SpecASR:ASR 专属 Speculative Decoding,让 LLM 语音识别快 3.79 倍
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

SpecASR:ASR 专属 Speculative Decoding,让 LLM 语音识别快 3.79 倍
原文:SpecASR: Accelerating LLM-based Automatic Speech Recognition via Speculative Decoding
1. 前言
你有没有用过那些”基于大模型的语音识别”产品?识别准是真的准,但就是有一种说不清的”顿挫感”。
这背后的原因其实很简单:LLM decoder 的 autoregressive decoding 是逐 token 生成的,用在 ASR 上就意味着每说一句话,模型要一个字一个字地”想”出来。
像 Seed-ASR 的 LLM decoder 参数量超过 10B,Speech-Llama 是 7B,BESTOW 也有 1.1B。相比之下,audio encoder 通常不到 1B,有的甚至不到 100M。问题显而易见:计算瓶颈全卡在 LLM decoder 上。
Speculative Decoding(投机解码)是目前公认的解决 LLM 推理延迟的有效方案之一。核心思路是:用一个小模型(draft model)先”猜”几个 token,再让大模型(target model)并行验证,猜对了就批量接受,猜错了回退重生成。
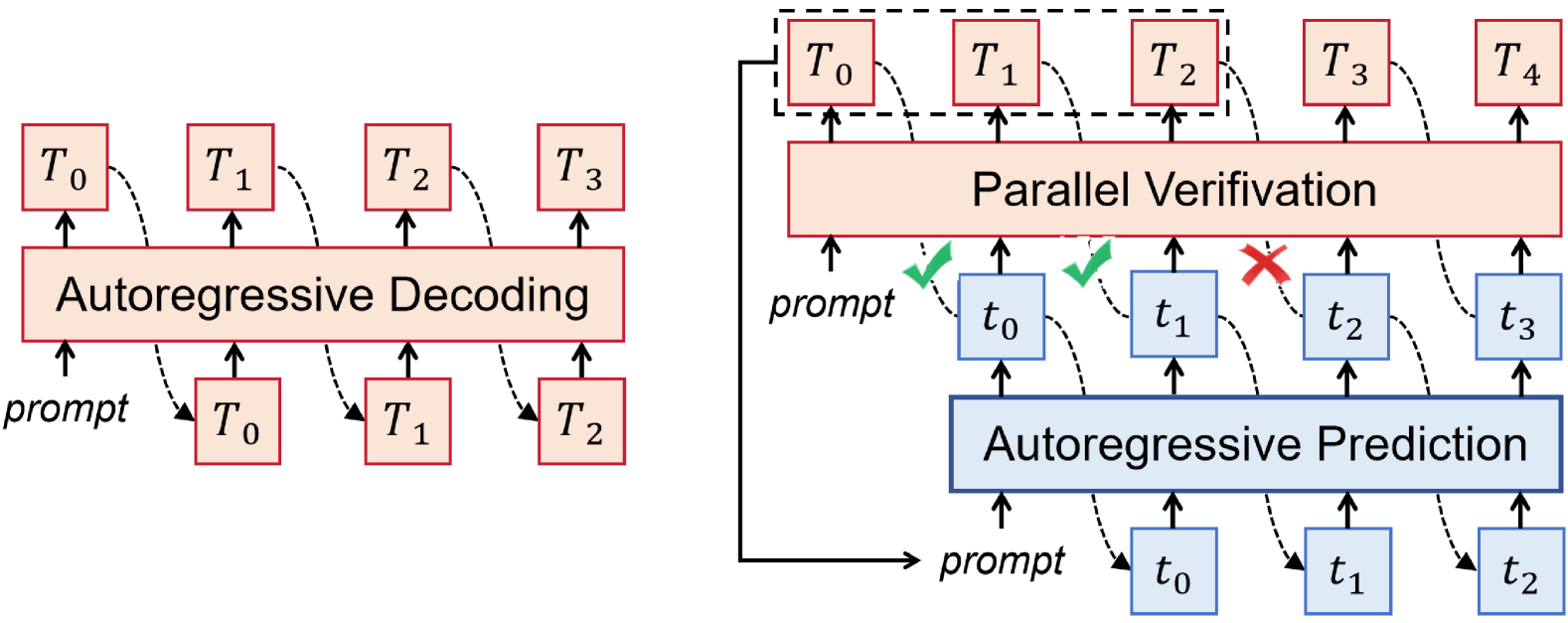
如上图,speculative decoding 通过并行验证,把原本串行的多步生成压缩成一次 forward,大幅降低延迟。
但问题是,现有的 speculative decoding 方案都是为纯文本任务设计的,直接搬到 ASR 上只能拿到 1.5×-2× 的加速,远远不够。
今天要聊的这篇工作,SpecASR,北大的团队专门针对 ASR 任务的特性重新设计了 speculative decoding 框架,最终达到了 3.04×-3.79× 的加速——而且不损失任何识别精度。
2. LLM-based ASR 到底慢在哪
先看数据。下面两张图是主流 LLM-based ASR 模型的参数量和相对延迟拆解:
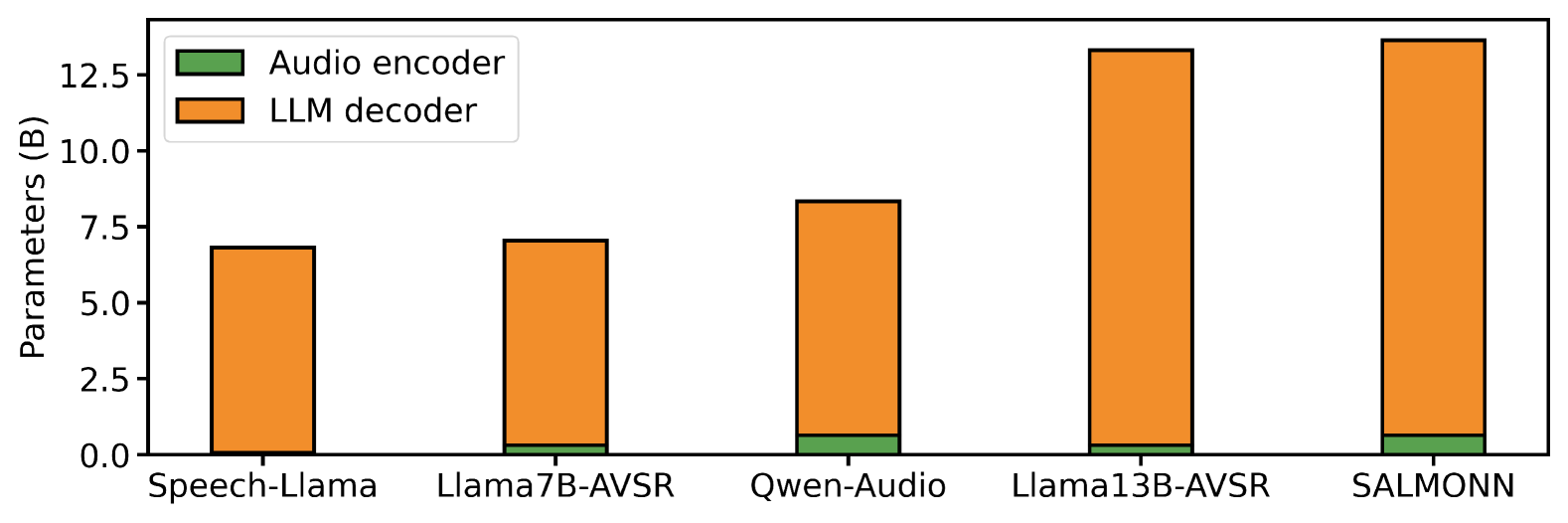
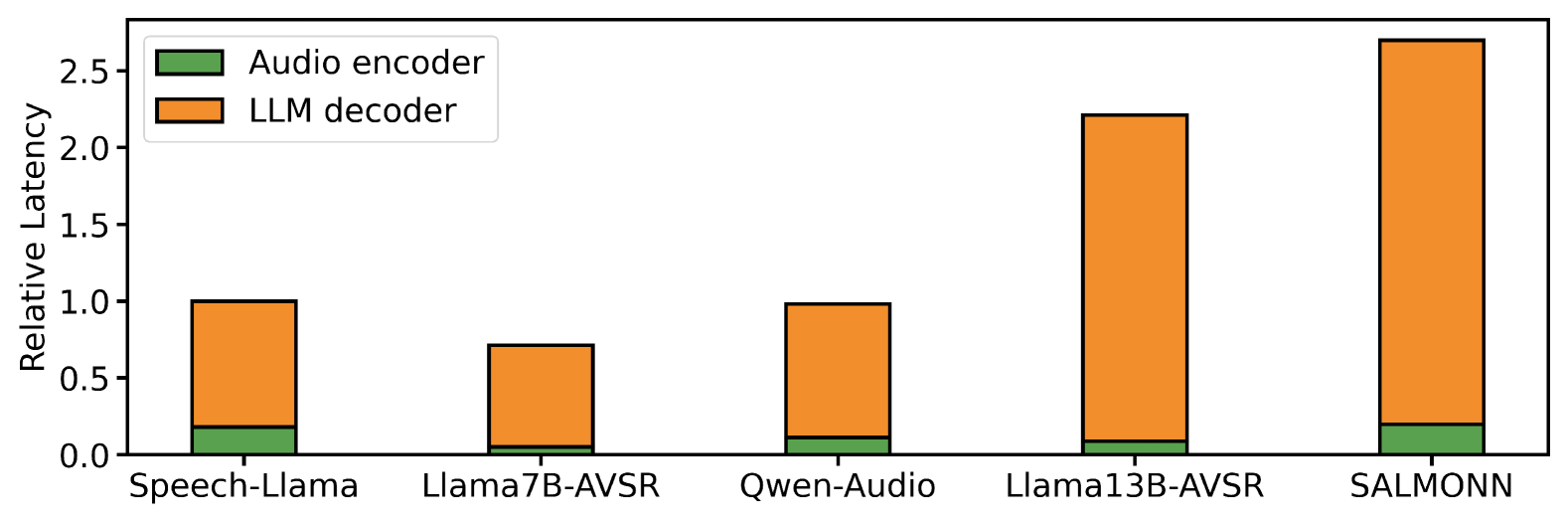
LLM decoder 无论参数量还是推理延迟都占绝对大头——audio encoder 那点计算量几乎可以忽略不计。
这背后的原因是架构决定的。LLM-based ASR 是一个级联系统:
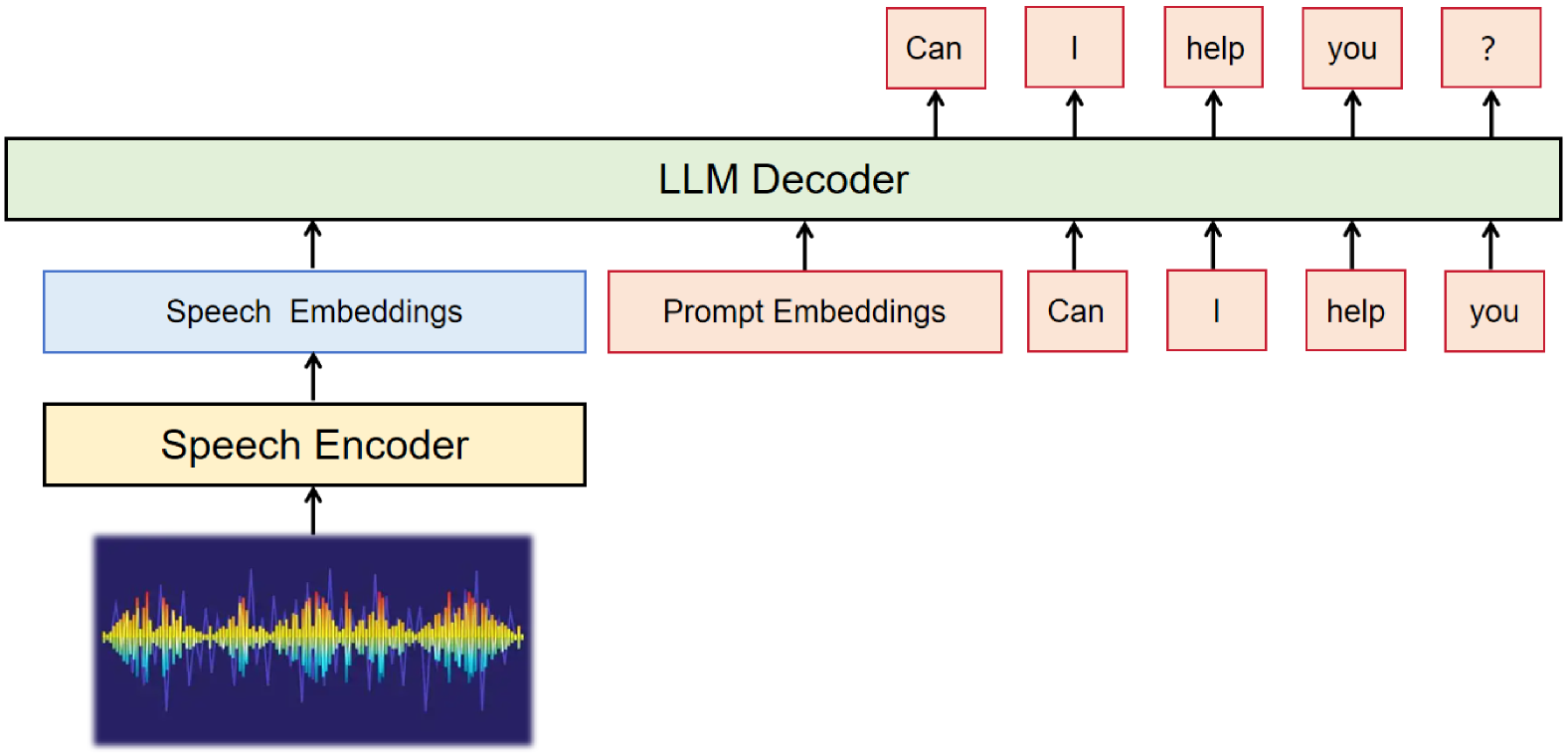
整个流程:Speech Encoder 把语音帧压缩成高维特征,再拼上 text prompt,喂给 LLM Decoder 逐 token 生成转录文字。Speech Encoder 只跑一次(等价于 prefill),瓶颈完全在 LLM Decoder 的 autoregressive decoding 上。
这也是为什么 speculative decoding 是一个有价值的切入点。
3. 为什么 ASR 适合更激进的 Speculative Decoding?
这篇工作有一个很核心的 insight,我觉得是整篇文章最有意思的地方:
ASR 解码是 audio-conditioned 的。
什么意思?普通文本生成任务里,大小模型的”思路”会随着生成的 token 不断发散——小模型猜错了,后面全歪了。但 ASR 不一样:无论模型大小,它们都在”转录同一段音频”,音频信号就像一根锚把大小模型的输出拉到了同一个方向。
实验结果非常直观(如下图,小模型在 ASR 任务里的 acceptance rate 明显高于纯文本任务的各种 top-k 采样):
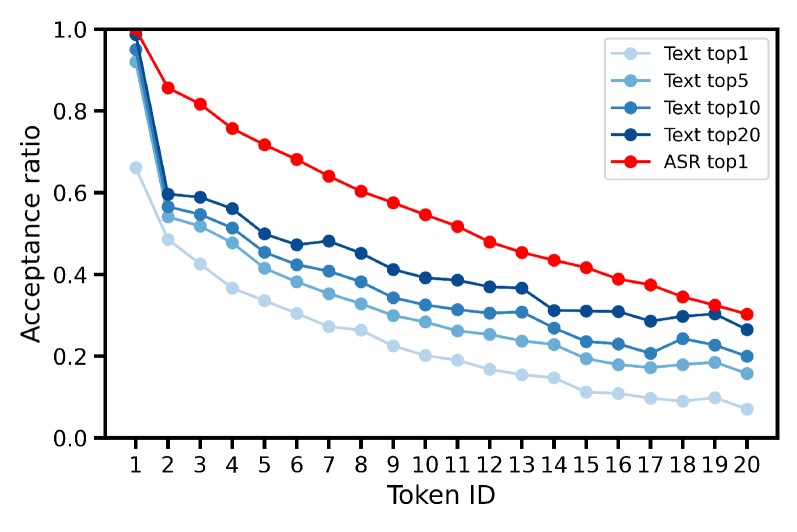
这意味着在 ASR 场景下,我们可以:
- 用更长的 draft sequence(普通场景一般 4-8 token,这里可以到 24 token)
- 更激进地做 token tree 扩展(因为大小模型对齐度高)
这就是 SpecASR 的出发点。
4. SpecASR 的三板斧
整体框架如下:
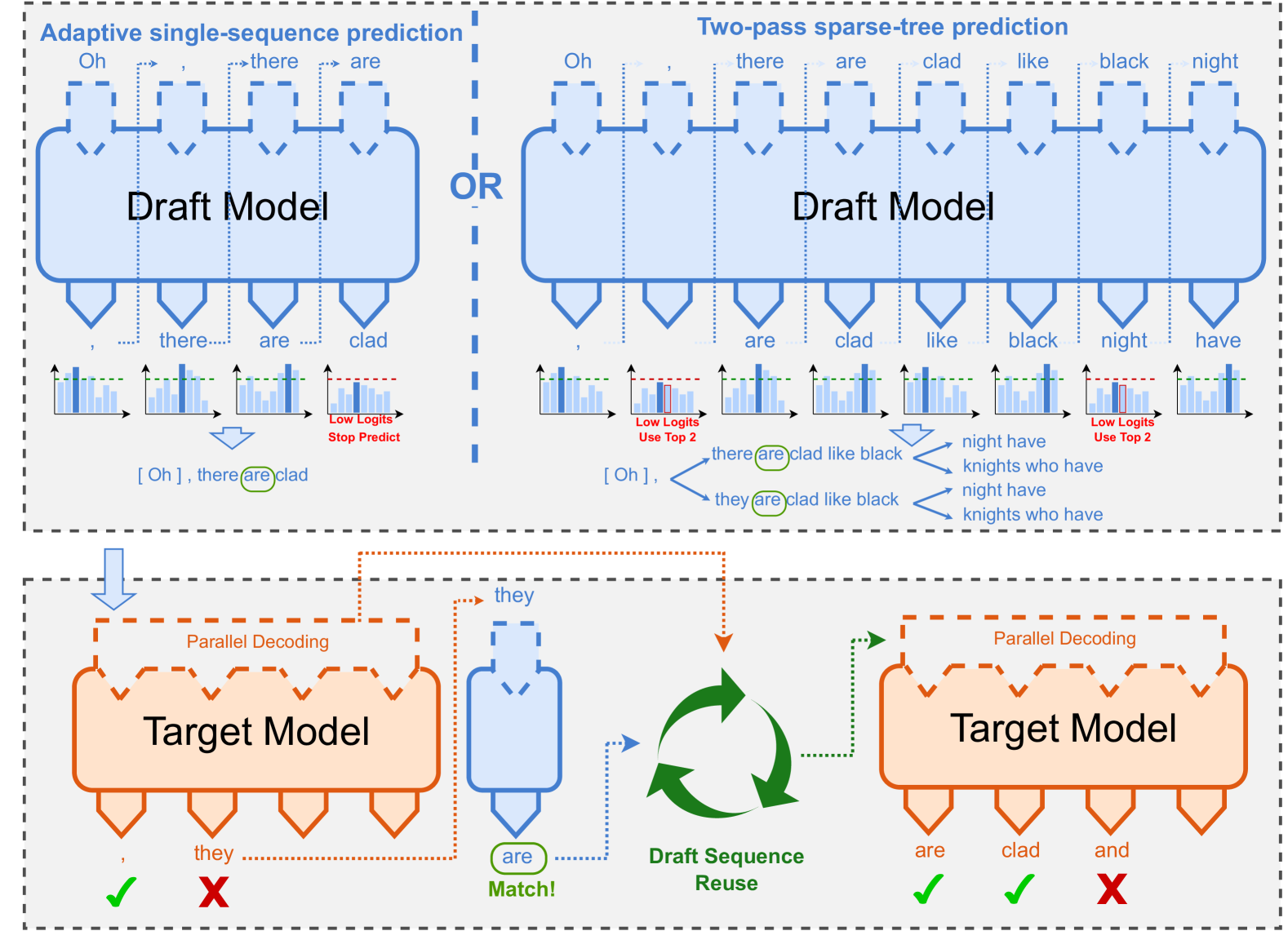
SpecASR 提出了三个核心技术,来分别对应 draft generation 效率和 target verification 效率的提升。
4.1 自适应单序列预测(Adaptive Single-sequence Prediction)
核心思路:不设固定的 draft 长度,而是根据当前 token 的 logit 置信度动态截断。
具体来说,预测过程中会实时监控每个 draft token 的 normalized logit。如果某个位置的 logit 低于设定阈值,说明这个 token “没把握”,与其让它继续往后猜一堆大概率错的 token,不如提前把当前的 draft 序列送给 target model 验证。
这样做的好处是两面的:
- 高置信度时:大胆猜长序列(up to 24 tokens),充分利用 ASR 的 audio-conditioned 对齐优势
- 低置信度时:及时刹车,避免 draft model 浪费算力
4.2 Draft Sequence 复用策略(Draft Sequence Recycling)
这是一个很工程化、也很实用的优化。
结合下图理解:
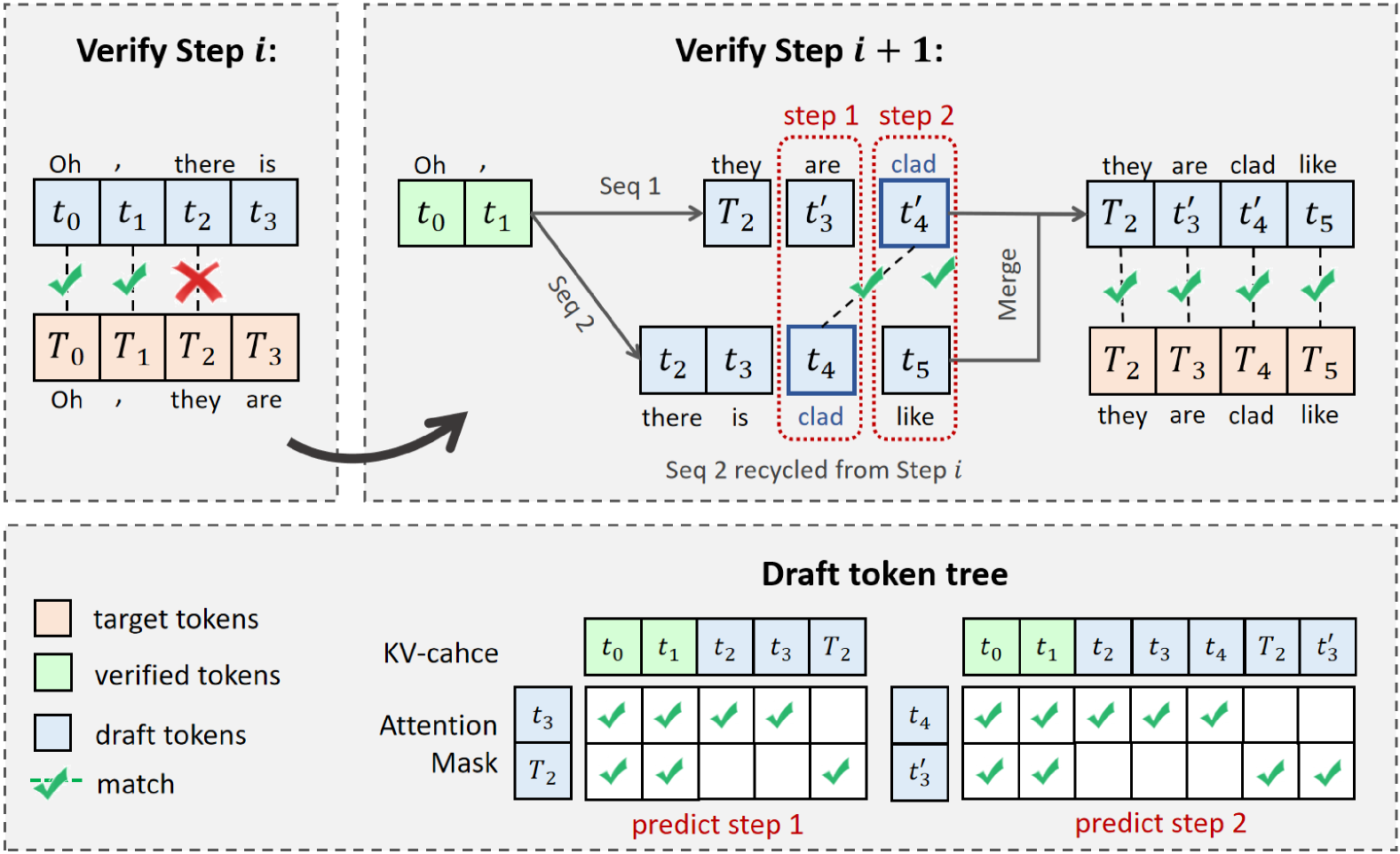
问题背景是:就算有了自适应截断,被 target model 拒绝的 token 依然存在。被拒绝的 draft tokens 通常不会直接被抛弃——它们对下一轮的预测其实还有参考价值。
SpecASR 的做法是:把上一轮 draft 序列里”未被接受但可以拼接”的部分复用到下一轮的 draft 生成起点,而不是从头开始让 draft model 重新生成。
这直接减少了 draft model 的重复计算,实验数据是:减少了 74.1% 的无效预测步骤,draft model 这边的延迟大幅下降。
4.3 两轮稀疏 Token Tree 预测(Two-pass Sparse Token Tree)
前两个技术主要针对 draft model 相对较小的场景(比如 TinyLlama + Llama-7B)。当 target model 非常大(比如 Vicuna-13B)时,target verification 本身变成了新瓶颈,这时候就需要 token tree 来提高单次验证的 token 吞吐量。
但传统的 tree-based speculative decoding(如 SpecInfer)需要 draft model 多次运行来扩展 tree,overhead 很高。
SpecASR 的两轮预测流程:
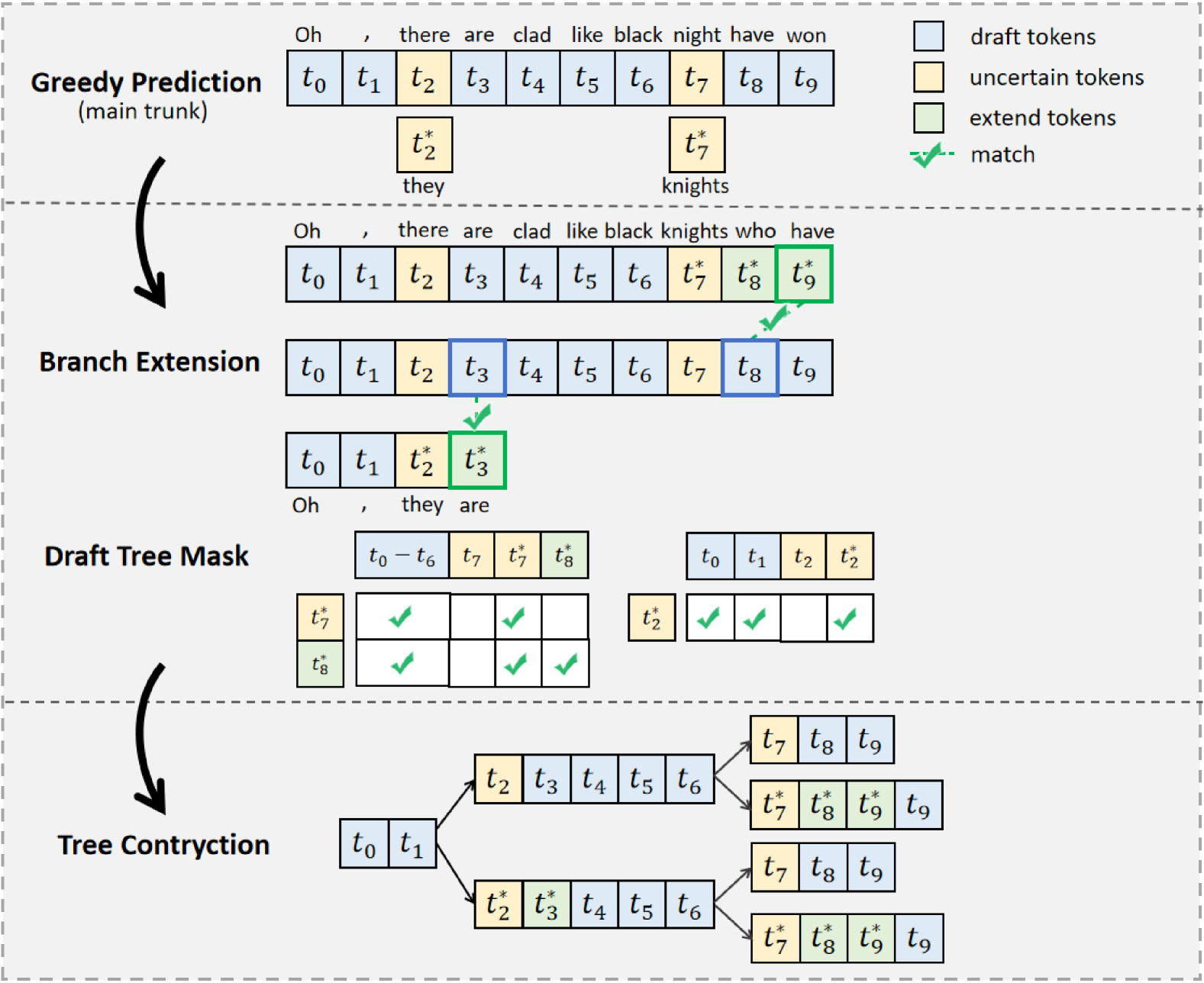
第一轮:正常做 greedy 单序列预测,同时标记出 logit 置信度低的位置(不确定点)
第二轮:只在这些不确定点上做分支扩展(用 top-k 候选),组成一棵稀疏 token tree
关键在于”稀疏”——不是在每个位置都展开,而是只在需要的地方展开,大大降低了 tree 构建的 overhead。结合前面的 draft recycling 策略,新分支如果能接在已有的”主干”上,就不需要重新生成,直接复用。
如下图,随着预测长度增大,draft model 的延迟占比上升,target model 的延迟占比下降——这说明优化 draft model 效率和 target verification 效率需要同时兼顾:
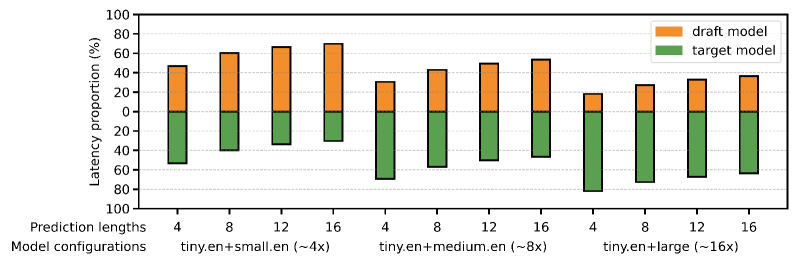
对比下三种方案的效率矩阵:
| 方法 | Draft 效率 | Target 验证效率 | Draft 长度 | 接受率 | 灵活性 |
|---|---|---|---|---|---|
| 单序列(普通) | 高 | 低 | 中 | 低 | 中 |
| Fixed Tree | 低 | 高 | 低 | 中 | 低 |
| Dynamic Tree | 低 | 高 | 低 | 高 | 高 |
| SpecASR(ours) | 高 | 高 | 高 | 高 | 高 |
SpecASR 是唯一一个在四个维度上都做到”高”的方案。
5. 实验结果
测试平台是 NVIDIA RTX A6000,数据集是 LibriSpeech(clean/other + dev/test)。
主要加速结果如下(相比 autoregressive baseline):
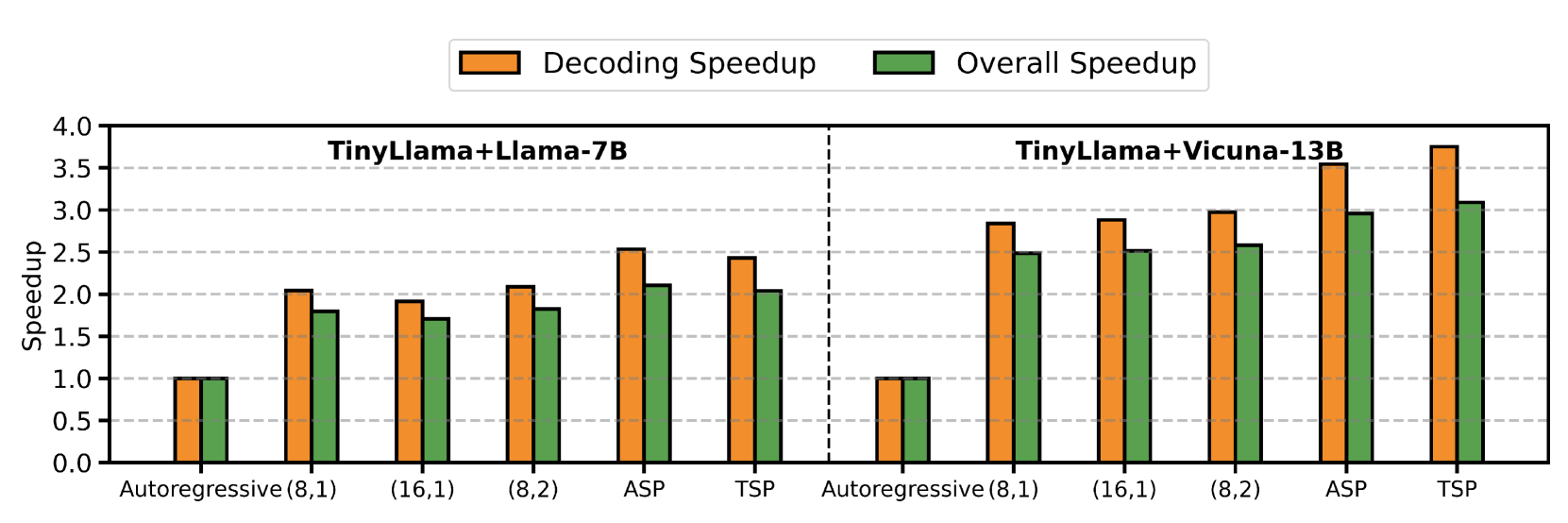
- TinyLlama+Vicuna-13B:最高 3.79× overall speedup
- TinyLlama+Llama-7B:2.05× overall speedup
- vs. 普通 speculative decoding:1.25×-1.84× 额外加速
消融实验数据(每 10s 音频平均解码延迟):
| 方法 | Draft(ms) | Target(ms) | Total(ms) |
|---|---|---|---|
| baseline speculative | 231.06 | 254.48 | 485.54 |
| +自适应单序列 | 236.23 | 191.20 | 427.43 |
| +draft sequence recycling | 189.48 | 199.52 | 389.00 |
| +两轮稀疏 tree | 244.62 | 123.17 | 367.79 |
三个组件叠加后,总延迟从 485.54ms 降到 367.79ms,对 target model 的加速尤其显著(254.48ms → 123.17ms,减少了 51.6%)。
值得一提的是:SpecASR 在整个加速过程中WER 没有任何变化——speculative decoding 从理论上保证了输出等价,识别精度完全不受影响。
6. 几点个人 take
这篇工作最打动我的是那个核心 observation:audio conditioning 是 ASR speculative decoding 的天然优势。这个 insight 不是拍脑袋出来的,他们用实验数据仔细验证了 ASR 和纯文本任务的 acceptance rate 分布差异,然后再反推出三个针对性的技术优化。这个从观察到设计的逻辑链条很清晰。
当然也有一些局限值得关注:
- 实验用的是 Whisper 模拟 Llama-based ASR 的解码轨迹,真正的 LLM-based ASR(Seed-ASR、Speech-Llama 这类)并没有开源模型可以直接验证,作者也坦承了这一点
- noisy 场景(test-other)下加速比有明显下降(3.7× → 3.04×),说明 draft 模型的准确率对整体效果有显著影响
不过整体来说,这是一篇做得很扎实的工程优化工作,三个技术点组合起来协同效果很好,代码也有望开源。对做 LLM 推理加速或者 ASR 系统的同学都很值得一读。
欢迎评论区交流,有问题或者发现我哪里理解有误,欢迎指出~