UPenn & Meta | NF-CoT:当 LLM 的思维链不再是文字,而是连续概率流
插播:之前写的《动手学 AutoML》终于出版了,从 NAS 到超参优化都有覆盖,适合想系统入门 AutoML 的同学。好了广告结束,现在进入正题。

NF-CoT:当 LLM 的思维链不再是文字,而是连续概率流
1. 前言
你有没有想过一个问题:大模型在”思考”的时候,为什么非得一个字一个字把推理过程说出来?
Chain-of-Thought(CoT)确实让模型变聪明了,但代价也很离谱——每一步推理都必须变成人话才能继续。即使模型内部只是做了一个简单的语义更新,它也得把这个更新”翻译”成一串 token 输出到序列里,然后才能看到自己刚才在想什么。
这就好比:你做数学题时,每写一步草稿都要先把它翻译成完整的中文句子,才能继续往下算。效率当然低。
那有没有办法让模型在连续空间里”想”,想完了直接输出答案?这就是 latent reasoning(潜在推理)想做的事。但之前的 latent reasoning 方法各有各的问题——有的是确定性的(Coconut,没有概率分布,只有一条路径),有的需要迭代去噪(LaDiR,用 diffusion model,慢)。
今天介绍的这篇 NF-CoT,来自 UPenn + UC San Diego + Meta,给了一个很漂亮的解:用 Normalizing Flow 在 LLM 内部建模连续思维链的概率分布,既有精确的 likelihood,又能像普通 token 一样从左到右采样,还能复用 KV cache。代码推理任务上比 LaDiR 强 7%,推理速度快 1.92 倍。
2. 背景铺垫:CoT 的四种范式
在讲 NF-CoT 之前,先帮大家理清当前 CoT 推理的四种主流范式,如下图:
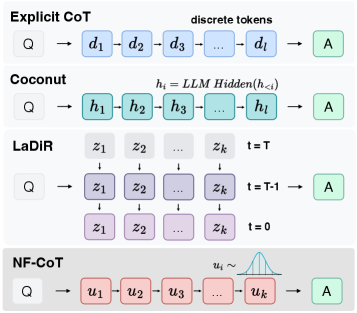
2.1 Explicit CoT(显式思维链)
最经典的做法,模型把推理过程逐步写出来:Q → d₁ → d₂ → … → dₗ → A。每个 d 都是离散 token,可以采样、打分、用 KV cache。但问题是:文本是一种信息密度极低的”思考”介质,很多内部计算用自然语言表达既冗余又不自然。
2.2 Coconut(确定性隐状态)
把推理过程压缩到 hidden state 里,直接回传给模型作为”上下文”。但问题是:这些 hidden state 是确定性的,不是概率分布。后续研究发现它实际上只走一条路径(single-threaded),不能表达多种推理策略。
2.3 LaDiR(Diffusion 去噪 latent)
用 VAE 把 CoT 编码成连续向量,再用 diffusion model 从噪声去噪生成 latent。有概率性,但需要 30 步迭代去噪,推理时很慢,也丧失了 LLM 原生的从左到右 likelihood 接口。
2.4 NF-CoT(本文)
用 Normalizing Flow 建模连续思维 token,在 LLM 内部从左到右自回归采样,有精确 likelihood。集四家之长:概率性 + 自回归 + KV cache 兼容 + 可精确计算 log-likelihood。
3. 先聊聊 Normalizing Flow 是什么
如果你对 Normalizing Flow(NF)不太熟,这里简单过一下核心思想。
NF 的本质是:用一系列可逆变换,把一个简单的分布(如标准高斯)映射到一个复杂的目标分布。因为变换可逆,你既可以从简单分布采样(生成),也可以把数据点映射回简单分布(计算 likelihood)。
具体来说,如果有一个可逆函数 f⁻¹ 把数据 y 映射到高斯噪声 z:
- z = f⁻¹(y; c)
-
p(y c) = p(z) · det J_{f⁻¹}(y;c)
其中 J 是 Jacobian 矩阵。只要 f 可逆且 Jacobian 行列式可算,你就同时拥有了:
-
精确 likelihood(可以直接算 log p(y c)) - 直接采样(从 z~N(0,I) 采样后通过 f 变换得到 y)
TARFlow / STARFlow 是近期把 NF 扩展到高维序列数据的工作,用 Transformer 做自回归 flow——每个位置的变换只依赖之前的位置,Jacobian 是三角矩阵(行列式好算),天然和 causal attention 兼容。
NF-CoT 正是把这种自回归 flow “植入”到 LLM 的 causal stream 里,让连续思维 token 拥有和文本 token 一样的建模接口。
4. NF-CoT 的架构与训练
如下图是 NF-CoT 的训练和推理流程:
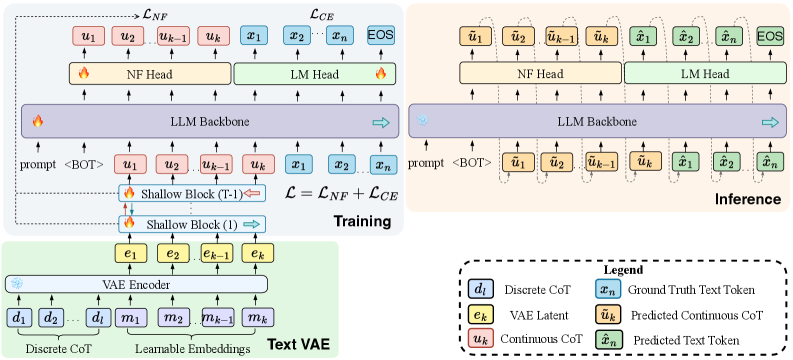
4.1 整体思路
NF-CoT 做了一件很巧妙的事:把 LLM 的 backbone 本身当作 deep autoregressive flow 的一部分。
具体来说,NF-CoT 包含两个 flow 组件:
-
Shallow Flow Blocks(浅层 flow 块):5 个轻量的 MetaBlock,负责把 VAE 编码空间 e 重新参数化到一个更适合自回归建模的空间 u。这是一个可逆映射 u = F(e; q)。
-
Deep Flow(深层 flow):就是 LLM backbone 本身。连续思维 u₁:K 被投影到 token embedding 维度后,跟答案 token 一起放进同一个 causal stream 处理。在连续思维位置,NF head 输出高斯参数 (μ, σ);在文本位置,LM head 输出 token logits。
4.2 训练目标
训练时,先用一个冻结的 VAE encoder 把显式 CoT 编码成连续 target e₁:K(64 个 latent slot,维度 2560)。然后优化一个联合目标:
L = λ_flow · L_flow + λ_text · L_text
- L_flow:NF 精确 likelihood,给连续思维分配概率
- L_text:标准 cross-entropy,给答案 token 分配概率
两个 loss 在同一个 causal forward pass 里算出来——flow head 打分连续思维,LM head 打分答案 token,共享一个 backbone。
4.3 两阶段训练课程
- Stage 1:冻住 LLM backbone,只训练 shallow flow blocks 和投影层。让 flow 组件先学会一个合理的 latent 接口。
- Stage 2:解冻所有参数,端到端联合训练。
Ablation 表明,跳过 Stage 1 直接端到端训练会掉 2-3 个点——因为 backbone 会被随机初始化的 flow 组件发出的”噪声梯度”干扰。
4.4 推理
推理时最优雅的地方:shallow flow blocks 完全不需要运行。模型直接在 u 空间从左到右采样:
- 给定 prompt q,从自回归高斯密度逐步采样连续思维 ũ₁:K
- 采样完成后,切换到 LM head,在同一个 causal stream 里继续解码答案 token
- KV cache 无缝复用——因为连续思维和答案 token 共享同一个 backbone
不需要迭代去噪(LaDiR 需要 30 步),不需要额外的 prefix recomputation。一次性从左到右过完。
5. 强化学习:在连续空间做 Policy Gradient
NF-CoT 的一个核心优势是连续思维有精确的 log-likelihood,这意味着可以直接对 latent 推理路径做 policy gradient 优化。
具体做法是 GRPO 风格的 RL:对每个 prompt 采样一组 trajectory (ũ, x̂),用执行奖励(代码通过单元测试 = reward 1,否则 = 0)计算 group-normalized advantage,然后用 PPO 的 clipped surrogate 更新:
- Token PPO:标准 token-level 策略梯度(更新 LM head 的答案解码)
- Latent PPO:sequence-level 策略梯度(更新 NF head 的连续思维采样)
关键发现:token-space GRPO 会导致 pass@k collapse(pass@1 提了,但 pass@128 不涨甚至下降),而 latent-space RL 不会。如下图对比:
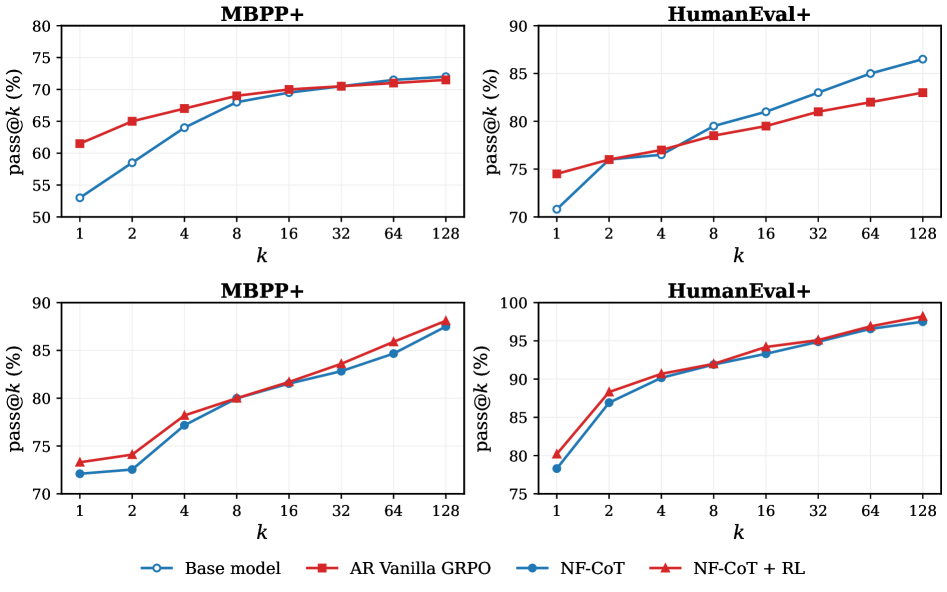
原因很直观:token-space RL 会让模型把概率集中在少数”正确模板”上;而 latent-space RL 在连续空间做优化,不同的 latent 采样可以 steer 到不同的实现策略,多样性被保留。
6. 实验结果
6.1 主结果:代码生成 pass@1
基于 Qwen3-8B-Base backbone,在 5 个代码生成 benchmark 上的结果:
| 方法 | MBPP | MBPP+ | HumanEval | HumanEval+ | LCB v6 | 平均 |
|---|---|---|---|---|---|---|
| Base Model | 60.5 | 53.8 | 78.2 | 68.6 | 17.7 | 55.8 |
| Standard SFT | 63.3 | 52.7 | 84.6 | 69.5 | - | - |
| LaDiR | 66.8 | 59.5 | 87.4 | 73.2 | 21.3 | 61.6 |
| NF-CoT (Unified) | 83.9 | 72.1 | 85.8 | 78.3 | 23.7 | 68.8 |
| NF-CoT + RL | 85.4 | 73.3 | 86.7 | 80.2 | 25.1 | 70.1 |
几个关键数字:
- NF-CoT (Unified) 比 base model +13.0%,比 LaDiR +7.1%
- 加上 RL 后进一步到 +14.3%
- 比 OlympicCoder(目前最强的开源自回归代码模型之一)还高 0.3%
6.2 pass@k 扩展性
如下图,NF-CoT 在 MBPP+ 上 pass@1 (72.1) 就已经 match 了 base model 的 pass@128 (72.0)。随着 k 增大,NF-CoT 的 pass@k 持续上升到 87.5(k=128),而 LaDiR 在 90.2 就开始饱和。
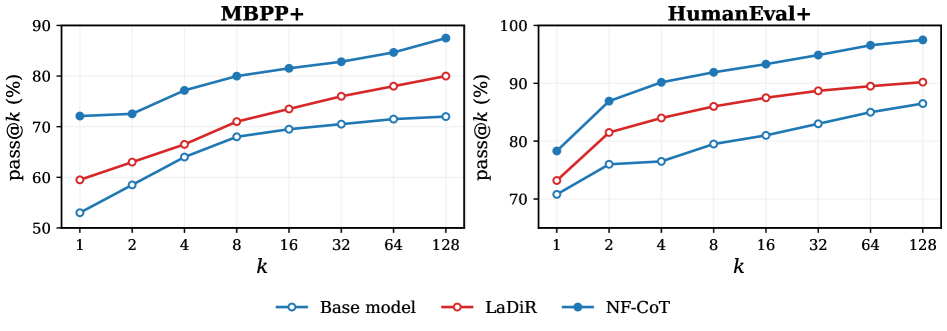
这说明 flow noise 采样确实产生了结构性多样的连续思维路径,而非坍缩到单一模式。
6.3 推理效率
这是我最关心的部分——都是在 HumanEval 上,16 candidates/problem,Qwen3-8B backbone,vLLM 解码:
| 方法 | Latent 生成 (s) | 解码 (s) | 总时间 (s) | FLOPs/样本 |
|---|---|---|---|---|
| NF-CoT (Unified) | 173.5 | 152.1 | 325.6 | 19.9T |
| LaDiR | 468.2 | 157.1 | 625.3 | 49.3T |
- Latent 生成快 2.70×(自回归一次 pass vs. 30 步去噪)
- 总体快 1.92×
- Per-sample compute 省 2.48×
训练同样显著:NF-CoT 比 LaDiR sample throughput 高 2.85×,total FLOPs 低 6.66×。
6.4 压缩率
64 个 latent token 平均编码 385 个文本 token 的 CoT,有效压缩率约 6.0×。也就是说,模型用 64 步连续”想法”做完了原本需要 385 个 token 才能表达的推理。
7. 一个有意思的分析:latent 空间是平滑的
论文做了一个 perturbation 实验:对采样出的连续思维加高斯噪声 ε,然后看 pass@1 怎么变。
当噪声 σ 从 0 涨到 3.0 时:
- cosine similarity 从 1.000 掉到 0.116(几乎正交了)
- 但 pass@1 只从 86.0 掉到 83.6(置信区间重叠)
- exact-text match 从 0.973 掉到 0.278
这说明什么?NF-CoT 学到的 latent 空间是局部平滑的。扰动改变的是生成程序的”表面形式”(用哪种算法实现、变量名怎么起),而不是”能否正确解题”。连续思维更像是分布式控制变量——控制走哪条路,而非能否到达目的地。
8. 我的 Take
作为一个做 LLM 推理效率的研究者,我觉得这篇工作有几个点值得关注:
1. 把 NF 和 LLM 统一到一个 causal stream 里是一个很优雅的设计。之前 latent reasoning 的方案要么跟 LLM 的推理接口割裂(diffusion 需要额外模型),要么损失概率性(Coconut 类方法)。NF-CoT 的统一架构让 latent 和 text 共享一个 backbone + KV cache,既干净又高效。
| 2. 精确 likelihood 打开了 RL 的大门。这是相比 LaDiR 的核心优势——有了 tractable log p(u | q),policy gradient 就可以直接作用于连续推理空间,而不只是答案 token。更重要的是,这种 RL 不会导致 pass@k collapse,这对 best-of-N 采样场景很关键。 |
3. 6x 压缩 + 2x 加速的组合很实用。64 个 latent token 替代 385 个文本 token,加上不需要迭代去噪,实际部署时对 KV cache 内存和推理延迟都有直接好处。
局限性也很明显:目前只在代码生成上验证,对数学推理、自然语言推理等场景还没有数据。另外 latent 不可解释——解码出来的”思维链”只能作为定性 probe,不能当作 faithful explanation。
总的来说,NF-CoT 展示了一条很有前景的路线:用概率生成模型(而非确定性隐状态)来做 latent reasoning,且不牺牲 LLM 原生的自回归接口。期待后续在更多推理任务上的验证。
欢迎评论区交流。如果你也在做 LLM 推理效率相关的工作,可以聊聊你怎么看 latent reasoning 这个方向。