从零理解 ASR:音频基础、Qwen3-ASR 架构,以及离线 vs 流式推理原理
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

从零理解 ASR:音频基础、Qwen3-ASR 架构,以及离线 vs 流式推理原理
1. 前言吐槽
最近接了个新任务:对 Qwen3-ASR 做推理优化。
理论上,做 LLM 推理优化的人接 ASR 任务应该没什么门槛——毕竟 Qwen3-ASR 本质上是个 LLM。但说实话,ASR 这块我一直是个半生不熟的状态:音频输入到底长什么样、怎么变成模型能吃的 token、流式和离线到底差在哪——这些细节从没认真捋过。
于是就有了这篇文章。从最基础的”声音是什么”开始,一路走到 Qwen3-ASR-1.7B 的具体架构,再到离线和流式推理的原理差异,最后配上可运行的代码让大家直观感受两种模式的区别。希望对和我处于同样处境的同学有帮助(也希望我自己以后不要再从头查了…)。
2. 声音的数字表示:从波形到模型可用的特征
2.1 原始音频是什么
声音的本质是空气压强的振动。麦克风把这个振动采样成数字序列,叫做 PCM(脉冲编码调制) 信号:
采样率 16kHz:每秒采集 16000 个数值
每个数值:该时刻的声压,范围 [-1.0, 1.0] 的 float
1 秒语音 → shape [16000]
30 秒语音 → shape [480000]
这个采样率不是随便定的。人声基频大概在 80Hz-300Hz,辅音频率可以到 8kHz。根据奈奎斯特采样定理:要还原最高频率 F 的信号,采样率至少要 2F。语音识别通常只关心 8kHz 以下,所以 16kHz 够用了。
2.2 为什么不直接用原始波形
直接用原始波形训练模型有两个根本性问题:
- 太长了。30 秒音频有 480000 个点,Transformer 处理不了这么长的序列。
- 冗余且敏感。两个人说同一句话,波形可能完全不同(音色、语速、音调不同),但我们想要相同的文字输出。时域波形包含了太多与语义无关的信息。
解决方案:把时域信号变换到频域,看每个时间窗口里各个频率的能量分布——这就是 Log-Mel Spectrogram 的核心思路。
2.3 Log-Mel Spectrogram 提取流水线
下图展示了完整的特征提取流水线(用真实的合成信号生成):
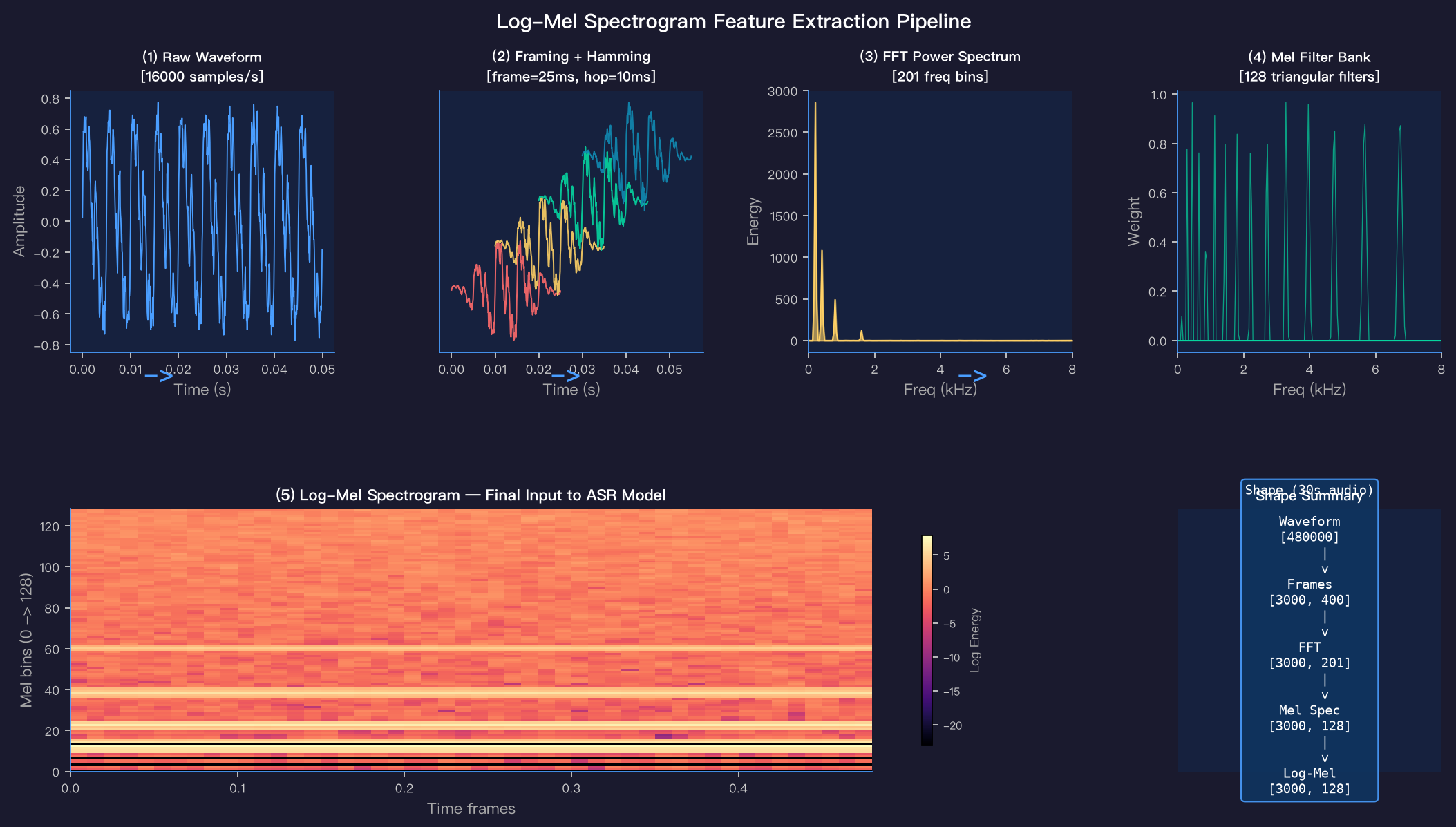
从左到右一步步来:
第一步:分帧(Framing)
不能对整段音频做一次 FFT——那样会丢失时间信息(不知道哪个频率在什么时候出现)。要把音频切成小段,每段叫一帧:
- 帧长(window size):25ms → 在 16kHz 下 = 400 个采样点
- 帧移(hop length):10ms → 在 16kHz 下 = 160 个采样点
- 相邻帧有重叠(帧长 > 帧移),保证时间连续性
30 秒音频 → (480000 - 400) / 160 + 1 ≈ 3000 帧
第二步:加窗(Hamming Window)
每帧边缘截断会产生频谱泄漏,所以 FFT 之前要乘上汉明窗,让边缘平滑衰减到 0。
第三步:FFT → 功率谱
对每帧做快速傅里叶变换,输出该帧各频率的能量:
import numpy as np
frame = signal[0:400] * np.hamming(400) # 加窗
fft_out = np.fft.rfft(frame, n=400) # shape [201],0 到 8kHz
power = np.abs(fft_out) ** 2 # 功率谱,shape [201]
第四步:Mel 滤波器组
人耳对低频敏感、对高频不敏感(对数感知)。Mel 刻度就是模拟这个感知特性的频率变换:
mel = 2595 × log10(1 + freq_hz / 700)
128 个三角形带通滤波器均匀分布在 Mel 刻度上(低频密,高频疏),把线性功率谱压缩到 128 个 bin。
第五步:取对数
log_mel = np.log(np.maximum(mel_spec, 1e-10))
取对数的好处:压缩动态范围,使能量分布更均匀,模型更容易学习。
完整维度变化(30s音频):
原始波形 [480000]
↓ 分帧 + 汉明窗
帧序列 [3000, 400]
↓ 对每帧 FFT → 取模平方
功率谱 [3000, 201]
↓ Mel 滤波器组(128 个 bin)
Mel 频谱 [3000, 128]
↓ 取对数
Log-Mel 特征 [3000, 128] ← 这就是模型的输入
你可以把 Log-Mel 理解成一张”声纹图像”——横轴是时间(帧),纵轴是梅尔频率(128 个 bin),像素值是对数能量。ASR 模型的输入,就是这张二维图。
Qwen3-ASR 的 preprocessor 配置完全对应上面的参数:
-
n_mels = 128,n_fft = 400(25ms × 16kHz) -
hop_length = 160(10ms × 16kHz) -
chunk_length = 30(秒)→ 3000 帧
3. ASR 解码范式演进:从 CTC 到 LLM
理解了输入怎么来的,再看”输出怎么出来”。
读到这里可能会有个疑问:分帧时相邻帧有 overlap,那转成文字的时候会不会出现重复?
不会,而且这是两个完全不同层面的事。 分帧 overlap 是信号处理层的操作,目的是让频谱平滑过渡、不丢边界信息,这一步完全不产生文字。文字是后面的解码器输出的——Encoder 先把 3000 帧压缩成 375 个 audio token(已经聚合了重叠帧的信息),再由 LM 整体生成一段文字,根本不存在”帧有重叠所以字会重复”的问题。
但这个顾虑在 CTC 范式里确实是真实存在的,看下面的对比就清楚了。
3.1 CTC:最简单的方案,重复问题真实存在
CTC(Connectionist Temporal Classification) 是端到端 ASR 最早流行的方案。思路极简:在每一帧上直接预测字符概率,3000 帧就输出 3000 个预测。
Audio Embedding [T, d]
↓ Linear
帧级别 logits [T, vocab_size + 1] # +1 是 blank token
↓ CTC Decode(去 blank,合并相邻重复)
文字序列
帧移 10ms、帧长 25ms,相邻帧本来就有重叠,同一个音节会跨越好几帧,每帧都预测同一个字符是完全正常的。所以 CTC 专门设计了 blank token 来处理这个问题:
CTC 每帧输出: h h e _ l l _ l o
↓ 去掉 blank(_)
h h e l l l o
↓ 合并相邻重复
h e l l o → "hello"
blank token 的含义是”这一帧没有新字符”,解码时先去 blank 再合并相邻重复,就能还原出干净的文字序列。
优点:非自回归(NAR),所有帧并行解码,推理极快。
缺点:每帧的预测完全独立,没有语言模型先验——不知道”你”后面更可能是”好”还是”们”,识别准确率天花板低。
3.2 Attention Encoder-Decoder:Whisper 的路子
Encoder 处理音频,Decoder 自回归生成文字,通过 cross-attention 连接。Decoder 直接生成目标文字序列,不做帧级别预测,从根本上绕开了重复问题。Whisper 就是这个范式,效果比 CTC 好很多,但不能原生支持流式。
3.3 LLM-based ASR:Qwen3-ASR 的选择
最新趋势:把 Audio Encoder 接到预训练好的大语言模型上,把音频当成 text prompt 的前缀,让 LLM 自回归续写出转录文字。和 AED 一样,LM 直接生成文字序列,不存在帧级别重复的问题。
核心优势:继承 LLM 的语言理解能力、原生多语言、支持 instruction following(识别+翻译+打标签)。代价是参数量大,推理 latency 高——这也是推理优化有意义的原因。
4. Qwen3-ASR-1.7B 架构详解
先看两张图,再逐一解释容易看懵的地方:
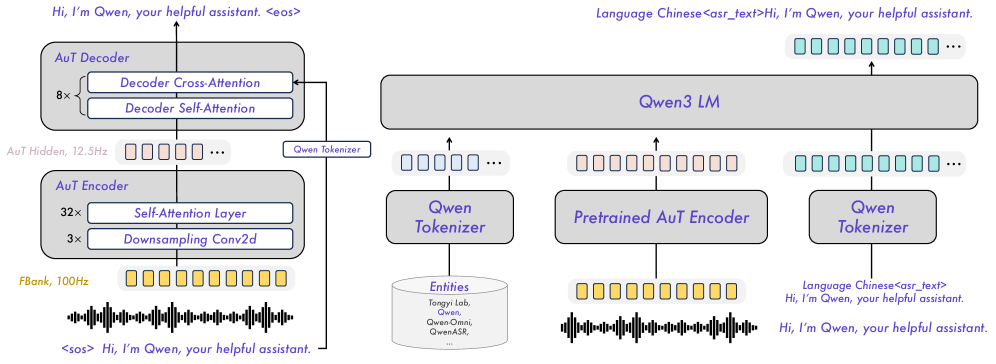
这张架构图信息量很大,而且左右两侧画的是两件不同的事,容易搞混,下面拆开说。
4.1 AuT 是什么,为什么有 Encoder + Decoder
AuT(Audio Transformer) 是一个单独预训练的 AED(Attention Encoder-Decoder)模型,在进入 Qwen3-ASR 训练之前就已经独立训练好了。它本身是个完整的端到端 ASR 系统,不是 Qwen3-ASR 的子组件。
训练数据:约 4000 万小时伪标注语音。训练目标:给音频进来,输出转录文字。这就是个标准的 seq2seq ASR。
Figure 2 左侧展示的正是 AuT 独立运行时的完整结构:
FBank 音频特征(100Hz)
↓
AuT Encoder(3× Downsampling Conv2d + 32× Self-Attention)
↓ 8× 降采样,输出 12.5Hz 的音频隐向量
AuT Decoder(8× Decoder Self-Attention + Cross-Attention)
↑ 同时接收 Qwen Tokenizer 的文字 token(<sos>...)
↓
转录文字(Hi, I'm Qwen... <eos>)
AuT Decoder 的作用是 AuT 预训练阶段的解码头,负责把 Encoder 输出的音频表示转成文字,跟 Whisper 的 Decoder 是同样的角色。
4.2 Qwen3-ASR:AuT Decoder 被丢弃了
Figure 2 右侧是 Qwen3-ASR 实际推理时的结构。最关键的一点:AuT Decoder 被完全丢弃,只保留了 AuT Encoder 作为音频特征提取器,解码工作全部交给 Qwen3 LM。
为什么换掉?AuT Decoder 是个轻量 seq2seq 解码器,语言理解能力有限。换成 Qwen3 LM 之后,直接继承了完整 LLM 的多语言能力、长文本理解和 instruction following 能力。
| AuT Decoder | Qwen3 LM | |
|---|---|---|
| 用途 | AuT 预训练阶段的解码器 | Qwen3-ASR 推理阶段的解码器 |
| 命运 | 预训练完成后丢弃 | 保留,是最终模型的核心 |
| 架构 | Cross-attention + Causal self-attention | Decoder-only 因果 Transformer |
| 语言能力 | 仅 ASR 导向,轻量 | 完整 LLM,多语言 + instruction following |
4.3 Figure 2 右侧的三列输入是什么意思
右侧三列并排的结构描述的是喂给 Qwen3 LM 的一条完整输入序列的三个来源,两个 “Qwen Tokenizer” 是同一个 tokenizer,只是图示上把来自不同文本的 token 分开画了:
左列(Qwen Tokenizer) 中列(Pretrained AuT Encoder) 右列(Qwen Tokenizer)
↓ ↓ ↓
system prompt 里的 音频经 AuT Encoder 指令文本 token
"Entities" token 编码出的音频 token ("请转录以上音频"等)
(命名实体/领域词汇)
↓ ↓ ↓
└──────────────────────────────┴──────────────────────────────┘
↓
Qwen3 LM
↓
Language Chinese<asr_text>Hi, I'm Qwen...
Entities(左列) 是用户可以注入 system prompt 的上下文信息——比如说话人名、品牌词、领域术语。模型训练时学会了利用这些信息做定制化识别,类似于给转写加 hints。
Qwen3 LM 最终收到的是这三部分拼成的一条序列:[Entities tokens] + [audio tokens] + [instruction tokens],没有任何 cross-attention——一切都是 decoder-only 的因果注意力。
4.4 Projector 在哪里
图里没有画 Projector,但它确实存在,论文原文写得很清楚:
“Qwen3-ASR-1.7B is built with Qwen3-1.7B, a projector, and an AuT encoder with 300M parameters and 1024 hidden size.”
AuT Encoder 输出维度 1024,Qwen3-1.7B 的 hidden size 2048,不匹配,中间必须有一个线性层做维度对齐。这个 Projector 就隐含在 Figure 2 右侧中列 AuT Encoder 和 Qwen3 LM 之间的那条箭头里,没有单独画出来。
4.5 完整数据流(以 30 秒音频为例)
原始音频 [480000 samples]
↓ Log-Mel 特征提取(FBank,100Hz)
FBank 特征 [3000, 128]
↓ AuT Encoder(Conv2d 8× 降采样 + 32 层 Self-Attention)
音频隐向量 [375, 1024] ← 帧数从 3000 压缩到 375
↓ Projector(Linear: 1024 → 2048,图中未画出)
音频 token [375, 2048]
↓ 与文字 token 拼接
[Entities_tokens] + [audio_tokens × 375] + [instruction_tokens]
↓ Qwen3 LM(decoder-only,28 层因果 Transformer)
↓ 自回归解码
转录文字
4.6 Qwen3 LM 关键参数
| 参数 | 值 | 含义 |
|---|---|---|
hidden_size | 2048 | 隐层维度(也是 Projector 的输出维度) |
num_hidden_layers | 28 | Transformer 层数 |
num_attention_heads | 16 | Q 的头数 |
num_key_value_heads | 8 | KV 的头数(GQA,KV Cache 减半) |
vocab_size | 151936 | 词表大小 |
GQA(Grouped Query Attention) 是内置的推理优化:num_key_value_heads=8 而 num_attention_heads=16,每组 2 个 Q head 共享一对 KV head,KV Cache 直接减半。
5. 训练流水线:Qwen3 LM 是怎么学会理解音频的
这里有个很自然的问题:Qwen3 LM 之前只见过文字,AuT Encoder 输出的音频 embedding 它凭什么认识?
答案是:它在进入 ASR 训练之前就已经见过音频了。Qwen3-ASR 的训练分四个阶段,前两个阶段和 Qwen3-Omni 共用:
“The training process consists of AuT pretraining, Omni pretraining, and ASR post-training, where the first two stages are identical to those of Qwen3-Omni.”
5.1 Stage 1:AuT 预训练
单独训练 AuT 这个 AED 模型,跟 Qwen3-ASR 的其余部分没有关系。
- 数据:约 4000 万小时伪标注 ASR 数据,中英文为主
- 训练目标:完整的 seq2seq ASR——AuT Encoder + AuT Decoder 一起训
- 产出:一个泛化能力强、在动态 attention window 下稳定的音频 Encoder
这个阶段结束后,AuT Decoder 就功成身退了,后续只用 Encoder。
5.2 Stage 2:Omni 预训练
Qwen3-Omni 是 Qwen3 LM 的多模态版本,在音频、视觉、文字的混合数据上联合预训练。
- 数据:多任务音视频 + 文本,两个尺寸的模型都训练了 3 trillion tokens
- 产出:一个 LM,它已经具备了多模态理解能力——见过音频表示,知道怎么把它映射成文字
这是 Qwen3 LM 能”认识”音频 embedding 的根本原因。它不是一个纯文本 LLM,而是从 Qwen3-Omni 出发,天然有多模态感知基础。
Projector 虽然不是在这个阶段从头训的,但 LM 在 Omni 预训练里已经适应了音频 token 的分布,后续联合微调时收敛更快、对齐更稳。
5.3 Stage 3:ASR 监督微调(SFT)
把 AuT Encoder + Projector + Qwen3-Omni LM 接在一起,针对 ASR 任务联合微调。
- 数据:多语言 ASR 数据 + 非语音数据 + 流式增强数据 + 上下文偏置数据(Entities 相关)
- 目标:让整条链路对齐——Projector 学会把 AuT 的表示映射到 LM 能理解的空间,LM 学会输出规范的 ASR 格式
- 产出:一个 ASR 专项模型,”does not follow natural-language instructions”(不是通用助手,就是转写机器)
5.4 Stage 4:强化学习(RL)
用 GSPO(一种 RL 算法)继续优化,主要提升准确率和多语言泛化能力。
- 数据:约 5 万条语音,其中 35% 中英文、35% 多语言、30% 功能性数据(语言识别、格式规范等)
- 目标:在 SFT 基础上进一步降低 WER 指标
WER(Word Error Rate,词错误率) 是 ASR 最核心的评估指标,计算公式是:
WER = (替换错误数 + 删除错误数 + 插入错误数) / 参考文本总词数 × 100%
举个例子:参考文本是”今天天气很好”(5个字),模型输出”今天气很好”(漏了”天”),则 WER = 1/5 = 20%。WER 越低越好,0% 是完美识别。State-of-the-art 模型在标准测试集(如 LibriSpeech)上 WER 已经能做到 1-2%。
整条训练链路的逻辑很清晰:先把音频 Encoder 训好(Stage 1),再让 LM 具备多模态感知(Stage 2),最后把两者接起来对齐(Stage 3 + 4)。Projector 是粘合两者的关键,从头训练,Stage 3 里和整条链路一起联合优化。
6. 离线推理 vs 流式推理:原理与代码
这是本文的核心部分。两种模式在音频 Encoder 的计算方式上有根本区别。
5.1 原理对比
如下图,离线模式和流式模式的数据流完全不同:
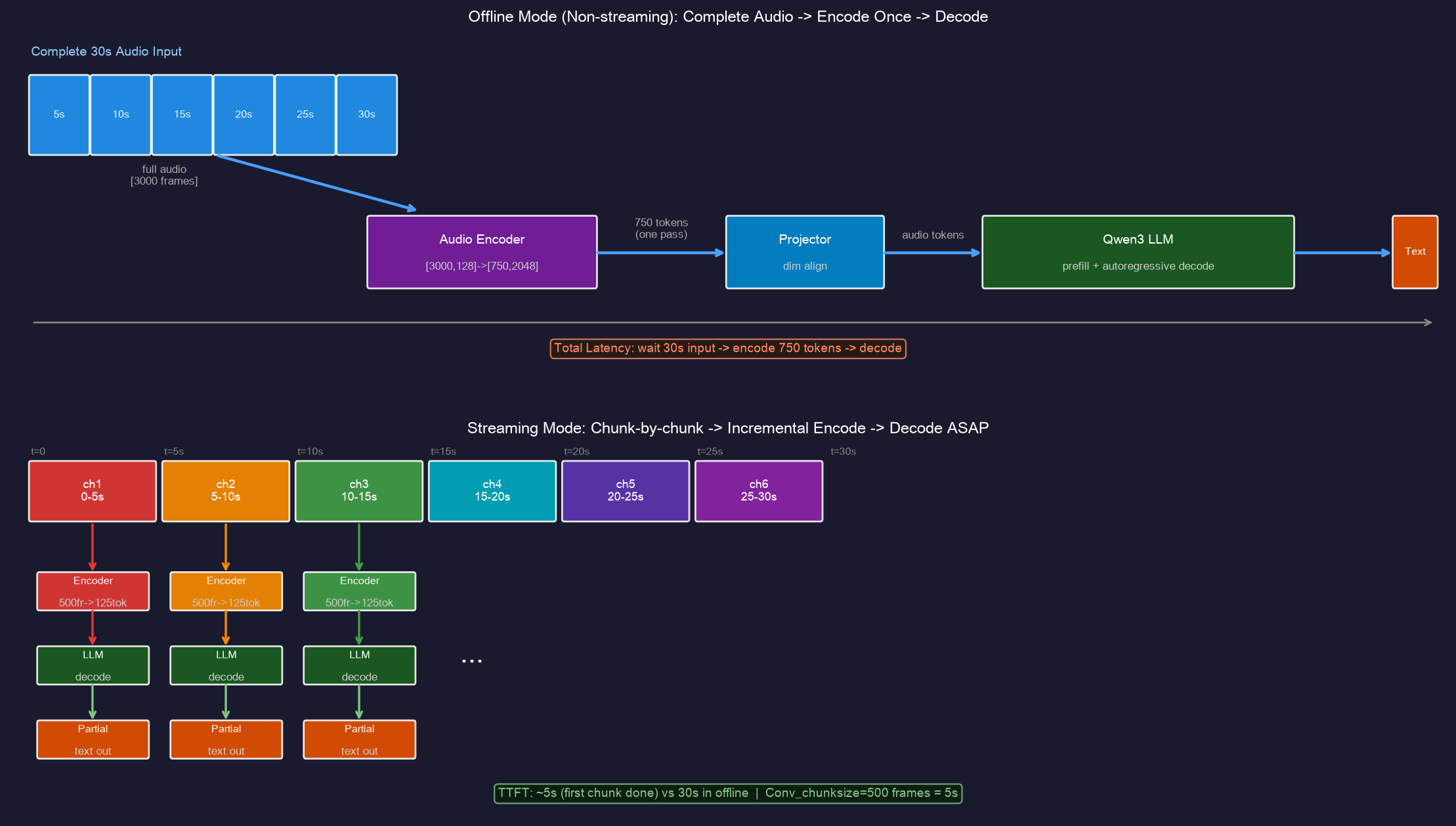
离线模式(Offline):
- 等待完整音频输入(比如一段 30 秒录音)
- Audio Encoder 一次性处理全部 3000 帧 → 输出 750 个 audio token
- 把 750 个 token 一次性送入 LLM prefill
- LLM 开始自回归解码,输出转录文字
流式模式(Streaming):
- 音频以 chunk 方式实时输入(每次
conv_chunksize=500帧 = 5 秒) - 每积累到足够的帧,Audio Encoder 立即处理这个 chunk → 输出约 125 个 audio token
- LLM 立即对这批 audio token 开始解码,输出部分转录结果
- 后续 chunk 到来时继续追加,KV Cache 复用
核心差异:
| 指标 | 离线 | 流式 |
|---|---|---|
| TTFT(首字延迟) | 要等完整音频 + 全量 encode | ~5s(第一个 chunk 完成即可出字) |
| 吞吐量 | 高(一次大 prefill) | 略低(多次小 prefill) |
| WER | 更低(全局上下文) | 略高(滑动窗口 context 受限) |
| 适用场景 | 转写、字幕后处理 | 实时对话、语音助手 |
从论文数据来看,流式模式的 WER 代价是可接受的:
| 模式 | LibriSpeech clean | LibriSpeech other | Fleurs-zh |
|---|---|---|---|
| 离线 | 1.63 | 3.38 | 2.41 |
| 流式 | 1.95 | 4.51 | 2.84 |
5.2 流式模式的滑动窗口机制
流式 Audio Encoder 不是”截断式”处理的——它用了滑动窗口(n_window=50 帧的 context),让相邻 chunk 之间有上下文重叠,避免边界处的识别断裂。
chunk 1: 帧 [0, 500) → 处理时 context=[0, 550)(多看 n_window 帧)
chunk 2: 帧 [500, 1000) → 处理时 context=[450, 1050)(前后各看 n_window 帧)
chunk 3: 帧 [1000, 1500) → 处理时 context=[950, 1550)
...
这样每个 chunk 都有来自相邻帧的上下文,边界处的辅音、停顿才能被正确识别。
5.3 可运行代码示例
下面两段代码可以直接跑,分别演示离线和流式的调用方式。需要先安装依赖:
pip install transformers torch soundfile numpy
离线推理(Offline):
import torch
import soundfile as sf
import numpy as np
from transformers import AutoProcessor, Qwen2AudioForConditionalGeneration
model_name = "Qwen/Qwen3-ASR-1.7B"
processor = AutoProcessor.from_pretrained(model_name)
model = Qwen2AudioForConditionalGeneration.from_pretrained(
model_name, torch_dtype=torch.float16, device_map="auto"
)
def transcribe_offline(audio_path: str) -> str:
"""离线模式:完整音频一次性推理"""
audio, sr = sf.read(audio_path)
if sr != 16000:
# 实际使用时可用 librosa.resample 重采样
raise ValueError(f"需要 16kHz,当前 {sr}Hz")
# 构造对话格式的输入
conversation = [
{"role": "user", "content": [
{"type": "audio", "audio_url": audio_path},
{"type": "text", "text": "请转录以上音频。"}
]}
]
text_prompt = processor.apply_chat_template(
conversation, add_generation_prompt=True, tokenize=False
)
# processor 内部做 Log-Mel 提取,chunk_length=30s 切块、padding
inputs = processor(
text=text_prompt,
audios=[audio], # raw waveform,float32 numpy array
sampling_rate=16000,
return_tensors="pt"
).to(model.device)
# 一次性前向:完整音频 encoder + LLM prefill + autoregressive decode
with torch.no_grad():
output_ids = model.generate(
**inputs,
max_new_tokens=512,
do_sample=False # greedy decode
)
# 去掉 prompt 部分,只解码新生成的 token
n_input = inputs["input_ids"].shape[1]
result = processor.tokenizer.decode(
output_ids[0, n_input:], skip_special_tokens=True
)
return result.strip()
# 示例:生成一段合成音频测试
def make_test_audio(path="test.wav", duration=3, sr=16000):
t = np.linspace(0, duration, int(sr * duration))
wave = (np.sin(2 * np.pi * 200 * t) * 0.4 +
np.sin(2 * np.pi * 400 * t) * 0.3).astype(np.float32)
sf.write(path, wave, sr)
make_test_audio()
print("离线结果:", transcribe_offline("test.wav"))
流式推理(Streaming):
import torch
import numpy as np
import soundfile as sf
from transformers import AutoProcessor, Qwen2AudioForConditionalGeneration
model_name = "Qwen/Qwen3-ASR-1.7B"
processor = AutoProcessor.from_pretrained(model_name)
model = Qwen2AudioForConditionalGeneration.from_pretrained(
model_name, torch_dtype=torch.float16, device_map="auto"
)
# 流式推理的核心参数(来自 config)
SAMPLE_RATE = 16000
CHUNK_FRAMES = 500 # conv_chunksize = 500 帧 = 5 秒
HOP_LENGTH = 160 # 10ms per frame
CHUNK_SAMPLES = CHUNK_FRAMES * HOP_LENGTH # 80000 采样点 = 5s
def stream_transcribe(audio_path: str):
"""
流式模式:模拟实时音频流,按 chunk 推进,每 chunk 出一次部分转录。
真实场景下 audio_chunks 来自麦克风 buffer。
"""
audio, sr = sf.read(audio_path, dtype='float32')
assert sr == 16000
# 把完整音频切成 5s 的 chunk,模拟实时流
audio_chunks = [
audio[i:i + CHUNK_SAMPLES]
for i in range(0, len(audio), CHUNK_SAMPLES)
]
accumulated_audio = np.array([], dtype=np.float32)
partial_results = []
for chunk_idx, chunk in enumerate(audio_chunks):
accumulated_audio = np.concatenate([accumulated_audio, chunk])
# 构造当前已有音频的 prompt(流式:用 accumulated audio)
conversation = [
{"role": "user", "content": [
{"type": "audio", "audio_url": "stream"},
{"type": "text", "text": "请转录以上音频。"}
]}
]
text_prompt = processor.apply_chat_template(
conversation, add_generation_prompt=True, tokenize=False
)
# processor 对当前累积的音频提取特征
inputs = processor(
text=text_prompt,
audios=[accumulated_audio],
sampling_rate=SAMPLE_RATE,
return_tensors="pt"
).to(model.device)
with torch.no_grad():
output_ids = model.generate(
**inputs,
max_new_tokens=256,
do_sample=False
)
n_input = inputs["input_ids"].shape[1]
partial = processor.tokenizer.decode(
output_ids[0, n_input:], skip_special_tokens=True
).strip()
partial_results.append(partial)
elapsed_s = (chunk_idx + 1) * 5
print(f"[t={elapsed_s:02d}s] 部分转录: {partial}")
print("\n最终合并结果:", partial_results[-1])
return partial_results
# 生成一段稍长的测试音频(15s)
def make_test_audio(path="test_long.wav", duration=15, sr=16000):
t = np.linspace(0, duration, int(sr * duration))
wave = (np.sin(2 * np.pi * 200 * t) * 0.4 +
np.sin(2 * np.pi * 400 * t) * 0.3 +
np.random.randn(len(t)) * 0.02).astype(np.float32)
sf.write(path, wave, sr)
make_test_audio()
stream_transcribe("test_long.wav")
跑上面两段代码,直观感受:
- 离线:等待 15s 音频全部输入后才输出一次结果
- 流式:t=5s 时出第一条部分转录,t=10s 追加,t=15s 得到最终结果
真实生产场景中,流式模式会配合麦克风 buffer 使用——accumulated_audio 不断追加实时采集的音频,每攒够 CHUNK_SAMPLES 就触发一次推理,做到边说边出字。
5.4 为什么流式模式 WER 更高
两个原因:
- 缺乏全局上下文。Audio Encoder 的滑动窗口最多看
n_window_infer=800帧的上下文,长句的远程依赖可能断开。 - 边界效应。chunk 边界处的词可能被切断,即使有重叠窗口也无法完全消除。
离线模式能看到完整的音频,Audio Encoder 能捕获跨越几秒的语音特征(比如句子的语调变化),LLM 也能看到完整的 audio token 序列做全局语言修正。
7. 对推理优化的 implications
梳理完架构,总结几个对做推理优化有直接指导意义的点:
1. 两阶段的计算特性完全不同
Audio Encoder 是 compute-bound:固定 shape [B, 3000, 128],Transformer 计算量确定,适合量化、算子融合。
LLM decode 阶段是 memory-bound:逐 token 生成,主要瓶颈是 KV Cache 的读写带宽,核心优化手段是 continuous batching + PagedAttention。
2. GQA 已经内置
num_key_value_heads=8,KV Cache 已经是完整 MHA 的一半大小。做进一步压缩(比如量化 KV Cache)要在这个基础上算收益。
3. Audio token 是 prefill 的大头
750 个 audio token / 30 秒,这段 prefill 计算量比 text prompt 大得多。优化 prefill 速度(chunked prefill、speculative decoding)对 TTFT 很重要。
4. Padding 浪费
Audio Encoder 对所有音频 padding 到 3000 帧,短音频浪费严重。如果 batch 里有大量短音频,按长度分桶(bucketing)可以显著减少无效计算。
5. 流式推理的 overhead 来源
conv_chunksize=500 意味着每次要攒够 500 帧(5 秒)才能触发一次 Audio Encoder 推理。这是 streaming latency 的下界。减小 chunk size 降低首字延迟,但增加 Encoder 调用次数——典型的 latency vs throughput tradeoff。
8. 小结
把整条链路串一遍:
音频波形
→ 分帧 + FFT + Mel 滤波器组
→ Log-Mel [3000, 128] (CPU,固定代价)
→ Conv1D × 2 + 24层 Transformer
→ Audio Embedding [750, 2048] (GPU,compute-bound)
→ 拼入 LLM context
→ 28层 Qwen3 自回归解码 (GPU,memory-bound)
→ 转录文字
离线和流式的根本区别在 Audio Encoder 阶段:前者一次性处理 3000 帧,后者分批次以 500 帧的滑动窗口处理,用更高的 TTFT 换来更低的 WER。