ICML'26 | Transformer 真的需要三个投影矩阵吗?Q-K=V 让 KV Cache 直接砍半
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

Transformer 真的需要三个投影矩阵吗?Q-K=V 让 KV Cache 直接砍半
原文:Do Transformers Need Three Projections? Systematic Study of QKV Variants
1. 前言
你有没有想过,Transformer 里每个 attention head 都要算 Q、K、V 三个投影,这三个真的缺一不可吗?
CNN 用的是共享卷积核,SSM(Mamba)用的是统一的状态表示,为什么独独 Transformer 非得维护三份独立的投影矩阵?要知道,在 LLM 推理的时候,K 和 V 需要全量缓存(KV Cache),这玩意儿在长上下文场景下是真正的显存杀手——32k context 下一个用户就要吃掉 2.6 GB。
今天想和大家聊聊这篇 ICML 2026 的工作。作者提了一个很朴素的问题:如果我们让 K 和 V 共享同一个投影矩阵(K=V),会怎样? 答案让人惊喜——perplexity 只涨了 3.1%,但 KV Cache 直接砍半。更狠的是,这个方法和 GQA/MQA 正交,两者叠加可以把 cache 压到只剩 3.1%。
2. 核心思路:哪个投影矩阵可以省?
标准 attention 的公式大家都熟:
\[A = \text{Softmax}(\alpha \cdot Q K^T) V\]其中 $Q = XW_q$,$K = XW_k$,$V = XW_v$,三个投影矩阵各管各的。作者系统性地测试了三种”省矩阵”的方案:
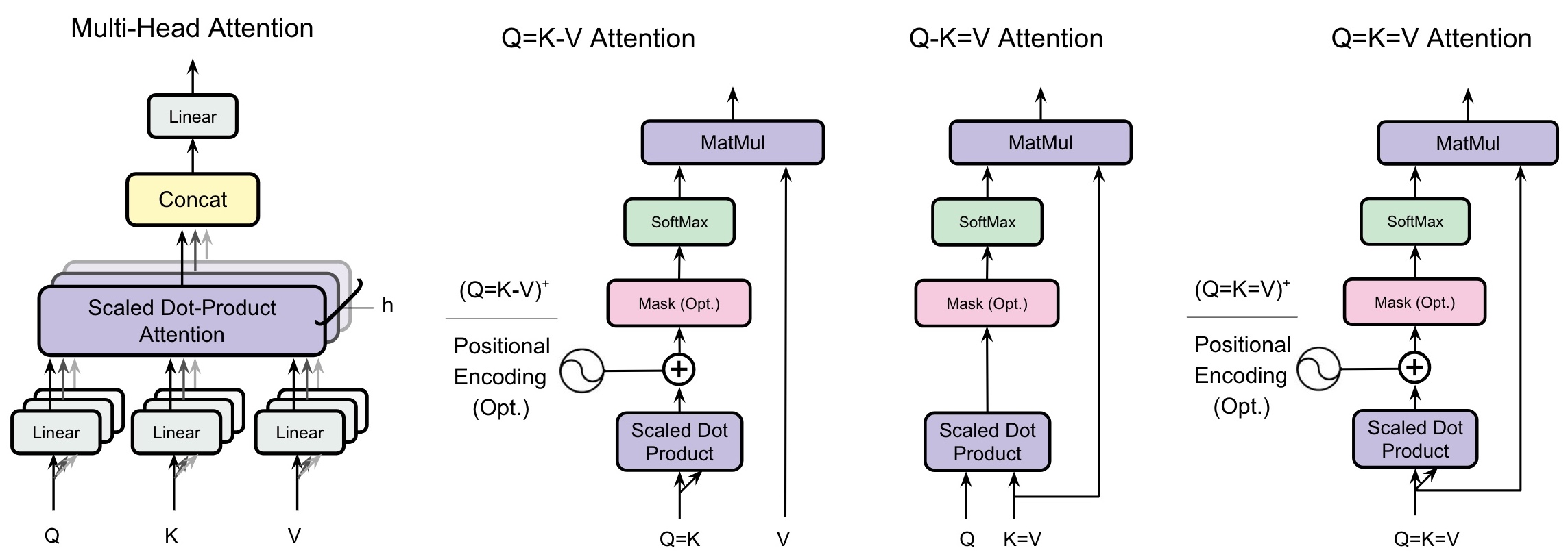
方案 1:Q=K-V(合并 Q 和 K,保留独立 V)
\[A = \text{Softmax}(\alpha \cdot K K^T) V\]问题:$KK^T$ 是对称矩阵,attention map 变成对称的了。对于需要因果关系的语言模型来说,方向性被破坏了。
方案 2:Q-K=V(保留独立 Q,合并 K 和 V)
\[A = \text{Softmax}(\alpha \cdot Q K^T) K\]注意这里 V 直接用 K 代替。$QK^T$ 仍然是非对称的,attention 的方向性完全保留。
方案 3:Q=K=V(三合一,只有一个投影矩阵)
\[A = \text{Softmax}(\alpha \cdot K K^T) K\]最极端的简化——既对称又共享 value,约束太强。
直觉上哪个能行? 想想 KV Cache 的工作原理:推理时需要缓存每个 token 的 K 和 V 向量。如果 K=V(方案 2),那我们只需要缓存 K 就行了——KV Cache 直接减半。而方案 1(Q=K)虽然也省了一个矩阵,但推理时还是得分别存 K 和 V,没有任何推理收益。
这也是整个工作最核心的 insight:不是所有投影共享都能带来推理加速,只有共享 K 和 V 才能直接转化为 KV Cache 的减少。
3. 为什么 K=V 能 work?
作者分析了训练好的标准 QKV 模型,发现一个有意思的现象:
- K 和 V 投影矩阵的 cosine similarity 高达 0.73
- K 和 V 的 effective rank 也很接近(687 vs 702,总维度 1024)
- 相比之下,Q 和 K 的 cosine similarity 只有 0.42,Q 和 V 更低只有 0.31
说人话:K 和 V 本来就在学很相似的表示空间。强制让它们共享一个投影矩阵,只是把一个已经存在的”软约束”变成了”硬约束”,质量损失自然很小。
而 Q 和 K 的表示空间差异大得多——Q 负责”我要查什么”,K 负责”我是什么”,这两个角色本质上需要不对称性来支撑 attention 的方向性。合并 Q 和 K 会把 attention map 变对称,对因果语言模型是致命的。
4. 实验:从 300M 到 1.2B 全面验证
作者用 SlimPajama 数据集训练了 300M 和 1.2B 参数的 GPT 风格模型(10B tokens),实验非常扎实。
4.1 300M 模型主实验
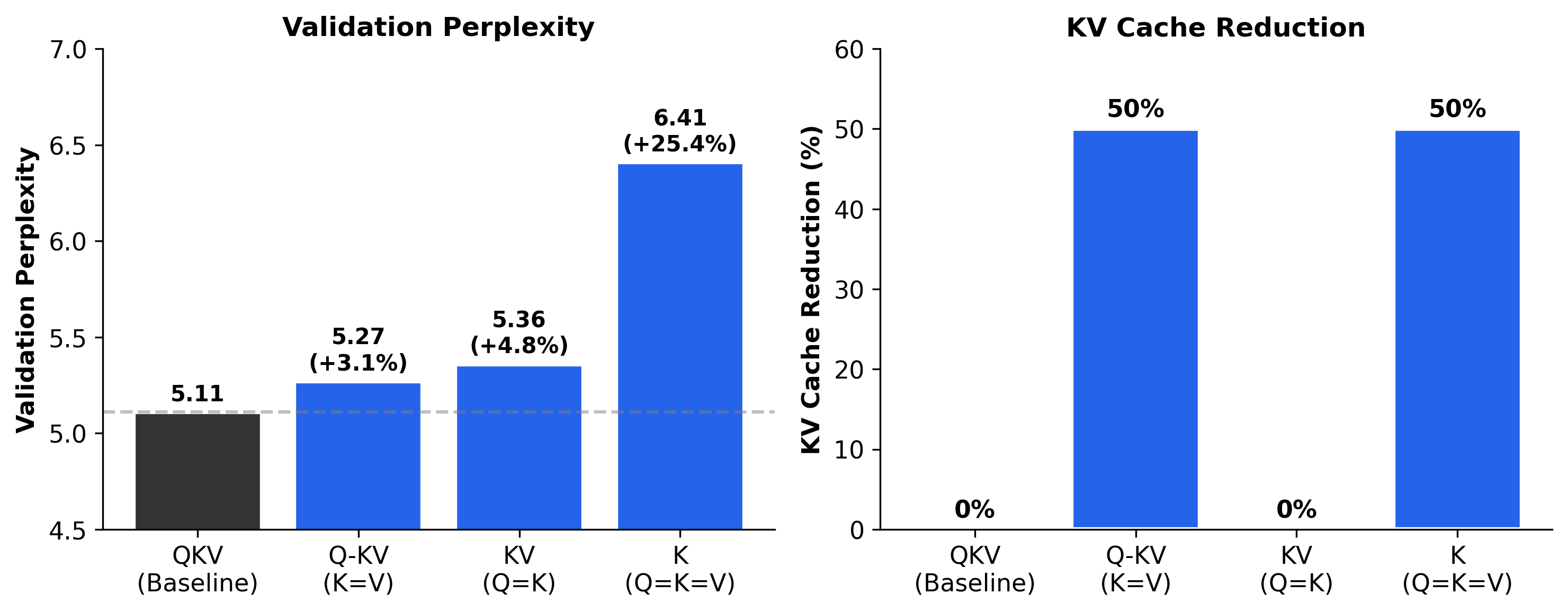
| 模型 | Val PPL | PPL 退化 | KV Cache 缩减 |
|---|---|---|---|
| QKV(baseline) | 5.11 | — | 0% |
| Q-K=V | 5.27 | +3.1% | 50% |
| Q=K-V | 5.36 | +4.9% | 0% |
| Q=K=V | 6.41 | +25.4% | 50% |
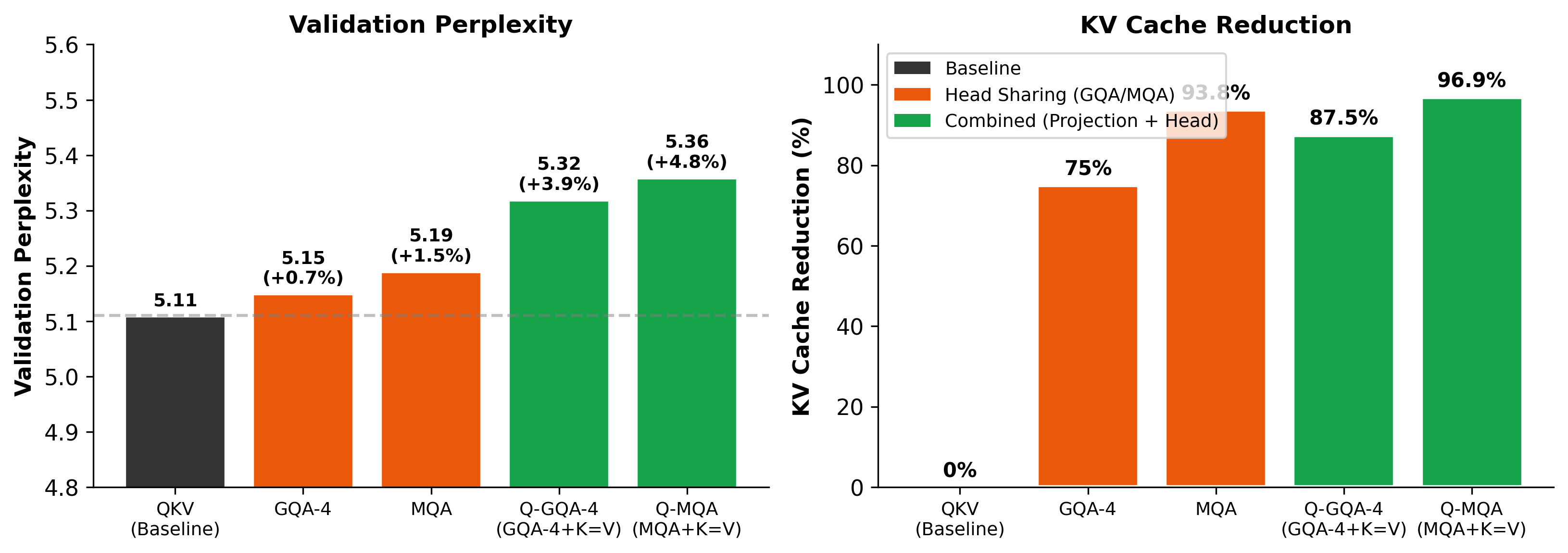
| GQA-4 | 5.15 | +0.7% | 75% |
| MQA | 5.19 | +1.5% | 93.8% |
| Q-GQA-4 | 5.32 | +3.9% | 87.5% |
| Q-MQA | 5.36 | +4.8% | 96.9% |
几个关键发现:
- Q-K=V 是投影共享方案里的明确赢家:3.1% 的 perplexity 退化换来 50% 的 cache 缩减
- Q=K-V 看起来质量还行(+4.9%),但没有任何推理收益——因为它还是得缓存 K 和 V
- Q=K=V 直接崩了(+25.4%),三合一太激进
- 投影共享和 head sharing 正交且可叠加:Q-K=V + MQA 直接把 cache 压到只剩 3.1%
4.2 1.2B 模型验证
| 模型 | Val PPL | PPL 退化 | KV Cache (32K ctx) |
|---|---|---|---|
| QKV | 5.004 | — | 5,900 MB |
| Q-K=V | 5.128 | +2.48% | 2,950 MB |
| GQA-8 | 5.030 | +0.52% | 1,408 MB |
| MQA | 5.057 | +1.06% | 176 MB |
| Q-GQA-8 | 5.158 | +3.08% | 704 MB |
| Q-MQA | 5.212 | +4.16% | 88 MB |
1.2B 的结果更让人兴奋——Q-K=V 的退化从 300M 的 3.1% 降到了 2.48%,模型越大对投影约束越鲁棒。如果这个趋势在 7B+ 继续保持,那投影共享对大规模生产模型就更有吸引力了。
Q-MQA 的数字尤其夸张:只用 88 MB 的 KV Cache 就能服务 32K context,相比 QKV baseline 的 5.9 GB 压缩了 67 倍。对 batch=32 的并发场景,从 189 GB 降到 2.8 GB——这是”能不能跑”和”跑不起来”的区别。
4.3 Downstream 任务不掉点
更实用的发现:虽然 Q-K=V 的 perplexity 比 baseline 差了 2.48%,但在 5-shot downstream 评测(HellaSwag、PIQA、ARC 等)上,平均准确率只掉了 0.41%(35.99% vs 36.40%)。Perplexity 的小幅退化并没有转化为下游任务上的等比损失。
5. Pareto 前沿:投影共享填补了效率-质量的空白
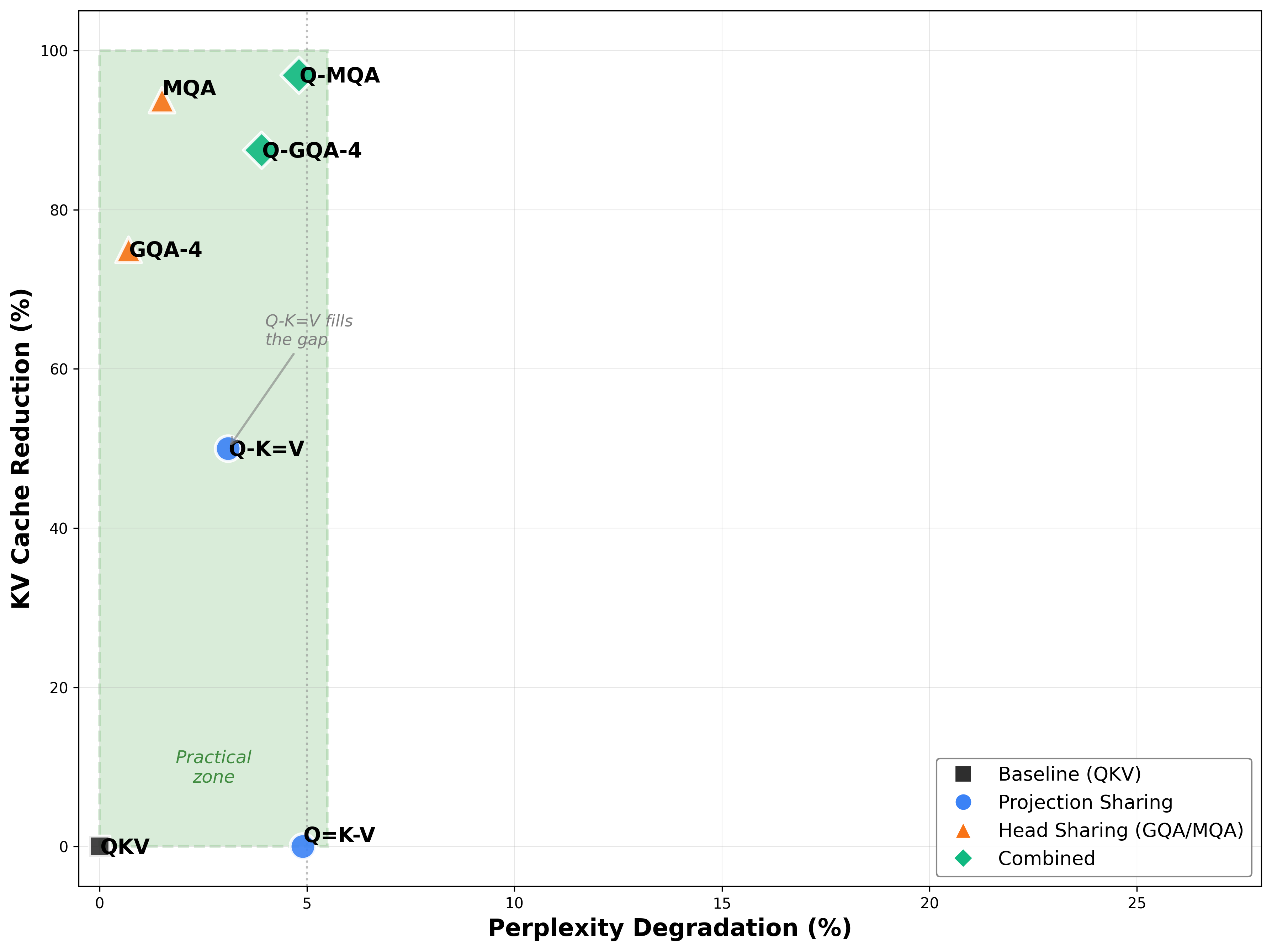
这张图把所有方案放在一起看就很清楚了:
- GQA/MQA 在右上角——高 cache 压缩、低质量损失
- Q-K=V 填补了 QKV baseline 和 GQA 之间的空白——提供了一个 50% cache reduction 的中间选项
- 组合方案(Q-GQA、Q-MQA)进一步推高了效率前沿
作者也给出了部署建议:
| 场景 | 推荐方案 | Cache 缩减 | PPL 退化 |
|---|---|---|---|
| 云端(质量优先) | GQA-4 | 75% | +0.7% |
| 边缘(平衡) | Q-K=V | 50% | +3.1% |
| 边缘(激进) | Q-GQA-4 | 87.5% | +3.9% |
| IoT/移动端 | Q-MQA | 96.9% | +4.8% |
6. 训练曲线稳不稳?
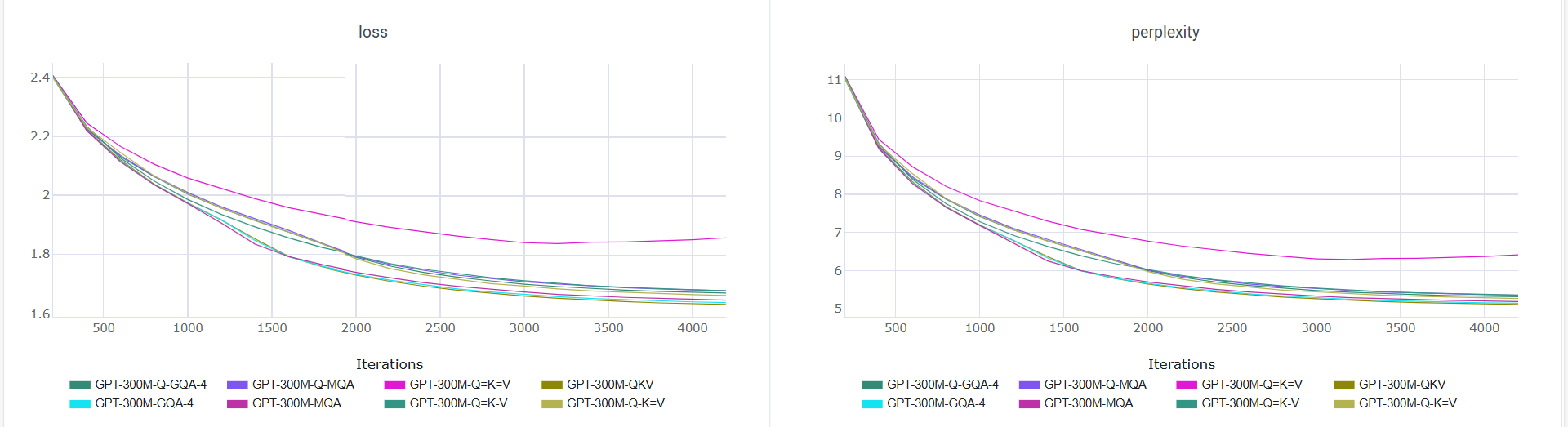
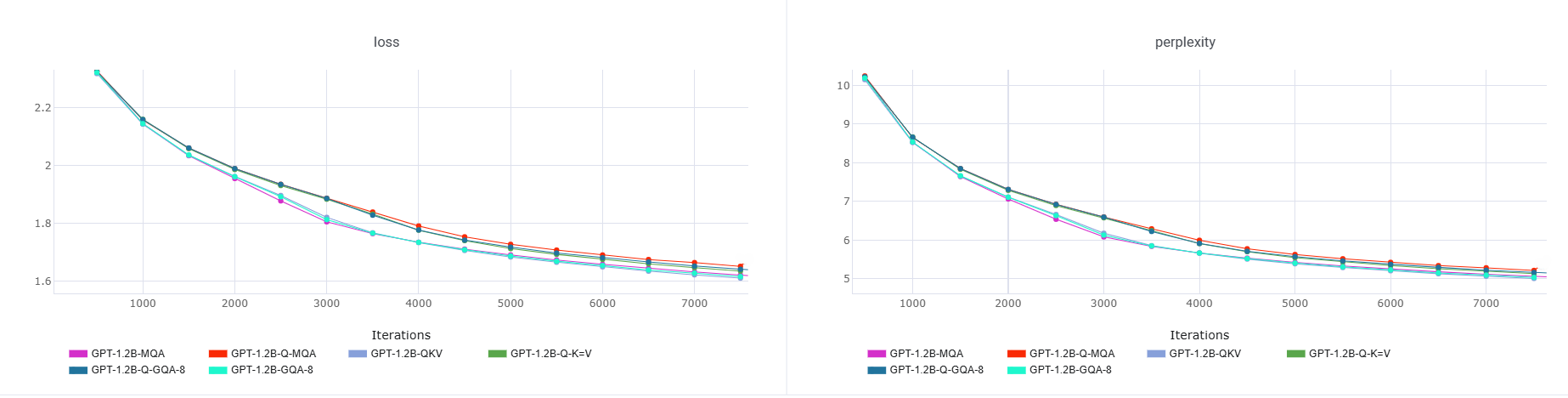
值得一提的是所有变体训练都很稳定——不需要特殊的初始化、学习率调度或架构修改,直接把 attention 里的投影矩阵改一下就行。训练速度也基本没差(423k-460k tokens/s),Q=K=V 因为少算了投影甚至稍微快一点点。
7. 和 DeepSeek-V2 MLA 的区别
看到 K=V 你可能会想到 DeepSeek-V2 的 Multi-Head Latent Attention(MLA)。两者都是为了压 KV Cache,但路线完全不同:
- MLA:把 K 和 V 压缩到一个共享的低维 latent 向量,推理时再展开。K 和 V 功能上仍然独立,只是压缩了存储。代价是额外的 up-projection 参数。
- Q-K=V:直接硬约束 K=V,不需要额外参数,简单粗暴。
两者是正交的思路,理论上甚至可以组合——先用 MLA 压缩,再在压缩后的 latent 里做 K=V 共享。
8. 我的 take
这篇文章的亮点不是方法有多 fancy(让 K=V 这件事本身并不复杂),而是系统性地回答了一个基础问题:Transformer 的三个投影矩阵到底各自贡献了什么?
几个我觉得有意思的点:
-
V 的重要性被高估了。K 已经足够 rich 来同时承担”寻址”和”内容”两个角色。这和 He & Hofmann (ICLR 2024) 说 V 的角色没那么关键是一致的。
-
投影共享和 head sharing 是完全正交的优化轴。以前大家只在”减少 KV head 数量”这一个维度上使劲(GQA、MQA),这篇文章开辟了另一个维度。两者叠加的效果是乘法关系,不是加法。
-
这对已有模型可能有 fine-tuning 的意义。虽然论文是 from scratch 训练的,但既然预训练好的模型里 K 和 V 本身就高度相似(cosine similarity 0.73),那是不是可以 post-hoc 做 K=V merging + 少量 fine-tune?值得探索。
-
实际部署时的收益:32K context 下每用户省 1.31 GB,batch=32 省 42 GB,折算下来一年省 $72K 的 GPU 成本。这种数字对工程团队很有说服力。
总的来说,方法简单、实验扎实、insight 清晰。做 LLM 推理效率优化的同学建议读一读,尤其是同时做 serving 优化的。 把 Q-K=V 加到现有的 GQA 模型里可能是一个低成本高收益的事情。