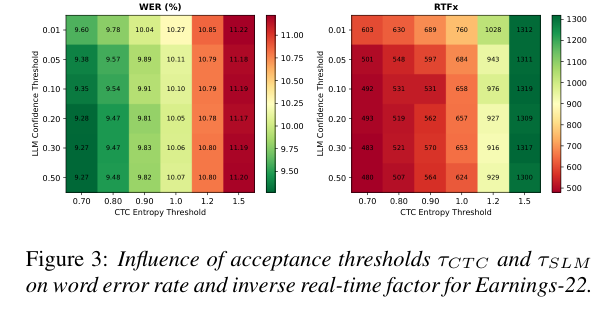
左图是 WER(越低越好),右图是 RTFx(越高越快)。两个阈值形成一个 Pareto frontier:τ_CTC 越低(接受 CTC 的条件越严),WER 越低但 RTFx 越小;τ_SLM 越低(接受 LLM verified CTC 的条件越严),同理。
实验定义了两个工作点:
- High Accuracy(τ_CTC=0.7,τ_SLM=0.2):精度优先,WER 最低
- High RTFx(τ_CTC=3.0,τ_SLM=0.1):速度优先,RTFx 最大
4. 实验结果
测试模型是 granite-speech-4.0-1b(IBM,1B 参数),在英语 Open ASR、多语言 MLS、CommonVoice 等数据集上评测,H100 单卡测速。
下表是核心结果:
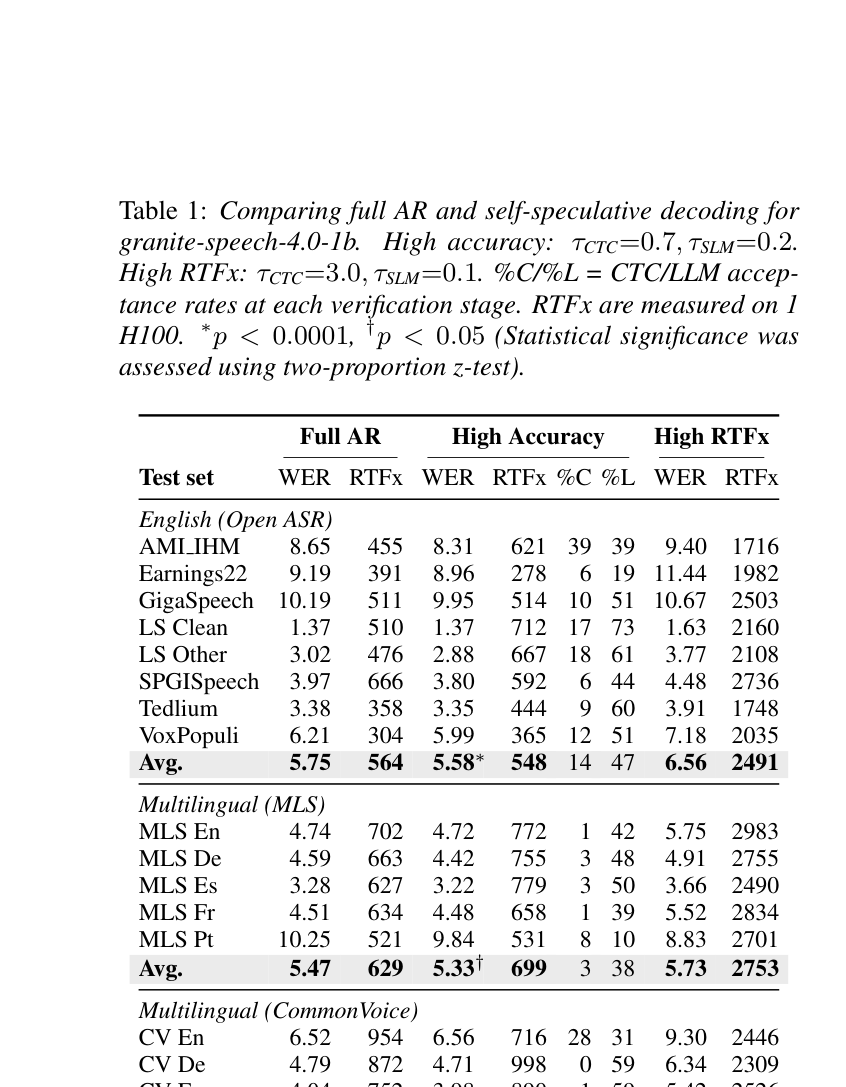
几个关键数字:
英语 Open ASR 平均:
- Full AR:WER 5.75,RTFx 564
- High Accuracy:WER 5.58(显著低于 Full AR!),RTFx 548(几乎持平)
- High RTFx:WER 6.56,RTFx 2491(速度 4.4× 于 Full AR)
等等——High Accuracy 模式下 WER 反而比 Full AR 更低?这是因为 CTC 在某些情况下恰好纠正了 LLM 的错误。Table 2(原文)专门列了一些例子,说明 LLM verified CTC 的输出比纯 AR 更准的案例。
本质原因在于两个模型各有盲区:LLM 有语言模型偏置,倾向于生成”读起来流畅”的文本,有时会把口语连读、领域专名或同音词”脑补”成更常见的表达(典型错误如把人名/地名替换成近音词);而 CTC 完全依赖声学信号,没有这种语言偏置,在声学清晰的情况下反而更贴近真实发音。当 τ_SLM 设置适中时,Step 2 的验证逻辑能识别出”LLM 对这条 hypothesis 信心充足”的情况——此时 CTC 的声学精准度和 LLM 的语言确认形成互补,联合结果优于单独跑 LLM 自回归的结果。
多语言 MLS 平均:
- Full AR:WER 5.47,RTFx 629
- High Accuracy:WER 5.33(同样更低),RTFx 699
High RTFx 模式下各数据集的时间分解:
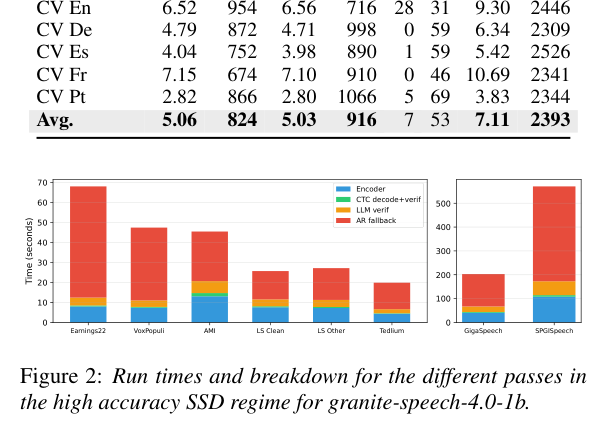
橙色(AR fallback)在 Earnings22 这类难数据集上占比最大,在 LS Clean 这类干净数据集上几乎为零——说明模型在”简单”音频上基本靠 CTC 直接解决,LLM 只在难例上介入。
与其他 SOTA 系统对比:
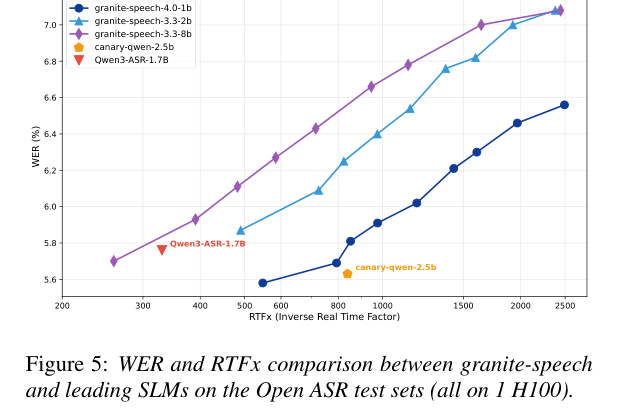
granite-speech 系列通过调整 SSD 阈值可以在 WER-RTFx 平面上走出一条 Pareto 曲线,在不同速度-精度要求下都能和 canary-qwen-2.5b 等竞争对手持平甚至更优。
5. 和经典 SSD 的根本差异
这篇工作和前几篇 SSD 在本质上有所不同,值得单独说一下:
| 经典 Self-SD(Dense/MoE/dLLM) | SSD for ASR | |
|---|---|---|
| 草稿生成器 | 目标模型的”残缺版”(跳层) | 独立的 CTC encoder head |
| 验证方式 | 同一模型完整前向传播 | 同一 LLM 的完整前向传播 |
| 共享参数 | 是(草稿和验证共享权重) | 部分(encoder 共享,CTC head 独立) |
| “自”的含义 | 同一模型自己给自己打草稿 | 同一系统内的 CTC 分支给 LLM 打草稿 |
所以这篇的”Self”其实比前几篇稍松一些——不是同一模型的不同”深度版本”,而是同一 system 内两个分支的协作。但核心精神是一样的:避免引入外部独立草稿模型,用系统内部的廉价计算路径生成草稿。
6. 小结:SSD 的适用范围比我们想象的宽
回顾一下整个系列的技术脉络:
| 论文 | 场景 | 草稿来源 | 核心贡献 |
|---|---|---|---|
| Draft & Verify(2023) | Dense LLM | 跳层浅版本 | 提出 Self-SD 范式 |
| LayerSkip(ACL’24) | Dense LLM | 训练支持的 early exit | 训练端配合,跨任务稳定 |
| SWIFT(ICLR’25) | Dense LLM | 在线自适应选层 | 无需训练,即插即用 |
| SS-MoE(WWW’25) | MoE LLM | 少激活 expert 的浅版本 | SSD × MoE,解决显存墙 |
| SSD-dLLM(2025) | 扩散 LLM | 置信度最高的并行预测 | SSD 走出自回归边界 |
| SSD-ASR(2026) | LLM-based ASR | CTC encoder 分支 | SSD 进入语音识别领域 |
从 Dense → MoE → dLLM → ASR,SSD 这个框架在不断往新场景迁移,核心问题始终是同一个:怎么在不引入外部独立草稿模型的前提下,用系统内部的廉价路径加速推理。
离下一个还没被覆盖的场景,只差一点想象力。
如果这篇文章涉及的 LLM 推理效率优化你想系统深入,可以看看我之前出版的《动手学 AutoML:从 NAS 到大语言模型优化实战》,书里有专章讲 LLM 推理效率,和本文的加速框架思路有直接关联。
