COLM'25 | PredGen:你还在说话,LLM 已经想好怎么回了
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

COLM’25 | PredGen:你还在说话,LLM 已经想好怎么回了
1. 前言
你有没有想过,和语音助手对话时,那段烦人的”停顿感”是哪来的?
不是网络延迟,不是模型太大——核心症结在于:LLM 必须等你说完,才能开始想怎么回。
这句话看起来是废话,但仔细想想:你说一句话通常要 2-5 秒,这 2-5 秒里 GPU 在干嘛?啥也没干,白白闲着。等你说完,LLM 开始生成,生成完第一句,再喂给 TTS(文字转语音)系统,TTS 再输出声音——用户实际感受到的延迟,是这一串链条的总和。
这篇来自 COLM 2025 的工作 PredGen(Predictive Generation) 提出了一个非常直觉的想法:既然 GPU 在等你说话时是空闲的,不如趁这个窗口先”猜”你想问什么,提前把回答准备好一部分。 实验结果显示,audio latency 能压缩大约 2×,而额外的计算开销极小。
2. 问题背景:语音交互的延迟到底卡在哪
现在的语音对话系统基本是一条流水线:
用户说话(ASR) → 文字 → LLM 生成回复 → TTS 转成语音 → 播放
其中 Audio Latency(音频延迟) 是用户体验的核心指标,也就是”你说完到你听到第一个字”之间的等待时间。
现有优化方向大多集中在:
- 用更快的解码算法(如 speculative decoding)减少 LLM 生成时间
- 用流式 TTS,边生成文字边合成语音
这些方案都在”你说完之后”的环节做文章。但 PredGen 换了个角度:在你还没说完时,就偷偷开始干活。
3. PredGen 的核心思路
整体 pipeline 如下图:
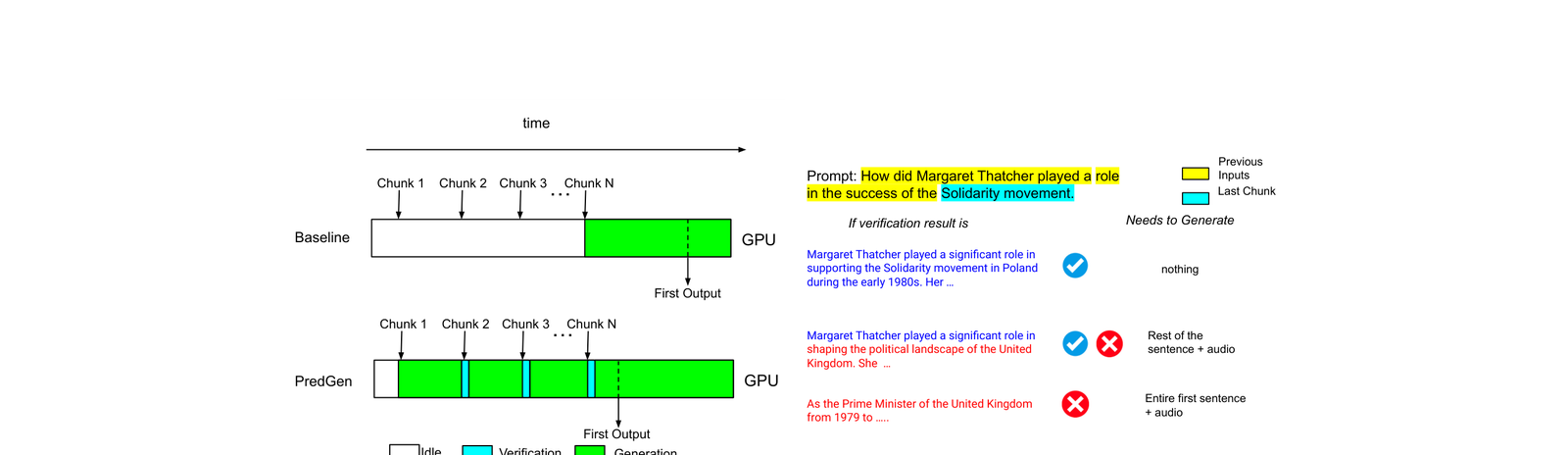
思路可以用一句话概括:边听用户说话,边用当前已知的部分 prompt 预测回复;等用户说完,用 verifier 验证预测结果,接受能用的部分,丢掉不符合的。
这本质上是把 speculative decoding 的思路,从”token 层面的预测”搬到了”输入时间维度”——利用的是同一个洞察:预测比验证便宜,只要命中率够高,整体就是赚的。
3.1 具体怎么运作
详细的算法设计如下图:
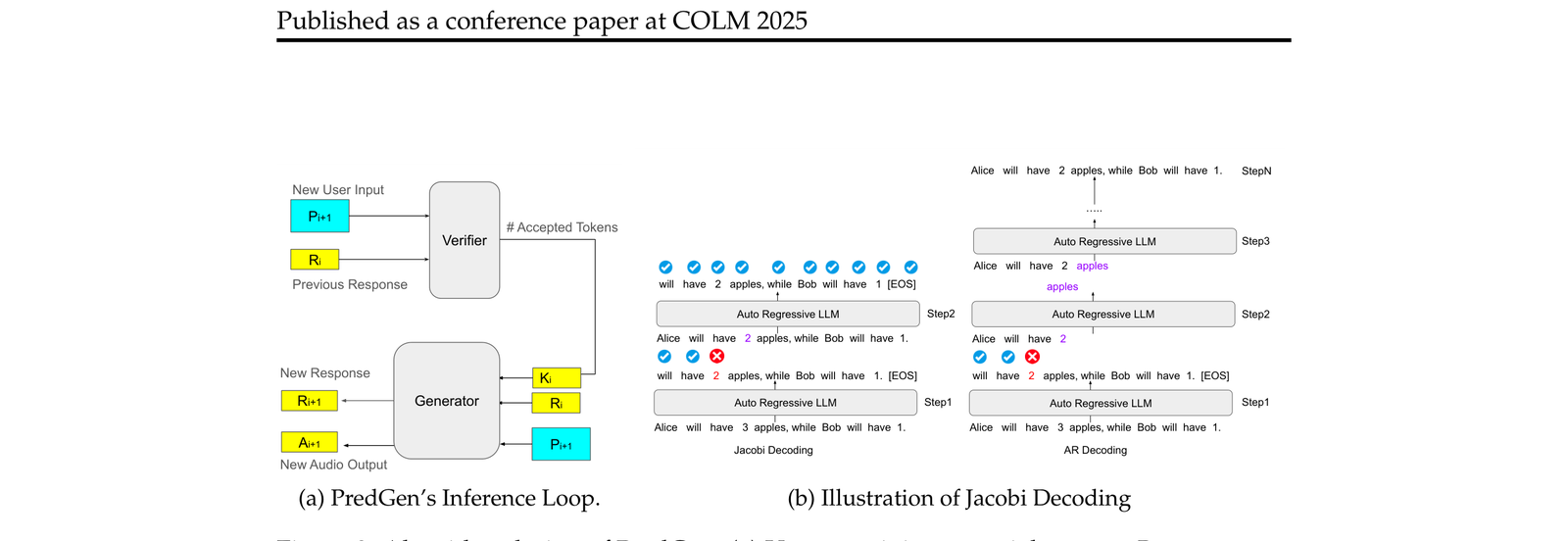
分两个核心子模块:
(a)预测-验证循环(Predictive-Verify Loop)
用户每说完一小段 prompt(记为 $P_{i+1}$),系统:
- 用当前已有的 response $R_i$ 作为”猜测”
- 用 verifier 检查 $R_i$ 里有多少 token($k_i$ 个)在新 prompt 下仍然成立
- 接受这 $k_i$ 个 token,在此基础上继续生成更新后的 $R_{i+1}$,同时合成第一句话的音频 $A_{i+1}$
这样每轮循环,已经生成并验证通过的部分就会积累,等用户说完的那一刻,很可能第一句回复已经准备好了。
算法伪代码:

(b)Jacobi 解码(更快的 AR 生成)
在”预测”阶段,为了让每轮的生成速度更快,PredGen 引入了 Jacobi decoding。相比标准的 autoregressive 解码(一个 token 一个 token 串行出),Jacobi decoding 通过多步并行迭代近似来加速生成,特别适合这里”宁快勿慢”的场景——反正结果最后还要过 verifier。
3.2 用户说话有多快?
论文里有一个细节:实验设定的输入速率是 600 字符/分钟,折算下来大概 10 字/秒,接近正常说话速度。这意味着用户说一句完整的问题,系统有好几秒可以提前”猜”,时间窗口其实相当可观。
4. 实验结果
4.1 主结果
核心数据如下:
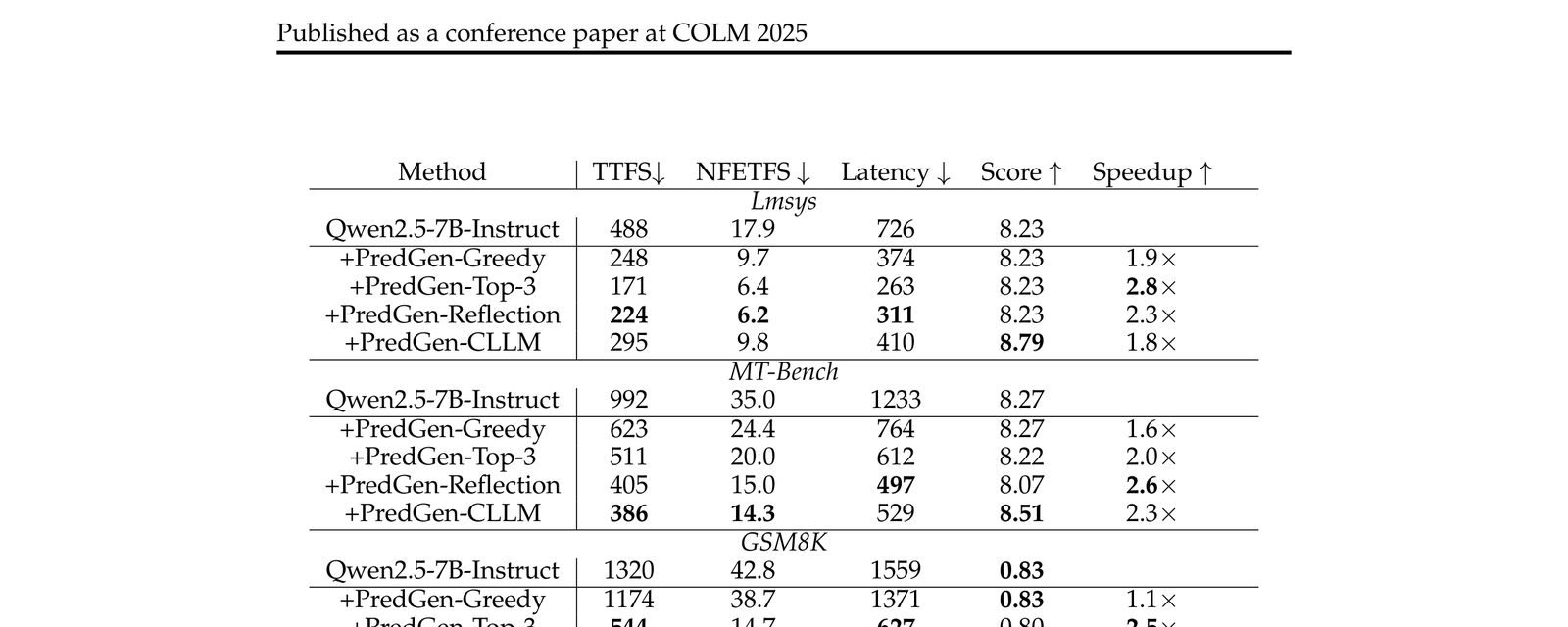
所有 PredGen 变体都实现了至少 1.6× 的 audio latency 加速,在部分场景接近 2×。

Latency 和 TTFS(Time-To-First-Sound)的单位是 ms,数字是实打实的工程收益。
4.2 不同 LLM 的泛化性
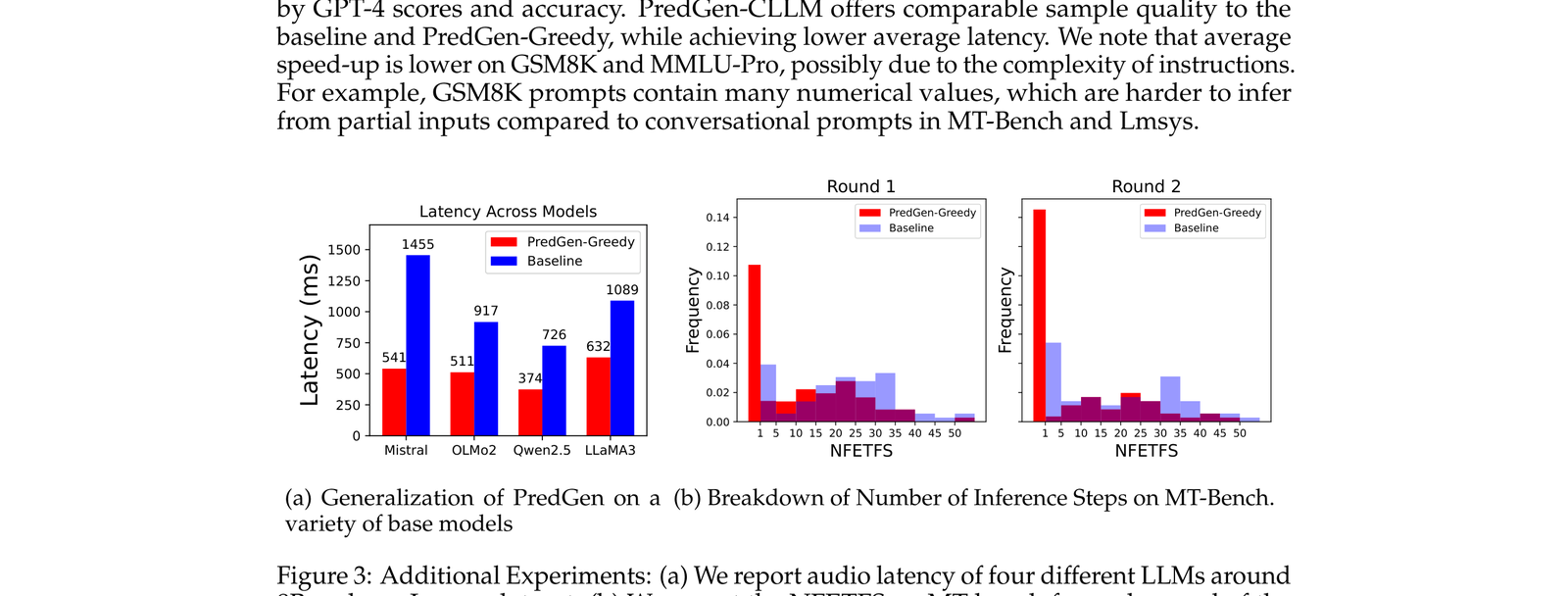
这张图说明 PredGen 在 Llama、Mistral 等四款约 8B 规模的模型上都有效,不依赖某个特定模型架构。对多轮对话(MT-bench)的 NFETFS(Normalized First Echo Time-to-First-Sound)也做了消融,效果持续稳定。
4.3 Top-K 接受策略的影响
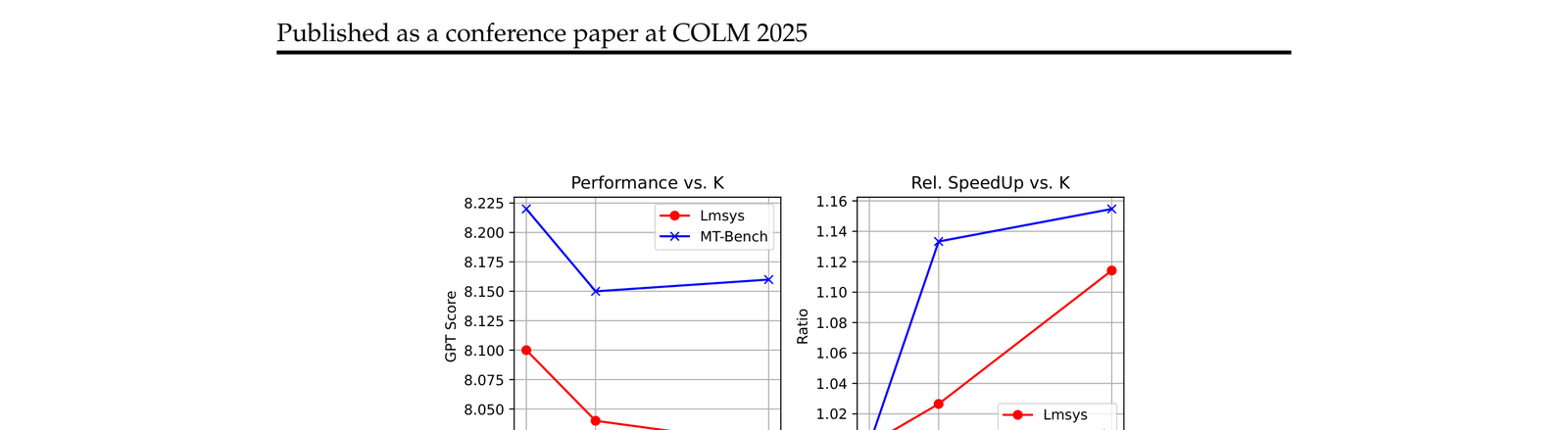
verifier 的接受策略(Top-K)对速度和质量都有影响,K 太小则接受率低(预测白做),K 太大则质量下滑。论文里给出了最优区间的参数建议。
5. 个人 take
这篇工作的出发点非常接地气——不是在 GPU 更忙的地方榨性能,而是在 GPU 闲着的时候多干活,属于”填谷”而不是”削峰”的思路。
几个觉得有意思的点:
-
和传统 speculative decoding 的区别:经典 speculative decoding 是”用小模型猜,大模型验”,在 token 级别并行。PredGen 是”用部分 prompt 猜,完整 prompt 验”,在时间维度并行。两者都是”预测比验证便宜”这个核心假设,但利用的资源完全不同。
-
适用场景的边界:这套方案对”用户输入有明确时间窗口”的场景(语音对话、慢速打字)非常有效。但对于 API 调用、批量推理这类场景,用户 prompt 是一次性给完的,就没有可利用的输入时间窗口了。
-
实际部署的工程考量:预测阶段的 LLM forward 会抢占推理资源,如果系统同时有其他请求,资源调度会更复杂。论文里的实验是单用户场景,多并发下的 overhead 值得后续研究。
总体来说,思路简洁、切中实际痛点、数据漂亮,是那种”想到之后会拍大腿”的工作。语音交互这个场景下,2× 的延迟降低对用户感知影响是非线性的——从 800ms 降到 400ms,体感差距比数字看起来大得多。
感兴趣的同学可以去看原文,有完整的算法描述和更多消融实验。欢迎评论区交流~
| *作者:Shufan Li, Aditya Grover | COLM 2025* |