2026 | dLLM-ASR 让语音识别推理快 4.44 倍,还不掉精度
2026 | dLLM-ASR 让语音识别推理快 4.44 倍,还不掉精度
原文:dLLM-ASR: A Faster Diffusion LLM-based Framework for Speech Recognition
1. 前言
你有没有想过,当你对着手机说话,语音转文字的时候,背后到底在跑什么?
早几年是端到端的声学模型(CTC、RNN-T 这类,直接从音频帧映射到文字,不依赖 LLM),后来 Whisper 出来,直接把语音识别的天花板抬了一截。再后来,大家发现把 Whisper 当编码器、接一个 LLM 来解码,精度还能再往上走——毕竟 LLM 有大量文本知识,能更好地处理同音词、专有名词这些边缘情况。
但 LLM 有个老大难问题:自回归解码,token 一个一个吐。序列越长,等的时间越久,延迟和序列长度成线性关系 O(N)。对 ASR 来说,一句话十几二十个字,这个延迟在实时性要求高的场景(语音助手、实时字幕)就很要命。
最近比较火的 Diffusion LLM(dLLM) 理论上能解这个问题——它并行生成整个序列,推理复杂度降到 O(K),K 是去噪步数,通常远小于序列长度 N。
但直接把 dLLM 搬来做 ASR,又踩了一堆新坑。这篇 dLLM-ASR 就是来填这些坑的,最终在 LibriSpeech(英语有声书语音识别标准 benchmark)等多个数据集上实现了 4.44× 推理加速,同时 WER(Word Error Rate,词错误率,越低越好)比自回归 LLM-ASR 还要低一点点。
2. 两个前置背景
2.1 LLM-based ASR 长什么样
现在主流的 LLM-based ASR 架构基本是三段式:
语音编码器(Speech Encoder)→ 对齐适配器(Adapter/Projector)→ LLM 解码器
以 Whisper-LLaMA3 为例:
- Whisper-large-v3 做编码器,把音频转成声学特征序列(25 Hz 帧率)
- 一个 1D 卷积(stride=2,降采样到 12.5 Hz)+ 线性层,把声学特征维度从 1280 映射到 LLM 的 4096
- LLaMA3-8B 自回归地根据声学特征生成文字 token
精度确实好,但推理慢——8B 参数的 LLM,一个词一个词地生成,RTF(Real-Time Factor,实时因子)在 LibriSpeech clean 上是 0.317。RTF = 处理耗时 / 音频时长,也就是处理 1 秒音频需要 0.317 秒。RTF < 1 才算快于实时,越小越好;RTF > 1 意味着系统处理速度跟不上说话速度,完全不能用于实时场景。
2.2 Diffusion LLM 怎么工作
dLLM(以 LLaDA 为代表)用的是 masked diffusion,思路和图像扩散模型有点像,但作用在离散 token 空间上。
前向过程(加噪):把目标序列 x₀ 里的 token,以概率 t 替换成 [MASK],得到 xₜ。t 越大,mask 越多,t=1 时全部被 mask。
训练目标:让模型学会从 xₜ 还原 x₀,loss 是:
\[\mathcal{L} = -\mathbb{E}_{t,x_0,x_t}\left[\frac{1}{t}\sum_{i=1}^{L}\mathbb{I}(x_t^i=[\mathrm{M}])\log p_\theta(x_0^i|x_t, A)\right]\]其中 A 是条件(这里是声学特征),1/t 是归一化系数,平衡不同 mask 数量下的梯度。训练时以 α=0.2 的概率对全序列做完全 mask,增强鲁棒性。
推理过程:从全 mask 序列出发,迭代去噪 K 步,每步模型并行预测所有被 mask 的位置,置信度高的先 unmask,低的继续 mask 下一轮。因为每步都是并行预测,比自回归的逐 token 生成快很多。
3. 直接用 dLLM 做 ASR,三个根本矛盾
把 LLaDA 接上 Whisper 做 ASR(论文叫 Whisper-LLaDA baseline),实测下来 RTF 高达 1.678——比自回归的 Whisper-LLaMA3(0.317)慢了 5 倍多。dLLM 号称能并行生成,怎么反而更慢了?
根本原因是:dLLM 是为开放式文本生成设计的,但 ASR 是强约束的声学转录任务,两者之间存在三个根本性的不匹配:
矛盾一:从纯噪声开始去噪
回顾一下 dLLM 的推理流程:从全 mask 序列出发,每一步模型预测所有被 mask 的位置,置信度高的先 unmask,剩下的继续 mask 到下一轮,迭代 K 步直到全部确定。
问题在于:这个设计是为了”凭空生成文字”的场景设计的——输入是一个主题或 prompt,输出是模型自由发挥的内容,所以从全 mask 出发是合理的。但 ASR 不是自由生成,音频本身已经给了你大量信息:这句话大概说了多少个字、哪个位置是元音、停顿在哪里……这些声学特征都隐含着对转录结果的强烈约束。从全 mask 零起点去噪,等于把这些先验全部忽略,模型需要用更多步骤才能从噪声中”摸索”出答案。
矛盾二:序列长度固定
dLLM 在推理时需要一开始就确定序列长度——因为 transformer 的 self-attention 要在整个序列上做矩阵运算,序列长度是张量维度的一部分,必须提前定好。这在文本生成里不是大问题,因为你可以根据任务经验预设一个合理长度。
但 ASR 不同,你根本不知道这段音频会转录出多少个字。5 秒的音频,快说的人可能说了 30 个字,慢的可能只有 10 个字。实际操作只能预设一个”够大”的上限(比如 100 个位置),然后短句子用大量 padding token 补齐。这些 padding 位置在每一步去噪中同样占用 attention 计算,和真正的文字 token 一起参与矩阵运算。句子越短,浪费的比例越高。
矛盾三:去噪步骤固定,不分难易
dLLM 的去噪步数 K 是一个固定超参数,所有 token 无论难易,都要经历同样多的去噪轮次。
但实际上不同位置的 token 难度天差地别。比如”人工智能”这个词,在大多数语音上下文里几乎唯一确定,第一步去噪置信度就能达到 99%;而”吃”和”七”在普通话里同音,到底是哪个字,可能需要结合好几个词的上下文才能确定,置信度很晚才会收敛。但 dLLM 不管这些,K 步就是 K 步,”吃/七”要跑满,”人工智能”也要跑满。早就确定的 token 在后续轮次里只是在做无用功,但计算量实实在在地消耗在那里。
4. dLLM-ASR:四个补丁解决三个矛盾
如下图是 dLLM-ASR 的整体架构,左边是模型结构和训练过程,右边展示了推理过程从 baseline 到完整方案的演进:
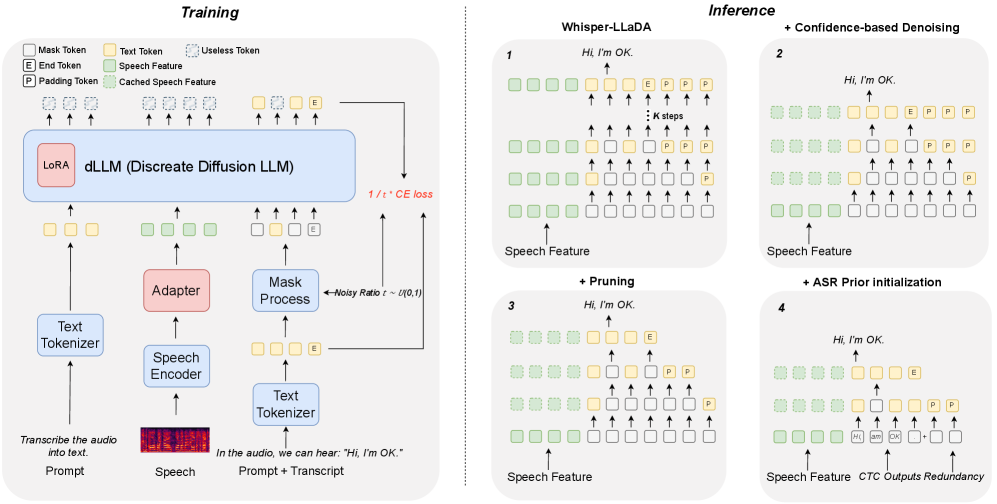
方法部分有四个核心组件,对应解决上面的三个矛盾:
4.1 ASR Prior 初始化
解决矛盾一:不从全 mask 出发,用 CTC 先验初始化去噪起点。
在冻结的 Whisper 编码器输出上加一个轻量的 CTC 分支(Connectionist Temporal Classification,一种经典的非自回归语音识别解码方式,能直接并行输出每帧对应的字符概率,速度很快但精度不如 LLM)——1D 下采样卷积 + 分类头,生成一个初始的 ASR 假设序列。推理时:
- 先跑 CTC 得到初始文字序列(计算量可忽略不计)
- 把这个序列作为 dLLM 去噪的起始状态,而不是全 mask
这样做两个好处:一是去噪起点已经”有意义”,离最终结果更近,收敛更快;二是 CTC 输出的长度可以直接作为目标序列长度的参考,解决了长度固定的问题。
4.2 Length-Adaptive Pruning
解决矛盾二:动态裁掉序列里的冗余 token。
在第一步去噪后,找到置信度高的 padding/EOS 位置并裁掉。之后每一步去噪,已经 unmask 且置信度稳定的位置也可以从序列里移除。序列长度随去噪进行自适应收缩,每步的有效计算量不断降低。
4.3 Confidence-Based Denoising
解决矛盾三:置信度超过阈值 τ 的 token 提前退出去噪循环。
每一步去噪后,置信度 > τ(默认 0.9)的 token 直接”冻结”,后续步骤不再更新它们。如果某步没有 token 超过 τ,则选当前置信度最高的一个 token 强制 unmask(保证每步都有进展,不陷入死循环)。
这里有一个关键点容易被忽略:这个机制必须配合 ASR Prior 才能正常工作。如果初始状态是全 mask,模型在第一步对所有位置都高度不确定,但有些位置可能”凑巧”得了个高置信度——这个预测其实是噪声,并不是真正收敛了。一旦被冻结,错误就无法纠正。消融实验里,把置信度截断单独加到 Whisper-LLaDA baseline 上,WER 从 5.22 直接跳到 5.98,就是这个原因。而有了 ASR Prior 提供的有意义的初始状态之后,高置信度才真正意味着”这个位置已经确定了”,早退出才有效。
τ 怎么选?如下图是消融实验:
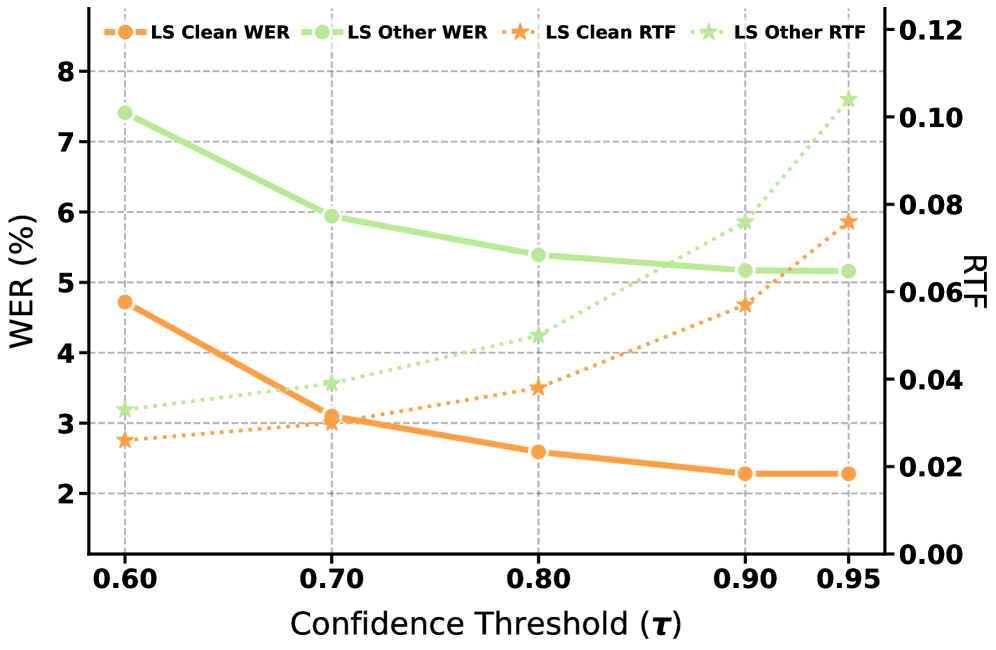
τ=0.9 和 τ=0.95 的 WER 差异可忽略不计,但 τ=0.9 的 RTF 更低,所以取 0.9 作为默认值。τ 太小(如 0.6)会过早冻结 token,WER 上升明显。
4.4 Speech KV Cache
这个是附加的工程优化,但对速度贡献不小。
dLLM 每一步去噪都要把声学特征 A 过一遍 attention,重新计算 Key 和 Value。但声学特征在整个推理过程中压根没有变——第一步算完的 KV cache 完全可以复用到后续所有步骤,不用重算。
这个优化的效果取决于去噪步数 K:K 越大,节省越多,相当于把声学特征的 attention 计算量从 K 次压缩到 1 次。论文验证了加上这个优化后精度几乎无损,属于免费的速度提升。这个思路也不局限于 ASR——任何条件在推理过程中保持不变的 dLLM 场景(比如图文生成时的图像条件、结构化生成时的 schema 条件),都可以直接套用。
用代码把四个组件串起来
论文暂未开源代码,但结构描述足够清晰,下面用简化代码把整个系统还原一遍,把上面讲的每个组件对号入座。
模型结构:Whisper 编码器(冻结)+ 适配器(含 CTC 分支)+ LLaDA 解码器。
import torch
import torch.nn as nn
from transformers import WhisperModel, AutoModelForMaskedLM
class SpeechAdapter(nn.Module):
def __init__(self, whisper_dim=1280, llm_dim=4096):
super().__init__()
self.conv = nn.Conv1d(whisper_dim, whisper_dim, kernel_size=3, stride=2, padding=1)
self.proj = nn.Linear(whisper_dim, llm_dim)
def forward(self, x):
x = self.conv(x.transpose(1, 2)).transpose(1, 2)
return self.proj(x) # [B, T/2, D_llm]
class CTCBranch(nn.Module):
"""ASR Prior 的来源:轻量 CTC 头,直接接在冻结的 Whisper 输出上"""
def __init__(self, whisper_dim=1280, vocab_size=50257):
super().__init__()
self.conv = nn.Conv1d(whisper_dim, whisper_dim, kernel_size=3, stride=2, padding=1)
self.head = nn.Linear(whisper_dim, vocab_size)
def forward(self, x):
x = self.conv(x.transpose(1, 2)).transpose(1, 2)
return self.head(x) # [B, T/2, vocab_size]
class dLLMASR(nn.Module):
def __init__(self):
super().__init__()
self.encoder = WhisperModel.from_pretrained("openai/whisper-large-v3").encoder
self.adapter = SpeechAdapter()
self.ctc = CTCBranch()
self.dllm = AutoModelForMaskedLM.from_pretrained("GSAI-ML/LLaDA-8B-Instruct")
for p in self.encoder.parameters():
p.requires_grad = False
def encode_speech(self, waveform):
acoustic = self.encoder(waveform).last_hidden_state # [B, T, 1280]
return self.adapter(acoustic), self.ctc(acoustic) # speech_features, ctc_logits
训练:Stage 1 只练 Adapter,Stage 2 加入 LoRA(r=16)联合微调;masked diffusion loss + CTC 辅助 loss。
def train_step(model, waveform, transcript_ids):
speech_features, ctc_logits = model.encode_speech(waveform)
B, L = transcript_ids.shape
t = torch.rand(B)
t = torch.where(torch.rand(B) < 0.2, torch.ones(B), t) # 20% 概率全 mask
mask = torch.rand(B, L) < t.unsqueeze(1)
noisy_ids = transcript_ids.masked_fill(mask, MASK_ID)
logits = model.dllm(
input_ids=noisy_ids,
encoder_hidden_states=speech_features,
).logits
# 只在 mask 位置算 loss,1/t 归一化(对应 §2.2 的 loss 公式)
loss = -(logits.log_softmax(-1)
.gather(-1, transcript_ids.unsqueeze(-1)).squeeze(-1)
* mask).sum(-1) / t
ctc_loss = nn.CTCLoss()(ctc_logits.log_softmax(-1).transpose(0, 1), transcript_ids, ...)
return loss.mean() + 0.1 * ctc_loss
推理:四个组件按顺序登场——CTC Prior → 第一步建 KV Cache(+ Confidence Freeze + Length Pruning)→ 后续步复用 KV Cache。
@torch.no_grad()
def inference(model, waveform, num_steps=20, tau=0.9):
speech_features, ctc_logits = model.encode_speech(waveform)
# [ASR Prior] CTC greedy decode 作为去噪起点,而不是全 mask
ctc_pred = ctc_collapse(ctc_logits.argmax(-1)) # 合并重复、去 blank
x = ctc_pred.clone()
# [Speech KV Cache] 第一步去噪,同时缓存声学特征的 KV
logits, kv_cache = model.dllm(
input_ids=x, encoder_hidden_states=speech_features,
use_cache=True, return_speech_cache=True,
)
confidence, tokens = logits.softmax(-1).max(-1)
# [Confidence-Based Denoising] 置信度 > τ 的位置直接冻结
frozen = confidence > tau
x[frozen] = tokens[frozen]
# [Length-Adaptive Pruning] 裁掉已确定的 EOS/padding
active = ~((tokens == EOS_ID) & frozen)
for _ in range(1, num_steps):
if not (~frozen & active).any():
break # 全部确定,提前退出
# 复用 speech KV cache,声学 attention 只算一次
logits = model.dllm(input_ids=x[:, active], speech_kv_cache=kv_cache)
confidence[:, active], tokens[:, active] = logits.softmax(-1).max(-1)
newly_frozen = (confidence > tau) & ~frozen & active
if not newly_frozen.any():
# 没有超阈值的,强制冻结置信度最高的一个
best = (confidence * (~frozen & active).float()).argmax(-1)
newly_frozen.scatter_(1, best.unsqueeze(1), True)
x[newly_frozen] = tokens[newly_frozen]
frozen |= newly_frozen
active &= ~((x == EOS_ID) & frozen) # 动态收缩序列
return x
整个推理流程用一句话概括:CTC 给方向,dLLM 做精修,置信度高的位置提前下车,声学 KV 只算一次。
5. 实验
5.1 实验设置
数据集:LibriSpeech(LS)clean/other、CommonVoice(CV)、VoxPopuli,覆盖朗读语音、口语、多语言场景。
Baseline 对比:
- Whisper-LLaMA3-8B(自回归 LLM-ASR,主要对比对象)
- Whisper-Qwen3-8B(另一个自回归系统)
- Whisper-LLaDA(直接组合,不加任何优化)
评估指标:WER 和 RTF(前文已介绍),两个都是越低越好。
5.2 主要结果
| 模型 | 参数量 | LS Clean WER | LS Other WER | CV WER | VoxPopuli WER | 平均 WER | 平均 RTF |
|---|---|---|---|---|---|---|---|
| Whisper-LLaMA3 | 8.03B | 2.15 | 5.58 | 8.55 | 9.89 | 6.54 | 0.280 |
| Whisper-Qwen3 | 8.19B | 2.72 | 6.62 | 9.18 | 10.06 | 7.15 | 0.389 |
| Whisper-LLaDA | 8.02B | 2.34 | 5.22 | 8.80 | 9.68 | 6.51 | 1.736 |
| dLLM-ASR | 8.02B | 2.28 | 5.17 | 8.36 | 9.56 | 6.34 | 0.063 |
几个关键数字:
- vs Whisper-LLaMA3:WER 从 6.54 降到 6.34(小幅提升),RTF 从 0.280 降到 0.063,快 4.44×
- vs Whisper-Qwen3:快 6.17×,WER 同样更好
- vs Whisper-LLaDA(不加优化的 dLLM):快 27.6×,同时 WER 也更低
值得注意:dLLM-ASR 在四个数据集上 WER 均略优于或持平于自回归系统,并不是靠牺牲精度换速度。RTF=0.063 意味着处理 1 秒音频只需 0.063 秒,远快于实时,有实际部署价值。
5.3 消融实验
| 配置 | LS Clean WER | LS Clean RTF | LS Other WER | LS Other RTF |
|---|---|---|---|---|
| dLLM-ASR(完整) | 2.28 | 0.057 | 5.17 | 0.076 |
| 去掉 ASR Prior | 2.29 | 0.069 | 5.20 | 0.084 |
| 去掉 Length Pruning | 2.27 | 0.071 | 5.13 | 0.089 |
| 去掉 Chat-Style Prompt | 2.87 | 0.056 | 5.76 | 0.076 |
| Whisper-LLaDA baseline | 2.34 | 1.678 | 5.22 | 1.892 |
| 只加 Confidence-Based Denoising | 2.98 | 0.077 | 5.98 | 0.108 |
几个有意思的发现:
ASR Prior 和 Length Pruning 主要贡献速度,对 WER 影响微小。去掉 ASR Prior,RTF 从 0.057 涨到 0.069(慢了约 20%);去掉 Length Pruning,RTF 从 0.057 涨到 0.071(慢了约 25%)。两者对 WER 几乎没影响。
Chat-Style Prompt 对精度最关键。去掉对话格式的 prompt,WER 跳了 0.59(clean)和 0.59(other),这说明 dLLM 的指令跟随能力对 ASR 任务非常重要,没有 chat prompt 模型就退化回普通续写,语义理解变差。
各组件必须协同,不能单独用。只把 Confidence-Based Denoising 加到 Whisper-LLaDA 上,RTF 确实从 1.678 降到 0.077,但 WER 从 5.22 飙升到 5.98——孤立地用置信度截断会过早冻结错误的 token,精度损失无法接受。完整方案里 ASR Prior 提供了正确的初始化,才让置信度截断有意义。
6. 讨论
思路很清晰,三个矛盾对应四个解法,逻辑链完整。几个地方需要进一步讨论:
1. CTC Prior 在噪声环境下的鲁棒性
CTC 本身在嘈杂环境(噪声、口音)下 WER 就会比较高,用它初始化去噪起点,噪声场景里会不会把 CTC 的错误带入 dLLM 的去噪过程?LibriSpeech 相对干净,CommonVoice 和 VoxPopuli 略复杂,但论文没有专门分析这个问题。
2. τ 的跨领域泛化
τ=0.9 在 LibriSpeech 上是最优的,但换到医疗、法律等专业词汇密集的领域,模型的置信度分布可能发生变化,这个值需不需要重新调?没有看到相关实验。
3. 流式 ASR 的兼容性问题
这篇文章结尾提到未来工作是”扩展到流式 ASR”。这个问题确实不简单:masked diffusion 的并行去噪天然是”等全句到齐了再处理”,流式场景需要来一帧处理一帧。怎么把这个 prior-guided adaptive denoising 改造成增量式,不是一句话能解决的问题,值得单独开一篇工作来做。
欢迎评论区交流,有不同看法尽管指出来。
如果这篇文章涉及的 LLM 推理加速思路让你感兴趣,可以看看我之前出版的《动手学 AutoML:从 NAS 到大语言模型优化实战》,书里有专章介绍 LLM 推理效率优化和参数高效微调,和本文讨论的加速方向有些关联。
