ACL'24 | LayerSkip:Meta 把 Self-Speculative Decoding 从头训到尾,直接干到 2.16×
ACL’24 | LayerSkip:Meta 把 Self-Speculative Decoding 从头训到尾,直接干到 2.16×
原文:LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich et al.(Meta),ACL 2024
1. 前言
你有没有遇到过这种情况:LLM 生成一段简单的文字,每个 token 都得走完模型的所有 32 层甚至更多,哪怕生成的是”的”、”是”这种明显不需要那么多算力的 token。
这就是自回归解码的根本症结。推测解码(Speculative Decoding)这两年提出了一个很优雅的解法:用一个”小模型”快速生成多个候选 token,再让大模型一次性并行验证。但小模型从哪来?要么得专门训一个,要么从大模型里裁剪——额外显存、额外维护成本。
Draft & Verify(2023 年)把这个思路往前推了一步:不要独立的小模型,直接跳过大模型的部分中间层来打草稿。同一套参数,浅版本生成草稿,完整版验证,零额外显存,最高做到 1.99×。
但它有个硬伤——层配置需要离线贝叶斯搜索,每次跑 6-7 小时,而且结果 task-specific:在摘要任务上搜出来的最优跳层方案,拿到代码生成上用,acceptance rate 直接从 92% 跌到 68%。
为什么会这样?因为模型训练时压根没为”跳层推理”做过准备。 越靠后的层对前面所有层的输出依赖越深,强行跳掉中间几层,质量当然不稳定。
LayerSkip(Meta,ACL 2024)的出发点就是这个:从训练阶段就让模型学会在任意早期层退出,推理时就不需要搜索了。
2. 训练:两个改动
LayerSkip 在训练时加了两样东西,改动不大,但效果很关键。
Layer Dropout:越靠后,dropout 越猛
普通 dropout 作用在单个神经元,LayerSkip 的 dropout 作用在整个 Transformer 层。关键在于:越靠后的层,dropout 概率越高:
p_l = (l / L) × p_max
第 0 层几乎不 dropout,最后一层 dropout 率最高(p_max 一般设 0.2-0.4)。训练时后面的层经常”消失”,模型就被迫在更浅的层学会输出有意义的表征——不然 loss 没法收敛。
Shared Early Exit Loss:所有层共用一个 LM Head
光有 dropout 还不够。正常训练时,loss 只在最后一层算,浅层的 hidden state 根本没对齐到词表空间,即便从中间层强行退出,输出也是乱码。
LayerSkip 的解法是所有层共享同一个 LM Head,训练时对多个中间层同时算 cross-entropy,加权求和作为总 loss:
L_total = Σ_l weight_l × CE(LM_head(h_l), y)
这样浅层 hidden state 也被强制对齐词表空间。下图展示了这个设计的本质——训练一次,等价于得到了多个不同深度的共享权重子模型:
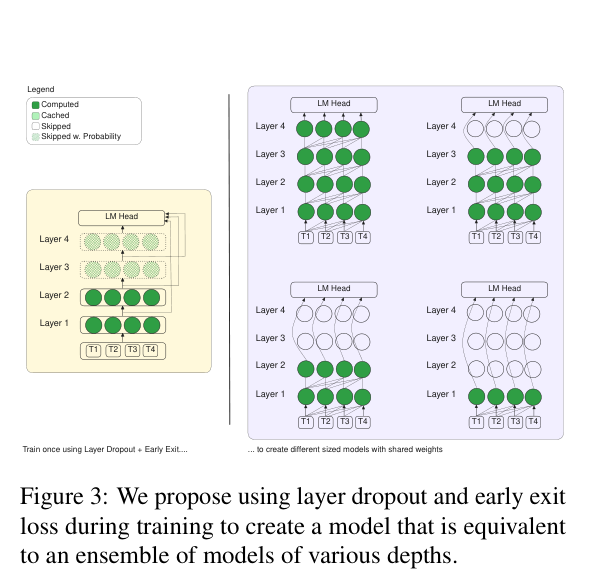
3. 推理:Early Exit + Self-Speculative Decoding
训好之后,LayerSkip 提供两种推理方式。
模式一:直接 Early Exit(有损,更快)
在第 e 层退出,不跑后面的层。有损但快,适合对精度要求不严的场景。下图展示了 Llama2 7B 在不同层 exit 时各任务的精度——绿线是 LayerSkip 训练配方,蓝线是普通训练模型:
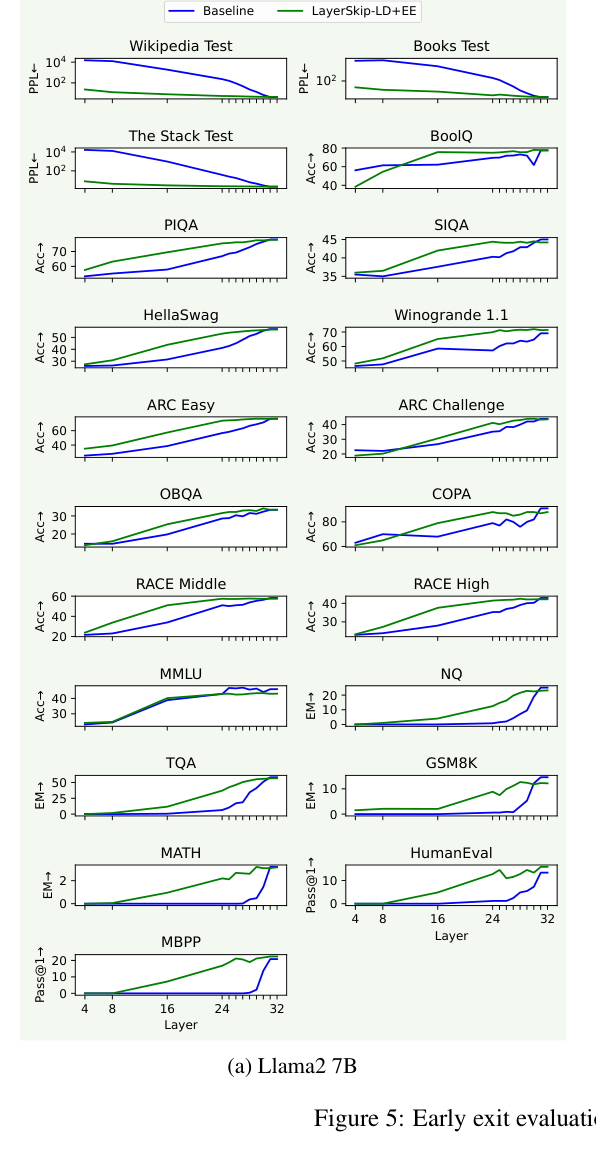
LayerSkip 配方训出的模型(绿线)在各层 exit 时精度大幅高于普通训练。说明训练配方确实有效,浅层已经具备相当强的独立预测能力。
模式二:Self-Speculative Decoding(无损,主要贡献)
这才是论文的核心。Draft 阶段用前 E 层做快速草稿,Verify 阶段用完整 L 层验证,最终输出分布无损等价于完整自回归。
3.1 Draft 阶段:E 层前向,token-by-token
每生成一个 draft token,只跑前 E 层(E < L),然后直接用共享的 LM Head 输出分布:
def draft_phase(context, draft_exit_layer, d, model):
"""
context: 当前已确认的 token 序列
draft_exit_layer: E,草稿模型从这层退出(0-indexed)
d: 最多生成 d 个草稿 token
"""
draft_tokens = []
draft_probs = []
for j in range(d):
# 只跑前 E 层,KV cache 正常积累
hidden = context + draft_tokens
kv_cache = {}
for l in range(draft_exit_layer + 1): # 层 0 到 E
hidden, kv_cache[l] = model.layers[l](hidden, kv_cache.get(l))
# 在第 E 层的 hidden state 上直接用 LM Head
# 这一步有效的关键:训练时 shared early exit loss 保证了浅层 h_E 已对齐词表空间
logits = model.lm_head(hidden[-1]) # 只看最后一个位置
probs = softmax(logits)
draft_token = probs.argmax() # greedy draft
draft_tokens.append(draft_token)
draft_probs.append(probs)
return draft_tokens, draft_probs, kv_cache
整个 Draft 阶段共 d 次前向,每次只过 E 层,总计算量是 d × E 层的 attention。
3.2 Verify 阶段:L 层完整验证,复用 KV cache
这是 LayerSkip SSD 的关键加速来源。Verify 阶段需要完整的 L 层模型来给出无偏的验证结果,但:
- 前 E 层的 KV cache 已经在 Draft 阶段算好了,不需要重算
- 只需要额外运行层 E+1 到层 L(共 L-E 层)
- d 个 draft token 位置可以并行处理(一次 batch forward),不需要串行
def verify_phase(context, draft_tokens, draft_kv_cache,
draft_exit_layer, model):
"""
用完整 L 层模型并行验证 d 个 draft token
"""
full_sequence = context + draft_tokens # [context_len + d] 个 token
# 从层 draft_exit_layer+1 开始继续算,复用前 E 层的 KV cache
# 对所有 d+1 个位置(context 最后一个 + d 个 draft)并行处理
hidden = draft_kv_cache[draft_exit_layer] # 取第 E 层的 hidden state
for l in range(draft_exit_layer + 1, len(model.layers)): # 层 E+1 到 L
hidden, _ = model.layers[l](hidden)
verify_logits = model.lm_head(hidden) # [d+1, vocab_size]
# verify_logits[i] 是完整模型对位置 context_len + i 的输出
return verify_logits
为什么 KV cache 可以复用?
Draft 阶段在层 E 做了早退出,前 E 层的 KV cache(attention 用的 key-value 对)是完全正确的——这些层没有跳过,计算是完整的。Verify 阶段运行同一个模型,前 E 层的输出结果是一样的,所以 KV cache 可以直接接续用,不需要重跑这些层。
相比之下,如果用独立草稿模型(标准 Speculative Decoding),Verify 阶段就得从第 0 层重跑目标模型,没有任何复用。这是 Self-SD 相比标准 SD 的固有优势。
如下图,三种方式的计算图对比非常直观:
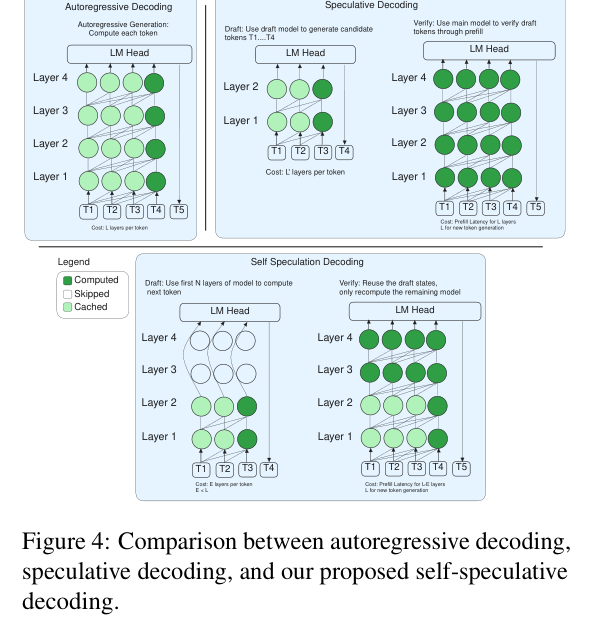
- 自回归(AR):每个 token 跑完整 L 层,串行
- 标准 SD:草稿模型跑 L’ 层,验证模型重跑 L 层,没有复用
- LayerSkip SSD:草稿跑前 E 层,验证从层 E+1 开始继续跑,KV cache 无缝衔接
3.3 接受/拒绝与循环推理
def layerskip_ssd(prompt, model, E, d):
"""
LayerSkip Self-Speculative Decoding 完整推理循环
E: draft exit layer(通常 L/5 到 L/3)
d: speculation length(通常 10-14)
"""
context = prompt
output = []
while not done:
# Draft:d 次浅层前向,每次只过 E 层
draft_tokens, draft_probs, kv_cache = draft_phase(
context, draft_exit_layer=E, d=d, model=model)
# Verify:一次 batch forward,从层 E+1 开始,复用 KV cache
verify_logits = verify_phase(
context, draft_tokens, kv_cache,
draft_exit_layer=E, model=model)
# 接受/拒绝:标准推测解码接受条件
accepted = 0
new_token = None
for j, (d_t, q_t) in enumerate(zip(draft_tokens, draft_probs)):
p_t = verify_logits[j].softmax()
# 接受概率 = min(1, p_full / p_draft)
accept_prob = min(1.0, p_t[d_t] / q_t[d_t])
if random() < accept_prob:
accepted += 1 # 接受,继续检查下一个
else:
# 拒绝:从修正分布 norm(max(0, p - q)) 重采样
correction = sample(norm(max(0, p_t - q_t)))
new_token = correction
break
# 如果全部接受,还要从完整模型多采一个 bonus token
if accepted == len(draft_tokens) and new_token is None:
new_token = sample(verify_logits[accepted].softmax())
output.extend(draft_tokens[:accepted])
if new_token is not None:
output.append(new_token)
context = context + output[-len(context):] # 更新上下文
return output
每轮的效果:
| 接受情况 | 每次 verify 前向产出的 token 数 |
|---|---|
| 全部接受(d 个) | d+1 个(d 个 draft + 1 个 bonus) |
| 接受 k 个后拒绝 | k+1 个(k 个 draft + 1 个修正) |
| 第一个就拒绝 | 1 个(修正 token) |
每次 verify 至少得到 1 个 token,最多得到 d+1 个,比自回归每步只得 1 个好。
两种模式的对比:
| Early Exit(有损) | Self-Speculative(无损) | |
|---|---|---|
| 输出质量 | 低于完整模型 | 完全等价于完整模型 |
| 计算量 | 每 token E 层 | 每轮 d×E + L 层(平均摊下来更少) |
| 适用场景 | 质量不敏感场景 | 需要完整模型质量的场景 |
| KV cache | 只积累 E 层 | Draft 积累 E 层,Verify 复用后补 |
4. 效果怎么样
实验跑在 Llama2 系列上,四种训练场景都测了(从零预训练、continual pretraining、domain finetuning、task finetuning)。
下表是 continual pretraining 配方的主要结果,对比了自回归、Early Exit、Self-Speculative 三种模式,以及 Draft & Verify 作为 baseline:
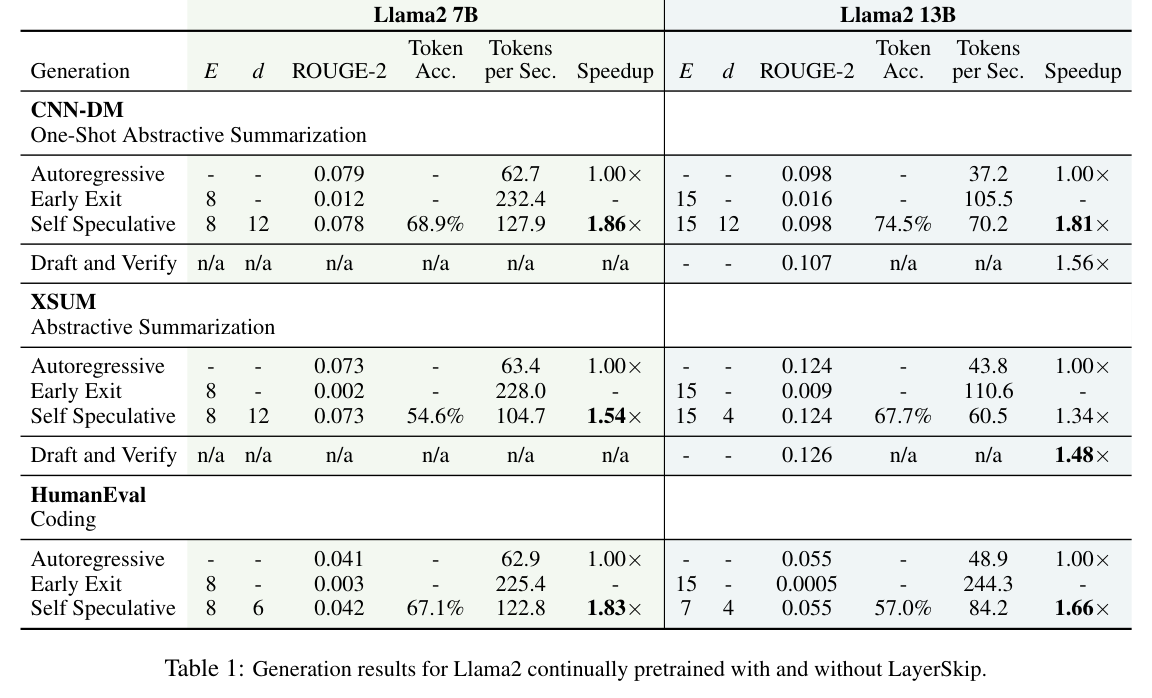
几个数字值得关注:
- Llama2 7B,CNN-DM 摘要:Self-Speculative 到 1.86×,ROUGE-2 从 0.079 降到 0.078,几乎无损
- Llama2 13B,CNN-DM:1.81×,ROUGE-2 完全一致(0.098)
- Llama2 7B,HumanEval 代码:1.83×,pass@1 不降反升(0.041 → 0.042,噪声范围内)
Early Exit 那行速度确实更快(7B 在 CNN-DM 上 232.4 tokens/sec,是自回归的 3.7×),但质量损失明显(ROUGE-2 从 0.079 跌到 0.012)。所以实际用途里 Self-Speculative 更合理,保无损同时拿加速。
参数怎么选(exit layer E 和 speculation length d)?论文给了一张热力图,横轴是 exit layer,纵轴是 speculation length,颜色是 tokens/sec:
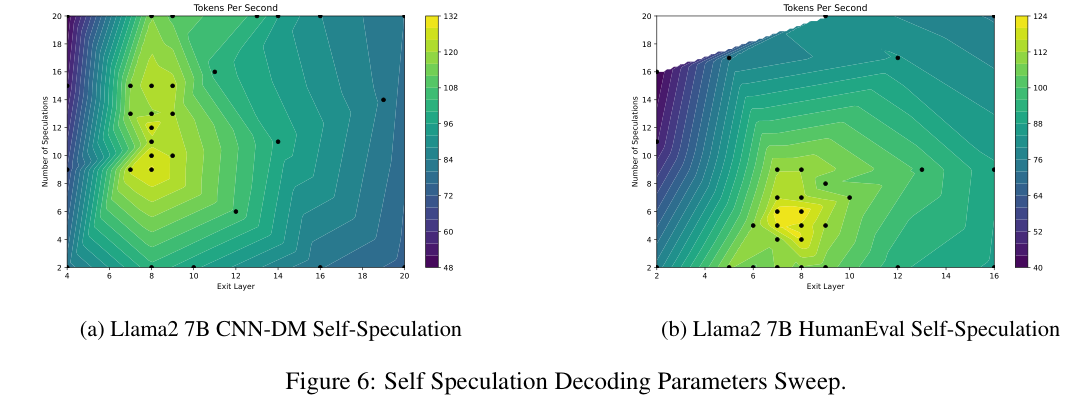
最优点集中在 exit layer ≈ 8,speculation length ≈ 10-14 附近,最优区域很宽,不需要精细调参。
5. 一点个人看法
细思极恐的一件事是:这个训练配方其实挺”便宜”——Layer Dropout 加上一个共享 LM Head,改动非常小,但训出来的模型具备了普通模型不具备的”任意层退出”能力。这说明模型在正常训练中其实有大量”浪费”——后面的层做的很多事情,用更少的层本来也可以做到,只是没有显式地去训。
LayerSkip 的主要限制是它需要重新训练。对于大多数人来说,能用的只有 Meta 官方训好的 Llama 系列,自己重训一个 70B 不现实。所以这套方案虽然效果好,适用范围实际上比较窄——除非你在某个具体任务上做 continual pretraining 或 finetuning,这时候加上 LayerSkip 配方是有意义的。
这个限制后来被 SWIFT 正面解决——不改训练,在推理阶段在线自适应地搜索最优层配置,优化开销只有 0.8%。那篇文章我们后面聊。
如果这篇文章涉及的 LLM 推理效率优化你想系统深入,可以看看我之前出版的《动手学 AutoML:从 NAS 到大语言模型优化实战》,书里有专章讲 LLM 参数高效方法和推理优化,和本文的训练配方设计思路有直接关联。
