长音频转写慢 10 倍,99% 的 Attention 在白做功——MURMUR 如何破解这道难题
长音频转写慢 10 倍,99% 的 Attention 在白做功——MURMUR 如何破解这道难题
1. 前言
你有没有遇到过这种场景:开了一小时的会,散会后想把录音发给模型转成文字,结果等了好几分钟才出来?这个等待时间有点尴尬——短的话直接重听算了,长的话至少还能喝杯咖啡缓一缓。
这篇文章要介绍的 MURMUR,就是来解决这个等待问题的。
先交代背景:最近语音识别(ASR)领域出现了一类新模型,能把 60 分钟的录音一口气处理完,同时输出文字、时间戳、说话人标注,不需要任何外部后处理模块。听起来很美——但代价是推理速度比传统方案慢将近 10 倍。
MURMUR 这篇论文的核心贡献,就是通过分析 KV Cache 里的冗余,把这个巨大的延迟差距大幅压缩,最终在几乎不损失精度的前提下实现了 4.2 倍加速——而且精度还比原来更好了(原因后面说)。
对语音领域不熟悉的同学,先跟着我过一遍必要的背景知识,再来看方案会清晰很多。
2. 科普:ASR 是什么,长音频为什么难
2.1 ASR 基础
ASR(Automatic Speech Recognition,自动语音识别)说白了就是”把声音转成文字”。手机语音输入、会议软件实时字幕、视频平台自动字幕,背后都是 ASR 系统在工作。
现代 ASR 模型大多是 Transformer 结构:把音频先转成一系列特征向量(speech token),然后用 decoder 逐词生成文本。
2.2 长音频的特殊挑战
大部分 ASR 模型有”输入长度限制”。比如大家熟知的 Whisper,最多只能处理 30 秒音频。
那一小时的录音怎么办?经典方案是切片:把录音按时间切成小段,分别转写,再把结果拼接。这叫 chunk-based 方案。
切片方案的问题在于:
- 跨片段上下文丢失:说话人在第 29 秒说了半句,第 31 秒说完,切片边界恰好卡在中间,前后对不上
- 说话人识别困难:录音里可能有 A、B、C 三个人在说话,切片方案需要额外的说话人分离(diarization)模块打标签,每个模块的误差叠加起来,”谁说了什么”这个问题的错误率会高很多
所以识别”说了什么”(WER)还凑合,但识别”谁在什么时间说了什么”(tcpWER)差距就很明显了。
2.3 几个指标的含义
读这篇论文会碰到几个术语,先解释清楚:
- WER(Word Error Rate):单词错误率,衡量”转写内容对不对”,越低越好
- DER(Diarization Error Rate):说话人分离错误率,衡量”说话人识别对不对”
- tcpWER(time-constrained per-speaker WER):把内容准确性和说话人归属同时考虑进去的综合错误率,是最贴近实际场景(会议记录、庭审转录等)的指标,也是这篇论文最核心的优化目标
3. 两种方案的现实困境
现在语音识别领域有两条路线在竞争,各有缺陷:
路线 A:WhisperX(chunk-based)
- 把音频切成 30 秒片段,批量并行处理
- 再跑说话人分离、时间戳对齐等独立模块
- 优点:快;缺点:跨片段上下文断掉,tcpWER 很高
路线 B:VibeVoice(长上下文单次推理)
- 一次性把几十分钟音频全塞进去,自回归输出文字+时间戳+说话人
- 优点:精度好;缺点:慢 10 倍,而且偶尔会触发”重复循环”失败(repetition loop),整段录音直接报废
实测数据(AMI-IHM 数据集,8.7 小时会议录音):
| 方案 | WER | tcpWER | 推理时间 |
|---|---|---|---|
| WhisperX | 22.5% | 35.5% | 38.8s |
| VibeVoice 单次完整推理 | 19.2% | 25.7%* | 370.7s |
* 单次推理有 2/14 段录音因重复循环失败,这两段被排除在外;如果算上失败的,实际 tcpWER 更难看。
tcpWER 上 VibeVoice 比 WhisperX 好 10 个百分点,但慢了将近 10 倍——这就是 MURMUR 要破解的核心矛盾。
如下图直观对比了三种推理策略的差异:
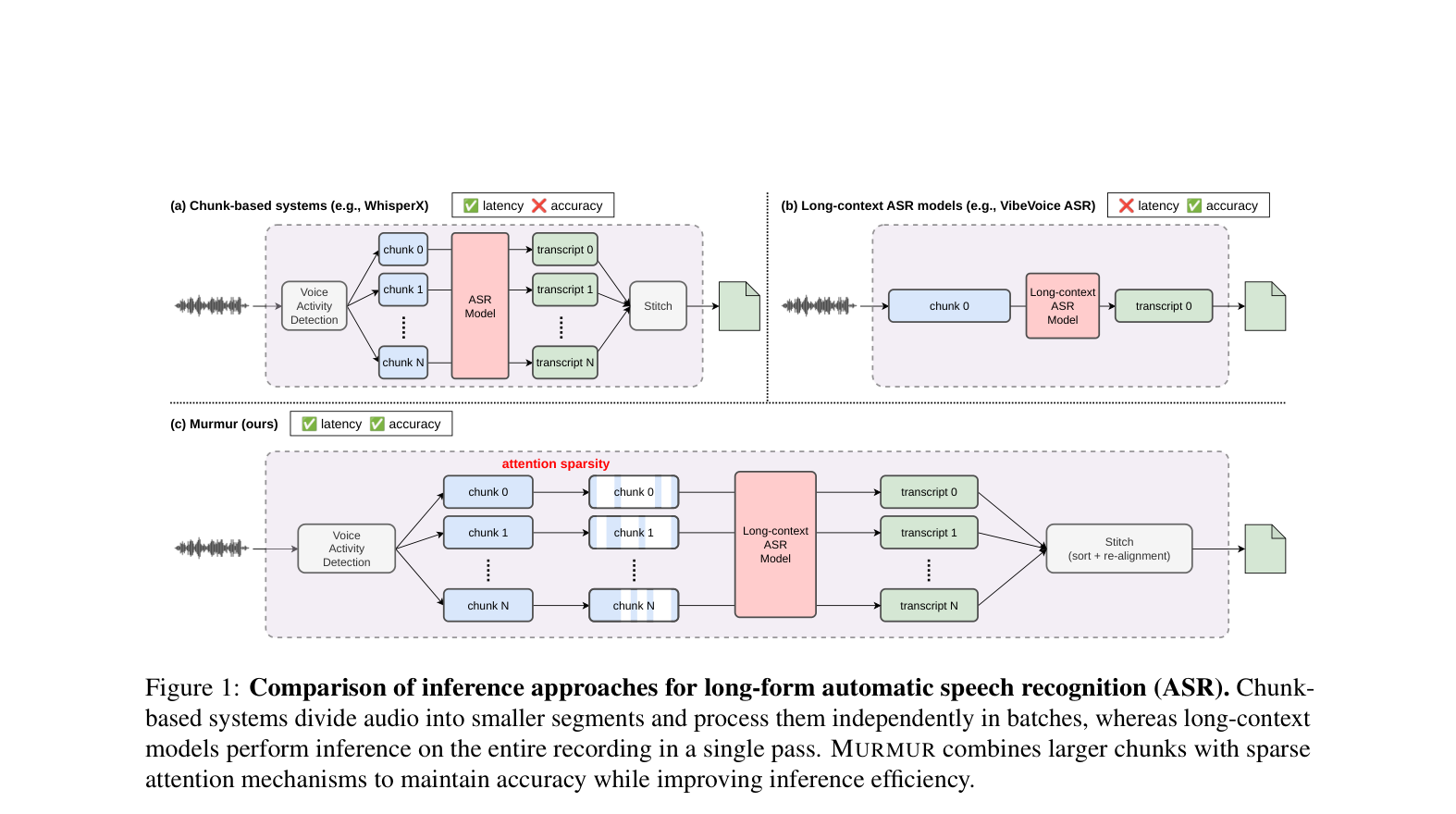
4. 科普:KV Cache 是什么,为什么是速度瓶颈
这是理解后续优化方案的关键。LLM 领域的同学应该对 KV Cache 有印象,但语音领域的同学可能相对陌生,这里展开讲一下。
4.1 自回归解码的问题
现代 ASR 模型生成文字时是逐词(token)输出的:生成第 1 个词,把这个词加入上下文,再预测第 2 个词……以此类推,这叫自回归解码(autoregressive decoding)。
每生成一个新 token,模型都要通过 Attention 机制”回头看”之前所有 token 的信息。Attention 的计算方式是:新 token 的 Query 向量与所有历史 token 的 Key 向量做点积,得到注意力权重,再用这个权重对所有 Value 向量加权求和。
如果每一步都重新计算所有历史 token 的 Key 和 Value,代价会随序列长度平方增长——太贵了。
4.2 KV Cache 的作用
解决方案是:把每个 token 的 Key(K)和 Value(V)向量缓存起来,新 token 生成时直接复用,不重复计算。这就是 KV Cache。
代价是内存占用随序列长度线性增长,而且每个解码步骤都要读取整个 KV Cache 参与 Attention 计算——序列越长,每步的 Attention 计算量越大。
4.3 为什么长音频的 KV Cache 特别大
ASR 模型的 KV Cache 里有两类 token:
Speech token(音频 token):音频被编码成特征向量后,1 秒音频约对应 7.5 个 token。300 秒的音频 ≈ 2,250 个 speech token,这些 token 在推理开始时全部进入 KV Cache,之后每一步解码都要跟它们做 Attention,是计算量的大头。
Output token(文本 token):解码时逐步生成的文字。300 秒音频大约生成 ~2,700 个 output token,随着解码进行不断增长。
论文做了 profile 分析,发现:
- 解码阶段占总推理时间的 95.3%
- Attention 操作占总推理时间的 74.6%
也就是说,不优化 Attention / KV Cache,其他什么都白优化。
5. MURMUR 的核心发现:Attention 大部分是稀疏的
光知道 Attention 是瓶颈还不够,MURMUR 的关键在于找到了可以安全丢弃大部分 KV Cache 的依据。
5.1 Speech token 的对角线稀疏模式
如下图,对比 30 秒和 300 秒两种 chunk 下某一层某一头的 Attention 权重:
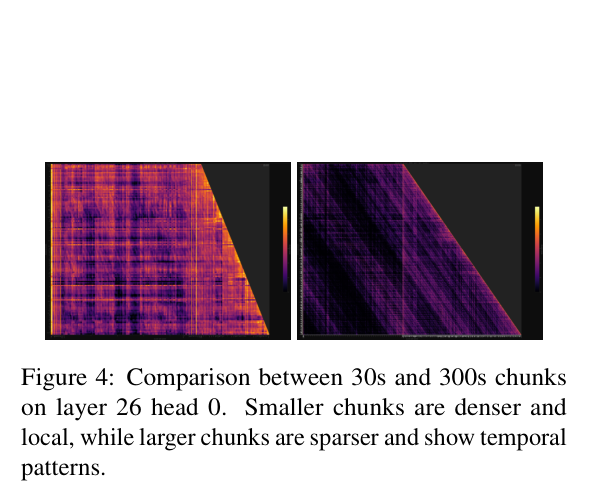
30 秒 chunk 时,speech token 的注意力权重分布比较均匀;300 秒 chunk 时,出现了明显的对角线带状稀疏模式——解码进行到哪里(横轴是解码步数,纵轴是 speech token 位置),有效 Attention 就集中在对应的音频位置附近,前面已经处理过的大段音频基本用不到了。
量化结论:在 28 层 Transformer 里的 24 层,只需要保留不到 25% 的 speech token,就能覆盖 99% 的总 Attention 权重。
直觉上也很合理:模型在转写”第 200 秒说了什么”时,不太需要回头看”第 10 秒的音频内容”——这些信息在当时已经转写完了。
下图展示了不同层的 Attention token 构成比例:
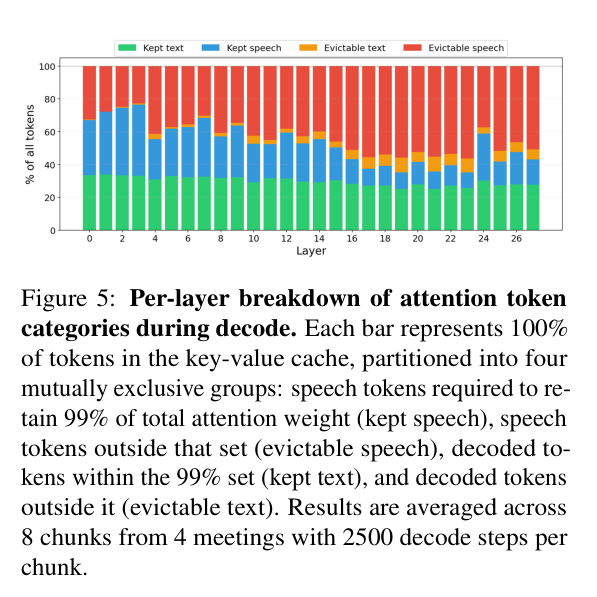
5.2 Output token 的两个规律
Output token 的 Attention 呈现出不同的特征:
-
Recency bias(近端偏向):大部分注意力权重集中在最近生成的 token 上,远处的历史文本权重极低
-
Attention sink(注意力汇聚):序列最开始的几个 token 会吸收大量权重——哪怕它们的内容(比如特殊开始符)对当前生成毫无意义。这个现象在 LLM 推理优化领域有大量记录,本质上是模型把”不确定该注意什么”的权重都堆到了第一个 token 上。
6. MURMUR 的两级优化方案
基于上述发现,MURMUR 构建了一个两级推理系统:第一级优化 chunk 大小选择,第二级优化 chunk 内部的 KV Cache。
6.1 第一级:把 chunk 大小当超参数
之前大家默认”chunk-based 就是固定 30 秒,长上下文就是一口气全推”,非此即彼。MURMUR 说:其实 30 秒到 3600 秒之间的中间地带才是最优解——chunk 大小是一个可以调的超参数。
实验测了不同 chunk 大小下精度和延迟的变化:
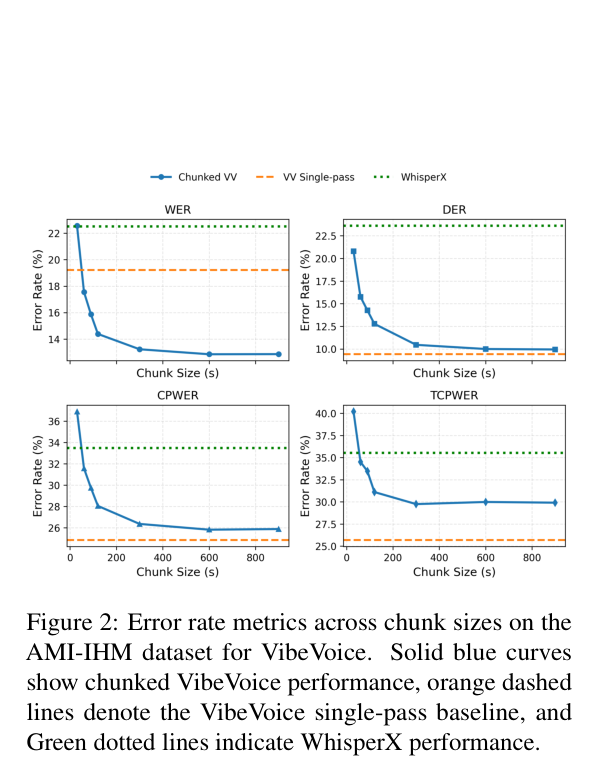
核心发现:精度随 chunk 大小增加而提升,但大约到 300 秒就基本饱和,之后再增加 chunk 大小边际收益极小,反而推理时间继续增加。
对于相对干净的音频(TED 演讲、财报电话),饱和点更早;对于嘈杂的会议录音(多人说话、混响),从更长的上下文中受益更明显,但也就到 300 秒为止。
所以 MURMUR 选择 300 秒作为 chunk 上限。这一步本身就把推理时间从 370.7 秒压缩到 100.8 秒,实现 3.68 倍加速,而且精度不降反升(因为避免了单次推理的失败案例)。
6.2 第二级:KV Cache 驱逐(token eviction)
确定 chunk 大小之后,MURMUR 进一步对 chunk 内部的 KV Cache 动刀,分别针对两类 token 设计不同的驱逐策略。
Output token 驱逐
思路直接:只保留”attention sink token”(序列最前面的少量 token)+ 最近的 w 个 token,其余全部驱逐。
具体参数:sink token 数 = 4,窗口大小 w = 1024。
这套方案叫 StreamingLLM 风格,在 LLM 推理优化里已经是成熟方案了,直接拿来用。
Speech token 驱逐
Speech token 不能直接套 StreamingLLM,因为它的有效 Attention 区域不是固定在最近端,而是随着解码进度向后平移的(就是那个对角线)。
MURMUR 设计了一个带延迟的平移窗口:

逻辑如下:
- 解码开始的前 d 步,窗口保持在起点(让模型充分看到音频开头的上下文信息)
- 之后每解码一步,窗口向后移动一格,跟上解码进度
参数:延迟 d = 512,窗口大小 w = 1024–1538。
关键点:Speech token 的可驱逐区域不是连续的位置块,而是散落在各处——这是论文里特别强调的,所以简单的头部/尾部截断根本不够精细,必须用这个精确追踪的滑动窗口。
7. 实验结果
7.1 主要结果(AMI-IHM 数据集)
| 系统 | tcpWER | 推理时间 | 加速比 |
|---|---|---|---|
| VibeVoice 单次推理(有失败排除) | 25.7% | 370.7s | 1× |
| WhisperX | 35.5% | 38.8s | 9.55× |
| MURMUR(无驱逐,300s chunk) | 24.9% | 100.8s | 3.68× |
| MURMUR + Speech token eviction | 25.3% | 88.4s | 4.20× |
| MURMUR + 两种 eviction 同时 | 25.7% | 96.1s | 3.85× |
几个值得关注的细节:
MURMUR 无驱逐版本精度甚至超过了 VibeVoice 单次推理(tcpWER 24.9% vs 25.7%)。原因是单次推理偶尔会触发重复循环失败,整段录音精度归零;chunk 方案把失败范围限制在单个 chunk 内,不会”一错全错”。
两种驱逐同时用反而比只用 Speech eviction 慢(3.85× vs 4.20×)。两套策略并行管理的额外 overhead 抵消了节省的计算量——所以实际部署时 Speech eviction 单独用效果更好。
Speech eviction 是主要提速来源。因为 speech token 数量固定(约 2250 个)且每步都要参与 Attention,而 output token 从 0 开始逐步增长,初期贡献有限。
7.2 跨数据集泛化性
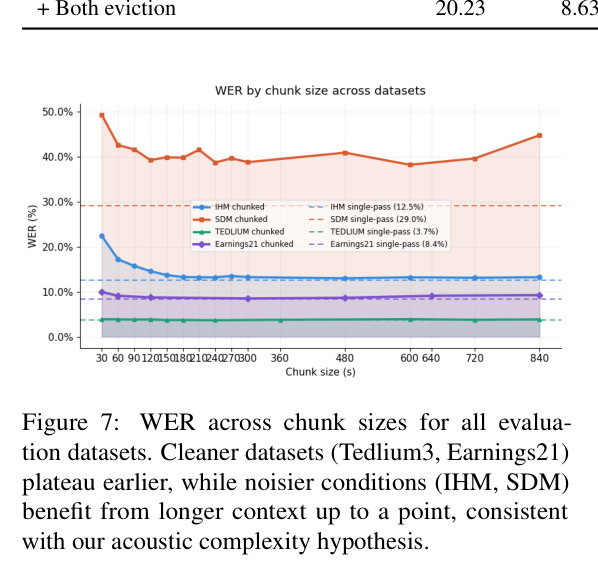
在所有测试数据集上,MURMUR 均保持了接近 VibeVoice 单次推理的精度,同时大幅优于 WhisperX。干净音频(Earnings21、Tedlium3)在更小的 chunk 大小下就饱和,嘈杂会议录音(AMI-SDM)从更长的 chunk 中收益更多。
8. 总结
MURMUR 解决了一个实际场景里非常痛的问题:长上下文 ASR 模型精度好但太慢,chunk-based 方案快但精度差,两个极端之间几乎没有选择。
论文的核心 insight 是:chunk 大小不是 30 秒或全程的二选一,300 秒是一个甜点;speech token 的 KV Cache 存在对角线稀疏性,可以精确追踪并安全驱逐大部分历史 token。
两个观察合起来,推理时间从 370s 压缩到 88s,精度不降反升,最终实现了 4.2 倍加速。
KV Cache 稀疏性在 LLM 推理优化领域早有研究,但把它迁移到语音场景、识别出 speech token 独特的时序对齐特性、设计对应的延迟平移窗口——这个落地本身有价值。
当然也有局限:论文只测了英语,高度重叠说话(鸡尾酒会场景)下的鲁棒性没有讨论,不同语言的 speech token 密度可能也有差异。这些都是有趣的后续方向。
代码已开源:github.com/uw-syfi/Murmur(CC BY 4.0)
欢迎评论区交流,有问题或者说错的地方欢迎指出。
这篇文章涉及的 KV Cache 稀疏性、推理加速这套方法论,在 LLM 效率优化里已经是主流方向。如果想系统了解从 NAS 到 LLM 推理优化的完整技术脉络,可以看看我们团队出版的《动手学 AutoML:从 NAS 到大语言模型优化实战》,书里有专章讲 LLM 推理效率,和本文的技术背景直接相关。
