LLM agent 为什么不稳?问题可能不在模型,在 harness
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

LLM agent 为什么不稳?问题可能不在模型,在 harness
1. 前言:一个反直觉的问题
你有没有遇到过这种情况:换了更强的模型,agent 表现没什么变化,甚至还倒退了?
我相信做过一段时间 agent 开发的人都踩过这个坑。直觉告诉我们”模型越强,系统越好”,但现实往往不是这样。
今天想聊聊这篇在审的综述——Agent Harness Engineering: A Survey(来自 CMU、Yale、Amazon 等多家机构)。它试图系统地回答一个核心问题:
LLM agent 的可靠性,到底是由模型决定的,还是由 harness 决定的?
作者的答案是:在很多情况下,harness 才是天花板,不是模型。
这个结论并不是拍脑袋的,论文里有三个非常硬的数字支撑:
- 研究员 Bölük(2026)只改了 edit-tool 格式和 tool harness,一个下午让 15 个模型的 coding benchmark 最高提升了 10×,模型权重一字未动
- OpenAI 团队固定模型为 GPT-5.2-Codex,仅通过重构 system prompt、注入 middleware context、加 self-verification hook,Terminal-Bench 2.0 上的分数从 52.8% 升到 66.5%,+13.7 个百分点,相对提升 26%
- Meta-Harness(Lee et al., 2026)通过自动化 harness 优化,在 Terminal-Bench-2 上跑到了 76.4%,超过所有手工设计的方案,没改模型
每一个数字,都超过了同一 benchmark 上靠换模型通常能带来的 2~4 个点的提升幅度。
这就是论文提出的 binding-constraint thesis(约束瓶颈假说):对于长任务的 agent,benchmark 方差更多是由 harness 驱动的,而不是模型本身。
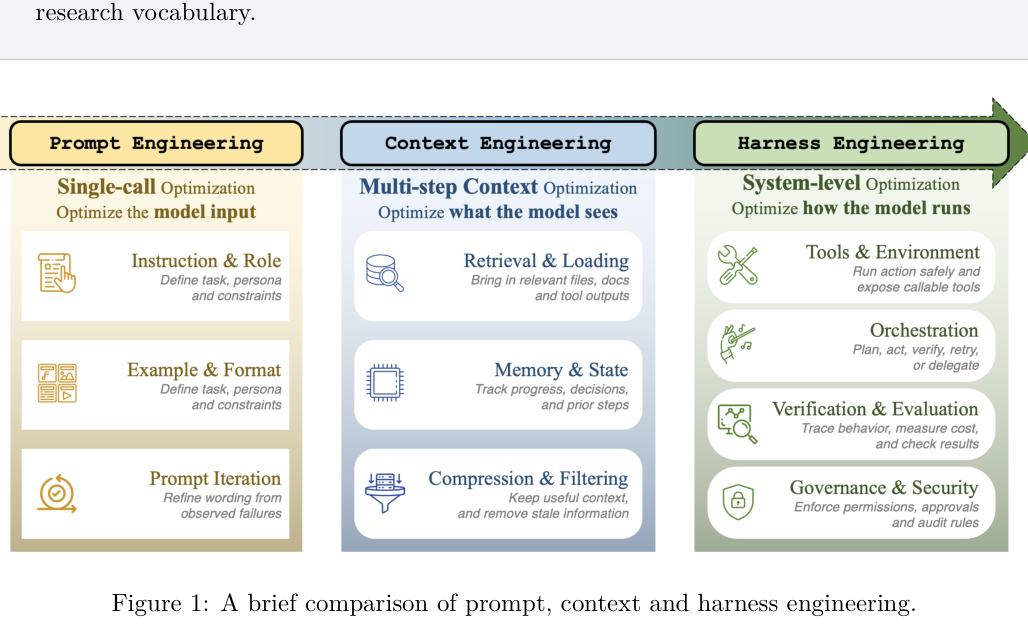
2. 先把概念捋清楚:harness 到底是什么
很多人可能对”harness”这个词不熟悉。说人话,harness 就是包裹在 LLM 外面的那一整套 infrastructure:怎么管 context、怎么调工具、怎么编排多个 agent、出了错怎么恢复、有没有监控、有没有安全管控……
论文把 2022 年到 2026 年的 agent 工程演化分成三个阶段:
Prompt Engineering(2022-2024):优化 prompt 文本本身,一次 LLM call,一个静态输入。
Context Engineering(2025):agent 开始跑多步任务,问题变成了”每一步给模型看什么信息”——怎么压缩 memory、怎么 retrieve、怎么避免 context 塞满。Anthropic 的 applied AI team 对此有专门的 blog,把它定义成”管理 LLM 推理时最优 token 集合的策略集”。
Harness Engineering(2026):模型能力已经足够强,系统可靠性的瓶颈转移到了 infrastructure——状态怎么维护、工具接口怎么设计、错误怎么反馈、执行怎么约束、安全怎么管控。harness engineering 把所有这些当成一个整体来设计。
三个阶段是包含关系,不是替代关系:harness engineering 包含 context engineering,context engineering 包含 prompt engineering。
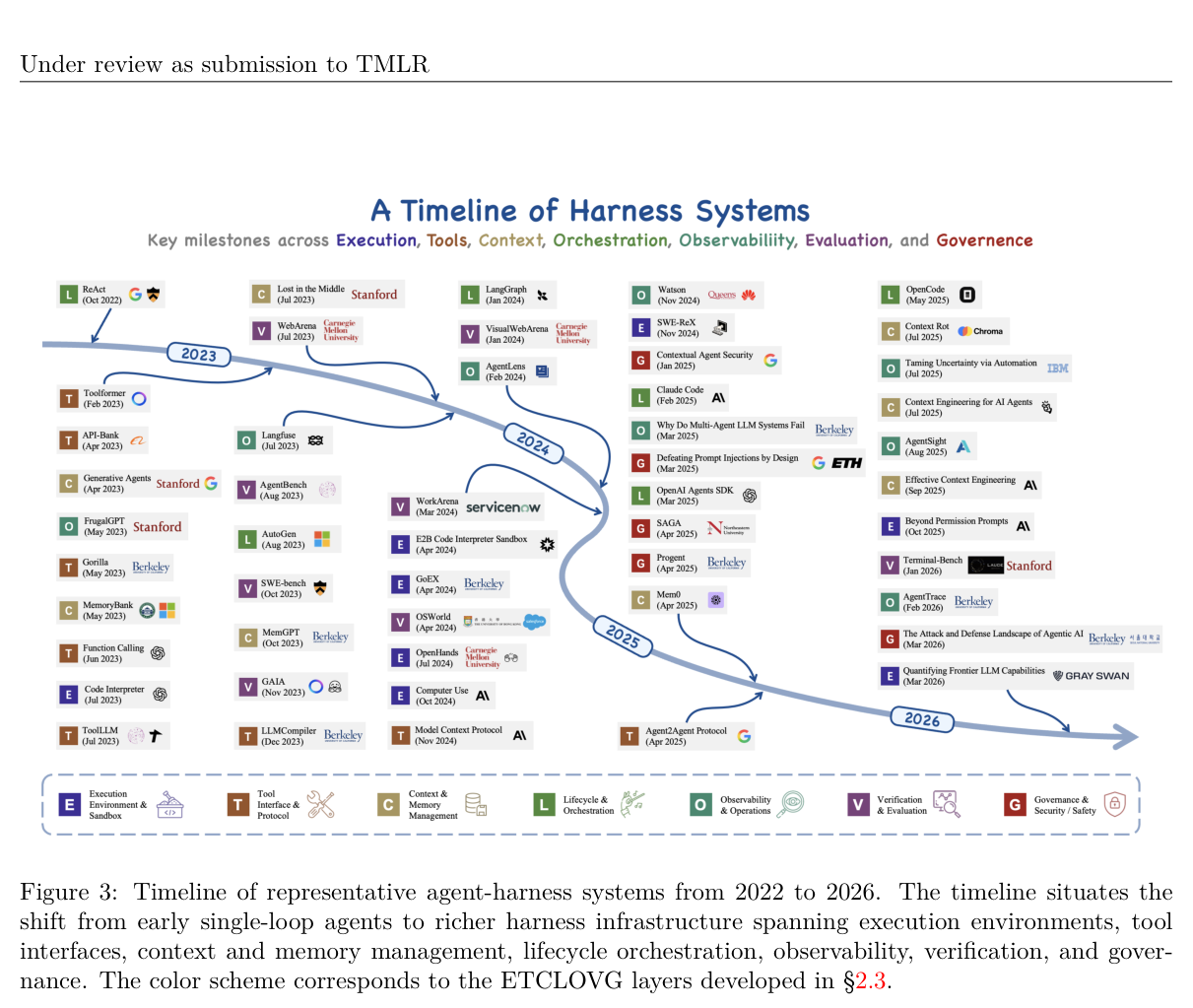
3. ETCLOVG:一个七层分类框架
论文的核心贡献之一是提出了 ETCLOVG 这个七层分类体系,覆盖了 harness 的所有工程维度。下面逐层拆解,每层说清楚它解决什么问题。
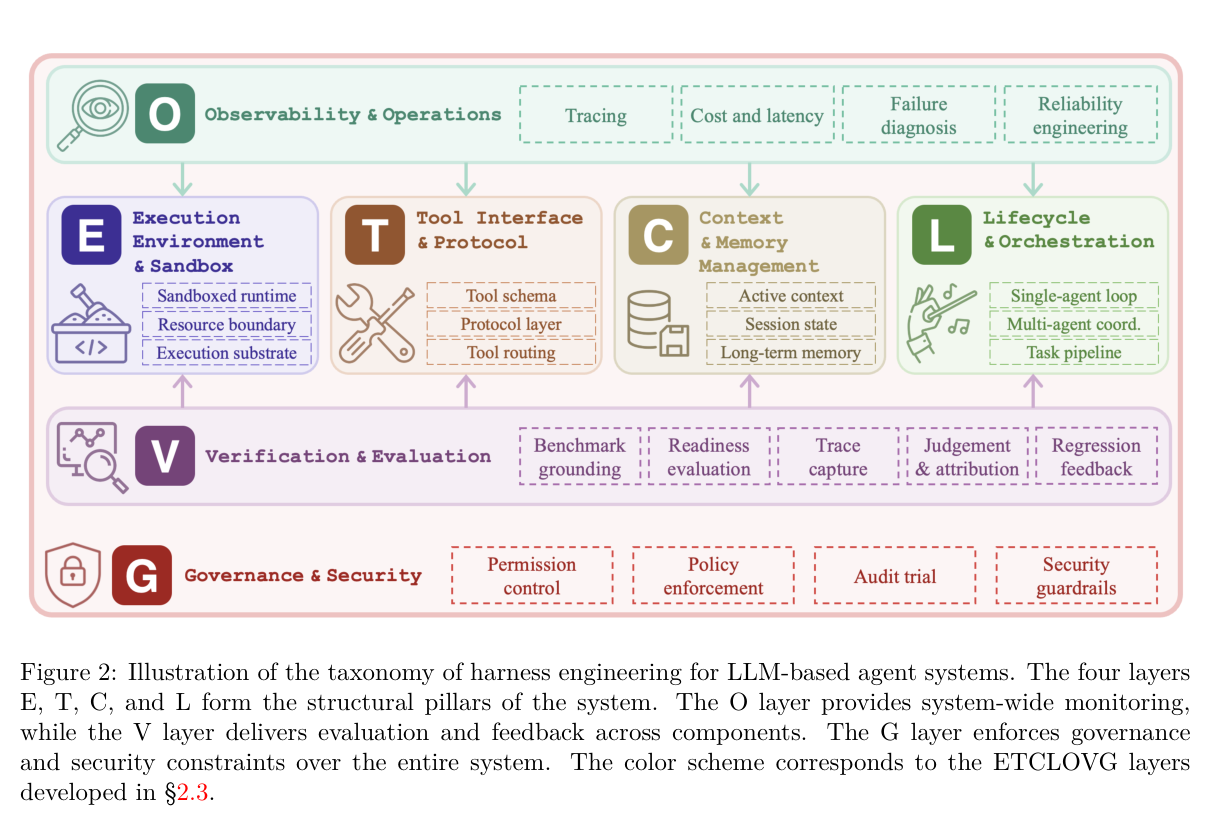
3.1 E — Execution Environment & Sandbox(执行环境)
agent 代码跑在哪里?在什么约束下运行?
这一层决定了 agent 的”活动边界”。沙箱不只是安全隔离,更重要的是它同时扮演两个角色:既是笼子,也是授权。Anthropic 报告称,引入沙箱机制后,Claude Code 的权限弹窗数量减少了 84%,同时保持安全性不变。
代表工具:E2B、Daytona、Docker Sandboxes、SWE-ReX(用于 eval 的可重置沙箱)。

3.2 T — Tool Interface & Protocol(工具接口)
怎么描述工具、怎么发现、怎么调用?
光有工具不够,关键是 agent 能不能在正确的时机用正确的工具。论文的一个核心结论:“fewer but better tools” 往往优于暴力扔一大堆工具,因为工具少了,模型选择错误的概率会下降,prompt entropy 也更低。
代表工具:MCP(Anthropic)、A2A protocol、LangChain tool 系统。

3.3 C — Context & Memory Management(上下文与记忆管理)
给模型看什么?看多久?
这一层是整篇综述里我认为最值得深挖的部分。有两个现象论文描述得很精准:
Context rot(上下文腐败):一个号称支持 200K token 的模型,在 50K 的时候就开始出现性能下降。随着 tool 结果、中间推理、文件内容不断堆积,模型对早期信息的注意力会下降。
Context drift(上下文漂移):跑 100 步以上的任务,agent 会反复做已经做过的事、违背之前自己定的决策、忘记最初的目标。压缩技术(compaction)只是延缓了这个过程,每次压缩带来的细微误差会随时间累积,agent 的内部状态最终会和真实任务环境发生偏离,而且现有架构对这个偏离没有任何检测机制。
代表工具:MemGPT、Mem0、Hindsight(Vectorize.io)、Anthropic 的 context compaction。

3.4 L — Lifecycle & Orchestration(生命周期与编排)
控制流怎么跑?单 agent loop 还是多 agent 协作?
从最简单的 observe-think-act 循环(ReAct 范式),到 issue → plan → code → validate → PR 的完整 pipeline,这一层管的是任务执行的整体编排。
值得注意的是:状态管理被论文放在这一层,而不是上下文层,因为状态天然和执行流耦合在一起。
代表工具:LangGraph、AutoGen、CrewAI、OpenHands、GitHub Agentic Workflows。

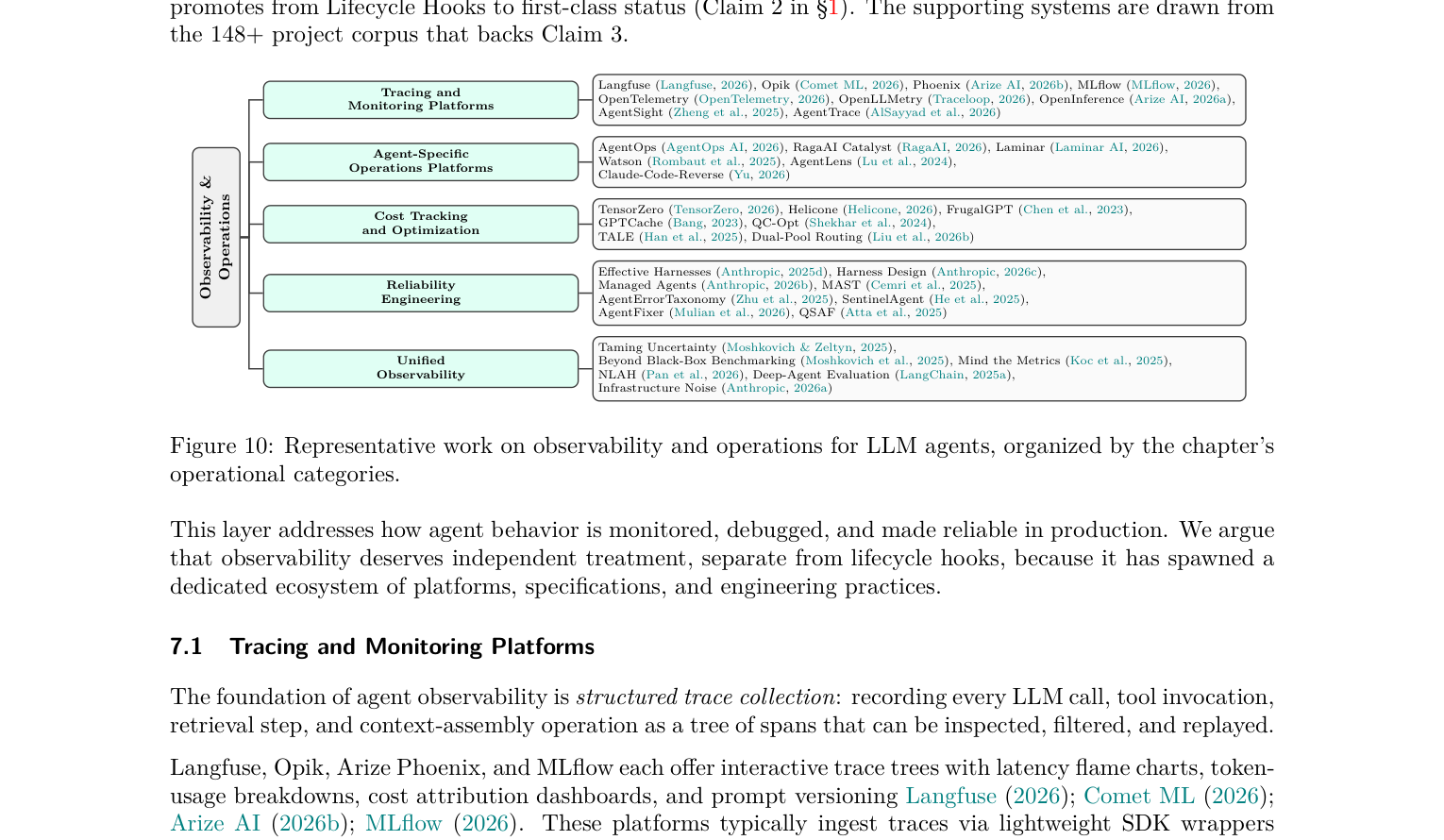
3.5 O — Observability & Operations(可观测性)
你的 agent 在干什么?为什么失败?花了多少钱?
这一层在现有框架里经常被当成”可选项”,但论文特意把它提升为独立的第一类层。
一个让我印象深刻的数据:89% 的团队在用 observability 工具,但只有 52.4% 在做 offline evaluation(LangChain 2026 年调查)。也就是说,大多数团队能看到 agent 在做什么,但没有系统地判断做的对不对。
代表工具:Langfuse、AgentOps、OpenTelemetry、Phoenix(Arize)。
3.6 V — Verification & Evaluation(验证与评估)
怎么判断 agent 跑得好不好?
论文把评估设计成一个五阶段的生命周期,而不是最终一个分数:
- 任务和 benchmark 的接地:确保评估环境是真实的
- 执行前就绪验证:环境准没准备好、工具装没装好
- 受控执行和 trace 采集:跑起来并且完整记录
- 多层判断和失败归因:失败了是模型问题、工具问题、还是 harness 问题?
- 持续回归和部署反馈:一个不断闭环的质量控制循环
一个 final score 不够用。对于长任务 agent,核心问题不只是”成没成功”,而是”为什么成功或失败、路径合不合理、哪个组件该改进“。

3.7 G — Governance & Security(治理与安全)
谁能做什么?怎么防 prompt injection?出了问题怎么审计?
这一层也是论文特意升为独立层的。和普通的”安全加固”不同,governance 的目标是在 agent 有自主权的前提下,定义它的行动边界。
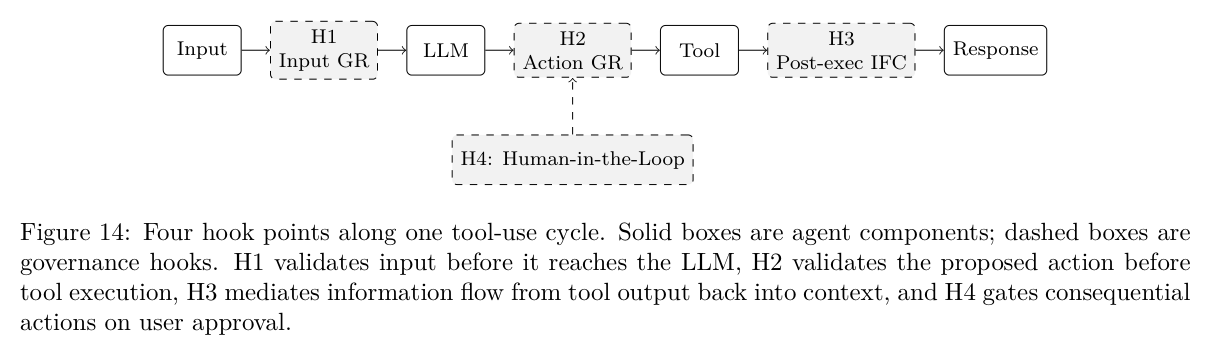
论文列出了四个治理 hook 点:输入验证、工具调用前、工具调用后、输出验证。代表工具包括 CaMeL(Anthropic 的 prompt injection 防御方案)、AgentSpec、Claude’s Constitution。
4. 生态现状:哪层厚,哪层薄
论文把 148+ 个开源项目映射到 ETCLOVG,有几个值得关注的发现:
- E(执行环境)、T(工具)、L(编排)、V(评估) 覆盖密集,开源工具多
- O(可观测性)、G(治理) 相对薄弱,更多依赖商业平台
- 有三类在早期语料里缺失的新项目现在已经成熟:task runner(任务运行器)、multi-agent orchestrator、spec-driven 开发工具
5. 几个跨层的核心矛盾
论文第 11 章的 cross-layer synthesis 是最有意思的部分,提炼了三个无法靠单层解决的系统级矛盾:
Cost-Quality-Speed Trilemma(成本-质量-速度三角):更强的沙箱更安全但更贵更慢;更丰富的 context 更准确但消耗 token 更多;更深的评估更可靠但更慢。生产系统必须在三者之间做权衡,没有免费的午餐。
Capability-Control Tradeoff(能力-控制权衡):给 agent 越多权限,它能做的事越多,但 blast radius 也越大。工具列表越长,越容易选错,prompt injection 的攻击面也越大。这不是安全模块的问题,这是整个 harness 设计的核心轴线。
Harness Coupling Problem(harness 耦合问题):各层之间是耦合的。执行环境的差异会影响评估结果;工具描述消耗 context budget 从而影响模型行为;可观测性日志只有在身份信息对齐的情况下才能成为治理证据。局部优化各层,整体不一定更好。
6. 最有意思的 open problem:随着模型变强,harness 应该越来越简单
论文最后一部分有一个反直觉的观点,我觉得很值得单独拿出来说:
每一个 harness 组件,本质上都是在假设”模型自己做不好某件事”。
随着模型能力增强,有些 harness 干预理应变得不再必要。Anthropic 就报告过一个例子:为某个模型设计的 context reset 机制,在换了更强的模型之后反而成了累赘——去掉它,成本下降,质量不变。
这引出了一个 meta-engineering 问题:harness 本身需要有机制来评估自己哪些部分还有用、哪些可以去掉。论文把这个称为 adaptive simplification(自适应简化)——harness 不应该随着时间越堆越厚,而应该随着模型变强而变得更精简。
目前这个方向的研究还非常早期。Meta-Harness 和 Natural-Language Agent Harnesses 在探索”把 harness 本身作为优化目标”,但离生产可用还差很远。
7. 写在最后
这篇综述的价值,我觉得有两层:
对工程师来说,ETCLOVG 是一个非常实用的 checklist。你在搭一个 agent 系统的时候,可以对着这七层问自己:执行环境有没有沙箱?工具接口有没有设计得让模型容易用?context 管理有没有处理 context rot?有没有可观测性?有没有做持续回归测试?治理和权限控制有没有?
对研究者来说,binding-constraint thesis 是一个值得认真对待的命题。如果你在做 agent eval,下次在 benchmark 上刷分之前,先问一下:我换的是模型,还是 harness?如果换的是 harness,那分数提升说明的是 harness 的效果,不是模型能力。这两件事不应该被混淆。
当然,这篇论文本身也有局限——它是综述,不是实证研究。binding-constraint thesis 的三个支撑数据来自有限的场景(coding benchmark),不代表所有 agent 任务。模型和 harness 谁更重要,可能取决于任务类型、任务长度、模型代际。目前我们还缺少一个能系统控制变量的 factorial 实验,同时控制模型和 harness 的多个维度。这本身也是论文点出的 open problem 之一。
有什么想法欢迎评论区交流,尤其是有实际 agent 工程经验的同学,很想听听你们觉得哪一层在实践中是最大的坑。