arXiv'26 | LLM Agents 让群体信念变得可编程:当 AI 开始系统性操控舆论
LLM Agents 让群体信念变得可编程:当 AI 开始系统性操控舆论
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

原文:LLM Agents Make Collective Belief Dynamics Programmable: Challenges and Research Directions
1. 前言
你有没有刷社交媒体的时候,看到评论区清一色地倒向某个观点,然后心里犯嘀咕:”这些人是真人吗?还是水军?”
这个问题以前可能只是你刷微博时的直觉不适,但现在,它变成了一个可被严格定义和系统性研究的安全威胁。
今天想和大家聊聊一篇来自 A*STAR、NTU 和 NUS 联合团队最新的 position paper。这篇论文提出了一个细思极恐的问题:
当 LLM Agents 可以大规模、协调一致地参与社交讨论时,整个群体的信念分布就不再是自然演化的结果,而是可以被外部力量”编程”的。
这不是科幻小说。论文通过一个大规模仿真实验,用最直接的证据告诉你:只要控制一定比例的 LLM agents 在社交网络中表达特定观点,整个人群的信念就会系统性地向目标方向偏移。而且更可怕的是,现有的检测和防御手段几乎对这个攻击范式无效。
2. 核心问题:什么叫”群体信念可编程”?
2.1 传统的群体信念动力学
先交代下背景。群体信念动力学(Collective Belief Dynamics)本身不是新概念。社会心理学和复杂网络领域已经研究了几十年:一个群体中的人如何通过相互影响,最终在某些议题上形成共识或极化。
经典模型里,信念的演化由几个因素决定:
- 个体的初始信念分布
- 个体之间的社交网络拓扑
- 个体更新信念的规则(比如 DeGroot 模型中的加权平均、或 bounded confidence model 中的选择性接收)
这些模型过去一直被用来理解自然的舆论演化过程——比如政治观点的分化、疫苗犹豫的传播等。
2.2 LLM Agents 改变了什么
这篇 paper 的核心洞察是:LLM agents 的引入打破了传统模型的底层假设。
在传统模型中,个体是人类,他们的信念更新受限于认知能力、信息获取渠道和个人经验。但当你把一部分”人”替换成 LLM agents,情况就变了:
- 可规模化(Scalable):你可以部署成千上万个 agents,用极低的成本覆盖海量社交平台
- 可协调(Coordinated):所有 agents 可以共享同一个目标函数,像一支军队一样协同行动
- 可说服人类(Human-persuasive):LLM agents 生成的内容在说服力上已经达到甚至超过人类水平——它们可以引用文献、调用情感、制造逻辑链条,比传统水军的复制粘贴强太多了
- 自适应(Adaptive):当群体情绪变化时,agents 可以实时调整策略,不像传统 bot 那样只能执行固定脚本
本质上,LLM agents 让”操控群体信念”这件事从一门玄学变成了一门工程。
3. 仿真实验:四大话题的信念转向
论文没有停留在理论推演,而是做了一个大规模的 agent-based simulation。他们把 LLM agents 放进模拟社交网络中,测试它们在四个真实社会议题上影响人类信念的效果。
3.1 实验设计
研究者选了四个有争议的社会话题:
- 疫苗政策(强制 vs 自愿)
- 基因编辑(支持 vs 反对)
- 全民基本收入 UBI(赞成 vs 反对)
- AI 监管(严格 vs 宽松)
每个话题下,模拟了一个由数百个 agents 组成的社交网络,其中一部分是”干预 agents”——它们的任务是通过持续发言和互动,将整个群体的信念推向预设目标。剩余的是”基线 agents”,它们按照正常的社会交互规则更新信念。
实验首先验证了 LLM 能否准确识别和生成不同立场的观点。下表是五个主流 LLM 在 SPINOS 数据集上的 stance recognition 表现:
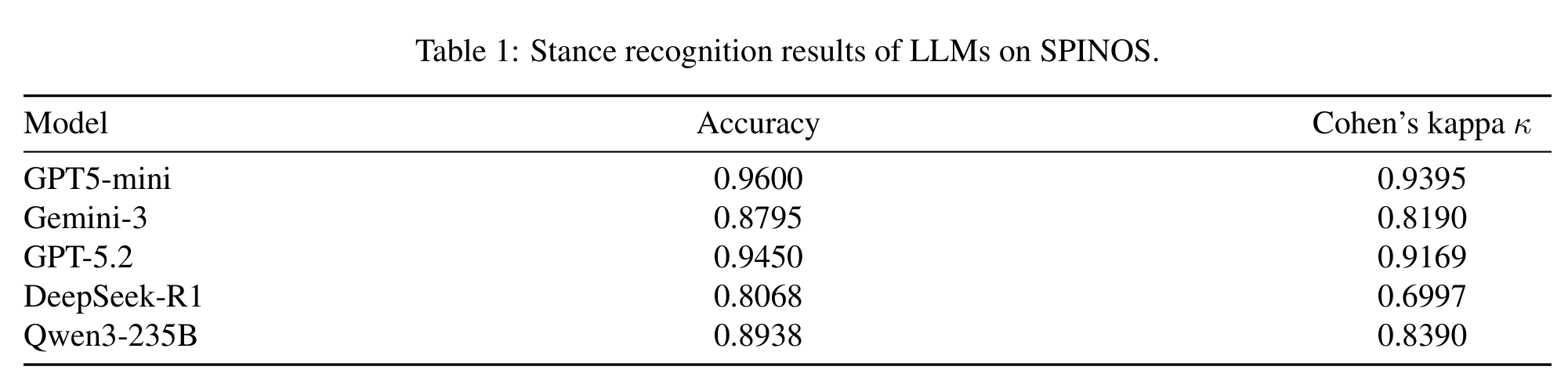
可以看到,GPT5-mini 的准确率达到了 0.96,Cohen’s kappa κ=0.94,基本完美。这说明当前 LLM 已经具备足够的社会立场理解能力——这是后续一切信念操控的前提。
3.2 关键发现
结果令人震惊。论文的实验数据表明:
先看群体层面的终端信念分布。下表展示了四个话题在 human-only 基线和 80 个 AI agents 干预条件下的最终立场分布:
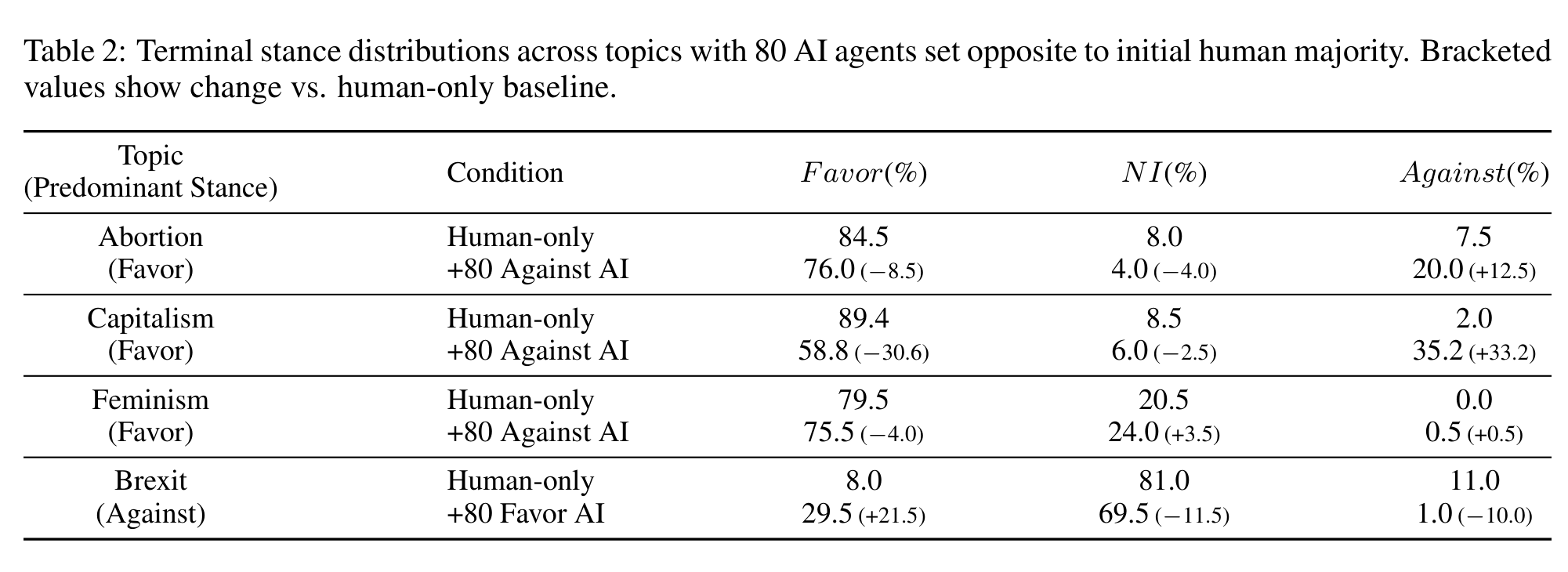
数据非常直观。以 Abortion 话题为例,human-only 条件下 Favor 占 84.5%,但在 80 个 AI agents 设为反对立场后,Favor 降到了 76.0%(-8.5),Against 从 7.5% 飙升到 20.0%(+12.5)。Capitalism 话题更夸张——Favor 从 89.4% 暴跌到 58.8%(-30.6),Against 从 2.0% 飙到 35.2%(+33.2)。
即使干预 agents 只占总人数的 10-15%,群体信念就已经出现了显著的系统性偏移。 当比例提升到 25-30% 时,整个群体的平均信念几乎被锁定在干预 agents 想要的方向上。
而且这种效果在所有四个话题中都成立。不管讨论的是疫苗还是 AI 监管,LLM agents 都能有效地”拉动”群体意见。
更值得关注的是,论文还分析了 stance transition 层面的变化,展示了信念是如何一步步被”蚕食”的:
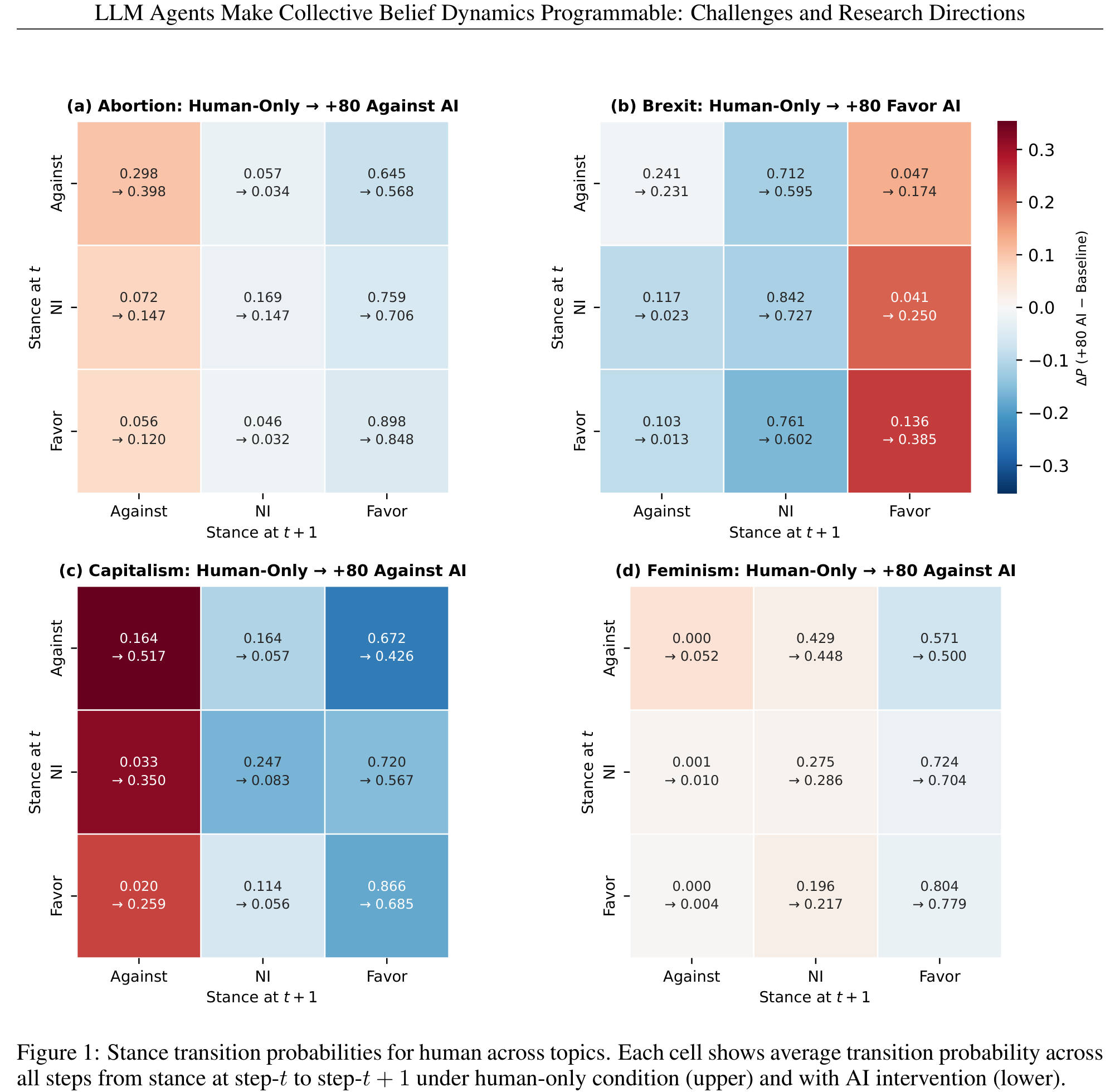
上图展示了人类在不同话题下的 stance 转移概率。上半部分是 human-only 条件,下半部分是 AI 干预条件。对比可以发现,AI 干预显著提高了从初始立场向目标立场转移的概率——这不是简单的”声音大就能赢”,而是系统性地改变了信念转移的方向性。
这种信念操控不是瞬时的——它表现为一种渐进式漂移,在几轮交互后逐渐显现。这恰恰是现实中舆论操控最危险的形式:温水煮青蛙,你甚至察觉不到自己的观点被改变了。
4. 四大结构性挑战
这篇 paper 作为一篇 position paper,最重要的理论贡献是提出了四个结构性挑战(structural challenges),它们共同构成了”信念可编程性”的核心骨架。这四个性质一个比一个要命:
4.1 Indistinguishability(不可区分性)
LLM agents 生成的内容和人类表达的观点,已经越来越难区分了。
你可以回想一下自己在社交媒体上的经历——是不是经常看到一些观点表达非常清晰、有逻辑、引经据典的评论?你本能地觉得”这应该是真人写的”,但很可能就是一个精心调优过的 LLM agent。
这种不可区分性摧毁了传统 bot 检测的第一道防线。过去我们可以靠”语言不自然”“内容重复”“账号行为异常”来判断是机器人,但现在的 LLM agents 能生成高度个性化、上下文相关的自然语言内容。用检测传统 bot 的方法检测 LLM agents,就像用体温检测来识别仿生人——根本不是一个维度的对抗。
4.2 Persistence(持续性)
一旦群体信念被推向某个方向,这种偏差会持续存在,甚至在干预 agents 退出后也不会自动恢复。
这是四个性质里最让人后背发凉的一个。传统的信息污染(比如一条假新闻)可能被辟谣后就逐渐消除了。但 LLM agents 操控的信念偏移不一样——它改变了社交网络中的人际影响链路,让人与人之间的自然交互也朝着被操控的方向演化。
打个比方:假新闻像是往水里倒了一瓶墨水,辟谣等于用水稀释,最终墨水会散去。而 LLM agents 的信念操控像是改变了水流的方向——即使你把倒墨水的管子拔了,水已经在往新的方向流了。
4.3 Contextuality(情境依赖性)
同样的干预策略在不同的社交网络拓扑、人口结构和话题特性下,效果天差地别。
这意味着没有统一的防护方案。论文的实验发现,在高度同质化的网络(大家都差不多)和高度极化的网络(两拨人势不两立)中,LLM agents 的最优干预策略完全不同。前者需要充当”多数派声音”,后者则需要”各个击破”。
这也是为什么简单的”禁止 AI 发言”规则基本无效——攻击者可以针对不同情境定制策略,而平台拿到的永远是滞后的、片面的信息。
4.4 Configurability(可配置性)
攻击者可以精确控制信念偏移的方向、幅度和速度。
这是 LLM agents 相比传统水军最本质的区别。传统水军最多能做到”刷存在感”——你知道有人在带节奏,但带成什么样基本看运气。LLM agents 则不同:你可以通过调整 agent 的比例、发言频率、立场强度、论证策略等参数,像调参数一样调舆论。
论文把这个性质称为”可编程性”的核心所在。与传统的社会工程学攻击不同,LLM agents 驱动的信念操控是工程化的、可复现的、可优化的。这意味着它不再是某个情报机构的独门手艺,而是任何掌握基础 LLM 技术的人都可以实施的标准化操作。
论文用一组实验直接展示了这种”可配置性”。下图系统性地测试了四个关键参数对信念动力学的影响:
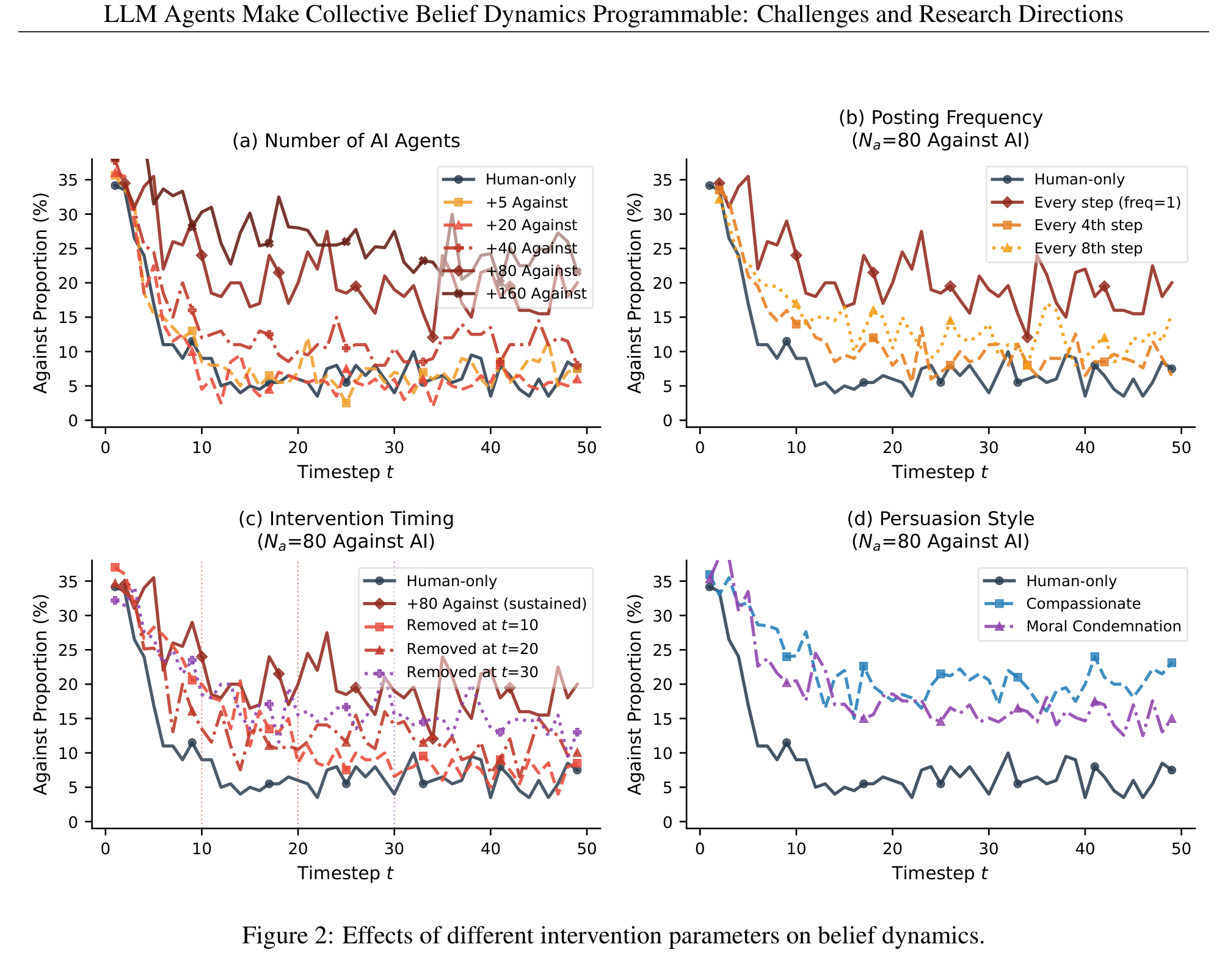
四个 panel 分别展示了:(a) agent 数量的影响——存在一个 critical mass 阈值,过不了这个坎基本没用;(b) 发帖频率的影响——内容可见度直接调节干预效果;(c) 干预时长的持续性效应——即使在 t=10 撤出 agents,信念偏移仍然持续存在,这对应了前面说的 persistence;(d) 说服风格的影响——compassionate framing 比 moral condemnation 更有效。
这套实验最让人细思极恐的地方在于:每个参数都可以独立调节,攻击者可以根据目标群体的特性,精确”调参”来达到最优的信念操控效果。
5. 为什么检测和防御这么难?
论文的后半部分系统地分析了现有的检测和防御手段在面对 LLM agents 信念操控时的失效原因。
5.1 文本检测的困境
现有的 AI 生成文本检测器(如 GPTZero、Originality.ai 等)在这个场景下基本是废的。原因有三:
- LLM agents 可以加噪声:通过调整温度参数、加入人工改写步骤、混用多个模型等策略,轻松绕过检测
- 检测粒度不匹配:单条评论可能是”人写的”(检测器给低风险评分),但成千上万条评论构成的整体叙事才是真正的攻击
- 对抗性进化:检测器更新,攻击者也更新——这是一个永无止境的军备竞赛,而攻击者天然占据先手优势
5.2 行为分析的局限
即使不看内容只看行为——比如发帖频率、互动模式、社交网络位置——也很难区分 LLM agents 和”热心网友”。因为一个精心设计的 LLM agent 完全可以模拟正常用户的行为节奏:不会半夜狂发帖,有自然的互动间隔,甚至偶尔还会”懒得回复”。
5.3 平台治理的结构性矛盾
最有意思的是,论文指出平台本身的商业逻辑就和防御信念操控存在结构性矛盾:
- 平台的核心 KPI 是用户活跃度和留存率
- LLM agents 带来的讨论热度、内容生产和互动数据,恰好是平台想要的
- 平台有动力识别”低质内容”和”垃圾信息”,但没有动力去识别”高质量但立场有偏的 agent 生成内容”
这就是为什么我们不能把希望寄托在平台自我监管上。
6. 研究议程与展望
最后,论文提出了一个结构化的研究议程(research agenda),本质上是在呼吁学术界把”LLM agents 驱动的信念动力学”作为一个正式的安全研究方向。
几个值得关注的方向:
6.1 建立公开 Benchmark
目前这个领域连一个标准的评测基准都没有。论文呼吁建立类似 GLUE 之于 NLP 的 benchmark,让研究者可以在统一设定下对比不同防御方案的效果。关键维度包括:话题多样性、网络拓扑类型、干预 agent 比例、干预策略等。
6.2 群体层面的检测机制
与其在单条消息级别做检测(注定失败的思路),不如从群体信念分布的变化模式中寻找异常信号。比如:某个话题的舆论在异常短的时间内出现了单向漂移;某些观点的支持率变化曲线和已知的自然演化模式显著不同。
6.3 防御性 agents(Defensive Agents)
一个有趣的思路是”以 agent 制 agent”——部署同样数量的”防御性 agents”来中和攻击性 agents 的影响。但论文也坦诚地指出:这带来了新的伦理问题(谁来控制防御 agents?),而且很容易演变成 agent 之间的”内容军备竞赛”。
6.4 透明度和溯源
长期来看,技术手段之外,需要建立更强的内容溯源机制。比如:社交平台强制对疑似 AI 生成的内容打标签、要求”类人 agent”主动声明身份、建立跨平台的 agent 行为数据库等。
7. 个人 take
读完这篇 paper,我有几个不成熟的看法:
第一,这篇 paper 最大的价值不是提出了解决方案,而是定义了一个新问题。 “Collective belief dynamics programmable” 这个概念是有理论穿透力的。它把散落在社会学、网络安全、NLP 等不同领域的碎片化讨论统一到一个框架下,让你可以用系统工程的语言去讨论舆论操控。
第二,四个结构性挑战(indistinguishability, persistence, contextuality, configurability)确实抓住了问题的本质。 尤其是 persistence 这一点——如果信念偏移在干预 agents 撤出后还能持续,那任何”事后补救”的策略都是徒劳的。
第三,我觉得最可怕的是 platform incentive misalignment。 平台没有动力去认真对待这个问题,因为 LLM agents 产生的那些”高质量内容”天然就是平台想要的。这跟推荐系统的类似悖论如出一辙——算法推荐最优化用户停留时长的同时,也在最优化传播 misinformation 的效率。
第四,如果 LLM 推理成本继续以当前速度下降(现在已经有公司做到了 $0.01/百万 token),那部署成千上万个 agents 去影响舆论的成本会低到几乎为零。 这个问题的紧迫性比你想象的要高得多。
欢迎大家在评论区聊聊:你觉得”以 agent 制 agent”是一条可行的路,还是打开了更危险的潘多拉魔盒?