EMNLP'23 | 不用额外模型,LLM 自己给自己加速——Self-Speculative Decoding 原理详解
EMNLP’23 | 不用额外模型,LLM 自己给自己加速——Self-Speculative Decoding 原理详解
原文:Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding
1. 前言
你有没有想过,LLM 推理慢,根子上是慢在哪里?
不是矩阵乘法太重——现代 GPU 做矩阵乘法其实挺快的。真正的瓶颈是内存带宽。每生成一个 token,模型要把所有权重从显存搬到计算单元跑一遍,然后吐出一个 token。然后再搬一遍,再吐一个。这个过程是严格串行的,完全没办法并行。
Speculative Decoding(投机解码)就是为了解决这个问题而生的。核心思路是:找一个便宜的小模型快速起草(draft)一批 token,然后让大模型一次性并行验证这批 token,接受对的,拒绝错的,但输出分布保证和原始大模型完全一致——也就是说,这是无损加速。
但有个很现实的问题:从哪儿来这个小模型?
标准 Speculative Decoding 需要一个独立的 draft 模型,参数规模通常是 target 模型的 1/10 左右(比如 7B 配一个 700M),还得保证两个模型词表对齐、输出分布相近。这在工程落地上非常麻烦:要额外维护一个模型、占额外显存、还要操心对齐问题。
这篇来自 IBM Research 的工作给出了一个优雅的解法:
不需要额外的 draft 模型。用同一个模型、跳过部分层来起草,再用完整模型验证。
这就是 Self-Speculative Decoding。
2. 核心思路:用”残缺版自己”起草
2.1 为什么可以跳层?
LLM 中有个被反复观察到的现象:并不是每一层都同等重要。
中间层的 attention 和 MLP,在很多 token 的推理中贡献其实很小——跳过它们,输出的分布变化不大。这和知识蒸馏、层剪枝的直觉是一脉相承的。
Self-Speculative Decoding 利用的就是这个性质:跳过一部分中间层,得到一个”瘦身版”的 draft 模型,它的权重和原模型完全共享,不需要额外存储,推理速度更快。
2.2 整体流程
如下图,整个过程分两个阶段交替进行:

Draft 阶段(跳层快速生成):用跳过若干层的残缺模型,自回归生成 K 个候选 token。这一步每个 token 的计算量只有完整模型的一个子集,速度很快。
Verify 阶段(完整模型并行验证):把这 K 个 draft token 一次性送进完整模型,做一次并行前向。验证的逻辑如下:
设完整模型在位置 $t$ 给出的分布是 $p(x_t)$,draft 模型给出的是 $q(x_t)$,draft 采样出的 token 是 $\tilde{x}_t$。
接受概率定义为:
\[\alpha_t = \min\left(1, \frac{p(\tilde{x}_t)}{q(\tilde{x}_t)}\right)\]以概率 $\alpha_t$ 接受 $\tilde{x}_t$,否则按修正分布 $\text{norm}(\max(0, p - q))$ 重新采样。
这套机制保证了最终输出分布严格等于完整模型,是有理论保证的无损加速。
3. 跳哪些层?用贝叶斯优化搜
这套方法最关键的工程问题是:具体跳哪些层?
不是随便跳都行的。跳太少加速不明显,跳太多 draft 质量太差,验证阶段几乎全拒绝,整体反而更慢。
论文用贝叶斯优化来搜最优的 skip 层组合,如下图:
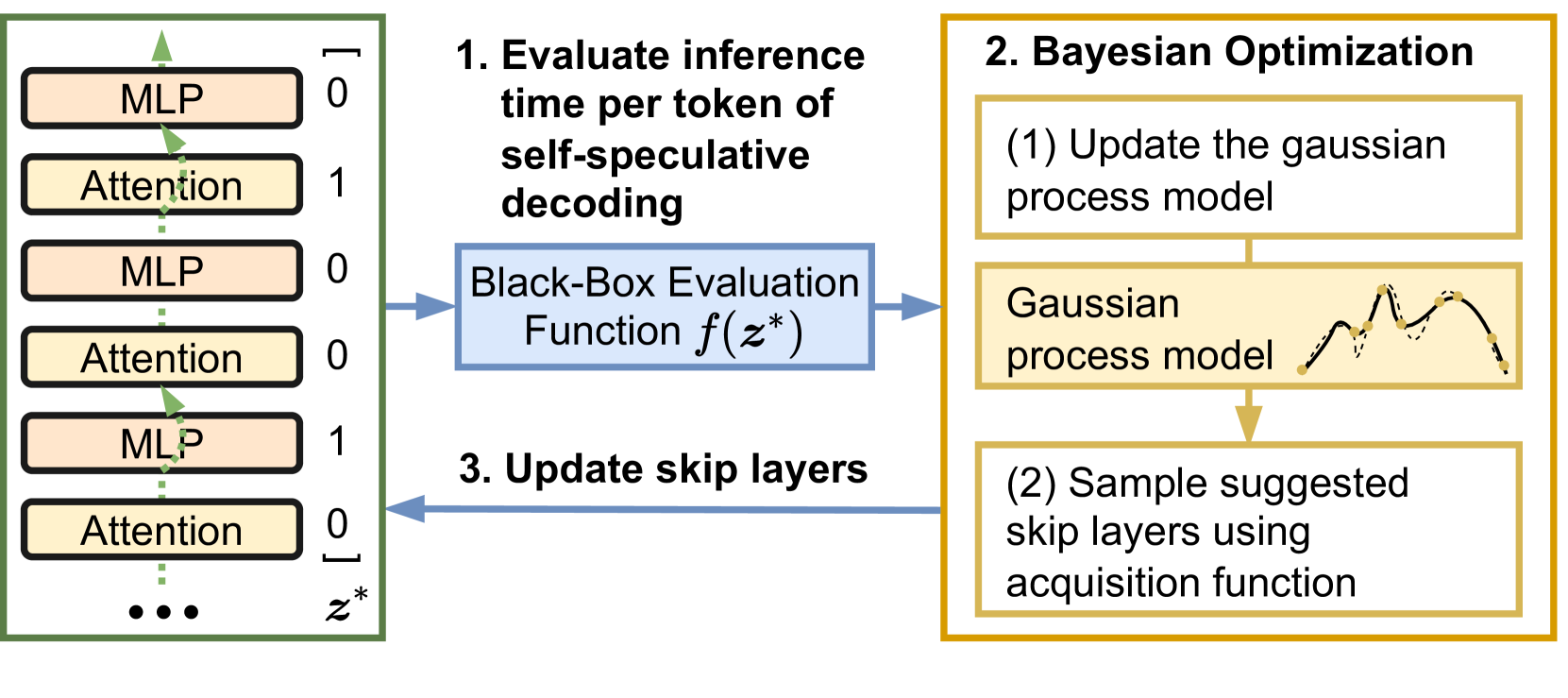
搜索过程是一个经典的 BO 循环:
- 给定一个 skip 层的二值向量 $z^* \in {0,1}^L$(1 表示跳过该层)
- 用黑盒评估函数 $f(z^*)$ 跑一遍 self-speculative decoding,得到每个 token 的实际推理耗时
- 用高斯过程拟合目标函数,用 acquisition function 采样下一个候选点
- 迭代若干轮,找到最优的 skip 组合
由于搜索空间是离散的(每层独立跳/不跳),BO 的效率优势非常明显——不需要穷举所有 $2^L$ 种组合。
用代码把这个搜索流程复现出来:
import numpy as np
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import Matern
from scipy.stats import norm
def evaluate_skip_config(model, tokenizer, skip_layers, calibration_texts, K=4):
"""
黑盒评估函数 f(z*):
给定一个 skip 层组合,跑一遍 self-speculative decoding,
返回平均每个 token 的生成耗时(越低越好)。
"""
import time
total_tokens = 0
total_time = 0.0
for text in calibration_texts:
inputs = tokenizer(text, return_tensors="pt").to(model.device)
start = time.perf_counter()
output = self_speculative_decode(
model, inputs.input_ids, skip_layers=skip_layers, K=K, max_new_tokens=50
)
elapsed = time.perf_counter() - start
new_tokens = output.shape[1] - inputs.input_ids.shape[1]
total_tokens += new_tokens
total_time += elapsed
return total_time / max(total_tokens, 1) # 越小越好
def expected_improvement(mu, sigma, best_so_far):
"""
EI acquisition function:
估计在当前高斯过程预测下,新候选点比历史最优提升多少。
mu/sigma 是 GP 对候选点的预测均值和标准差。
"""
z = (best_so_far - mu) / (sigma + 1e-9)
ei = (best_so_far - mu) * norm.cdf(z) + sigma * norm.pdf(z)
return ei.clip(min=0)
def bayesian_optimize_skip_layers(
model,
tokenizer,
num_layers: int, # 模型总层数,如 LLaMA-2-13B = 40
max_skip_ratio: float = 0.5, # 最多跳多少比例的层(防止 draft 质量崩掉)
n_init: int = 10, # 初始随机探索的点数
n_iter: int = 40, # BO 迭代轮数
K: int = 4,
calibration_texts=None,
):
"""
用贝叶斯优化搜索最优 skip 层组合。
搜索空间:长度为 num_layers 的二值向量,1 表示跳过该层。
目标:最小化 evaluate_skip_config 返回的每 token 耗时。
"""
if calibration_texts is None:
calibration_texts = ["Tell me about the history of artificial intelligence."] * 5
max_skip = int(num_layers * max_skip_ratio)
# ---- 1. 把二值向量映射到连续空间供 GP 使用 ----
# 直接用二值向量本身作为特征(整数 0/1),Matern 核在离散空间也工作得不错
X_observed = [] # shape: (n_obs, num_layers),每行是一个 skip 配置
y_observed = [] # shape: (n_obs,),对应的评估耗时
def sample_valid_config():
# 随机生成一个合法的 skip 配置(跳层数不超过 max_skip)
n_skip = np.random.randint(1, max_skip + 1)
# 论文观察到浅层/深层不适合跳,这里加个软约束:
# 只从中间 60% 的层里采样 skip 候选
mid_start = num_layers // 5
mid_end = num_layers - num_layers // 5
candidates = list(range(mid_start, mid_end))
skip_idx = np.random.choice(candidates, size=min(n_skip, len(candidates)), replace=False)
z = np.zeros(num_layers, dtype=int)
z[skip_idx] = 1
return z
# ---- 2. 初始随机探索 ----
print(f"[BO] 初始随机探索 {n_init} 个配置...")
for i in range(n_init):
z = sample_valid_config()
skip_layers = list(np.where(z == 1)[0])
cost = evaluate_skip_config(model, tokenizer, skip_layers, calibration_texts, K)
X_observed.append(z)
y_observed.append(cost)
print(f" [{i+1}/{n_init}] skip={skip_layers} -> {cost:.4f}s/token")
# ---- 3. BO 迭代 ----
gp = GaussianProcessRegressor(
kernel=Matern(nu=2.5),
alpha=1e-6,
normalize_y=True,
n_restarts_optimizer=5,
)
best_cost = min(y_observed)
best_config = X_observed[np.argmin(y_observed)]
print(f"\n[BO] 开始迭代优化,初始最优耗时 {best_cost:.4f}s/token")
for iteration in range(n_iter):
# 用已有观测拟合 GP
X_arr = np.array(X_observed, dtype=float)
y_arr = np.array(y_observed)
gp.fit(X_arr, y_arr)
# 随机生成一批候选配置,用 EI 挑最有潜力的
n_candidates = 2000
candidates = np.array([sample_valid_config() for _ in range(n_candidates)], dtype=float)
mu, sigma = gp.predict(candidates, return_std=True)
ei_scores = expected_improvement(mu, sigma, best_cost)
# 选 EI 最高的候选点
best_candidate_idx = np.argmax(ei_scores)
z_next = candidates[best_candidate_idx].astype(int)
skip_layers_next = list(np.where(z_next == 1)[0])
# 评估这个候选点
cost_next = evaluate_skip_config(model, tokenizer, skip_layers_next, calibration_texts, K)
X_observed.append(z_next)
y_observed.append(cost_next)
if cost_next < best_cost:
best_cost = cost_next
best_config = z_next
print(f" [iter {iteration+1}] ✓ 新最优!skip={skip_layers_next} -> {cost_next:.4f}s/token")
else:
print(f" [iter {iteration+1}] skip={skip_layers_next} -> {cost_next:.4f}s/token")
best_skip_layers = list(np.where(best_config == 1)[0])
print(f"\n[BO] 搜索完成。最优 skip 层:{best_skip_layers},耗时 {best_cost:.4f}s/token")
return best_skip_layers
几个实现细节说明:
- GP 核选 Matern(ν=2.5):比 RBF 对不光滑函数更鲁棒,而 skip 层耗时对输入的响应确实不太平滑
- 候选集随机采样 + EI 排序:搜索空间是离散的,没法对 acquisition function 求梯度,所以用”大量随机候选 → 选 EI 最高”的方式近似最优化
- 软约束中间层:采样时限制只从中间 60% 的层里选 skip 候选,对应论文观察到的”浅层/深层不适合跳”这一规律
-
normalize_y=True:不同配置的耗时数量级可能差异不大(都在 0.01~0.1s/token 量级),归一化后 GP 拟合更稳定
搜出来的结果也很有意思,如下图(LLaMA-2-13B 上的 skip 分布):

规律很直观:浅层和深层基本不跳,中间层跳得更激进。这和直觉一致——底层做特征提取、顶层做输出预测,都比较关键;中间层冗余度最高。
4. 实验效果
在 LLaMA-2-13B 上,Self-Speculative Decoding 实现了 1.3x~2.0x 的端到端加速,具体数字取决于任务和接受率。
如下图,接受率和 draft token 数 K 对加速比的影响:
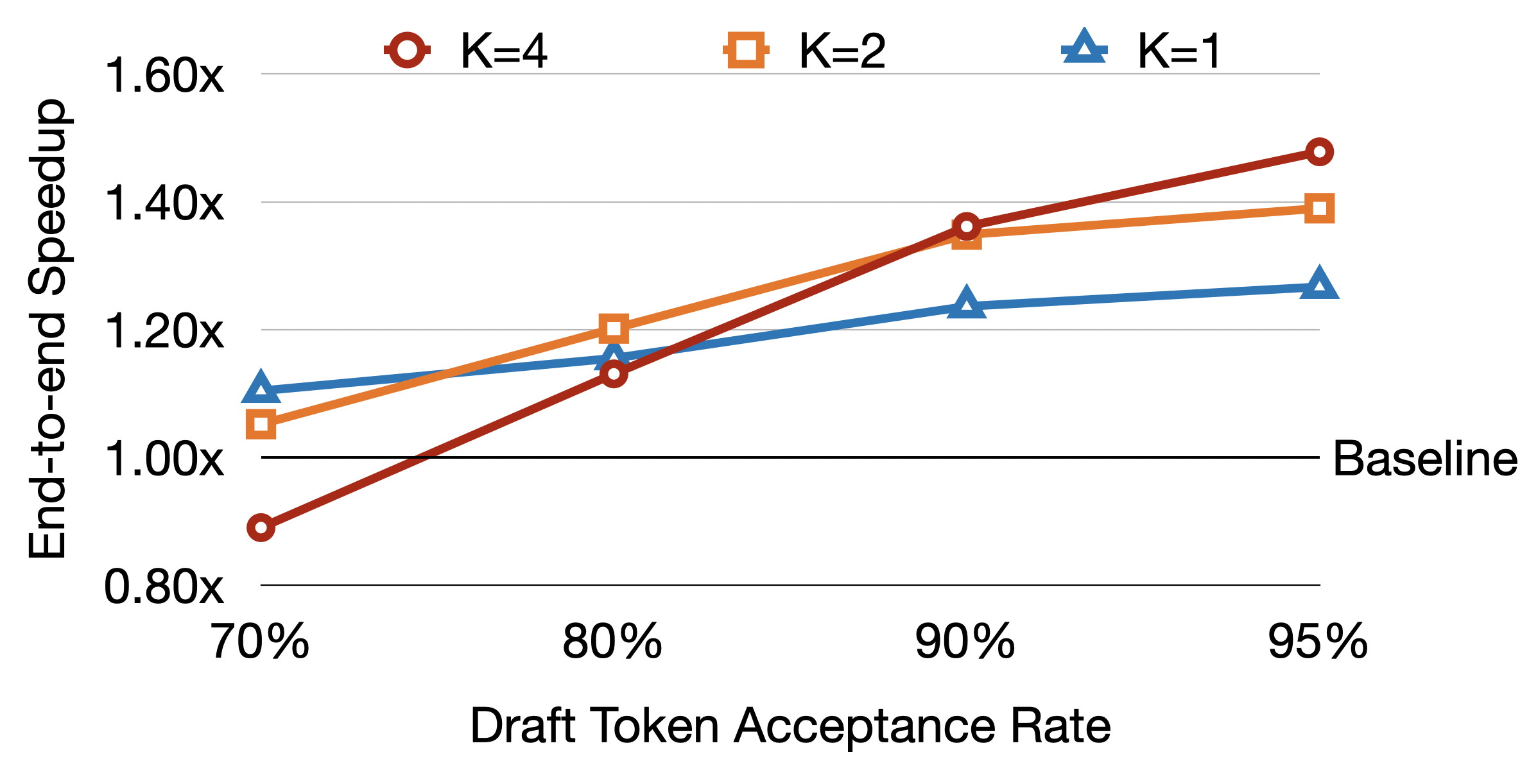
几个关键结论:
- 接受率越高,K 越大,加速越明显——这是理论上的必然,接受率高说明 draft 模型质量好,并行验证的红利吃得更充分。
- 接受率在 90% 以上时,K=4 能达到约 1.35x 加速。
- 接受率低于 80% 时,K=4 反而可能拖累整体(验证开销大于节省的时间),K=2 更稳。
相比标准 Speculative Decoding,Self-Speculative 的优势在于:
- 无需额外模型,只需要一个模型的显存
- 权重完全共享,没有对齐问题
- 输出质量有理论保证,不是近似方法
代价是:draft 质量可能不如专门训练的小模型,接受率相对低一些。
5. 用代码复现核心逻辑
按照论文描述,把 draft + verify 的核心逻辑复现出来(简化版,便于理解):
import torch
import torch.nn.functional as F
from typing import List
def self_speculative_decode(
model,
input_ids: torch.Tensor,
skip_layers: List[int], # 贝叶斯优化搜出来的跳层列表
K: int = 4, # 每轮 draft 的 token 数
max_new_tokens: int = 100,
temperature: float = 1.0,
):
"""
Self-Speculative Decoding 主循环。
model: 支持 forward(input_ids, skip_layers=None) 的 LLM
skip_layers: draft 阶段跳过的层索引列表
K: 每轮 draft 的 token 数
"""
generated = input_ids.clone()
while generated.shape[1] - input_ids.shape[1] < max_new_tokens:
# ---- Draft 阶段:跳层自回归生成 K 个 token ----
draft_tokens = []
draft_probs = []
draft_input = generated.clone()
for _ in range(K):
with torch.no_grad():
# 跳过 skip_layers 中的层,用残缺模型推理
logits = model(draft_input, skip_layers=skip_layers).logits[:, -1, :]
probs = F.softmax(logits / temperature, dim=-1) # q(x_t)
next_token = torch.multinomial(probs, num_samples=1)
draft_tokens.append(next_token)
draft_probs.append(probs)
draft_input = torch.cat([draft_input, next_token], dim=1)
# ---- Verify 阶段:完整模型并行验证 ----
# 把 generated + K 个 draft token 一次性过完整模型
verify_input = torch.cat([generated] + draft_tokens, dim=1)
with torch.no_grad():
# 完整模型,不跳层
verify_logits = model(verify_input, skip_layers=None).logits
# verify_logits[:, -K-1:-1, :] 对应 K 个位置的完整模型输出
accepted_len = 0
for i in range(K):
pos = generated.shape[1] + i - 1 # 对应 verify_logits 中的位置
full_probs = F.softmax(verify_logits[:, pos, :] / temperature, dim=-1) # p(x_t)
q_prob = draft_probs[i]
draft_tok = draft_tokens[i].squeeze()
# 计算接受概率 α = min(1, p(x) / q(x))
alpha = torch.clamp(full_probs[0, draft_tok] / (q_prob[0, draft_tok] + 1e-10), max=1.0)
if torch.rand(1).item() < alpha.item():
# 接受这个 draft token
accepted_len += 1
else:
# 拒绝:按修正分布 norm(max(0, p - q)) 重新采样
corrected = torch.clamp(full_probs - q_prob, min=0)
corrected = corrected / (corrected.sum() + 1e-10)
next_token = torch.multinomial(corrected, num_samples=1)
draft_tokens[i] = next_token
break
# 把接受的 token 追加到输出序列
accepted_tokens = torch.cat(draft_tokens[:accepted_len + 1], dim=1)
generated = torch.cat([generated, accepted_tokens], dim=1)
# 如果遇到 EOS,终止
if draft_tokens[accepted_len].item() == model.config.eos_token_id:
break
return generated
def build_skip_layer_model(base_model, skip_layers: List[int]):
"""
对 HuggingFace LLaMA/Mistral 类模型,
在 forward 时动态跳过指定层。
实际用法:monkey-patch model.forward 或用 hook 实现。
这里给出一个简化的 wrapper 示意。
"""
import types
original_forward = base_model.model.forward
def patched_forward(self, *args, skip_layers=None, **kwargs):
if skip_layers is None:
return original_forward(*args, **kwargs)
# 临时把 skip 的层换成 identity,推理完再换回来
skipped = {}
for idx in skip_layers:
layer = self.layers[idx]
skipped[idx] = layer
self.layers[idx] = torch.nn.Identity() # 跳过
output = original_forward(*args, **kwargs)
for idx, layer in skipped.items():
self.layers[idx] = layer # 恢复
return output
base_model.model.forward = types.MethodType(patched_forward, base_model.model)
return base_model
几点说明:
-
draft_probs存的是 draft 阶段每个位置的完整 softmax 分布 $q(x_t)$,验证时需要用到 - 接受/拒绝的判断是逐 token 顺序执行的,第一个被拒绝的位置就截断,后面的 draft token 全部丢弃
- 拒绝时的修正采样
norm(max(0, p - q))是理论保证输出分布正确性的关键——它补了 $p$ 比 $q$ 多出来的那部分概率质量 - 实际工程实现中 skip 层不会用 Identity 替换(有额外开销),而是在 transformer 循环里直接
if i in skip_set: continue
6. 几点个人 take
这篇工作的思路相当干净——问题清晰,解法优雅,理论保证完备。
但有几个地方值得打一个问号:
1. 贝叶斯优化的搜索成本。BO 本身不贵,但每次评估需要实际跑 self-speculative decoding 采几百个 token,累计下来开销不小。论文报的是 “less than 1 hour on a single A100”,对于生产环境算是可接受,但如果模型版本经常更新或者部署场景频繁变化,重搜的成本就不太友好了。
2. 跳层方案的泛化性。搜出来的最优 skip 组合是针对特定数据分布的。如果推理时的输入分布和搜索时差异较大(比如代码任务的 skip 方案用在数学推理上),加速比可能会打折扣,接受率也会下降。
3. 和 KV Cache 的交互。Draft 阶段跳层后,KV Cache 的结构和完整模型不一样,需要仔细处理——论文对这块的描述相对简略,实际实现里是个工程细节的坑。
整体来说这是一篇很扎实的工作,把”不需要额外模型”这个约束真正落地了。对于资源受限的部署场景(单卡跑 13B 这类),Self-Speculative Decoding 是个非常实用的选项。
如果这篇文章涉及的 LLM 推理加速你想系统深入,可以看看我之前出版的《动手学 AutoML:从 NAS 到大语言模型优化实战》,书里有专章讲 LLM 推理效率和参数高效微调,和本文的工程背景有直接关联。
