Meta-Harness:让 LLM 自己搜索最优 harness,模型不动,性能白涨
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

Meta-Harness:让 LLM 自己搜索最优 harness,模型不动,性能白涨
1. Motivation:为什么要优化 harness?
你有没有这种体验:同一个 LLM,换个 system prompt、改下 context 管理策略、调调 tool 调用逻辑,效果就突然起飞了?
这不是玄学,而是一个越来越被业界认可的事实:对于当前能力已经足够强的 LLM,性能瓶颈往往不在模型权重本身,而在”包裹”模型的那一套代码——harness。
所谓 harness,说人话就是:决定给模型看什么信息(context 管理)、怎么检索(retrieval)、怎么组织 prompt、怎么编排多步推理的那套外围代码。同一个模型,换一套 harness,可以在同一个 benchmark 上产生 6× 的性能差距。
问题是:这套 harness 到目前为止几乎全靠手工设计。研究员和工程师们凭直觉和经验去调 prompt、改 context 策略、设计 tool 接口。这个过程费时费力,而且效果高度依赖设计者的 domain expertise。
论文的核心问题就是:能不能让 LLM 自己搜索最优的 harness?
2. Challenge:现有的文本优化器为什么搞不定
你可能会问:这不就是 prompt optimization / text optimization 嘛?DSPy、OpenEvolve、TextGrad 不都在做类似的事?
确实相关,但论文指出了一个关键的匹配问题:现有的 text optimizer 对反馈信息压缩得太狠,丢失了 harness 搜索真正需要的诊断细节。
具体来说:
| 方法 | 历史信息 | 日志内容 | 每次迭代 token 开销 |
|---|---|---|---|
| OPRO | Window | past (solutions, scores) | 0.002 MToken |
| TextGrad | Last | textual feedback on current | 0.015 |
| AlphaEvolve | Window | program database + eval scores | 0.022 |
| GEPA | Summary | reflective feedback from n-best | 0.038 |
| Feedback Descent | Summary | comparison + textual feedback | 0.012 |
| TTT-Discover | Window | prev. solution fragment | 0.026 |
| Meta-Harness | Full | all logs and scores | 1.00 |
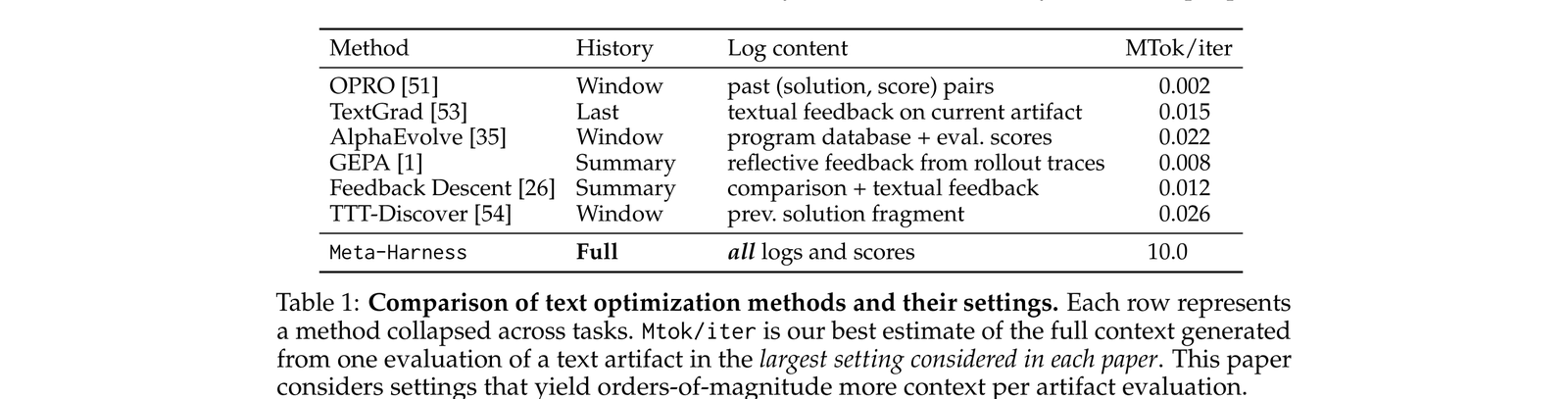
看到了吗?现有方法每次迭代只用 0.002~0.038 MToken 的上下文,而 Meta-Harness 用 1 MToken——差了两个数量级。
为什么需要这么多?因为 harness 优化和 prompt 优化本质上不一样:
- Prompt 优化:搜索空间是一段文本,改几个词就能有效果,反馈信号(”好/坏”)直接
- Harness 优化:搜索空间是一整套代码逻辑(检索策略、context 管理、prompt 构建、编排流程),需要看到完整的执行轨迹(哪个 example 失败了?失败时 context 里有什么?模型推理了什么?)才能做有效的归因
把一个完整 harness 的失败原因压缩成一句”accuracy too low”是没用的。你需要看到:哪些 case 错了、错的时候 context 长什么样、是检索没找到对的东西还是 prompt 格式有问题。这些诊断信息就是那 1M token 的来源。
3. 方法:Meta-Harness 怎么做
3.1 核心设计
Meta-Harness 的结构非常直觉——本质上是一个 outer-loop search,用一个 coding agent 作为 proposer,在 harness 代码空间里做搜索:
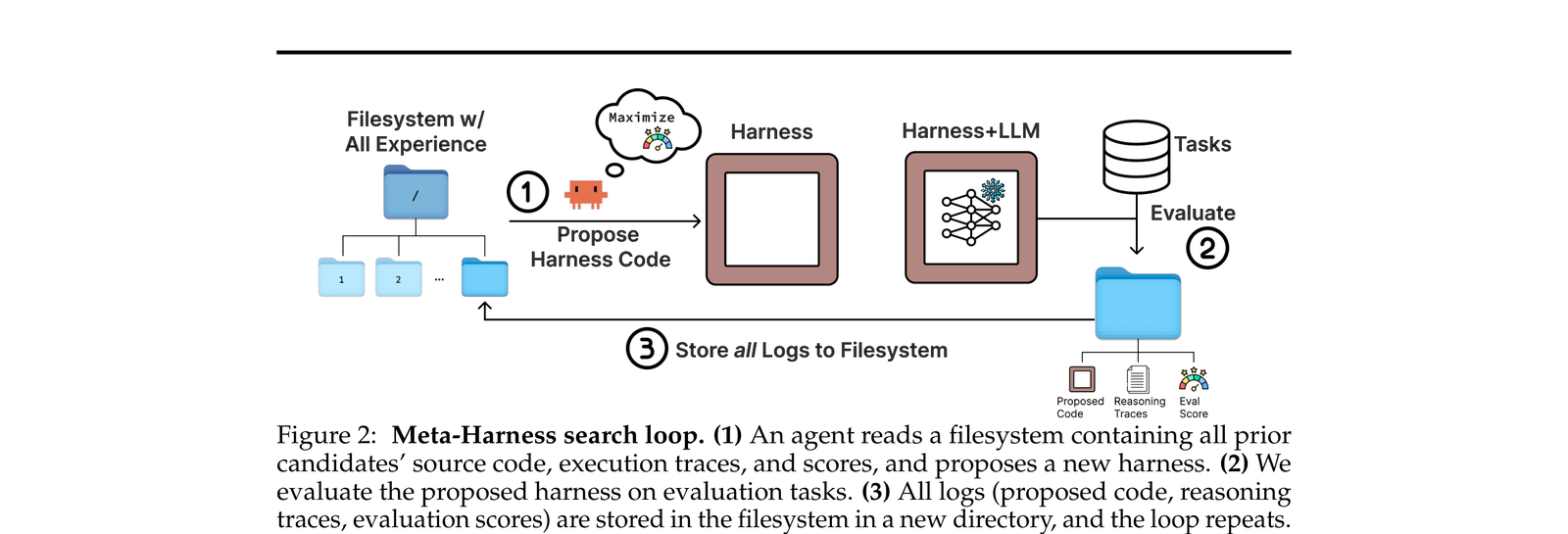
三步循环:
-
Proposer 读取文件系统:一个 coding agent 拥有对完整文件系统的访问权限。这个文件系统里存放着所有历史 candidate harness 的源代码、执行轨迹、评估分数。Proposer 通过
grep、cat等命令自由检索历史信息。 -
生成并评估新 harness:Proposer 生成新的 harness 代码,系统在验证集上评估它。
-
存储所有日志到文件系统:新 harness 的代码、推理轨迹、分数全部写回文件系统,供下一轮迭代使用。
3.2 关键设计选择
为什么是 filesystem 而不是 prompt?
这是论文最核心的设计决策。传统做法是把历史信息压缩成 summary 塞进 prompt——但 harness 级别的优化,一次评估就可能产生 1000 万 token 的诊断信息(100 个测试样本 × 每个样本完整推理轨迹)。这根本塞不进一个 prompt。
Meta-Harness 的方案是:不压缩,全存文件系统,让 proposer 自己决定看什么。 Proposer 是一个 coding agent,它可以自由地 grep 搜索失败 case、cat 某个具体轨迹、按分数排序历史 candidate——本质上把”该看什么历史信息”这个决策也交给了模型自己。
为什么 proposer 是 coding agent 而不是 text optimizer?
因为 harness 本身就是代码。Proposer 需要理解代码结构、做局部修改(而不是从头重写),这天然适合 coding agent。论文用的是 Claude Code [4] with Opus 4.6。
3.3 搜索策略
- 维护一个 Pareto frontier(多目标:accuracy + context cost)
- 每次迭代 proposer 生成 k 个 candidate
- 通过验证集筛选后加入 frontier
- 不做 population-based evolution——就是纯粹的 propose-evaluate 循环
实际跑的时候,一个典型的搜索过程是 20 轮迭代,每轮 proposer 读取中位数 82 个文件,引用超过 20 个历史 candidate。
4. 实验结果
论文在三个领域评估:在线文本分类、数学推理、agentic coding。
4.1 在线文本分类
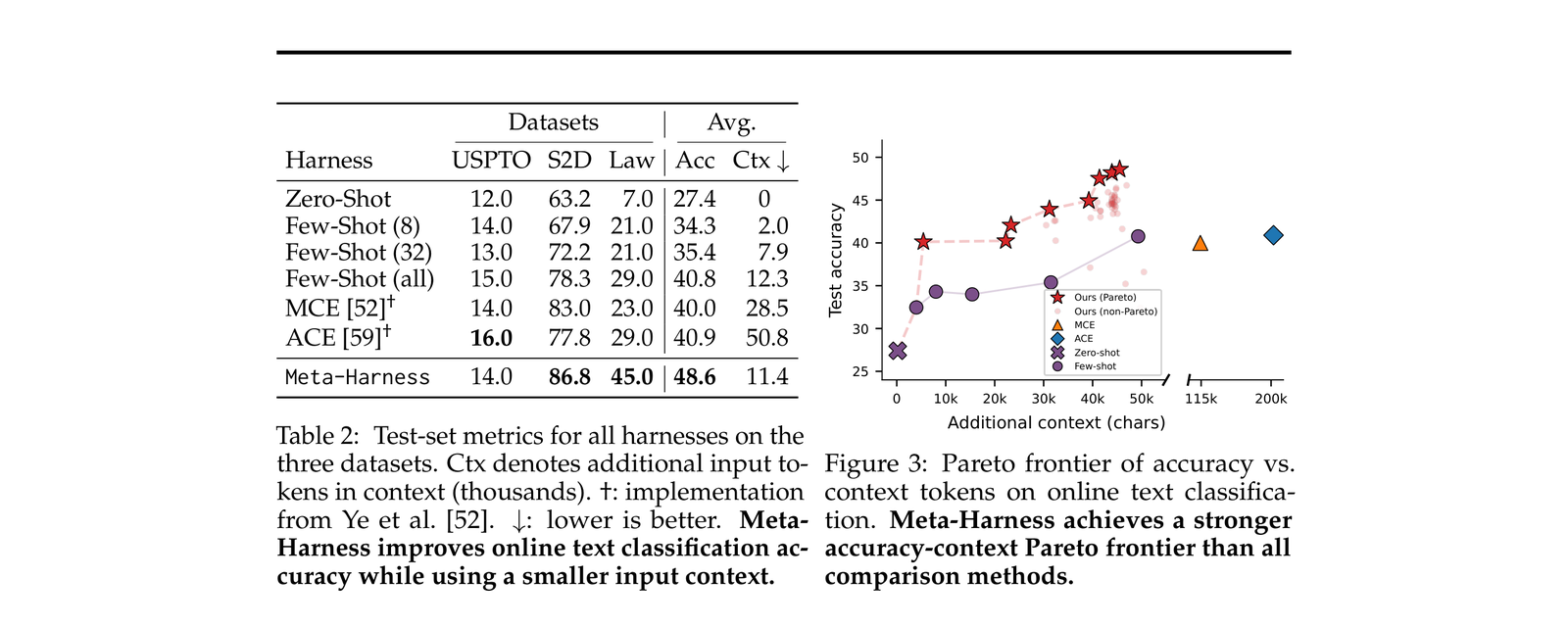
核心结论:
- Meta-Harness 比当前 SOTA context 管理系统 ACE(Zhang et al. [59])高 7.7 个点
- 同时只用了 4× 更少的 context token
- 仅 4 次评估就匹配了 next-best method 的最终 accuracy
- 比所有现有 text optimizer(OpenEvolve、TTT-Discover)都强,且收敛更快(10× fewer evaluations)

4.2 数学推理(IMO 级别)
这个实验设计很有意思:在 200 道 IMO 级别数学题上搜索 retrieval-augmented harness。

- 发现的 harness 在 5 个 held-out 模型上平均提升 4.7 个点——注意是 held-out 模型,说明发现的 harness 策略有跨模型迁移能力
- 相比 no retriever、dense retrieval、BM25 retrieval 都有显著提升
- 最终 harness 操作的是代码空间里的 retrieval stack(在 BM25 基础上做局部修改),而不是传统的 prompt rewrite
4.3 Agentic Coding(TerminalBench-2)

在 TerminalBench-2(89 道需要长 horizon 自主执行的 coding 任务)上:
- Meta-Harness 自动发现的 harness 超过了所有手工设计的 baseline
- 在 Opus 4.6 上达到 74.7% pass rate,超过手工调优的 Terminus-KIRA(72.5%)
- 在 Haiku 4.5 上排名 #1(所有 Haiku 4.5 agents 中)
- 发现的 harness 甚至超过了手工设计者在公开 leaderboard 上的提交
5. 讨论和思考
5.1 这本质上是 AutoML 在 LLM 时代的回归
作为做 NAS/AutoML 出身的人,看到这篇论文第一反应是:这不就是 harness 版的 neural architecture search 嘛。
NAS 的 insight 是:与其人工设计网络结构,不如定义搜索空间让算法去找。Meta-Harness 的 insight 完全对称:与其人工设计 harness 代码,不如定义评估协议让 agent 去搜索。
甚至连技术路线都有映射关系:
- NAS 的 controller/proposer → Meta-Harness 的 coding agent proposer
- NAS 的 search space (cells, ops) → 这里的 code space (harness 代码)
- NAS 的 evaluation (train & val) → 这里的 task evaluation
- NAS 的 Pareto frontier (accuracy vs FLOPs) → 这里的 Pareto frontier (accuracy vs context tokens)
5.2 “不压缩反馈”是最有意思的 insight
现有 text optimizer 的核心假设是:反馈信号可以被有效压缩成短 summary,然后塞进 prompt。这个假设在 prompt optimization 上基本成立——因为 prompt 本身就短,改动也小,一句”这个 prompt 在 X 类问题上容易出错”就够了。
但 harness 优化完全不一样。一个 harness 可能有几百行代码,失败原因可能藏在某个微妙的 edge case 里——比如”当检索结果超过 5 条时,context 格式化逻辑里有个 off-by-one bug”。这种诊断信息不可能被压缩成一个 scalar score 或一段 summary。
论文的 ablation 也证实了这一点:只给 scores(不给 traces)时 median accuracy 34.6;给 scores + summary 时 34.9;给完整 traces 时 50.0。traces 是真正的 game changer。
5.3 几个值得追问的问题
搜索成本有多大? 论文没有特别强调这一点,但从设计看:每轮迭代 proposer 需要读 82 个文件、消耗 1M token,跑 20 轮就是 20M token 纯 proposer 开销,加上 evaluation 开销。对于一次性的 harness 设计来说可以接受(搜一次用很久),但对于需要频繁适配新任务的场景,成本积累不小。
泛化能力的边界在哪? 数学推理实验里发现的 harness 能迁移到 5 个 held-out 模型,这很impressive。但 TerminalBench 的 harness 是”specialized to the TerminalBench-2 regime”——论文自己说了。所以迁移能力可能高度依赖任务类型:工具/格式层面的优化可能通用,但领域特定的 context 管理策略可能不行。
这对 harness engineering 的从业者意味着什么? 短期看,Meta-Harness 是一个强大的辅助工具——你不再需要从零手工调 harness,而是可以让它做初始搜索,你再在搜索结果上做微调。长期看,随着 coding agent 能力提升,harness 设计可能真的会变成一个完全自动化的流程。
5.4 一个有点 meta 的观察
论文最后提到一个很有趣的点:Meta-Harness 自己也是一个 harness(包裹 proposer 模型的那套代码)。那问题来了——能不能用 Meta-Harness 来优化 Meta-Harness 自身?
这不是开玩笑。论文的 proposer 是 Claude Code with Opus 4.6——它的 system prompt、filesystem 结构、搜索策略本身也是一套 harness。如果这套”meta-meta-harness”的设计也能被自动化,那就真的有点 recursive self-improvement 的味道了。当然,目前还远没到那一步,但方向值得关注。
总体来说,这篇工作的 contribution 很清晰:不是做了一个更好的 prompt optimizer,而是把问题定义提升到了 harness 层面,并且用”不压缩反馈 + filesystem 作为 memory + coding agent 作为 proposer”这套组合拳解决了 scale 的问题。 实验结果也足够硬——在三个不同领域都超过了手工设计和现有自动优化方法。
作为一个做 AutoML 的人,看到这个方向和 NAS 的深层联系,还是挺兴奋的。可能 LLM 时代的 AutoML 不是在搜网络结构了,而是在搜 harness 代码。搜索空间变了,但那个”let the machine find the design”的 spirit 没变。
欢迎评论区交流,尤其想听听有在做 agent harness 工程的同学的看法。